 TL; DR
TL; DR : arquitetura cliente-servidor de nossa ferramenta de gerenciamento de configuração interna, QControl.
No seu porão, há um protocolo de transporte de duas camadas que trabalha com mensagens compactadas com gzip sem descompressão entre os pontos de extremidade. Roteadores distribuídos e pontos de extremidade recebem as atualizações de configuração, e o próprio protocolo possibilita a instalação de relés localizados intermediários. Ele é baseado em um design de
backup diferencial (“recente-estável”, explicado mais adiante) e emprega a linguagem de consulta JMESpath e o modelo Jinja para renderização da configuração.
O Qrator Labs opera e mantém uma rede de mitigação distribuída globalmente. Nossa rede é anycast, com base no anúncio de nossas sub-redes via BGP. Ser uma rede anycast BGP localizada fisicamente em várias regiões da Terra nos permite processar e filtrar o tráfego ilegítimo mais próximo do backbone da Internet - operadores de nível 1.
Por outro lado, ser uma rede geograficamente distribuída tem suas dificuldades. A comunicação entre os pontos de presença da rede (PoP) é essencial para um provedor de segurança ter uma configuração coerente para todos os nós da rede e atualizá-la de maneira oportuna e coesa. Portanto, para oferecer o melhor serviço possível aos clientes, tivemos que encontrar uma maneira de sincronizar os dados de configuração entre diferentes continentes de maneira confiável.
No começo, havia a Palavra ... que rapidamente se tornou o protocolo de comunicação que precisava de uma atualização.
O ponto principal da existência do QControl e a principal razão para gastar muito tempo e esforço na construção de um protocolo nosso é a necessidade de obter uma fonte autorizada da configuração e, eventualmente, sincronizar nossos PoPs com ela. O armazenamento foi apenas um dos vários recursos necessários do desenvolvimento do QControl. Além disso, também precisamos de integração com a periferia existente e futura, validações de dados inteligentes (e personalizáveis) e diferenciação de acesso. Além disso, queríamos que este sistema gerisse coisas através de comandos, não através de modificações manuais nos arquivos. Antes do QControl, os dados eram enviados para os pontos de presença mais ou menos manualmente. Se algum PoP estava indisponível no momento e esquecemos de atualizá-lo mais tarde, a configuração foi dessincronizada e foi necessária uma solução de problemas demorada para trazê-lo de volta à sincronização.
Aqui está o sistema que criamos:
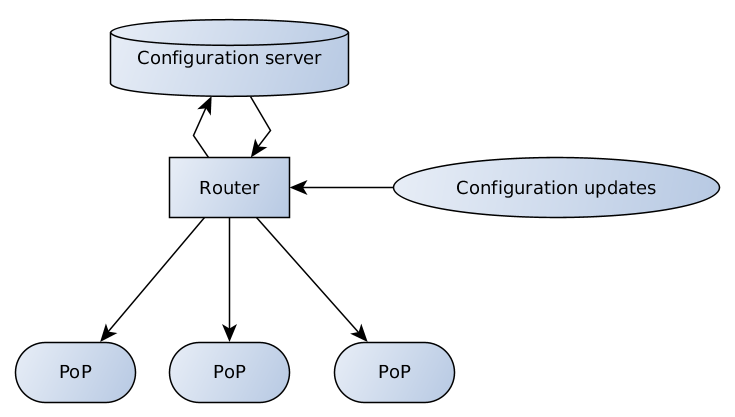
O servidor de configuração é responsável pela validação e armazenamento de dados; o roteador possui pontos de extremidade diferentes para receber e retransmitir atualizações de configuração dos clientes e da equipe de suporte ao servidor e do servidor aos PoPs.
A qualidade da conexão à Internet ainda é bastante diversificada em todo o mundo - para ilustrar isso, vamos visualizar um traceroute simples de Praga, República Tcheca a Cingapura e Hong Kong.

MTR de Praga para Singapura

Mesma segunda captura de tela com traceroute para Hong Kong
Números de alta latência significam baixa velocidade. Além disso, há uma alta perda de pacotes. Os números de largura de banda não compensam esse problema, que sempre deve ser levado em consideração ao criar redes descentralizadas.
A configuração completa do PoP é uma porção de dados bastante significativa e precisa ser transferida para muitos receptores diferentes através de conexões não confiáveis. Felizmente, embora a configuração mude com frequência, ela muda em pequenos incrementos.
Projeto estável recente
É uma decisão bastante direta construir uma rede distribuída com base em atualizações incrementais. Embora existam alguns problemas com os diffs, eles são difíceis de criar corretamente: precisamos salvar todos os diffs entre os pontos de referência em algum lugar, para poder reenviá-los se alguém perder alguma coisa. Todo destino deve aplicá-los de forma coerente. Caso haja vários destinos, isso pode levar muito tempo em toda a rede. O destinatário também deve poder solicitar peças ausentes e, é claro, a parte central deve responder a essa solicitação com precisão, enviando apenas os dados ausentes.
O que construímos no final é uma coisa - temos apenas uma camada de referência, a fixa "estável" e apenas uma diff, "recente". Todo recente é baseado no último estábulo e é suficiente para reconstruir os dados de configuração. Quando um novo recente chega ao destino, o antigo é descartável.
Às vezes, nos é necessário enviar uma nova configuração estável, porque as recentes crescem muito. Além disso, uma observação importante aqui é que podemos fazer tudo isso transmitindo / transmitindo multicast atualizações, sem nos preocupar com a capacidade de receber destinos para montar as peças. Depois de verificarmos que todos têm o estábulo certo, todos são alimentados apenas com o recente recente. Devemos dizer que funciona? Faz. Os estábulos são armazenados em cache no servidor de configuração e nos receptores, sendo os recentes recriados quando necessário.
Arquitetura de transporte em duas camadas
Por que exatamente construímos nosso transporte com duas camadas? A resposta é bem simples: queríamos dividir o roteamento do aplicativo, inspirando-nos no modelo OSI com suas camadas de transporte e aplicativo. Portanto, separamos o protocolo de transporte (Thrift) do formato de serialização de comando de alto nível (msgpack). É por isso que um roteador (que faz multicast / broadcast / retransmissão) nem olha dentro do msgpack, nem extrai ou comprime a carga útil e faz apenas a transmissão.
Wiki Thrift:
O Apache Thrift permite definir tipos de dados e interfaces de serviço em um arquivo de definição simples. Tomando esse arquivo como entrada, o compilador gera código a ser usado para criar facilmente clientes e servidores RPC que se comunicam sem interrupções nas linguagens de programação. Em vez de escrever uma carga de código padrão para serializar e transportar seus objetos e chamar métodos remotos.Adotamos a estrutura Thrift por causa de seu RPC e suporte a vários idiomas ao mesmo tempo. Como sempre, as partes fáceis são fáceis de construir: o cliente e o servidor. No entanto, o roteador era muito difícil de quebrar, em parte devido à ausência de uma solução pronta para uso no momento.

Existem outras opções, como o protobuf / gRPC, mas quando começamos o projeto, o gRPC era imaturo e hesitamos em usá-lo.
Obviamente, nós poderíamos (e deveríamos!) Criar nossa própria roda. Seria mais fácil criar um protocolo personalizado para o que precisamos, juntamente com o roteador, porque o cliente-servidor é mais simples de programar do que criar um roteador funcional com o Thrift. No entanto, há uma negatividade tradicional em relação a protocolos e implementações personalizadas de bibliotecas populares, e sempre há o "como podemos portá-lo posteriormente para outros idiomas". Por isso, decidimos abandonar as ideias indecorosas.
Descrição do Msgpack:
MessagePack é um formato eficiente de serialização binária. Permite trocar dados entre vários idiomas, como JSON. Mas é mais rápido e menor. Inteiros pequenos são codificados em um único byte, e cadeias curtas típicas requerem apenas um byte extra, além das próprias cadeias.Na primeira camada, temos um Thrift com as informações mínimas necessárias para o roteador enviar uma mensagem. Na segunda camada, nós compactamos as estruturas do msgpack.
Votamos no msgpack porque é mais rápido e mais compacto em comparação com o JSON. No entanto, o que é ainda mais importante é que ele suporta tipos de dados personalizados, permitindo alguns recursos interessantes, como "apagões" e transferência de dados binários brutos.
JmespathJMESPath é uma linguagem de consulta para JSON.Essa é a única descrição que obtemos da documentação oficial do JMESPath, mas, na verdade, é muito mais do que isso. O JMESPath permite pesquisar e filtrar estruturas arbitrárias do tipo árvore e até aplicar transformações de dados em tempo real. Usamos essa linguagem de consulta para obter informações relevantes do grande blob de configuração.
Embora toda a configuração tenha uma estrutura semelhante a uma árvore, extraímos as subárvores relevantes para diferentes destinos de configuração.
Também é flexível o suficiente para alterar a subárvore, independentemente de um modelo de configuração ou de outros plugins de configuração. Para torná-lo ainda melhor, o JMES Path é facilmente extensível e permite gravar filtros personalizados e rotinas de transformação de dados. No entanto, ele precisa de algum poder intelectual para compreender.
JinjaPara alguns destinos, precisamos renderizar a configuração em arquivos; portanto, precisamos de um mecanismo de modelo, onde o Jinja é uma escolha óbvia. O Jinja está gerando um arquivo de configuração a partir do modelo e dos dados recebidos no ponto de destino.
Para renderizar o arquivo de configuração, precisamos de uma solicitação jmespath, modelo para o caminho e arquivo de destino, modelo para a própria configuração. Além disso, neste momento, é bom especificar os direitos de acesso ao arquivo. Felizmente, tudo isso foi combinado em um arquivo - antes do modelo de configuração, colocamos um cabeçalho YAML, descrevendo o restante. Por exemplo:
---
selector: "[@][?@.fft._meta.version == `42`] | items([0].fft_config || `{}`)"
destination_filename: "fft/{{ match[0] }}.json"
file_mode: 0644
reload_daemons: [fft]
...
{{ dict(match[1]) | json(indent=2, sort_keys=True) }}
Para fazer a configuração de uma nova periferia, adicionamos um novo arquivo de modelo, nenhuma alteração no código fonte e atualizações de software PoP são necessárias.
O que mudou após a implementação da ferramenta de gerenciamento de configuração QControl?
Em primeiro lugar, recebemos atualizações de configuração coerentes e confiáveis em toda a nossa rede.
Segundo, colocamos uma ferramenta poderosa para validação de configuração e alterações nas mãos de nossa equipe de suporte e de nossos clientes.
Conseguimos isso empregando um design estável recente para simplificar a comunicação entre o servidor de configuração e os destinatários da configuração, usando o protocolo de comunicação de duas camadas para oferecer suporte a roteadores independentes de carga útil e implementando o mecanismo de renderização de configuração baseado em Jinja para suportar uma grande variedade de arquivos de configuração para nossa periferia diversificada.