
A Reunião Anual da Association for Computational Linguistics (ACL) é a principal conferência de processamento de linguagem natural. Está organizado desde 1962. Depois do Canadá e da Austrália, ela retornou à Europa e marchou em Florença. Assim, este ano foi mais popular entre os pesquisadores europeus do que a EMNLP.
Este ano foram publicados 660 artigos de 2900 enviados. Uma quantidade enorme. Dificilmente é possível fazer algum tipo de revisão objetiva do que estava na conferência. Portanto, contarei meus sentimentos subjetivos a partir deste evento.
Eu vim à conferência para mostrar em uma sessão de pôsteres
nossa decisão da competição Kaggle sobre a
resolução de pronome de gênero do Google. Nossa solução se baseou fortemente no uso de
modelos BERT pré-
treinados . E, como se viu, não estávamos sozinhos nisso.
Bertology

Havia tantos trabalhos baseados no BERT, descrevendo suas propriedades e usando-os como um porão, que até o termo Bertologia apareceu. De fato, os modelos BERT foram tão bem-sucedidos que até grandes grupos de pesquisa comparam seus modelos com o BERT.
Então, no início de junho, surgiram trabalhos sobre a
XLNet . E logo antes da conferência -
ERNIE 2.0 e
RoBERTaFacebook RoBERTa
Quando o modelo XLNet foi introduzido pela primeira vez, alguns pesquisadores sugeriram que ele obteve melhores resultados, não apenas por causa de seus princípios de arquitetura e treinamento. Ela também estudou em um corpo maior (quase 10 vezes) que o BERT e por mais tempo (4 vezes mais iterações).
Pesquisadores do Facebook mostraram que o BERT ainda não atingiu seu máximo. Eles apresentaram uma abordagem otimizada para o ensino do modelo BERT - RoBERTa (abordagem BERT otimizada com robustez).
Não mudando nada na arquitetura do modelo, eles mudaram o procedimento de treinamento:
- Aumentamos o corpo para treinamento, o tamanho do lote, a duração da sequência e a duração do treinamento.
- A tarefa de prever a próxima frase foi removida do treinamento.
- Eles começaram a gerar dinamicamente tokens MASK (tokens que o modelo tenta prever durante o pré-treinamento).
ERNIE 2.0 do Baidu
Como todos os modelos recentes populares (BERT, GPT, XLM, RoBERTa, XLNet), o ERNIE é baseado no conceito de um transformador com um mecanismo de auto-atenção. O que o distingue de outros modelos são os conceitos de aprendizado multitarefa e aprendizado contínuo.
O ERNIE aprende sobre diferentes tarefas, atualizando constantemente a representação interna do seu modelo de linguagem. Essas tarefas têm, como outros modelos, objetivos de auto-aprendizado (auto-supervisionado e fraco-supervisionado). Exemplos de tais tarefas:
- Recupere a ordem correta das palavras em uma frase.
- Capitalização de palavras.
- Definição de palavras mascaradas.
Nessas tarefas, o modelo aprende sequencialmente, retornando às tarefas nas quais foi treinado anteriormente.
RoBERTa vs ERNIE
Nas publicações, RoBERTa e ERNIE não são comparados entre si, pois apareceram quase simultaneamente. Eles são comparados ao BERT e ao XLNet. Mas aqui não é tão fácil fazer uma comparação. Por exemplo, no popular
benchmark, o GLUE XLNet é representado por um conjunto de modelos. E os pesquisadores do Baidu estão mais interessados em comparar modelos únicos. Além disso, como o Baidu é uma empresa chinesa, eles também estão interessados em comparar os resultados do trabalho com o idioma chinês. Mais recentemente, uma nova referência apareceu:
SuperGLUE . Ainda não existem muitas soluções, mas o RoBERTa está em primeiro lugar aqui.
No geral, porém, tanto o RoBERTa quanto o ERNIE apresentam desempenho melhor que o XLNet e significativamente melhor que o BERT. O RoBERTa, por sua vez, funciona um pouco melhor que o ERNIE.
Gráficos de conhecimento
Muito trabalho foi dedicado à combinação de duas abordagens: redes pré-treinadas e o uso de regras na forma de gráficos de conhecimento (Knowledge Graphs, KG).
Por exemplo:
ERNIE: representação aprimorada de idiomas com entidades informativas . Este artigo destaca o uso de gráficos de conhecimento sobre o modelo de linguagem BERT. Isso permite que você obtenha melhores resultados em tarefas como determinar o tipo de entidade (
Digitação de entidade) e Classificação de relação .
Em geral, a moda de escolher nomes de modelos pelos nomes de personagens da Vila Sésamo leva a consequências engraçadas. Por exemplo, esse ERNIE não tem nada a ver com o ERNIE 2.0 do Baidu, sobre o qual escrevi acima.

Outro trabalho interessante sobre a geração de novos conhecimentos:
COMET: Transformadores Commonsense para construção automática de gráficos de conhecimento . O artigo considera a possibilidade de usar novas arquiteturas baseadas em transformadores para o treinamento de redes baseadas no conhecimento. As bases de conhecimento de forma simplificada são muitos triplos: sujeito, atitude, objeto. Eles usaram dois conjuntos de dados da base de conhecimento: ATOMIC e ConceptNet. E eles treinaram uma rede baseada no modelo GPT (Generative Pré-Treinado Transformer). O sujeito e a atitude foram introduzidos e tentaram prever o objeto. Assim, eles obtiveram um modelo que gera objetos por sujeitos e relacionamentos de entrada.
Métricas
Outro tópico interessante na conferência foi a questão da escolha de métricas. Muitas vezes, é difícil avaliar a qualidade de um modelo em tarefas de processamento de linguagem natural, o que atrasa o progresso nessa área de aprendizado de máquina.
Em um artigo de
Estudo de métricas de avaliação de resumo no intervalo de pontuação apropriada , Maxim Peyar discute o uso de várias métricas em um problema de resumo de texto. Essas métricas nem sempre se correlacionam bem entre si, o que interfere na comparação objetiva de vários algoritmos.
Ou aqui está um trabalho interessante:
Avaliação automática de textos com várias frases . Nele, os autores apresentam uma métrica que pode substituir BLEU e ROUGE em tarefas nas quais você precisa avaliar textos de várias frases.
A métrica BLEU pode ser representada como Precisão - quantas palavras (ou n gramas) da resposta do modelo estão contidas no destino. ROUGE is Recall - quantas palavras (ou n gramas) do alvo estão contidas na resposta do modelo.
A métrica proposta no artigo é baseada na métrica WMD (Distância do motor do Word) - a distância entre dois documentos. É igual à distância mínima entre palavras em duas frases no espaço da representação vetorial dessas palavras. Mais informações sobre o WMD podem ser encontradas no tutorial, que usa o
WMD do Word2Vec e
do GloVe .
Em seu artigo, eles oferecem uma nova métrica: WMS (Similarity do Word Mover).
WMS(A, B) = exp(−WMD(A, B))
Eles então definem o SMS (semelhança do movedor de sentenças). Ele usa uma abordagem semelhante à do WMS. Como representação vetorial da sentença, eles recebem o vetor médio das palavras da sentença.
Ao calcular o WMS, as palavras são normalizadas pela frequência no documento. Ao calcular sentenças por SMS, é normalizado pelo número de palavras na sentença.
Finalmente, a métrica S + WMS é uma combinação de WMS e SMS. Em seu artigo, eles apontam que suas métricas se correlacionam melhor com a avaliação manual de uma pessoa.
Chatbots
A parte mais útil da conferência, na minha opinião, foram sessões de pôsteres. Nem todos os relatórios foram interessantes, mas se você começar a ouvir alguns, não sairá para outro no meio do relatório. Cartazes são outra questão. Existem várias dezenas deles na sessão de pôsteres. Você escolhe os que mais gosta e, em regra, pode conversar diretamente com o desenvolvedor sobre detalhes técnicos. A propósito, existe um site interessante com
pôsteres de conferências . É verdade que existem pôsteres de duas conferências por lá e não se sabe se o site será atualizado.
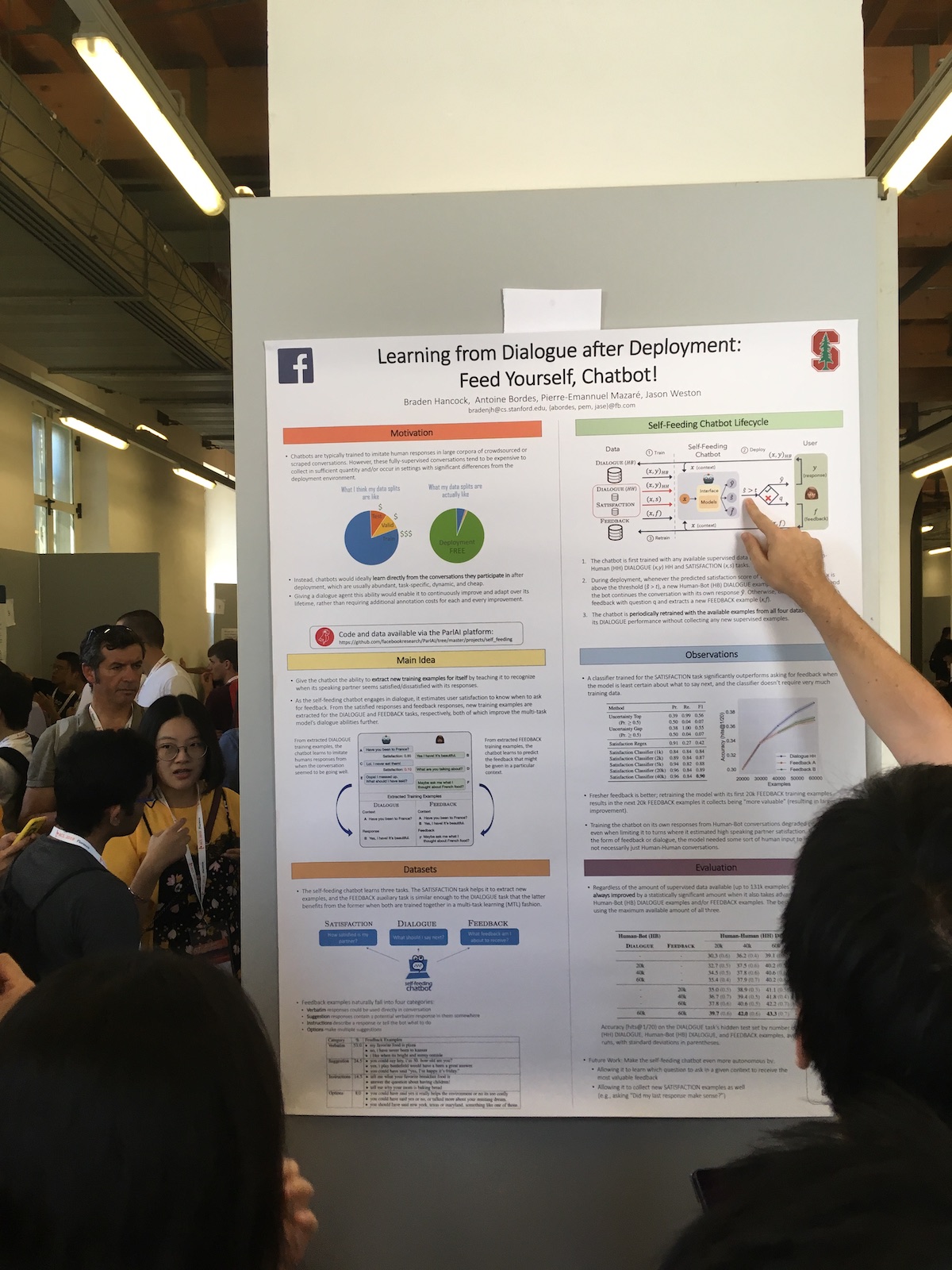
Nas sessões de pôsteres, grandes empresas frequentemente apresentavam trabalhos interessantes. Por exemplo, aqui está um artigo do Facebook
Aprendendo com o Diálogo após a Implantação: Alimente-se, Chatbot! .
A peculiaridade de seu sistema é o uso expandido das respostas do usuário. Eles possuem um classificador que avalia o grau de satisfação do usuário com o diálogo. Eles usam essas informações para diferentes tarefas:
- Use uma medida de satisfação como uma métrica de qualidade.
- Eles treinam o modelo, aplicando a abordagem da aprendizagem contínua (Aprendizagem Contínua).
- Use diretamente no diálogo. Expresse alguma reação humana se o usuário estiver satisfeito. Ou eles perguntam o que está errado se o usuário está insatisfeito.
A partir dos relatórios, havia uma história interessante sobre o chatbot chinês da Microsoft.
O design e a implementação do XiaoIce, um chatbot social empáticoA China já é um dos líderes na introdução de tecnologias de inteligência artificial. Mas muitas vezes o que está acontecendo na China não é bem conhecido na Europa. E o XiaoIce é um projeto incrível. Já existe há cinco anos. Atualmente, não há muitos chatbots dessa idade trabalhando. Em 2018, já tinha 660 milhões de usuários.
O sistema possui um bot de bate-papo e um sistema de habilidades. O bot já possui 230 habilidades, ou seja, adiciona aproximadamente uma habilidade por semana.
Para avaliar a qualidade do bot de bate-papo, eles usam a duração do diálogo. E não em minutos, como geralmente é feito, mas no número de réplicas em uma conversa. Eles chamam essa métrica de Conversão por turnos por sessão (CPS) e escrevem que no momento seu valor médio é 23, que é o melhor indicador entre sistemas similares.
Em geral, o projeto é muito popular na China. Além do bot em si, o sistema escreve poesia, desenha imagens,
lança uma coleção de roupas , canta músicas.
Tradução automática
De todos os discursos que participei, o mais animado foi o relatório de
interpretação simultânea de Liang Huang, representando a Baidu Research.
Ele falou sobre essas dificuldades na tradução simultânea moderna:
- Existem apenas 3.000 intérpretes simultâneos certificados no mundo.
- Os tradutores podem trabalhar apenas 15 a 20 minutos continuamente.
- Apenas cerca de 60% do texto original é traduzido.
A tradução em frases inteiras já atingiu um bom nível, mas ainda há espaço para melhorias na tradução simultânea. Como exemplo, ele citou o sistema de interpretação simultânea, que funcionou na Conferência Mundial do Baidu. O atraso na tradução em 2018 em comparação com 2017 foi reduzido de 10 para 3 segundos.
Poucas equipes fazem isso e existem poucos sistemas de trabalho. Por exemplo, quando o Google traduz a frase que você escreve online, ele refaz constantemente a frase final. E isso não é tradução simultânea, porque com tradução simultânea não podemos mudar as palavras já ditas.

No sistema deles, eles usam a tradução de prefixos - parte de uma frase. Ou seja, eles esperam algumas palavras e começam a traduzir, tentando adivinhar o que aparecerá na fonte. O tamanho dessa mudança é medido em palavras e é adaptável. Após cada etapa, o sistema decide se vale a pena esperar ou se já pode ser traduzido. Para avaliar esse atraso, eles introduzem a seguinte métrica:
métrica de atraso
médio (AL) .
A principal dificuldade com a tradução simultânea é a ordem das palavras diferentes nos idiomas. E o contexto ajuda a combater isso. Por exemplo, você muitas vezes precisa traduzir os discursos dos políticos, e eles são bastante estereotipados. Mas também há problemas. Então o orador brincou sobre Trump. Então, ele diz, se Bush voou para Moscou, é altamente provável que, para se encontrar com Putin. E se Trump voou para, então ele pode conhecer e jogar golfe. Em geral, ao traduzir, as pessoas geralmente criam algo que adicionam. E digamos que, se você precisar traduzir algum tipo de piada, e eles não puderem fazer isso imediatamente, eles podem dizer: "Uma piada foi dita aqui, apenas ria".
Havia também um artigo sobre tradução automática que recebeu o prêmio “O Melhor Artigo Longo”:
Fazendo a ponte entre treinamento e inferência para tradução automática
neural .
Ele descreve um problema de tradução automática. No processo de aprendizado, geramos tradução palavra por palavra com base no contexto de palavras conhecidas. No processo de uso do modelo, contamos com o contexto das palavras recém-geradas. Há uma discrepância entre treinar o modelo e usá-lo.
Para reduzir essa discrepância, os autores propõem, na fase de treinamento no contexto, misturar as palavras previstas pelo modelo no processo de treinamento. O artigo discute a escolha ideal de tais palavras geradas.
Conclusão
Obviamente, uma conferência não é apenas artigos e relatórios. É também comunicação, namoro e outras redes. Além disso, os organizadores da conferência estão tentando entreter os participantes. No ACL, na festa principal, houve uma apresentação de tenores, na Itália, afinal. E para resumir, houve anúncios dos organizadores de outras conferências. E a reação mais violenta entre os participantes foi causada por mensagens dos organizadores da EMNLP de que este ano a festa principal será na Disneylândia de Hong Kong e, em 2020, a conferência será realizada na República Dominicana.