Em geral, usando o comando shell, você pode obter qualquer métrica sem escrever código ou integrações. Portanto, no console, deve haver uma ferramenta simples e conveniente para visualização.
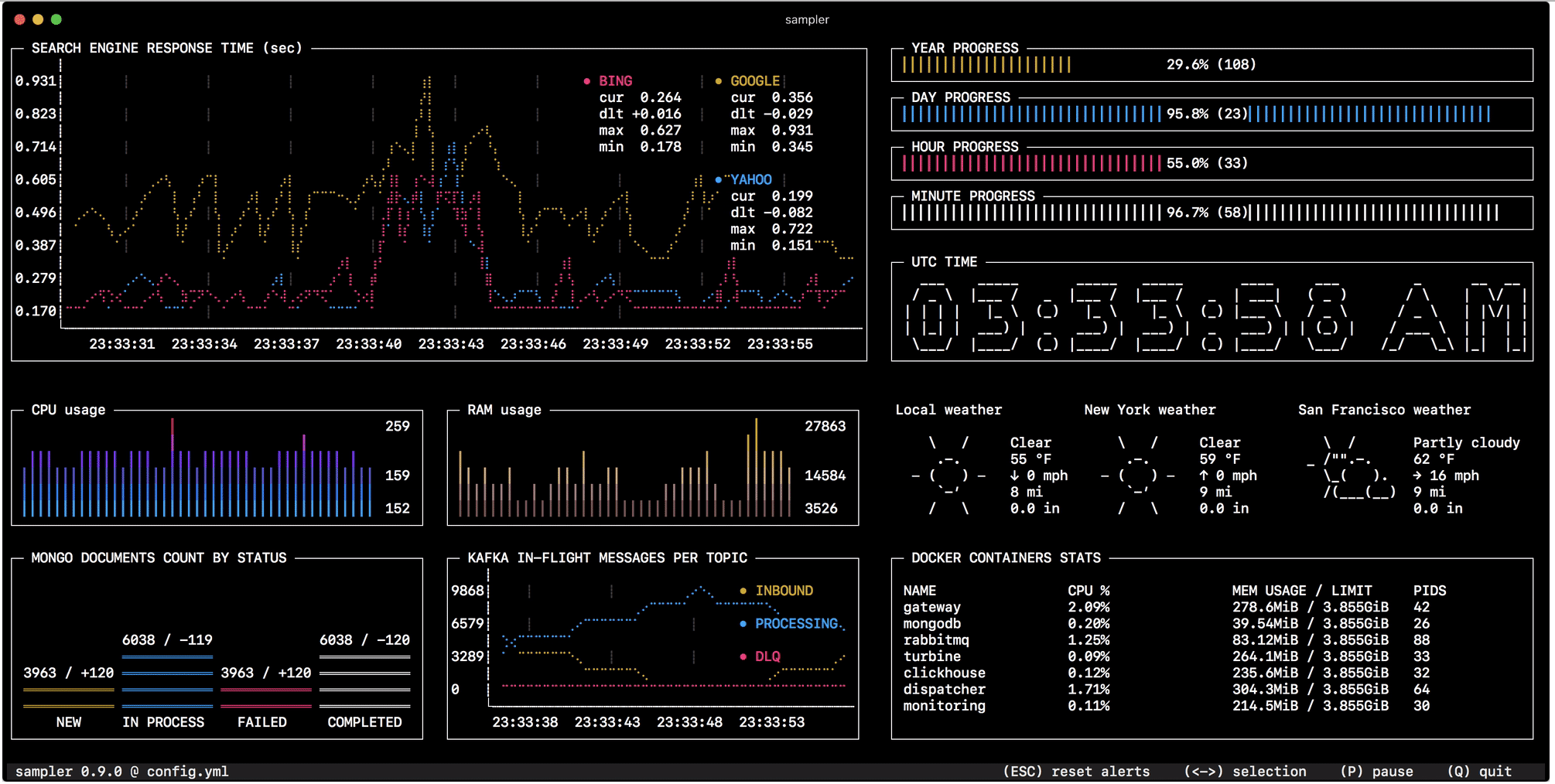
O monitoramento da mudança de estado no banco de dados, o tamanho das filas, a telemetria de servidores remotos, a execução de implantações de scripts e o recebimento de notificações após a conclusão são configurados em um minuto com um arquivo YAML simples.
O código está disponível no github . Instruções de instalação - para Linux, macOS e Windows (experimental).
Por que preciso disso quando existem sistemas de monitoramento completos?
Devo dizer imediatamente que isso não é de forma alguma uma alternativa aos painéis e monitoramento em grande escala. Comparar Sampler com Prometheus + Grafana é o mesmo que comparar tail e less com Elastic Stack ou Splunk .
Mas se você aumentar e configurar o monitoramento da produção para sua tarefa - como um canhão em pardais, talvez o Sampler seja a resposta para a pergunta. Foi concebido como uma ferramenta para prototipar, demonstrar ou simplesmente observar métricas em um local e em um servidor remoto.
Por isso, deve ser colocado em todos os servidores?
Não, o Sampler pode ser executado localmente, mas as métricas podem ser obtidas em muitas máquinas remotas. Cada componente no painel possui uma seção init , na qual é possível entrar via ssh (ou executar qualquer outra ação para entrar no interactive shell - estabelecer uma conexão com o banco de dados, conectar-se via JMX, efetuar login na API etc.)
Vistas de componentes e exemplos de configuração
Os exemplos de configuração mostram comandos para o macOS. Muitos funcionarão inalterados no Linux, mas alguns precisam ser adaptados.
Runchart

Configuração runcharts: - title: Search engine response time rate-ms: 500 # sampling rate, default = 1000 scale: 2 # number of digits after sample decimal point, default = 1 legend: enabled: true # enables item labels, default = true details: false # enables item statistics: cur/min/max/dlt, default = true items: - label: GOOGLE sample: curl -o /dev/null -s -w '%{time_total}' https://www.google.com - label: YAHOO sample: curl -o /dev/null -s -w '%{time_total}' https://search.yahoo.com - label: BING sample: curl -o /dev/null -s -w '%{time_total}' https://www.bing.com
Sparkline

Configuração sparklines: - title: CPU usage rate-ms: 200 scale: 0 sample: ps -A -o %cpu | awk '{s+=$1} END {print s}' - title: Free memory pages rate-ms: 200 scale: 0 sample: memory_pressure | grep 'Pages free' | awk '{print $3}'
Barchart

Configuração barcharts: - title: Local network activity rate-ms: 500 # sampling rate, default = 1000 scale: 0 # number of digits after sample decimal point, default = 1 items: - label: UDP bytes in sample: nettop -J bytes_in -l 1 -m udp | awk '{sum += $4} END {print sum}' - label: UDP bytes out sample: nettop -J bytes_out -l 1 -m udp | awk '{sum += $4} END {print sum}' - label: TCP bytes in sample: nettop -J bytes_in -l 1 -m tcp | awk '{sum += $4} END {print sum}' - label: TCP bytes out sample: nettop -J bytes_out -l 1 -m tcp | awk '{sum += $4} END {print sum}'
Medidor

Configuração gauges: - title: Minute progress rate-ms: 500 # sampling rate, default = 1000 scale: 2 # number of digits after sample decimal point, default = 1 percent-only: false # toggle display of the current value, default = false color: 178 # 8-bit color number, default one is chosen from a pre-defined palette cur: sample: date +%S # sample script for current value max: sample: echo 60 # sample script for max value min: sample: echo 0 # sample script for min value - title: Year progress cur: sample: date +%j max: sample: echo 365 min: sample: echo 0
Caixa de texto

Configuração textboxes: - title: Local weather rate-ms: 10000 # sampling rate, default = 1000 sample: curl wttr.in?0ATQF border: false # border around the item, default = true color: 178 # 8-bit color number, default is white - title: Docker containers stats rate-ms: 500 sample: docker stats --no-stream --format "table {{.Name}}\t{{.CPUPerc}}\t{{.MemUsage}}\t{{.PIDs}}"
Asciibox

Configuração asciiboxes: - title: UTC time rate-ms: 500 # sampling rate, default = 1000 font: 3d # font type, default = 2d border: false # border around the item, default = true color: 43 # 8-bit color number, default is white sample: env TZ=UTC date +%r
Funcionalidade adicional
Triggers
Os acionadores permitem acionar alguma ação adicional se o valor medido atender à condição especificada. Tanto a condição quanto a reação também são comandos de shell nos quais as variáveis $label , $cur e $prev são fornecidas. Primeiro, os acionadores foram concebidos para alertar (notificações sonoras e visuais estão embutidas), mas com a opção de seu próprio script para responder ao acionamento de um acionador, você pode personalizar a ação conforme desejar (por exemplo, enviar uma notificação para o seu telefone com o Pushover )
O exemplo abaixo ilustra a configuração dos gatilhos. Se a latência da resposta do mecanismo de pesquisa exceder 0,3 segundos - o Sampler pisca a campainha do terminal padrão, perde o tom quindar da NASA, exibe uma notificação visual no gráfico e executa um script que, neste caso, fala o valor medido da latência na voz:
runcharts: - title: SEARCH ENGINE RESPONSE TIME (sec) rate-ms: 200 items: - label: GOOGLE sample: curl -o /dev/null -s -w '%{time_total}' https://www.google.com - label: YAHOO sample: curl -o /dev/null -s -w '%{time_total}' https://search.yahoo.com triggers: - title: Latency threshold exceeded condition: echo "$prev < 0.3 && $cur > 0.3" |bc -l # "1" TRUE actions: terminal-bell: true # default = false sound: true # NASA quindar tone, default = false visual: true # default = false script: 'say alert: ${label} latency exceeded ${cur} second'
Shell interativo
Se você precisar inserir o shell interativo antes de iniciar a amostragem (para uma conexão única com o banco de dados, login SSH, conexão com JMX, etc.), poderá especificar um init script que será executado uma vez na inicialização. Um exemplo de conexão e sondagem do mongoDB:
textboxes: - title: MongoDB polling rate-ms: 500 init: mongo --quiet --host=localhost test # sample: Date.now(); # mongo shell transform: echo result = $sample #
Além disso, há suporte para o modo PTY e scripts multistep-init .
Variáveis
Se a configuração contiver partes usadas com freqüência que você não deseja repetir, poderá colocá-las em variáveis e usá- las em qualquer lugar do arquivo YML.
Na prática
Como programador de back-end, geralmente tenho que depurar, criar protótipos e medir. Daí a necessidade regular de visualização e monitoramento rápidos. Escrever algo personalizado toda vez é excessivamente longo, mas se o processo de personalização for rápido e (mais ou menos) conveniente, essa visualização poderá economizar tempo e resolver problemas. Não consegui encontrar nada parecido com isso, por isso foi decidido escrever uma ferramenta dessas e torná-la o mais universalmente configurável possível.
Pela primeira vez para a finalidade pretendida, comecei a usá-lo para depurar o mecanismo de agrupamento e acumulação de dados, que muda rapidamente o status de "eventos" na memória. Ler o estado do sistema nos logs ou pesquisar contadores individuais para cada um dos status não ajuda a navegar rapidamente e entender o que é o quê, mas uma olhada no Sampler resolve completamente esse problema -
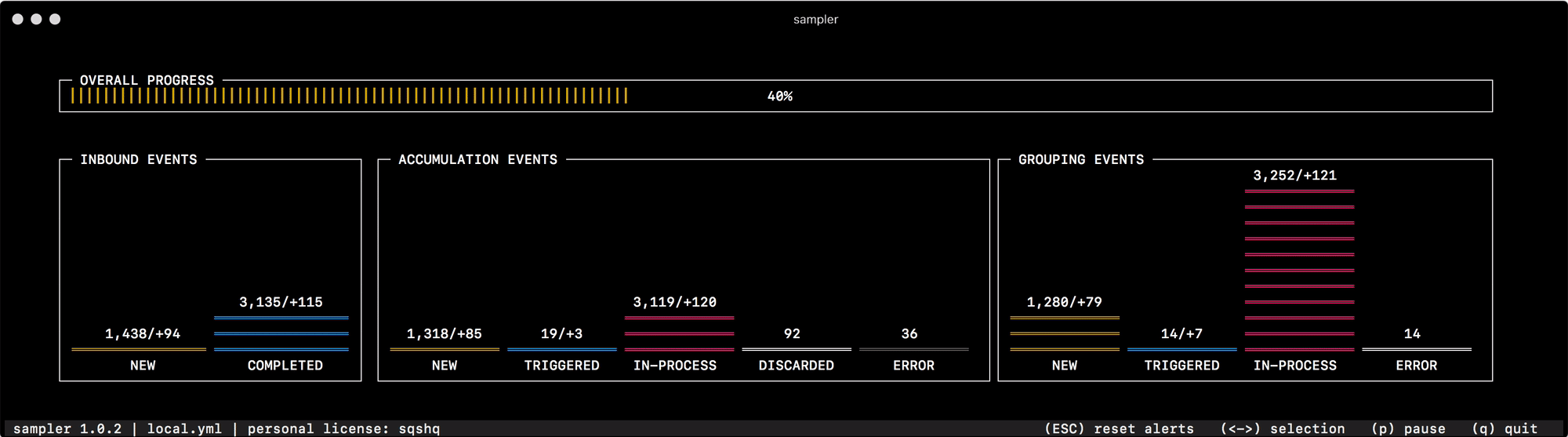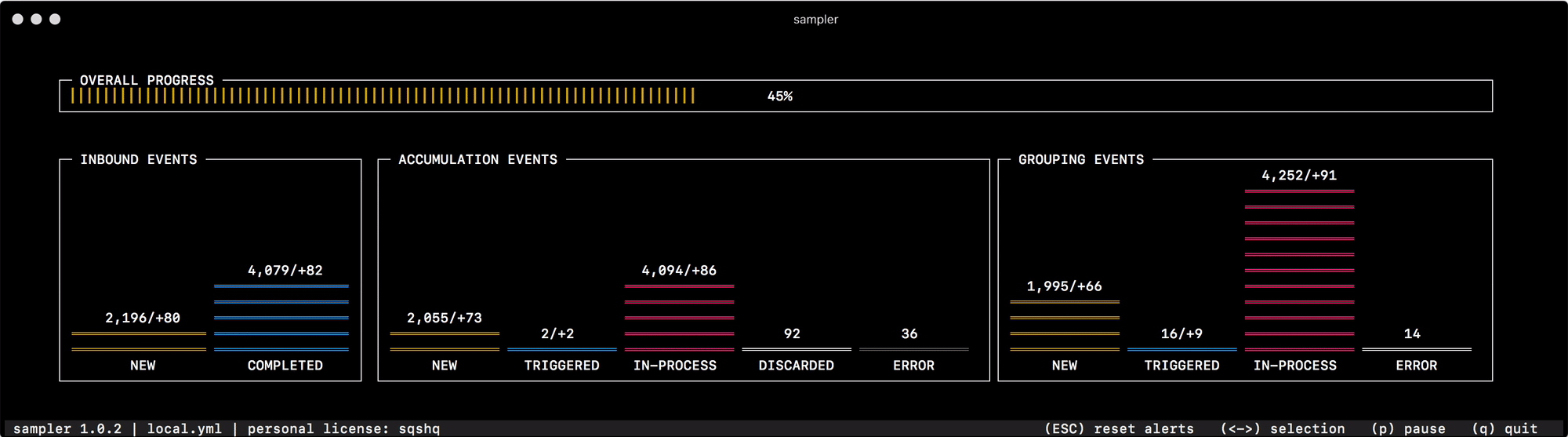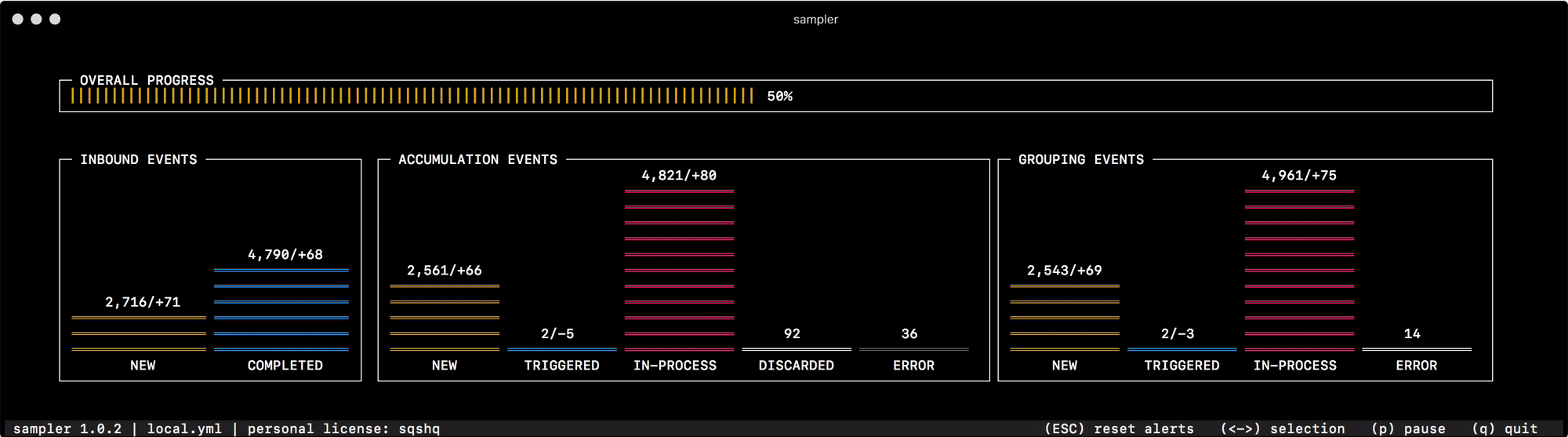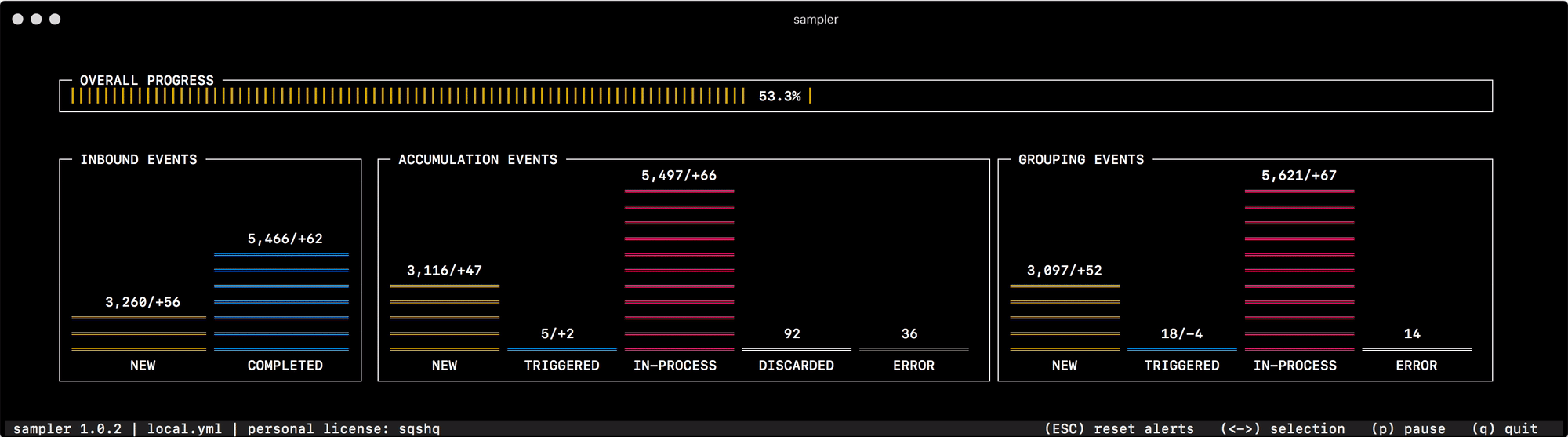
Para tudo o que eu me uso, preparei uma coleção de "receitas" - configurações de receitas que você pode copiar e começar imediatamente a personalizar para suas tarefas
- Conexões com o Banco de Dados: MySQL, PostgreSQL, MongoDB, Neo4J
- Kafka
- Docker
- Ssh
- Jmx
Esta lista será complementada (e sua contribuição é muito bem-vinda) e, enquanto isso, em questões, as pessoas começaram a compartilhar suas configurações para painéis Kubernetes, Github e muito mais.
Isso é tudo, habr. Eu ficaria feliz se alguém seria útil.