Olá pessoal!
Nossa empresa está envolvida no desenvolvimento de software e suporte técnico subsequente. Como parte do suporte técnico, você precisa não apenas corrigir os erros, mas monitorar o desempenho de nossos aplicativos.
Por exemplo, se um dos serviços "travar", será necessário corrigir automaticamente esse problema e começar a resolvê-lo, e não esperar chamadas para o suporte técnico para usuários insatisfeitos.
Temos uma empresa pequena, não há recursos para estudar e contém soluções complexas para o monitoramento de aplicações, foi necessário encontrar uma solução simples e eficaz.

Estratégia de monitoramento
Realizar uma verificação de integridade do aplicativo não é fácil, essa tarefa não é trivial, pode-se dizer criativo. É especialmente difícil testar um sistema complexo de múltiplos links.
Como comer um elefante? Apenas em partes! Usamos essa abordagem para monitorar aplicativos.
A essência da nossa estratégia de monitoramento:
Divida o aplicativo em componentes.
Para cada componente, faça as verificações de controle.
Um componente é considerado íntegro se todas as suas verificações de controle forem executadas sem erros. Um aplicativo é considerado íntegro se todos os seus componentes estiverem funcionais.
Assim, qualquer sistema pode ser representado como uma árvore de componentes. Componentes complexos são divididos em outros mais simples. Componentes simples têm verificações.

As verificações de controle não devem executar testes funcionais, pois não são testes de unidade. As verificações de controle devem verificar como o componente se sente no momento atual, se existem todos os recursos necessários para o seu funcionamento, se há algum problema.
Não há milagres, a maioria das verificações precisará ser desenvolvida de forma independente. Mas não se assuste, porque na maioria dos casos uma verificação requer de 5 a 10 linhas de código, mas você pode implementar qualquer lógica e entenderá claramente como a verificação funciona.
Sistema de monitoramento
Suponha que dividamos o aplicativo em componentes, inventemos e implementemos verificações para cada componente, mas o que fazer com os resultados dessas verificações? Como sabemos que algum tipo de verificação falhou?
Nós precisaremos de um sistema de monitoramento. Ela executará as seguintes tarefas:
- Receba os resultados do teste e determine o status dos componentes a partir deles.
Visualmente, parece destacar a árvore de componentes. Componentes reparáveis ficam verdes, componentes problemáticos ficam vermelhos.
- Realize verificações gerais prontas para uso.
O sistema de monitoramento pode executar algumas verificações sozinho. Por que reinventar a roda, vamos usá-los. Por exemplo, você pode verificar se a página do site está abrindo ou se o servidor está respondendo.
- Envie notificações de problemas para as partes interessadas.
- Visualização de dados de monitoramento, fornecendo relatórios, gráficos e estatísticas.
Breve descrição do sistema ASMO
Melhor explicado pelo exemplo. Vamos ver como é organizado o monitoramento da operação do sistema ASMO.
ASMO é um sistema automatizado de suporte meteorológico. O sistema ajuda os especialistas em serviços rodoviários a entender onde e quando é necessário tratar a estrada com materiais anticongelantes. O sistema coleta dados dos pontos de controle de tráfego. Um ponto de controle de estrada é um local na estrada em que o equipamento está instalado: uma estação meteorológica, uma câmera de vídeo e muito mais. Para prever situações perigosas, o sistema recebe previsões meteorológicas de fontes externas.

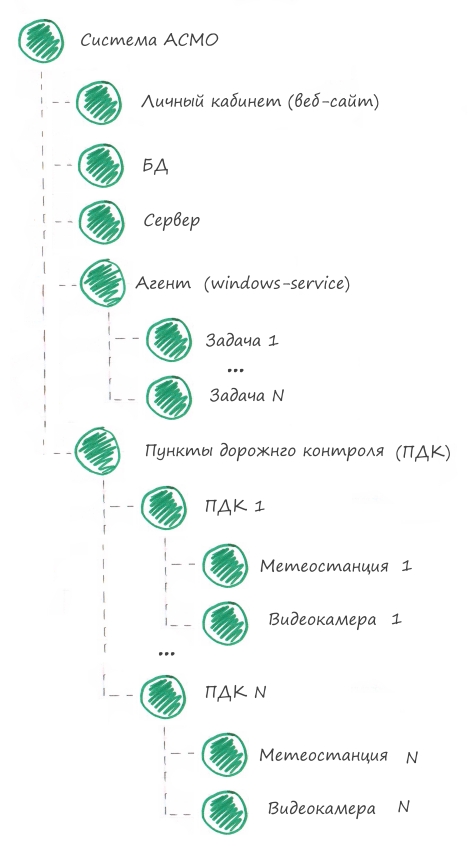
Portanto, a composição do sistema é bastante típica: site, agente, equipamento. Vamos começar a monitorar.
Dividimos o sistema em componentes
Os seguintes componentes podem ser distinguidos no sistema ASMO:
1. Conta pessoalEsta é uma aplicação web. No mínimo, você precisa verificar se o aplicativo está disponível na Internet.
2. Banco de DadosDados importantes para geração de relatórios são armazenados no banco de dados; é necessário verificar se os backups do banco de dados foram criados com sucesso.
3. ServidorPor servidor, queremos dizer hardware no qual os aplicativos estão sendo executados. É necessário verificar o status do HDD, RAM, CPU.
4. AgenteEste é um serviço do Windows que executa muitas tarefas agendadas diferentes. No mínimo, você precisa verificar se o serviço está sendo executado.
5. Tarefa do agenteApenas saber que o agente está trabalhando não é suficiente. Um agente pode funcionar, mas não pode executar as tarefas atribuídas a ele. Dividimos o componente do agente em tarefas e verificamos se cada tarefa do agente está funcionando com êxito.
6. Pontos de controle de estrada (contêiner de todos os MPCs)Como existem muitos pontos de controle de estradas, combinaremos todos os MPCs em um componente. Isso facilitará a leitura dos dados de monitoramento. Ao visualizar o estado do componente "sistema ASMO", ficará imediatamente claro onde estão os problemas: em aplicativos, hardware ou no MPC.
7. Ponto de controle de estrada (um MPC)Consideraremos que este componente pode ser reparado se todos os dispositivos neste MPC puderem ser reparados.
8. DispositivoEsta é uma câmera de vídeo ou estação meteorológica instalada no MPC. Você deve verificar se o dispositivo está funcionando corretamente.
No sistema de monitoramento, a árvore de componentes ficará assim:
Monitoramento de aplicativo da Web
Então, dividimos o sistema em componentes, agora precisamos fazer verificações para cada componente.
Para monitorar o aplicativo Web, usamos as seguintes verificações:
1. Verificando a abertura da página principalEssa verificação é realizada pelo sistema de monitoramento. Para sua execução, indicamos o endereço da página, o fragmento de resposta esperado e o tempo máximo de execução da consulta.
2. Verificação do prazo de pagamento do domínioCheque muito importante. Quando um domínio é deixado sem pagamento, os usuários não podem abrir o site. Pode demorar vários dias para resolver o problema. As alterações no DNS não são aplicadas imediatamente.
3. Verificação de Certificado SSLAgora, quase todos os sites usam o protocolo https para acesso. Para que o protocolo funcione corretamente, você precisa de um certificado SSL válido.
Abaixo está o componente "Conta pessoal" no sistema de monitoramento:

Todas as verificações acima são adequadas para a maioria dos aplicativos e não requerem escrita de código. Isso é ótimo porque você pode começar a monitorar qualquer aplicativo Web em 5 minutos. Abaixo estão verificações adicionais que podem ser executadas para um aplicativo Web, mas sua implementação é mais complexa e específica para aplicativos diferentes, portanto, não iremos analisá-las neste artigo.
O que mais posso verificar?
Para um monitoramento mais completo do aplicativo Web, você pode executar as seguintes verificações:
- Número de erros de JavaScript por período
- O número de erros no lado do aplicativo da web (back-end) para o período
- O número de respostas sem êxito do aplicativo da web (código de resposta 404, 500, etc.)
- Tempo médio de execução da consulta
Monitorando o serviço do Windows (agente)
No sistema ASMO, o agente atua como um agendador de tarefas, que em segundo plano executa tarefas agendadas.
Se todas as tarefas do agente forem bem-sucedidas, o agente estará funcionando corretamente. Acontece que, para monitorar um agente, é necessário monitorar suas tarefas. Portanto, dividimos o componente Agente em tarefas. Criaremos para cada tarefa um componente separado no sistema de monitoramento, onde o componente "Agente" será o "pai".
Dividimos o componente Agente em componentes filhos (tarefas):
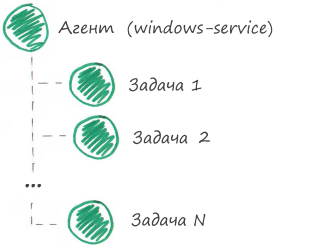
Então, dividimos um componente complexo em vários simples. Agora você precisa apresentar verificações para cada componente simples. Observe que o componente pai "Agente" não terá uma única verificação, porque o sistema de monitoramento calculará seu status com base no status de seus componentes filhos. Em outras palavras, se todas as tarefas forem concluídas com êxito, o agente também funcionará com êxito.
Existem mais de cem tarefas no sistema ASMO, é realmente necessário criar verificações exclusivas para cada tarefa? Obviamente, o controle será melhor se, para cada tarefa do agente, elaborarmos nossas próprias verificações especiais, mas na maioria dos casos é suficiente usar verificações universais.
O sistema ASMO usa apenas verificações universais para tarefas e isso é suficiente para monitorar o desempenho do sistema.
Verificar execuçãoA verificação mais simples e mais eficaz é uma verificação do progresso. A verificação verifica se a tarefa está sendo executada e sem erros. Todas as tarefas têm essa verificação.
Algoritmo de validação
Após a execução de cada tarefa, é necessário enviar ao sistema de monitoramento o resultado da verificação de SUCESSO, se a tarefa foi bem-sucedida, ou ERRO, se a execução falhar.
Essa verificação permite detectar os seguintes problemas:
- A tarefa é executada, mas falha.
- A tarefa parou de executar, por exemplo, congelou.
Vamos considerar como esses problemas são resolvidos em mais detalhes.
Problema 1 - A tarefa é executada, mas falhaAbaixo está o caso em que a tarefa é executada, mas das 14:00 às 16:00 falha.
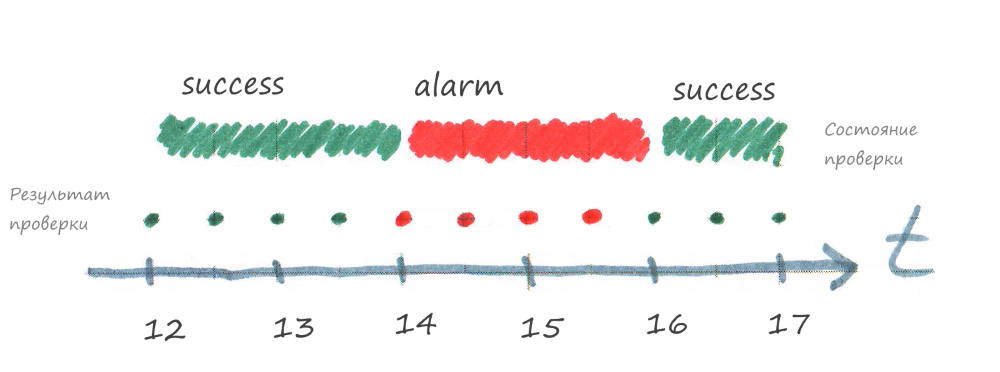
A figura mostra que quando a tarefa falha, o sinal é imediatamente enviado ao sistema de monitoramento e o status da verificação correspondente no sistema de monitoramento se torna alarme.
Observe que no sistema de monitoramento o status do componente depende do status da verificação. O status do alarme da verificação converterá todos os componentes de nível superior em alarme, veja a figura abaixo.
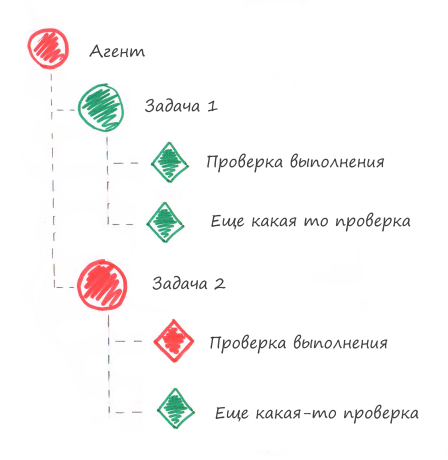 Problema 2 - A tarefa parou de funcionar (travou)
Problema 2 - A tarefa parou de funcionar (travou)Como o sistema de monitoramento entende que a tarefa está congelada?
O resultado da verificação tem um tempo de relevância, por exemplo, 1 hora. Se uma hora passar e não houver novo resultado de verificação, o sistema de monitoramento definirá o status do alarme na verificação.
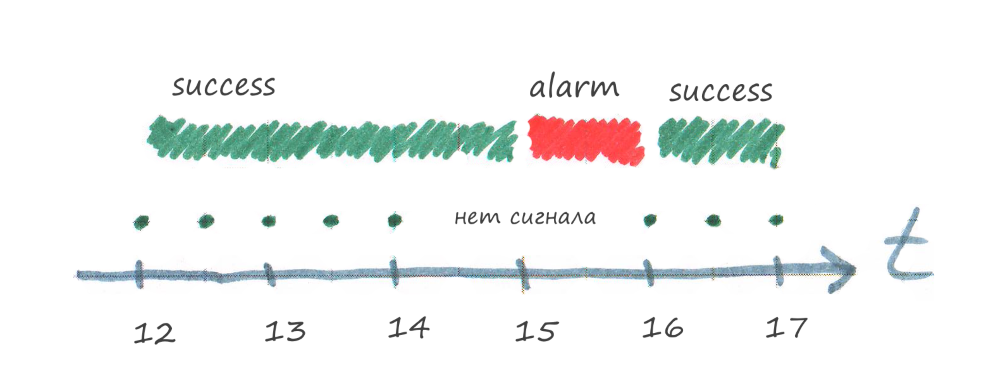
Na foto acima, às 14:00, as luzes foram apagadas. Às 15:00, o sistema de monitoramento detectará que o resultado do teste (das 14:00) está podre, porque o tempo de relevância expirou (uma hora), mas não há novo resultado e transferirá a verificação para o status de alarme.
Às 16:00, a luz foi acesa novamente, o programa concluirá a tarefa e enviará o resultado ao sistema de monitoramento, o status da verificação se tornará sucesso novamente.
Qual é o prazo de validade da verificação?
O tempo de relevância deve ser maior que o período de execução da tarefa. Eu recomendo definir o tempo de relevância 2-3 vezes maior que o período da tarefa. Isso é necessário para não receber notificações falsas quando, por exemplo, a tarefa demorou mais que o normal ou alguém recarregou o programa.
Verificação de ProgressoO sistema ASMO tem a tarefa "Download de uma previsão", que uma vez por hora tenta baixar uma nova previsão de uma fonte externa. O horário exato em que uma nova previsão aparece no sistema externo não é conhecido, mas sabe-se que isso acontece 2 vezes por dia. Acontece que, se não houver nova previsão por várias horas, isso é normal, mas se não houver nova previsão por mais de um dia, algo será quebrado em algum lugar. Por exemplo, em um sistema de previsão externo, o formato dos dados pode ser alterado, pelo que a ASMO não verá uma nova liberação de previsão.
Algoritmo de validação
A tarefa envia o resultado da verificação de SUCESSO para o sistema de monitoramento quando é possível obter progresso (faça o download de uma nova previsão do tempo). Se não houver progresso ou ocorrer um erro, nada será enviado ao sistema de monitoramento.
A auditoria deve ter um intervalo de relevância, de forma a garantir um novo progresso durante esse período.
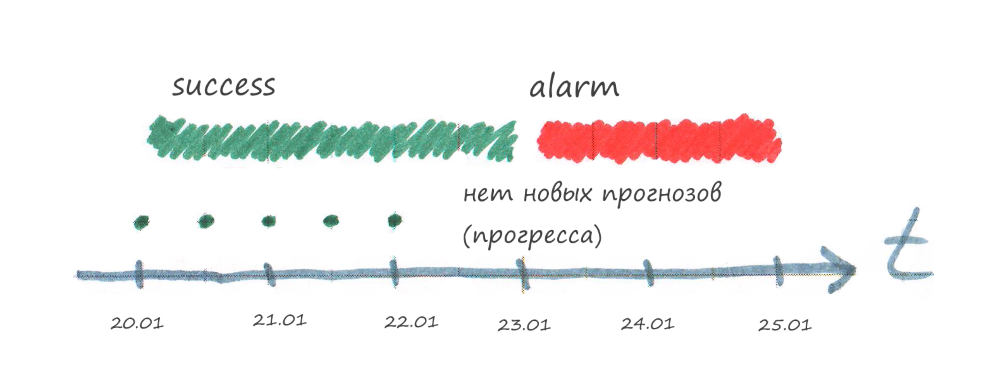
Observe que aprendemos sobre o problema com atraso, porque o sistema de monitoramento aguarda até que o tempo de relevância do último resultado do teste expire. Portanto, o tempo de relevância da verificação não precisa ser muito demorado.
Monitoramento de banco de dados
Para controlar o banco de dados no sistema ASMO, realizamos as seguintes verificações:
- Verificar backups
- Verificando espaço livre em disco
Verificar backupsNa maioria dos aplicativos, é importante ter backups atuais do banco de dados, para que, em caso de falha do servidor, você possa implantar o programa em um novo servidor.
A ASMO, uma vez por semana, cria uma cópia de backup e a envia ao repositório. Quando esse procedimento é concluído com êxito, o resultado da verificação de sucesso é enviado ao sistema de monitoramento. O resultado da verificação tem um prazo de validade de 9 dias. I.e. Para controlar a criação de backups, é usado o mecanismo de "verificação do progresso", que examinamos acima.
Verificando espaço livre em discoSe não houver espaço livre suficiente no disco, o banco de dados não poderá funcionar normalmente; portanto, é importante controlar a quantidade de espaço livre.
É conveniente usar métricas para verificar os parâmetros numéricos.
Métrica é uma variável numérica cujo valor é passado para o sistema de monitoramento. O sistema de monitoramento verifica os limites e calcula o status da métrica.
Abaixo está uma imagem de como é o componente "Banco de Dados" no sistema de monitoramento:

Monitoramento de servidor
Para monitorar o servidor, usamos as seguintes verificações e métricas:
1. Espaço livre em discoSe o espaço em disco acabar, o aplicativo não poderá funcionar. Utilizamos 2 valores limite: o primeiro nível é AVISO, o segundo nível é ALARME.
2. O valor médio da RAM em porcentagem por horaUsamos o valor médio por hora, como não estamos interessados em raças raras.
3. O valor médio da CPU em porcentagem por horaUsamos o valor médio por hora, como não estamos interessados em raças raras.
4. Verificação de pingVerifica se o servidor está online. O sistema de monitoramento é capaz de executar essa verificação, sem necessidade de escrever código.
Abaixo está uma imagem de como é o componente "Servidor" no sistema de monitoramento:

Monitoramento de equipamentos
Eu vou lhe dizer como os dados são recebidos. Para cada ponto de controle de estrada (MPC) no planejador de tarefas, há uma tarefa, por exemplo, "Polling MPC M2 km 200". A tarefa uma vez em 30 minutos recebe dados de todos os dispositivos MPC.
Problema no canal de comunicaçãoA maioria dos equipamentos está localizada fora da cidade, uma rede GSM é usada para transmissão de dados, que não funciona de forma estável (ou seja, não existe).
Devido a falhas freqüentes na rede, a primeira vez que verificou a pesquisa MPC no monitoramento ficou assim:

Tornou-se claro que essa não é uma opção funcional, porque muitos alertas falsos foram recebidos sobre os problemas. Em seguida, foi decidido que cada dispositivo usasse uma "verificação de progresso", ou seja, somente o sinal de sucesso é enviado ao sistema de monitoramento quando o dispositivo é pesquisado sem erros. O tempo de relevância foi estabelecido em 5 horas.

Agora, o monitoramento envia uma notificação de problemas somente quando o dispositivo falha ao interrogar por mais de 5 horas. Com um alto grau de probabilidade, esses não são alarmes falsos, mas problemas reais.
Abaixo está uma imagem de como o equipamento se parece em um sistema de monitoramento:
 Importante!
Importante!Quando a rede GSM pára de funcionar, todos os dispositivos MPC não são interrogados. Para reduzir o número de letras do sistema de monitoramento, nossos engenheiros assinam notificações de problemas de componentes com o tipo "MPC", e não "Dispositivo". Isso permite que você receba uma notificação para cada MAC, em vez de receber uma notificação separada para cada dispositivo.
O esquema final de monitoramento ASMO
Vamos juntar tudo e ver que tipo de esquema de monitoramento temos.
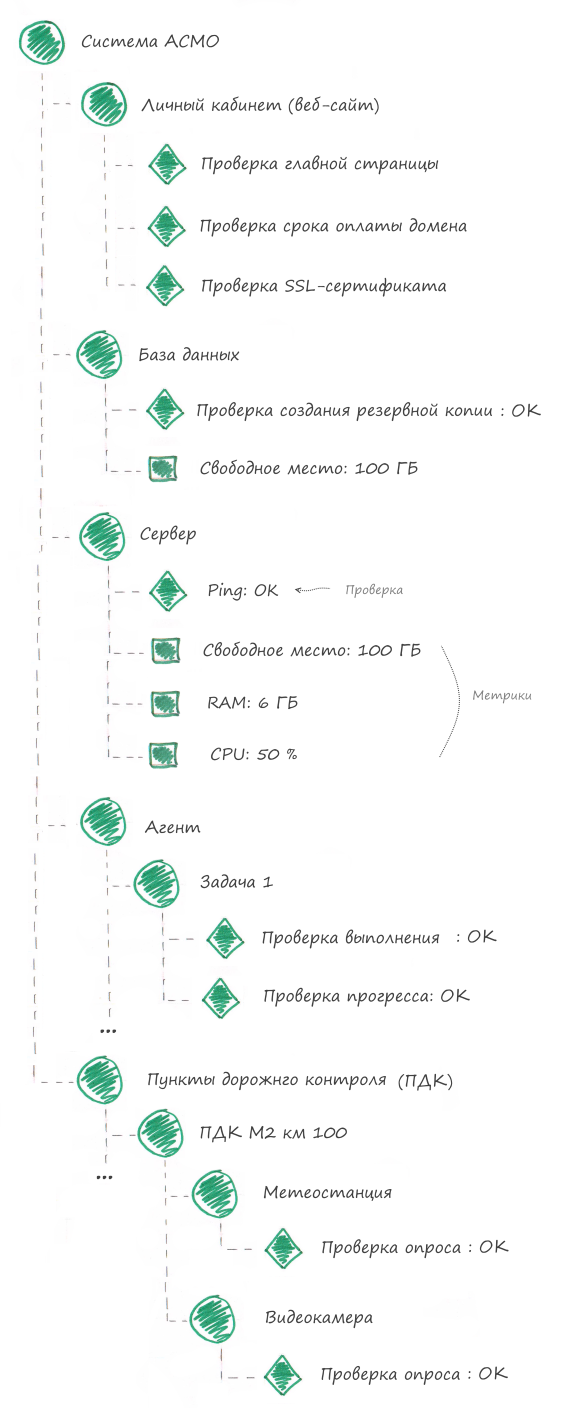
Conclusão
Vamos resumir.
O que o monitoramento do desempenho da OMAPE nos deu?
1. Diminuição do tempo de solução de problemasCostumávamos aprender sobre defeitos dos usuários, mas nem todos os usuários relatam defeitos. Aconteceu que descobrimos o mau funcionamento de qualquer componente do sistema uma semana após seu aparecimento. Agora, o sistema de monitoramento nos notifica sobre problemas assim que o problema é detectado.
2. Maior estabilidade do sistemaDesde que os defeitos começaram a ser corrigidos mais cedo, o sistema como um todo começou a funcionar muito mais estável.
3. Reduzindo o número de chamadas de suporte técnicoMuitos problemas agora são corrigidos antes que os usuários descubram sobre eles. Os usuários têm menos contato com o suporte técnico. Tudo isso tem um bom efeito em nossa reputação.
4. Aumentar a lealdade do cliente e do usuárioO cliente percebeu mudanças positivas na estabilidade do sistema. É menos provável que os usuários tenham problemas com o sistema.
5. Reduza os custos de suporte técnicoParamos de executar manualmente qualquer verificação. Agora todas as verificações são automatizadas. Costumávamos aprender sobre os problemas dos usuários, muitas vezes era difícil entender de que problema o usuário estava falando. Agora, a maioria dos problemas é relatada pelo sistema de monitoramento. As notificações contêm dados técnicos, nos quais é sempre claro o que e onde ocorreu.
Importante!Você não pode instalar um sistema de monitoramento no mesmo servidor em que seus aplicativos estão em execução. Se o servidor travar, os aplicativos deixarão de funcionar e não haverá ninguém para enviar uma notificação sobre isso.
O sistema de monitoramento deve funcionar em um servidor separado em outro data center.
Se você não quiser usar um servidor dedicado no novo datacenter, poderá usar o sistema de monitoramento em nuvem. Nossa empresa usa o sistema de monitoramento em nuvem Zidium, mas você pode usar qualquer outro sistema de monitoramento. O custo de um sistema de monitoramento em nuvem é menor do que o aluguel de um novo servidor.
Recomendações:- Quebre aplicativos e sistemas na forma de uma árvore de componentes com o máximo de detalhes possível, para que seja conveniente entender onde e o que foi quebrado, e o controle será mais completo.
- Para verificar a integridade de um componente, use verificações. É melhor usar muitas verificações simples do que uma complexa.
- Os valores da métrica de limite são configurados na lateral do sistema de monitoramento e não gravam no código. Isso evitará recompilar, reconfigurar ou reiniciar o aplicativo.
- Para verificações personalizadas, use o tempo de relevância com uma margem para não receber notificações falsas devido ao fato de que algum tipo de verificação demorou um pouco mais que o normal.
- Tente garantir que os componentes no sistema de monitoramento fiquem vermelhos somente quando houver um problema. Se eles ficarem vermelhos por nada, você deixará de prestar atenção às notificações do sistema de monitoramento, seu significado será perdido.
Se você ainda não estiver usando um sistema de monitoramento, comece! Não é tão difícil quanto parece. Fique alto olhando para a árvore de componentes verdes que você cresceu.Boa sorte