 TL; DR
TL; DR : Descrição da arquitetura cliente-servidor do nosso sistema interno de gerenciamento de configuração de rede, QControl. Ele é baseado em um protocolo de transporte de dois níveis que funciona com mensagens compactadas em gzip sem descompactação entre os pontos de extremidade. Roteadores distribuídos e pontos de extremidade recebem atualizações de configuração, e o próprio protocolo permite a instalação de relés intermediários localizados. O sistema é construído com base no princípio do
backup diferencial (“recente-estável”, explicado abaixo) e usa a linguagem de consulta JMESpath junto com o mecanismo de modelo Jinja para renderizar arquivos de configuração.
O Qrator Labs gerencia uma rede de mitigação de ataques distribuída globalmente. Nossa rede trabalha com o princípio de anycast, e as sub-redes são anunciadas via BGP. Sendo uma rede anycast BGP localizada fisicamente em várias regiões da Terra, podemos processar e filtrar o tráfego ilegítimo mais próximo do núcleo da Internet - operadores de nível 1.
Por outro lado, ser uma rede distribuída geograficamente não é fácil. A comunicação entre os pontos de presença da rede é fundamental para um provedor de serviços de segurança, a fim de ter uma configuração consistente de todos os nós da rede, atualizando-os em tempo hábil. Portanto, para fornecer o nível mais alto possível de serviços básicos para os consumidores, precisávamos encontrar uma maneira de sincronizar de forma confiável os dados de configuração entre os continentes.
No começo era a Palavra. Ele rapidamente se tornou um protocolo de comunicação que precisava de uma atualização.
A pedra angular da existência do QControl e, ao mesmo tempo, o principal motivo para gastar uma quantidade significativa de tempo e recursos para construir esse protocolo é a necessidade de obter uma única fonte autorizada de configuração e, finalmente, sincronizar nossos pontos de presença com ele. O próprio repositório foi apenas um dos vários requisitos durante o desenvolvimento do QControl. Além disso, também precisávamos de integração com os serviços existentes e planejados nos pontos de presença (TP), métodos inteligentes (e personalizáveis) de validação de dados e controle de acesso. Além disso, também queríamos gerenciar esse sistema usando comandos, em vez de fazer modificações nos arquivos. Antes do QControl, os dados eram enviados para pontos de presença no modo quase manual. Se um dos pontos de presença não estivesse disponível e esquecemos de atualizá-lo mais tarde, a configuração estava fora de sincronia - você precisou gastar algum tempo retornando-o ao serviço.
Como resultado, criamos o seguinte esquema:
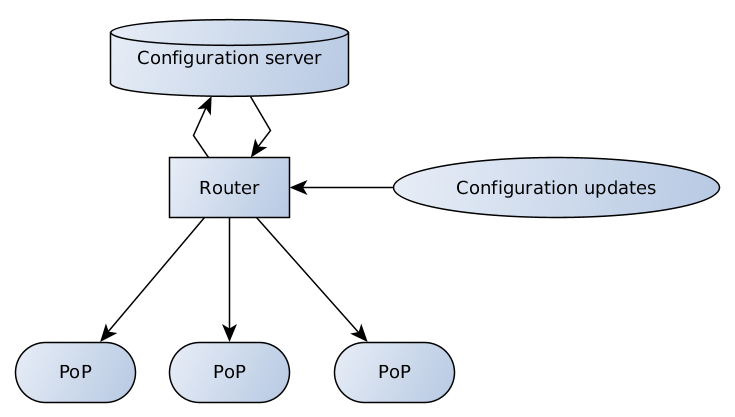
O servidor de configuração é responsável pela validação e armazenamento de dados, o roteador possui vários pontos de extremidade que recebem e transmitem atualizações de configuração de clientes e equipes de suporte ao servidor e do servidor para pontos de presença.
A qualidade da conexão à Internet ainda é significativamente diferente em diferentes partes do mundo - para ilustrar esta tese, vejamos um MTR simples de Praga, República Tcheca, Cingapura e Hong Kong.

MTR de Praga para Singapura

A mesma coisa para Hong Kong
Atrasos altos significam menos velocidade. Além disso, há perda de pacotes. A largura dos canais não compensa esse problema, que sempre deve ser levado em consideração ao criar sistemas descentralizados.
Uma configuração completa do ponto de presença é uma quantidade significativa de dados que precisa ser enviada a muitos destinatários por meio de conexões não confiáveis. Felizmente, embora a configuração esteja constantemente mudando, isso acontece em pequenas porções.
Projeto estável recente
Podemos dizer que construir uma rede distribuída com base no princípio de atualizações incrementais é uma solução bastante óbvia. Mas há muitos problemas com diffs. Precisamos manter todas as diferenças entre os pontos de controle e poder enviá-las caso alguém perca alguns dados. Cada destino deve aplicá-los em uma sequência estritamente definida. Normalmente, no caso de vários destinos, essa operação pode levar muito tempo. O destinatário também deve poder solicitar as partes ausentes e, é claro, a parte central deve responder a essa solicitação corretamente, enviando apenas os dados ausentes.
Como resultado, chegamos a uma solução bastante interessante - temos apenas uma camada de suporte, fixa, vamos chamá-la estável, e apenas uma diferença por ser recente. Cada recente é baseado no último estábulo formado e é suficiente para reconstruir os dados de configuração. Assim que um novo recente chega ao seu destino, o antigo não é mais necessário.
Ocasionalmente, envia periodicamente uma nova configuração estável, por exemplo, devido ao fato de as recentes terem se tornado muito grandes. Também é importante aqui enviarmos todas essas atualizações no modo de difusão / difusão seletiva, sem nos preocuparmos com os destinatários individuais e sua capacidade de coletar dados juntos. Assim que estamos convencidos de que todos têm o estábulo correto, enviamos apenas os novos mais recentes. Vale a pena esclarecer que isso funciona? Isso funciona. Estável é armazenado em cache no servidor de configuração e nos destinatários; recente é criado conforme necessário.
Arquitetura de transporte em dois níveis
Por que construímos nosso transporte em dois níveis? A resposta é bastante simples - queríamos separar o roteamento da lógica de alto nível, inspirando-se no modelo OSI com sua camada de transporte e camada de aplicação. Tomámos o Thrift como protocolo de transporte e o formato de serialização msgpack para o formato de mensagem de controle de alto nível. É por isso que o roteador (executando multicast / broadcast / retransmissão) não olha dentro do msgpack, não descompacta e não empacota o conteúdo de volta, e apenas realiza a transferência de dados.
O Thrift (do inglês - “thrift”, pronunciado [θrift]) é uma linguagem de descrição de interface usada para definir e criar serviços para diferentes linguagens de programação. É uma estrutura para chamada de procedimento remoto (RPC). Ele combina um pipeline de software com um mecanismo de geração de código para o desenvolvimento de serviços que, em um grau ou outro, funcionam de maneira eficiente e fácil entre idiomas.Adotamos a estrutura Thrift por causa do RPC e suporte para vários idiomas. Como sempre, o cliente e o servidor são as partes fáceis. No entanto, o roteador acabou por ser um osso duro de roer, em parte devido à falta de uma solução pronta durante o nosso desenvolvimento.

Existem outras opções, como protobuf / gRPC, no entanto, quando iniciamos nosso projeto, o gRPC era bastante jovem e não ousamos aceitá-lo.
É claro que poderíamos (e de fato valeu a pena) criar nossa própria bicicleta. Seria mais fácil criar um protocolo para o que precisamos, porque a arquitetura cliente-servidor é relativamente direta na implementação em comparação com a construção de um roteador no Thrift. De uma forma ou de outra, existe uma atitude preconceituosa tradicional em relação aos protocolos e implementações auto-escritas de bibliotecas populares (não em vão); além disso, a discussão sempre levanta a questão: "Como vamos portá-la para outros idiomas?" Portanto, imediatamente lançamos idéias sobre a bicicleta.
Msgpack é um análogo do JSON, mas mais rápido e menos. Este é um formato de serialização de dados binários que permite a troca de dados entre vários idiomas.No primeiro nível, temos o Thrift com as informações mínimas necessárias para o roteador encaminhar a mensagem. No segundo nível, estão estruturas empacotadas do msgpack.
Escolhemos o msgpack porque é mais rápido e mais compacto em comparação com o JSON. Mais importante, porém, ele suporta tipos de dados personalizados, permitindo o uso de recursos interessantes, como a transferência de binários brutos ou objetos especiais, indicando a falta de dados, o que foi importante para o nosso recente esquema estável.
JmespathJMESPath é uma linguagem de solicitação JSON.É exatamente assim que a descrição se parece, que obtemos da documentação oficial do JMESPath, mas, na verdade, fornece muito mais. O JMESPath permite pesquisar e filtrar subárvores em uma estrutura de árvore arbitrária, bem como aplicar alterações nos dados em tempo real. Também permite adicionar filtros especiais e procedimentos de conversão de dados. Embora, é claro, exija tensão cerebral para entender.
JinjaPara alguns consumidores, precisamos transformar a configuração em um arquivo - portanto, usamos o mecanismo de modelo e o Jinja é a escolha óbvia. Com sua ajuda, geramos um arquivo de configuração a partir do modelo e dos dados recebidos no destino.
Para gerar o arquivo de configuração, precisamos de uma solicitação JMESPath, um modelo para o local do arquivo no FS, um modelo para a própria configuração. Também nesta fase, é bom esclarecer as permissões de arquivo. Tudo isso foi combinado com sucesso em um arquivo - antes do início do modelo de configuração, colocamos o cabeçalho no formato YAML, que descreve o restante.
Por exemplo:
---
selector: "[@][?@.fft._meta.version == `42`] | items([0].fft_config || `{}`)"
destination_filename: "fft/{{ match[0] }}.json"
file_mode: 0644
reload_daemons: [fft]
...
{{ dict(match[1]) | json(indent=2, sort_keys=True) }}
Para criar um arquivo de configuração para um novo serviço, adicionamos apenas um novo arquivo de modelo. Não são necessárias alterações no código-fonte ou no software nos pontos de presença.
O que mudou desde que o QControl foi introduzido nas operações? A primeira e mais importante é a entrega consistente e confiável de atualizações de configuração em todos os nós da rede. O segundo é obter uma poderosa ferramenta de verificação de configuração e fazer alterações na nossa equipe de suporte, bem como nos consumidores do serviço.
Conseguimos fazer tudo isso usando o esquema de atualização estável recente para simplificar a comunicação entre o servidor de configuração e os destinatários da configuração. Usando um protocolo de duas camadas para oferecer suporte a um método de roteamento de dados independente de conteúdo. Tendo integrado com êxito o mecanismo de geração de configuração baseado em Jinja em uma rede de filtragem distribuída. Este sistema suporta uma ampla variedade de métodos de configuração para nossos periféricos distribuídos e variados.
Obrigado por escrever material, graças a
VolanDamrod ,
serenheit ,
NoN .
Versão em inglês do post.