Em um
artigo anterior, falei sobre nossa grande infraestrutura de teste de carga. Em média, criamos cerca de 100 servidores para fornecer carga e cerca de 150 servidores para o nosso serviço. Todos esses servidores precisam ser criados, excluídos, configurados e executados. Para fazer isso, usamos as mesmas ferramentas do produto para reduzir a quantidade de trabalho manual:
- Para criar e excluir um ambiente de teste - scripts Terraform;
- Para configurar, atualizar e executar - scripts Ansible;
- Para dimensionamento dinâmico, dependendo da carga - scripts Python auto-escritos.
Graças aos scripts Terraform e Ansible, todas as operações, desde a criação de instâncias até a inicialização do servidor, são executadas por apenas seis comandos:
# aws ansible-playbook deploy-config.yml # ansible-playbook start-application.yml # ansible-playbook update-test-scenario.yml --ask-vault-pass # Jmeter , infrastructure-aws-cluster/jmeter_clients:~# terraform apply # jmeter ansible-playbook start-jmeter-server-cluster.yml # jmeter ansible-playbook start-stress-test.yml #
Escala dinâmica de servidor
Na hora do rush da produção, temos mais de 20 mil usuários on-line ao mesmo tempo e, em outras horas, pode haver 6 mil. Não faz sentido manter constantemente o volume total de servidores; portanto, configuramos o dimensionamento automático para os servidores de placas nos quais as placas são abertas no momento em que os usuários as inserem e para servidores de API que processam solicitações de API. Agora, os servidores são criados e excluídos quando necessário.
Esse mecanismo é muito eficaz no teste de carga: por padrão, podemos ter o número mínimo de servidores e, no momento do teste, eles aumentam automaticamente na quantidade certa. No início, podemos ter 4 servidores de placa e, no máximo, até 40. Ao mesmo tempo, novos servidores não são criados imediatamente, mas somente após o carregamento dos servidores atuais. Por exemplo, o critério para criar novas instâncias pode ser 50% da utilização da CPU. Isso permite que você não diminua o crescimento de usuários virtuais no script e não crie servidores desnecessários.
Um bônus dessa abordagem é que, graças ao dimensionamento dinâmico, aprendemos quanta capacidade precisamos para um número diferente de usuários, o que ainda não tínhamos à venda.
Coleção de métricas como no prod
Existem muitas abordagens e ferramentas para monitorar testes de estresse, mas seguimos nosso próprio caminho.
Monitoramos a produção com uma pilha padrão: Logstash, Elasticsearch, Kibana, Prometheus e Grafana. Nosso cluster para testes é semelhante ao produto, por isso decidimos fazer o mesmo monitoramento que o produto, com as mesmas métricas. Há duas razões para isso:
- Não há necessidade de construir um sistema de monitoramento do zero, já o temos completo e imediatamente;
- Além disso, testamos o monitoramento de vendas: se durante o monitoramento entendermos que não temos dados suficientes para analisar o problema, eles não serão suficientes para produção, quando esse problema aparecer lá.
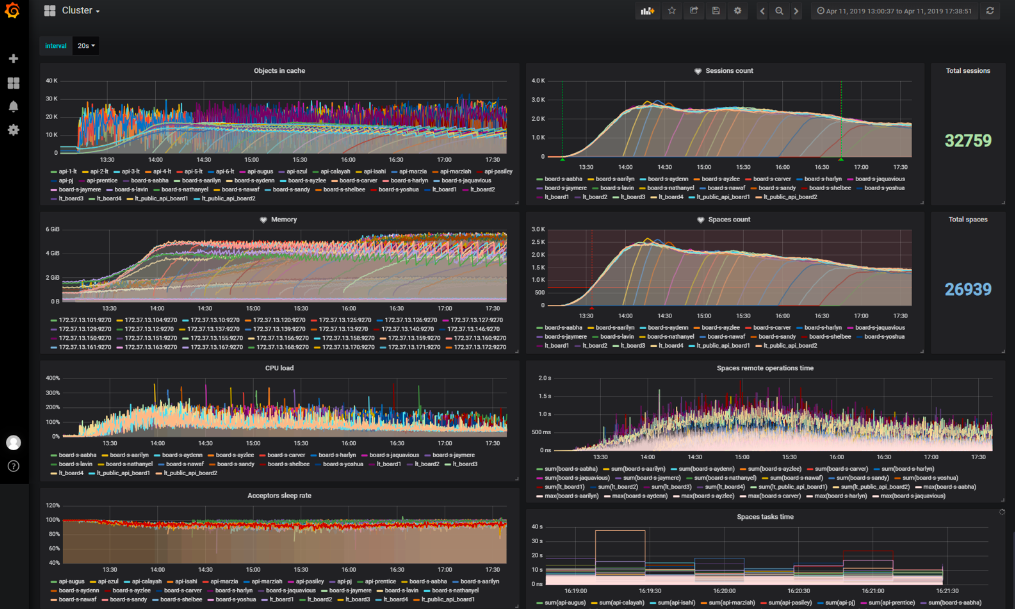
O que mostramos nos relatórios
- Características técnicas do estande;
- O script em si, descrito em palavras, não em código;
- Um resultado compreensível para todos os membros da equipe, desenvolvedores e gerentes;
- Gráficos do estado geral do estande;
- Gráficos que mostram um gargalo ou que são afetados pela otimização verificada no teste.
É importante que todos os resultados sejam armazenados em um único local. Portanto, será conveniente compará-los entre si, do lançamento ao lançamento.
Fazemos relatórios em nosso produto
(exemplo de um quadro branco com um relatório) :
A criação de um relatório leva muito tempo. Portanto, planejamos automatizar a coleta de informações gerais usando
nossa API pública .
Infraestrutura como código
Somos responsáveis pela qualidade do produto, não pelos engenheiros de controle de qualidade, mas por toda a equipe. Os testes de estresse são uma das ferramentas de garantia de qualidade. Legal, se a equipe entender que é importante verificar sob carga as alterações que ele fez. Para começar a pensar nisso, ela precisa se tornar responsável pela produção. Aqui somos ajudados pelos princípios da cultura DevOps, que começamos a implementar em nosso trabalho.
Mas começar a pensar em realizar testes de estresse é apenas o primeiro passo. A equipe não será capaz de pensar em testes sem entender o dispositivo de produção. Encontramos um problema assim quando começamos a configurar o processo de realização de testes de carga em equipes. Naquela época, as equipes não tinham como descobrir o dispositivo de produção, por isso era difícil para eles trabalharem no design dos testes. Havia várias razões: a falta de documentação atualizada ou uma pessoa que teria mantido em mente toda a imagem da venda; crescimento múltiplo da equipe de desenvolvimento.
Para ajudar as equipes a entender o trabalho de vendas, a abordagem de infraestrutura pode ser usada como código, que começamos a usar na equipe de desenvolvimento.
Quais problemas já começamos a resolver usando esta abordagem:
- Tudo deve estar com script e pode ser gerado a qualquer momento. Isso reduz significativamente o tempo de recuperação das vendas em caso de acidente no data center e permite manter a quantidade certa de ambientes de teste relevantes;
- Economia razoável: implantamos ambientes no Openstack quando ele pode substituir plataformas caras como a AWS;
- As próprias equipes criam testes de estresse porque entendem que o dispositivo está vendendo;
- O código substitui a documentação, portanto, não há necessidade de atualizá-la infinitamente, está sempre completa e atualizada;
- Você não precisa de um especialista separado em um campo estreito para resolver problemas comuns. Qualquer engenheiro pode descobrir o código;
- Com uma estrutura de vendas clara, é muito mais fácil agendar testes de carga de pesquisa, como testes de macaco do caos ou testes de vazamento de memória longa.
Eu gostaria de estender essa abordagem não apenas à criação de infraestrutura, mas também ao suporte de várias ferramentas. Por exemplo, o teste de banco de dados, sobre o qual
falei em um artigo anterior , nos transformamos completamente em código. Por esse motivo, em vez de um site pré-preparado, temos um conjunto de scripts, com os quais, em 7 minutos, obtemos o ambiente configurado em uma conta da AWS completamente vazia e podemos iniciar o teste. Pelo mesmo motivo, agora estamos considerando cuidadosamente o
Gatling , que os criadores estão posicionando como uma ferramenta para "Teste de carga como código".
A abordagem da infraestrutura como um código envolve uma abordagem semelhante para testá-la e os scripts que a equipe escreve para aumentar a infraestrutura de novos recursos. Tudo isso deve ser coberto por testes. Existem também várias estruturas de teste, como
Molecule . Existem ferramentas para testes de caos, para a AWS existem ferramentas pagas, para o Docker há
Pumba etc. Eles permitem que você resolva diferentes tipos de tarefas:
- Como verificar se uma das instâncias da AWS falha para verificar se a carga nos servidores restantes está reequilibrada e se o serviço sobreviverá a um redirecionamento tão acentuado de solicitações;
- Como simular a operação lenta da rede, sua quebra e outros problemas técnicos, após os quais a lógica da infraestrutura de serviço não deve quebrar.
A solução de tais problemas em nossos planos imediatos.
Conclusões
- Não vale a pena perder tempo com a orquestração manual da infraestrutura de teste; é melhor automatizar essas ações para gerenciar de maneira mais confiável todos os ambientes, incluindo prod;
- O dimensionamento dinâmico reduz significativamente o custo de manutenção de vendas e um grande ambiente de teste, além de reduzir o fator humano ao dimensionar;
- Você não pode usar um sistema de monitoramento separado para testes, mas retirá-lo do mercado;
- É importante que os relatórios de teste de estresse sejam coletados automaticamente em um único local e tenham uma visão uniforme. Isso permitirá que eles comparem e analisem facilmente as alterações;
- Os testes de estresse se tornarão um processo na empresa quando as equipes se sentirem responsáveis pelas vendas;
- Testes de carga - testes de infraestrutura. Se o teste de carga foi bem-sucedido, é possível que não tenha sido compilado corretamente. A validação da correção do teste requer um profundo entendimento das vendas. As equipes devem ter a oportunidade de entender independentemente o dispositivo de vendas. Resolvemos esse problema usando a infraestrutura como uma abordagem de código;
- Os scripts de preparação da infraestrutura também exigem testes como qualquer outro código.