
Neste artigo, quero oferecer uma alternativa ao estilo tradicional de design de teste usando os conceitos de programação funcional do Scala. A abordagem foi inspirada nos muitos meses de dor do suporte de dezenas e centenas de testes de queda e um desejo ardente de torná-los mais fáceis e mais compreensíveis.
Apesar do código estar escrito em Scala, as idéias propostas serão relevantes para desenvolvedores e testadores em todas as linguagens que suportam o paradigma de programação funcional. Você pode encontrar um link para o Github com uma solução completa e um exemplo no final do artigo.
O problema
Se você já lidou com testes (não importa - testes de unidade, integração ou funcional), provavelmente eles foram escritos como um conjunto de instruções seqüenciais. Por exemplo:
Essa é a preferida para a maioria, não exigindo desenvolvimento, uma maneira de descrever testes. Nosso projeto possui cerca de 1000 testes de diferentes níveis (testes de unidade, testes de integração, ponta a ponta), e todos eles, até recentemente, foram escritos em um estilo semelhante. À medida que o projeto crescia, começamos a sentir problemas significativos e uma desaceleração com o apoio de tais testes: colocar os testes em ordem não demorou menos do que escrever código relevante para os negócios.
Ao escrever novos testes, você sempre teve que pensar do zero como preparar os dados. Frequentemente, copie e cole etapas de testes vizinhos. Como resultado, quando o modelo de dados no aplicativo mudou, o baralho de cartas desmoronou e teve que ser coletado de uma nova maneira em cada teste: na melhor das hipóteses, apenas uma alteração nas funções dos auxiliares, na pior das hipóteses - uma imersão profunda no teste e reescrita.
Quando o teste falhou honestamente - ou seja, por causa de um bug na lógica de negócios, e não por problemas no próprio teste - para entender onde algo deu errado, sem depurar, era impossível. Como demorou muito tempo para entender os testes, ninguém possuía conhecimento completo dos requisitos - como o sistema deveria se comportar sob certas condições.
Toda essa dor é o sintoma de dois problemas mais profundos desse design:
- O conteúdo do teste é permitido de forma muito flexível. Cada teste é único, como um floco de neve. A necessidade de ler os detalhes do teste leva muito tempo e desmotiva. Detalhes não importantes desviam a atenção do principal - os requisitos verificados pelo teste. Copiar e colar está se tornando a principal maneira de escrever novos casos de teste.
- Os testes não ajudam o desenvolvedor a localizar erros, mas apenas sinalizam um problema. Para entender o estado em que o teste é executado, é necessário restaurá-lo em sua cabeça ou conectar-se a um depurador.
Modelagem
Podemos fazer melhor? (Spoiler: podemos.) Vejamos no que esse teste consiste.
val db: Database = Database.forURL(TestConfig.generateNewUrl()) migrateDb(db) insertUser(db, id = 1, name = "test", role = "customer") insertPackage(db, id = 1, name = "test", userId = 1, status = "new") insertPackageItems(db, id = 1, packageId = 1, name = "test", price = 30) insertPackageItems(db, id = 2, packageId = 1, name = "test", price = 20) insertPackageItems(db, id = 3, packageId = 1, name = "test", price = 40)
O código testado, como regra, aguardará a entrada de alguns parâmetros explícitos - identificadores, tamanhos, volumes, filtros etc. Além disso, muitas vezes precisará de dados do mundo real - vemos que o aplicativo se refere aos menus e modelos de menu banco de dados. Para uma execução confiável do teste, precisamos do equipamento - o estado em que o sistema e / ou os provedores de dados devem estar antes do início do teste e os parâmetros de entrada, geralmente relacionados ao estado.
Prepararemos as dependências com esse equipamento - preencha o banco de dados (fila, serviço externo, etc.). Com a dependência preparada, inicializamos a classe testada (serviços, módulos, repositórios, etc.).
val svc = new SomeProductionLogic(db) val result = svc.calculatePrice(packageId = 1)
Ao executar o código de teste em alguns parâmetros de entrada, obtemos um resultado ( saída ) significativo para os negócios - explícito (retornado pelo método) e implícito - uma alteração no estado notório: banco de dados, serviço externo etc.
result shouldBe 90
Por fim, verificamos que os resultados são exatamente o que eles esperavam, resumindo o teste com uma ou mais asserções .
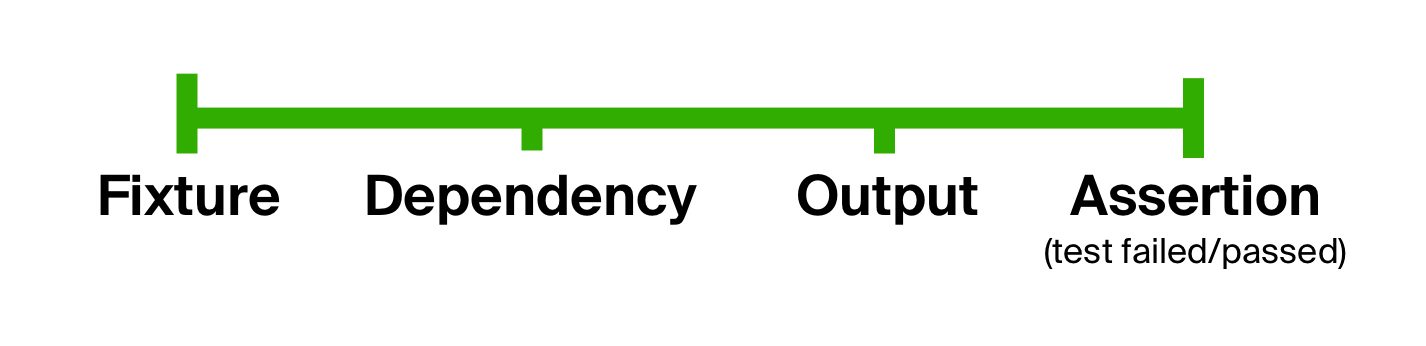
Pode-se concluir que, em geral, o teste consiste nas mesmas etapas: preparando parâmetros de entrada, executando o código de teste neles e comparando os resultados com os esperados. Podemos usar esse fato para nos livrar do primeiro problema do teste - de forma muito flexível, dividindo claramente o teste em estágios. Essa idéia não é nova e tem sido usada há muito tempo em testes no estilo BDD ( desenvolvimento orientado a comportamento ).
E quanto à extensibilidade? Qualquer uma das etapas do processo de teste pode conter quantas etapas intermediárias você desejar. No futuro, poderíamos formar um dispositivo, primeiro criando um tipo de estrutura legível por humanos e depois convertendo-o em objetos que preenchem o banco de dados. O processo de teste é infinitamente expansível, mas, no final das contas, sempre se resume aos estágios principais.

Executando testes
Vamos tentar entender a ideia de dividir o teste em estágios, mas primeiro determinamos como gostaríamos de ver o resultado final.
Em geral, queremos tornar os testes de escrita e suporte um processo menos trabalhoso e mais agradável. Quanto menos instruções explícitas não exclusivas (repetidas em outra parte) do corpo do teste, menos mudanças precisarão ser feitas nos testes após a alteração de contratos ou refatoração e menos tempo levará para a leitura do teste. O design do teste deve incentivar a reutilização de trechos de código usados com frequência e impedir cópias imprudentes. Seria bom se os testes tivessem uma aparência uniforme. A previsibilidade melhora a legibilidade e economiza tempo - imagine quanto tempo levaria os estudantes de física a dominar cada nova fórmula se eles fossem descritos em palavras de forma livre, em vez de linguagem matemática.
Assim, nosso objetivo é ocultar tudo que é perturbador e supérfluo, deixando apenas as informações críticas para a compreensão da aplicação: o que é testado, o que é esperado na entrada e o que é esperado na saída.
Vamos voltar ao modelo do dispositivo de teste. Tecnicamente, cada ponto deste gráfico pode ser representado por um tipo de dados e transições de um para outro - funções. Você pode vir do tipo de dados inicial para o final aplicando a seguinte função ao resultado do anterior por um. Em outras palavras, usando uma composição de funções : preparar dados (vamos chamá-lo de prepare ), executar o código de teste ( execute ) e verificar o resultado esperado ( check ). Passaremos o primeiro ponto do gráfico, dispositivo elétrico, para a entrada dessa composição. A função de ordem superior resultante é chamada de função de ciclo de vida de teste.
Função de ciclo de vida def runTestCycle[FX, DEP, OUT, F[_]]( fixture: FX, prepare: FX => DEP, execute: DEP => OUT, check: OUT => F[Assertion] ): F[Assertion] =
A questão é: de onde vêm as funções internas? Prepararemos os dados de um número limitado de maneiras - para preencher o banco de dados, se molhar etc. -, portanto, as opções para a função de preparação serão comuns a todos os testes. Como resultado, será mais fácil criar funções especializadas do ciclo de vida que ocultam a implementação específica da preparação de dados. Como os métodos de chamar o código que está sendo verificado e verificado são relativamente exclusivos para cada teste, a execute e a check serão fornecidas explicitamente.
Função de ciclo de vida adaptada para testes de integração no banco de dados Ao delegar todas as nuances administrativas à função de ciclo de vida, temos a oportunidade de expandir o processo de teste sem entrar em nenhum teste já escrito. Devido à composição, podemos nos infiltrar em qualquer lugar do processo, extrair ou adicionar dados lá.
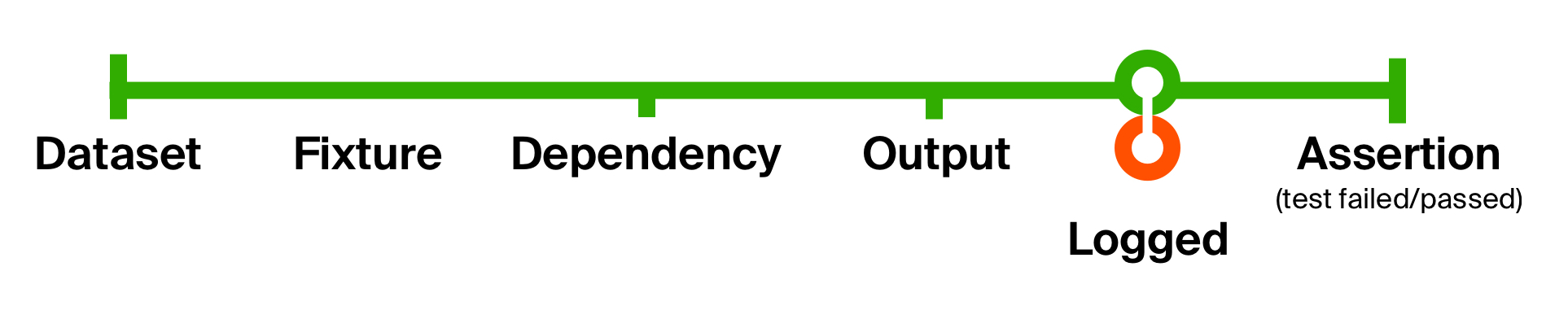
Para ilustrar melhor as possibilidades dessa abordagem, resolveremos o segundo problema de nosso teste inicial - a falta de informações de suporte para localizar problemas. Adicione o log ao receber uma resposta do método testado. Nosso registro não alterará o tipo de dados, mas produzirá apenas um efeito colateral - exibindo uma mensagem no console. Portanto, após o efeito colateral, retornaremos como está.
Função de ciclo de vida de log def logged[T](implicit loggedT: Logged[T]): T => T = (that: T) => {
Com um movimento tão simples, adicionamos o log do resultado retornado e o estado do banco de dados em cada teste . A vantagem dessas pequenas funções é que elas são fáceis de entender, fáceis de compor para reutilização e fáceis de eliminar, se não forem mais necessárias.

Como resultado, nosso teste terá a seguinte aparência:
val fixture: SomeMagicalFixture = ???
O corpo do teste tornou-se conciso, os equipamentos e as verificações podem ser reutilizados em outros testes, e não preparamos o banco de dados manualmente em nenhum outro lugar. Apenas um problema permanece ...
Preparação do acessório
No código acima, usamos a suposição de que o equipamento virá de algum lugar pronto e que ele só precisa ser transferido para a função de ciclo de vida. Como os dados são um ingrediente-chave em testes simples e suportados, não podemos deixar de abordar como formar esses dados.
Suponha que nossa loja de teste tenha um banco de dados de tamanho médio típico (por simplicidade, um exemplo com 4 tabelas, mas na realidade pode haver centenas). A parte contém informações básicas, parte - negócios diretamente e todas juntas podem ser conectadas a várias entidades lógicas completas. As tabelas são interconectadas por chaves (chaves estrangeiras ) - para criar uma entidade Bonus , você precisa da entidade Package e, por sua vez, User . E assim por diante

As circunstâncias das limitações do circuito e todos os tipos de hacks levam à inconsistência e, como resultado, testam a instabilidade e horas de emocionante depuração. Por esse motivo, preencheremos o banco de dados honestamente.
Poderíamos usar métodos militares para o preenchimento, mas mesmo com um exame superficial dessa idéia, muitas questões difíceis surgem. O que preparará os dados nos testes para esses métodos? Precisarei reescrever os testes se o contrato mudar? E se os dados forem entregues por um aplicativo não testado (por exemplo, importar por outra pessoa)? Quantas consultas diferentes terão que ser feitas para criar uma entidade dependente de muitas outras?
Preenchendo a base no teste inicial insertUser(db, id = 1, name = "test", role = "customer") insertPackage(db, id = 1, name = "test", userId = 1, status = "new") insertPackageItems(db, id = 1, packageId = 1, name = "test", price = 30) insertPackageItems(db, id = 2, packageId = 1, name = "test", price = 20) insertPackageItems(db, id = 3, packageId = 1, name = "test", price = 40)
Os métodos auxiliares dispersos, como no exemplo original, são o mesmo problema, mas com um molho diferente. Eles atribuem a responsabilidade de gerenciar objetos dependentes e seus relacionamentos a nós mesmos, e gostaríamos de evitar isso.
Idealmente, eu gostaria de ter esse tipo de dados, um olhar que é suficiente para entender em termos gerais em que estado o sistema estará durante o teste. Um dos bons candidatos à visualização de estado é uma tabela (a la datasets em PHP e Python), onde não há nada supérfluo, exceto em campos críticos para a lógica de negócios. Se a lógica comercial mudar em um recurso, todo o suporte ao teste será reduzido para atualizar as células no conjunto de dados. Por exemplo:
val dataTable: Seq[DataRow] = Table( ("Package ID", "Customer's role", "Item prices", "Bonus value", "Expected final price") , (1, "customer", Vector(40, 20, 30) , Vector.empty , 90.0) , (2, "customer", Vector(250) , Vector.empty , 225.0) , (3, "customer", Vector(100, 120, 30) , Vector(40) , 210.0) , (4, "customer", Vector(100, 120, 30, 100) , Vector(20, 20) , 279.0) , (5, "vip" , Vector(100, 120, 30, 100, 50), Vector(10, 20, 10), 252.0) )
Da nossa tabela, geraremos relacionamentos de chaves - entidades por ID. Nesse caso, se a entidade depender de outra, uma chave será formada para a dependência. Pode acontecer que duas entidades diferentes gerem uma dependência com o mesmo identificador, o que pode levar à violação da restrição na chave primária do banco de dados ( chave primária ). Mas, nesse estágio, os dados são extremamente baratos para desduplicar - como as chaves contêm apenas identificadores, podemos colocá-los em uma coleção que fornece desduplicação, por exemplo, em Set . Se isso for insuficiente, sempre poderemos tornar a desduplicação mais inteligente na forma de uma função adicional compilada em uma função de ciclo de vida.
Exemplo-chave sealed trait Key case class PackageKey(id: Int, userId: Int) extends Key case class PackageItemKey(id: Int, packageId: Int) extends Key case class UserKey(id: Int) extends Key case class BonusKey(id: Int, packageId: Int) extends Key
Delegamos a geração de conteúdo falso a campos (por exemplo, nomes) em uma classe separada. Em seguida, recorrendo à ajuda dessa classe e às regras para a conversão de chaves, obtemos objetos de string destinados diretamente à inserção no banco de dados.
Exemplo de linha object SampleData { def name: String = "test name" def role: String = "customer" def price: Int = 1000 def bonusAmount: Int = 0 def status: String = "new" } sealed trait Row case class PackageRow(id: Int, name: String, userId: Int, status: String) extends Row case class PackageItemRow(id: Int, packageId: Int, name: String, price: Int) extends Row case class UserRow(id: Int, name: String, role: String) extends Row case class BonusRow(id: Int, packageId: Int, bonusAmount: Int) extends Row
Os dados falsos padrão, como regra, não serão suficientes para nós, portanto, precisaremos redefinir campos específicos. Podemos usar lentes - percorrer todas as linhas criadas e alterar os campos apenas daqueles que são necessários. Como as lentes no final são funções comuns, elas podem ser compostas, e essa é a sua utilidade.
Exemplo de lente def changeUserRole(userId: Int, newRole: String): Set[Row] => Set[Row] = (rows: Set[Row]) => rows.modifyAll(_.each.when[UserRow]) .using(r => if (r.id == userId) r.modify(_.role).setTo(newRole) else r)
Graças à composição, em todo o processo, podemos aplicar várias otimizações e melhorias - por exemplo, agrupar linhas em tabelas para que possam ser inseridas com uma insert , reduzindo o tempo de teste ou protegendo o estado final do banco de dados para simplificar os problemas de captura.
Função de modelagem do dispositivo elétrico def makeFixture[STATE, FX, ROW, F[_]]( state: STATE, applyOverrides: F[ROW] => F[ROW] = x => x ): FX = (extractKeys andThen deduplicateKeys andThen enrichWithSampleData andThen applyOverrides andThen logged andThen buildFixture) (state)
Todos juntos nos fornecerão um suporte que preenche a dependência do teste - o banco de dados. No teste em si, nada de supérfluo será visto, exceto o conjunto de dados original - todos os detalhes serão ocultados na composição das funções.

Nossa suíte de testes agora ficará assim:
val dataTable: Seq[DataRow] = Table( ("Package ID", "Customer's role", "Item prices", "Bonus value", "Expected final price") , (1, "customer", Vector(40, 20, 30) , Vector.empty , 90.0) , (2, "customer", Vector(250) , Vector.empty , 225.0) , (3, "customer", Vector(100, 120, 30) , Vector(40) , 210.0) , (4, "customer", Vector(100, 120, 30, 100) , Vector(20, 20) , 279.0) , (5, "vip" , Vector(100, 120, 30, 100, 50), Vector(10, 20, 10), 252.0) ) " -" - { "'customer'" - { " " - { "< 250 - " - { "(: )" in calculatePriceFor(dataTable, 1) "(: )" in calculatePriceFor(dataTable, 3) } ">= 250 " - { " - 10% " in calculatePriceFor(dataTable, 2) " - 10% " in calculatePriceFor(dataTable, 4) } } } "'vip' - 20% , " in calculatePriceFor(dataTable, 5) }
Um código auxiliar:
Adicionar novos casos de teste à tabela se torna uma tarefa trivial, que permite que você se concentre em cobrir o número máximo de condições de contorno , em vez de em um padrão.
Reutilizando o código de preparação do dispositivo elétrico em outros projetos
Bem, escrevemos muito código para preparar equipamentos em um projeto específico, gastando muito tempo nisso. E se tivermos vários projetos? Estamos fadados a reinventar a roda e copiar e colar cada vez?
Podemos abstrair a preparação de luminárias a partir de um modelo de domínio específico. No mundo da FP, existe o conceito de classe de tipo . Em resumo, as classes de tipos não são classes do OOP, mas algo como interfaces, elas definem algum comportamento de grupo de tipos. A diferença fundamental é que esse grupo de tipos é determinado não pela herança de classe, mas pela instanciação, como variáveis comuns. Como na herança, a resolução de instâncias de classes de tipo (via implícitas ) ocorre estaticamente , no estágio de compilação. Para simplificar, para nossos propósitos, as classes de tipo podem ser consideradas extensões do Kotlin e C # .
Para prometer um objeto, não precisamos saber o que esse objeto possui, quais campos e métodos ele possui. É importante apenas para nós que o comportamento do log com uma determinada assinatura seja definido para ele. Seria Logged implementar uma certa interface de Logged em cada classe e nem sempre é possível - por exemplo, na biblioteca ou nas classes padrão. No caso de classes tipográficas, tudo é muito mais simples. Podemos criar uma instância da Logged Logged, por exemplo, para acessórios, e exibi-la em um formato legível. E para todos os outros tipos, crie uma instância para o tipo Any e use o método toString padrão para registrar qualquer objeto em sua representação interna gratuitamente.
Um exemplo da classe Tagged e instâncias para ela trait Logged[A] { def log(a: A)(implicit logger: Logger): A }
Além do registro, podemos expandir essa abordagem para todo o processo de preparação de acessórios. A solução de teste oferecerá suas próprias classes de tempo e a implementação abstrata de funções baseadas nelas. A responsabilidade do projeto que o utiliza é escrever sua própria instância de classes de tipos para tipos.
Ao projetar o gerador de dispositivos elétricos, concentrei-me na implementação dos princípios de programação e design do SOLID como um indicador de sua estabilidade e adaptabilidade a diferentes sistemas:
- O princípio da responsabilidade única : cada classe descreve exatamente um aspecto do comportamento do tipo.
- O princípio aberto fechado : não modificamos o tipo de combate existente para testes, expandimos-no com instâncias das tyclasses.
- O Princípio de Substituição de Liskov não importa neste caso, uma vez que não usamos herança.
- O Princípio de Segregação de Interface : Usamos muitas classes de tempo especializadas em vez de uma única global.
- O princípio da inversão de dependência : A implementação do gerador de acessórios não depende de tipos de combate específicos, mas de classes de tempo abstratas.
Depois de garantir que todos os princípios sejam cumpridos, pode-se argumentar que nossa solução parece suficientemente suportável e expansível para usá-la em diferentes projetos.
Depois de escrever as funções do ciclo de vida, a geração de acessórios e a conversão de conjuntos de dados em acessórios, além de abstrair de um modelo de domínio específico do aplicativo, finalmente estamos prontos para escalar nossa solução para todos os testes.
Sumário
Passamos do estilo tradicional (passo a passo) do design de teste para o estilo funcional. Um estilo passo a passo é bom nos estágios iniciais e em pequenos projetos, pois não requer trabalho adicional e não limita o desenvolvedor, mas começa a perder quando há muitos testes no projeto. O estilo funcional não foi projetado para resolver todos os problemas dos testes, mas pode facilitar muito o dimensionamento e o suporte dos testes em projetos em que seu número é de centenas ou milhares. Os testes de estilo funcional são mais compactos e focam no que é realmente importante (dados, código de teste e resultado esperado), e não em etapas intermediárias.
Além disso, vimos um exemplo vivo de quão poderosos são os conceitos de composição e classe de tipos na programação funcional. Com a ajuda deles, é fácil projetar soluções, parte integrante das quais são extensibilidade e reutilização.
, , , . , , , -. , . !
: Github