Finalidade do sistema
Suporte para acesso remoto a arquivos em computadores na rede. O sistema “virtualmente” suporta todas as operações básicas de arquivo (criação, exclusão, leitura, gravação etc.) trocando transações (mensagens) usando o protocolo TCP.
Áreas de aplicação
A funcionalidade do sistema é eficaz nos seguintes casos:
- em aplicativos nativos para dispositivos móveis e incorporados (smartphones, sistemas de controle a bordo, etc.) que requerem acesso rápido a arquivos em servidores remotos nas condições de prováveis interrupções temporárias na conexão (com o desligamento);
- nos DBMSs carregados, se as solicitações forem processadas em alguns servidores e o armazenamento de dados em outros;
- em redes corporativas distribuídas para a coleta e processamento de informações que exigem troca, redundância e confiabilidade de dados em alta velocidade;
- em sistemas complexos com arquitetura de microsserviços, onde os atrasos na troca de informações entre os módulos são críticos.
Estrutura
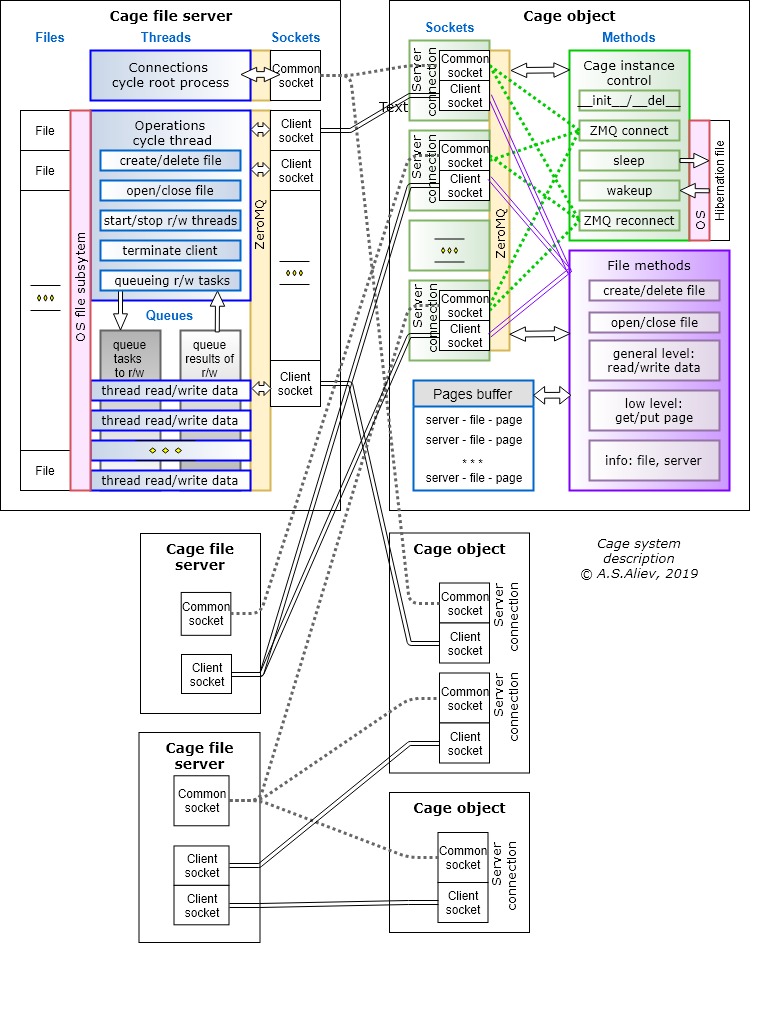
O sistema Cage (existe uma implementação - versão beta no Python 3.7 no sistema operacional Windows) inclui duas partes principais:
- Cageserver - um programa de servidor de arquivos (pacote de funções) executado em computadores na rede que precisam de acesso remoto aos arquivos;
- Classe Cage com uma biblioteca de métodos para software cliente que simplifica a codificação das interações do servidor.
Usando o sistema no lado do cliente
Os métodos da classe Cage substituem as operações usuais do sistema de arquivos "rotineiras": criando, abrindo, fechando, excluindo arquivos e também lendo / gravando dados em formato binário (indicando a posição e o tamanho dos dados). Conceitualmente, esses métodos estão próximos das funções de arquivo da linguagem C, onde a abertura / fechamento de arquivos é realizada "nos canais" da entrada e saída.
Em outras palavras, o programador não trabalha com métodos de objetos "arquivo" (classe _io em Python), mas com métodos da classe Cage.
Ao criar uma instância do objeto Cage, ele estabelece a conexão inicial com o servidor (ou vários servidores), passa a autorização pelo ID do cliente e recebe a confirmação com o número da porta dedicada para todas as operações de arquivo. Quando um objeto Cage é excluído, ele instrui o servidor a encerrar a conexão e fechar os arquivos. O término da comunicação pode iniciar os próprios servidores.
O sistema melhora o desempenho de leitura / gravação com base no buffer de fragmentos de arquivos usados com freqüência dos programas clientes no cache (buffer) da RAM.
O software cliente pode usar qualquer número de objetos do Gaiola com várias configurações (a quantidade de memória do buffer, o tamanho dos blocos ao trocar com o servidor, etc.).
Um único objeto Cage pode trocar dados com vários arquivos em vários servidores. Os parâmetros de comunicação (endereço IP ou servidor DNS, porta principal de autorização, caminho e nome do arquivo) são definidos ao criar o objeto.
Como cada objeto Cage pode trabalhar com vários arquivos ao mesmo tempo, o espaço de memória compartilhado é usado para armazenar em buffer. Tamanho do cache - o número de páginas e seu tamanho, é definido dinamicamente ao criar um objeto Cage. Por exemplo, um cache de 1 GB é 1.000 páginas de 1 MB cada, ou 10.000 páginas de 100 KB cada, ou 1 milhão de páginas de 1 KB cada. A escolha do tamanho e do número de páginas é uma tarefa específica para cada aplicativo.
É possível usar vários objetos do Gaiola ao mesmo tempo para definir diferentes configurações de memória de buffer, dependendo dos recursos de acesso às informações em arquivos diferentes. Como básico, o algoritmo de buffer mais simples é usado: depois que a quantidade especificada de memória é esgotada, novas páginas agrupam as páginas antigas com base no princípio da aposentadoria com um número mínimo de ocorrências. O buffer é especialmente eficaz no caso de compartilhamento desigual (no sentido estatístico), primeiro em arquivos diferentes e, em segundo lugar, em fragmentos de cada arquivo.
A classe Cage suporta entrada / saída não apenas nos endereços de dados (indicando a posição e o comprimento da matriz, "substituindo" as operações do sistema de arquivos), mas também em um nível "físico" mais baixo - pelos números de página na memória do buffer.
Para objetos Cage, a função original de "hibernação" ("suspensão") é suportada - eles podem ser "minimizados" (por exemplo, em caso de desconexão do servidor ou quando o aplicativo é interrompido etc.) em um arquivo de despejo local no lado do cliente e rapidamente restaurar a partir deste arquivo (após retomar a comunicação, quando você reiniciar o aplicativo). Isso possibilita reduzir significativamente o tráfego ao ativar o programa cliente após um "offline" temporário, pois fragmentos de arquivos usados com frequência já estarão no cache.
Cage possui cerca de 3.600 linhas de código.
Princípios de construção de servidores
Os servidores de arquivos Cageserver podem ser ativados com um número arbitrário de portas, uma das quais (a “principal”) é usada apenas para autorização de todos os clientes e o restante para troca de dados. O programa do servidor Cage requer apenas Python. Paralelamente, um computador com um servidor de arquivos pode executar qualquer outro trabalho.
O servidor inicia inicialmente como uma combinação de dois processos principais:
- "Conexões" - um processo para executar operações de estabelecer comunicação com clientes e seu encerramento por iniciativa do servidor;
- “Operações” - um processo para concluir tarefas (operações) de clientes no trabalho com arquivos, bem como para fechar sessões de comunicação nos comandos do cliente.
Ambos os processos não são sincronizados e organizados como ciclos intermináveis de recebimento e envio de mensagens com base em filas de multiprocessos, objetos proxy, bloqueios e soquetes.
O processo "Conexões" fornece a cada cliente uma porta para receber e transmitir dados. O número de portas é definido quando o servidor é iniciado. A correspondência entre portas e clientes é armazenada em uma memória proxy compartilhada entre processos.
O processo Operations suporta a separação dos recursos do arquivo, e vários clientes diferentes podem ler dados de um arquivo juntos ( quase paralelamente , já que o acesso é controlado por bloqueios), se isso foi permitido quando foi aberto pela primeira vez pelo "primeiro" cliente.
O processamento de comandos para criar / excluir / abrir / fechar arquivos no servidor é realizado no processo "Operações" estritamente sequencialmente, usando o subsistema de arquivos do sistema operacional do servidor.
Para aceleração geral de leitura / gravação, essas operações são executadas em threads gerados pelo processo "Operações". O número de threads geralmente é igual ao número de arquivos abertos. As tarefas de leitura / gravação dos clientes são enviadas para a fila geral e o primeiro encadeamento liberado tira a tarefa da cabeça dela. A lógica especial elimina a substituição de dados na RAM do servidor.
O processo "Operações" monitora a atividade dos clientes e interrompe o serviço por comandos e quando o tempo limite de inatividade é excedido.
Para garantir a confiabilidade, o Cageserver registra todas as transações. Um diário geral contém cópias de mensagens de clientes com tarefas para criar / abrir / renomear / excluir arquivos. Um log separado é criado para cada arquivo de trabalho, no qual cópias de mensagens são gravadas com tarefas de leitura e gravação de dados nesse arquivo de trabalho, bem como matrizes de dados (novos) gravados e matrizes de dados que foram destruídas durante a substituição (gravando novos dados “antigos”) )
Esses logs oferecem uma oportunidade para restaurar novas alterações nos backups, bem como "reverter" do conteúdo atual para o momento certo no passado.
O Cageserver possui cerca de 3.100 linhas de código.
Iniciando o Programa do Servidor de Arquivos Cageserver
Ao iniciar na caixa de diálogo, você precisa determinar:
- porto principal de autorização;
- o número de portas para troca de transações com clientes autorizados (a partir de 1 ou mais, o pool de números começa com o próximo seguinte ao número da porta principal).
Usando a classe Cage
gaiola de classe . Gaiola ( cage_name = "", tamanho da página = 0, numpages = 0, maxstrlen = 0, server_ip = {}, espera = 0, acordado = Falso, cache_file = "" )
A partir dessa classe, são criados objetos que interagem com os servidores de arquivos e contêm memória buffer.
Parâmetros
- cage_name ( str ) - o nome condicional do objeto usado para identificar clientes no lado do servidor
- tamanho da página ( int ) - tamanho de uma página da memória buffer (em bytes)
- numpages ( int ) - número de páginas de memória buffer
- maxstrlen ( int ) - comprimento máximo da sequência de bytes em operações de gravação e leitura
- server_ip ( dict ) - um dicionário com os endereços dos servidores usados, em que a chave é o nome condicional do servidor (ID do servidor dentro do aplicativo) e o valor é uma string com o endereço: “endereço IP: porta” ou “DNS: porta” (nomes e endereços reais são temporários , pode ser alterado)
- wait ( int ) - tempo para aguardar uma resposta do servidor ao receber portas (em segundos)
- awake ( boolean ) - sinalizador do método de criação do objeto ( False - se um novo objeto for criado, True - se o objeto for criado a partir de um anteriormente "minimizado" - usando a operação "hibernação", por padrão, False)
- cache_file ( str ) - nome do arquivo para hibernação
Métodos
Gaiola. file_create ( servidor, caminho ) - cria um novo arquivo
Gaiola. file_rename ( servidor, caminho, new_name ) - renomeia o arquivo
Gaiola. file_remove ( servidor, caminho ) - exclui o arquivo
Gaiola. open ( servidor, caminho, mod ) - abrir arquivo
Retorna o número do canal fchannel . O parâmetro mod é o modo de abertura de arquivo: “wm” é exclusivo (leitura / gravação), “rs” é somente leitura e compartilhado apenas por outros clientes, ws é leitura / gravação e compartilhado apenas por outros clientes.
Gaiola. close ( fchannel ) - fecha o arquivo
Gaiola. write ( fchannel, begin, data ) - escreve uma string de bytes em um arquivo
Gaiola. read ( fchannel, begin, len_data ) - lê uma string de bytes de um arquivo
Gaiola. put_pages ( fchannel ) - "envia" do buffer para o servidor todas as páginas do canal especificado que foram modificadas. É usado nesses pontos do algoritmo quando você precisa ter certeza de que todas as operações no canal estão fisicamente armazenadas em um arquivo no servidor.
Gaiola. push_all () - “envia” do buffer para o servidor todas as páginas de todos os canais da instância da classe Cage que foram modificadas. É usado quando você precisa ter certeza de que todas as operações em todos os canais estão armazenadas no servidor.