
Alguns anos atrás, no Badoo, começamos a usar a abordagem MVI para o desenvolvimento do Android. O objetivo era simplificar uma base de código complexa e evitar o problema de estados incorretos: em cenários simples, é fácil, mas quanto mais complexo o sistema, mais difícil é mantê-lo na forma correta e mais fácil é perder um bug.
No Badoo, todos os aplicativos são assíncronos - não apenas devido à ampla funcionalidade disponível ao usuário por meio da interface do usuário, mas também pela possibilidade de envio de dados unidirecionais pelo servidor. Usando a abordagem antiga em nosso módulo de bate-papo, encontramos vários bugs estranhos, difíceis de reproduzir, que precisávamos gastar muito tempo para eliminar.
Nosso colega Zsolt Kocsi (
Medium ,
Twitter ) do escritório de Londres contou como o uso do MVI criamos componentes independentes que são fáceis de reutilizar, que vantagens obtemos e que desvantagens encontramos ao usar essa abordagem.
Este é o terceiro artigo de uma série de artigos sobre a arquitetura do Badoo Android. Links para os dois primeiros:
- Arquitetura moderna de MVI baseada em Kotlin .
- Construindo um sistema de componentes reativos com o Kotlin .
Não fique com componentes mal conectados.
Conectividade fraca é considerada melhor que forte. Se você confiar apenas em interfaces e não em implementações específicas, será mais fácil substituir componentes, será mais fácil alternar para outras implementações sem reescrever a maior parte do código, o que simplifica a inclusão de testes de unidade.
Geralmente terminamos aqui e dizemos que fizemos todo o possível em termos de conectividade.
No entanto, essa abordagem não é ótima. Suponha que você tenha uma classe A que precise usar os recursos de três outras classes: B, C e D. Mesmo que você as refira através de interfaces, a classe A fica mais difícil com cada uma dessas classes:
- ele conhece todos os métodos em todas as interfaces, seus nomes e tipos de retorno, mesmo que ele não os use;
- ao testar A, você precisa configurar mais zombarias ( objeto simulado );
- é mais difícil usar A repetidamente em outros contextos em que não temos ou não queremos ter B, C e D.
Obviamente, é precisamente a classe A que deve determinar o conjunto mínimo de interfaces necessárias (princípio de segregação de interface do
SOLID ). No entanto, na prática, todos tivemos que lidar com situações em que, por uma questão de conveniência, foi adotada uma abordagem diferente: pegamos uma classe existente que implementa alguma funcionalidade, extraímos todos os seus métodos públicos para a interface e depois usamos essa interface onde a classe mencionada era necessária. Ou seja, a interface foi usada não com base no que esse componente é necessário, mas com base no que outro componente pode oferecer.
Com essa abordagem, a situação piora com o tempo. Sempre que adicionamos novas funcionalidades, nossas classes são vinculadas a uma rede de novas interfaces que eles precisam conhecer. As aulas estão crescendo em tamanho e os testes estão se tornando cada vez mais difíceis.
Como resultado, quando você precisar usá-los em um contexto diferente, será quase impossível movê-los sem todo esse emaranhado com o qual eles estão conectados, mesmo através de interfaces. Você pode fazer uma analogia: você quer usar uma banana, e ela está nas mãos de um macaco que fica pendurado em uma árvore; portanto, na carga da banana, você terá um pedaço inteiro da selva. Em resumo, o processo de transferência leva muito tempo e logo você começa a se perguntar por que, na prática, é tão difícil reutilizar o código.
Componentes da caixa preta
Se queremos que o componente seja fácil e reutilizável, para isso não precisamos saber sobre duas coisas:
- sobre onde mais ele é usado;
- sobre outros componentes que não estão relacionados à sua implementação interna.
A razão é clara: se você não conhece o mundo exterior, não estará conectado a ele.
O que realmente queremos do componente:
- definir seus próprios dados de entrada (entrada) e saída (saída);
- Não pense de onde esses dados vêm ou para onde vão;
- deve ser auto-suficiente para que não precisemos conhecer a estrutura interna do componente para seu uso.
Você pode considerar o componente como uma caixa preta ou um circuito integrado. Ela tem contatos de entrada e saída. Você os solda - e o microcircuito se torna parte de um sistema que não conhece nada.

Até agora, supunha-se que estamos falando de fluxos de dados bidirecionais: se a classe A precisar de algo, extrai um método pela interface B e recebe o resultado na forma do valor retornado pela função.

Mas então A sabe sobre B, e queremos evitar isso.
Obviamente, esse esquema faz sentido para os recursos de implementação de baixo nível. Mas se precisarmos de um componente reutilizável que funcione como uma caixa preta independente, precisamos garantir que ele não saiba nada sobre interfaces externas, nomes de métodos ou valores de retorno.
Passamos à unidirecionalidade
Mas sem nomes e métodos de interface, não podemos chamar nada! Tudo o que resta é usar um fluxo de dados unidirecional, no qual simplesmente obtemos entrada e geramos saída:

A princípio, isso pode parecer uma limitação, mas essa solução tem muitas vantagens, que serão discutidas abaixo.
Desde o
primeiro artigo , sabemos que os recursos (Recurso) definem seus próprios dados de entrada (Desejo) e seus próprios dados de saída (Estado). Portanto, não importa para eles de onde vem o Desejo ou para onde vai o Estado.
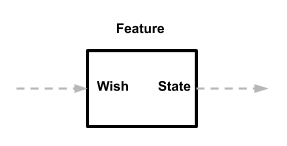
É disso que precisamos! Os recursos podem ser usados onde quer que você possa dar entrada e, com a saída, você pode fazer o que quiser. E como os recursos não se comunicam diretamente com outros componentes, são módulos independentes e não relacionados.
Agora pegue o View e projete-o para que ele também seja um módulo independente.
Primeiro, o View deve ser o mais simples possível, para que ele possa lidar apenas com suas tarefas internas.
Que tipo de tarefas? Existem dois deles:
- renderizando ViewModel (entrada);
- acionando ViewEvents dependendo das ações do usuário (saída).
Por que usar o ViewModel? Por que não desenhar diretamente o estado do recurso?
- (Não) exibir um recurso na tela não faz parte da implementação. O View deve ser capaz de renderizar-se se os dados vierem de várias fontes.
- Não há necessidade de refletir a complexidade do estado na Visualização. O ViewModel deve conter apenas as informações prontas para exibição necessárias para mantê-las simples.
Além disso, o View não deve se interessar pelo seguinte:
- de onde vêm todos esses ViewModels;
- o que acontece quando o ViewEvent é acionado;
- qualquer lógica de negócios;
- rastreamento analítico;
- diário
- outras tarefas.
Todas essas são tarefas externas e o View não deve estar conectado a elas. Vamos parar e resumir a simplicidade da exibição:
interface FooView : Consumer<ViewModel>, ObservableSource<Event> { data class ViewModel( val title: String, val bgColor: Int ) sealed class Event { object ButtonClicked : Event() data class TextFocusChanged(val hasFocus: Boolean) : Event() } }
Uma implementação do Android deve:
- Encontre visualizações do Android por seu ID.
- Implemente o método de aceitação da interface do consumidor, definindo o valor no ViewModel.
- Defina ouvintes (ClickListeners) para interagir com a interface do usuário para gerar eventos específicos.
Um exemplo:
class FooViewImpl @JvmOverloads constructor( context: Context, attrs: AttributeSet? = null, defStyle: Int = 0, private val events: PublishRelay<Event> = PublishRelay.create<Event>() ) : LinearLayout(context, attrs, defStyle), FooView,
Se não estiver limitado a Feature e View, eis a aparência de qualquer outro componente com esta abordagem:
interface GenericBlackBoxComponent : Consumer<Input>, ObservableSource<Output> { sealed class Input sealed class Output }
Agora tudo está claro com o padrão!

Unir, unir, unir!
Mas e se tivermos componentes diferentes e cada um deles tiver sua própria entrada e saída? Vamos conectá-los!
Felizmente, isso pode ser feito facilmente usando o Binder, o que também ajuda a criar o escopo correto, como sabemos no
segundo artigo :
A primeira vantagem: fácil de expandir sem modificações
O uso de componentes não relacionados na forma de caixas pretas que são conectadas apenas temporariamente permite adicionar novas funcionalidades sem modificar os componentes existentes.
Veja um exemplo simples:

Aqui, os recursos (F) e o View (V) são simplesmente conectados um ao outro.
As ligações correspondentes serão:
bind(feature to view using stateToViewModelTransformer) bind(view to feature using uiEventToWishTransformer)
Suponha que desejemos adicionar o rastreamento de alguns eventos da interface do usuário a este sistema.
internal object AnalyticsTracker : Consumer<AnalyticsTracker.Event> { sealed class Event { object ProfileImageClicked: Event() object EditButtonClicked : Event() } override fun accept(event: AnalyticsTracker.Event) {
A boa notícia é que podemos fazer isso simplesmente reutilizando o canal de visualização de saída existente:

No código, fica assim:
bind(feature to view using stateToViewModelTransformer) bind(view to feature using uiEventToWishTransformer)
Novas funcionalidades podem ser adicionadas com apenas uma linha de ligação adicional. Agora, não podemos apenas não alterar uma única linha de código View, mas nem sabemos que a saída é usada para resolver um novo problema.
Obviamente, agora é mais fácil evitar preocupações adicionais e componentes desnecessariamente complicados. Eles permanecem simples. Você pode adicionar funcionalidade ao sistema simplesmente conectando componentes aos já existentes.
Segunda vantagem: fácil de usar repetidamente
Usando o exemplo de Feature e View, pode-se ver claramente que podemos adicionar uma nova fonte de entrada ou consumidor de dados de saída com apenas uma linha com ligação. Isso facilita muito a reutilização de componentes em diferentes partes do aplicativo.
No entanto, essa abordagem não se limita às classes. Essa maneira de usar interfaces nos permite descrever componentes reativos independentes de qualquer tamanho.
Ao nos limitarmos a determinados dados de entrada e saída, nos livramos da necessidade de saber como tudo funciona sob o capô e, portanto, evitamos facilmente vincular acidentalmente os componentes internos dos componentes com outras partes do sistema. E sem encadernação, você pode facilmente e simplesmente usar componentes repetidamente.
Voltaremos a isso em um dos artigos a seguir e consideraremos exemplos do uso dessa técnica para conectar componentes de nível superior.
Primeira pergunta: onde colocar as ligações?
- Escolha o nível de abstração. Dependendo da arquitetura, isso pode ser uma Atividade, um fragmento ou algum ViewController. Espero que você ainda tenha algum nível de abstração nas partes em que não há interface do usuário. Por exemplo, em alguns dos escopos da árvore de contexto de DI.
- Crie uma classe separada para a ligação no mesmo nível que esta parte da interface do usuário. Se for FooActivity, FooFragment ou FooViewController, você poderá colocar FooBindings ao lado dele.
- Certifique-se de incorporar FooBindings nas mesmas instâncias de componente usadas na atividade, fragmento etc.
- Para formar o escopo das ligações, use o Ciclo de Vida da Atividade ou Fragmento. Se esse loop não estiver vinculado ao Android, você poderá criar gatilhos manualmente, por exemplo, ao criar ou destruir um escopo de DI. Outros exemplos de escopo são descritos no segundo artigo .
Segunda pergunta: testing
Como nosso componente não sabe nada sobre os outros, geralmente não precisamos de stubs. Os testes são simplificados para verificar a resposta correta do componente aos dados de entrada e produzir os resultados esperados.
No caso do Feature, isso significa:
- a capacidade de testar se determinados dados de entrada geram o estado esperado (saída).
E no caso do View:
- podemos testar se um determinado ViewModel (entrada) leva ao estado esperado da interface do usuário;
- podemos testar se a simulação de interação com a interface do usuário leva à inicialização no ViewEvent (saída) esperado.
Obviamente, as interações entre componentes não desaparecem magicamente. Acabamos de extrair essas tarefas dos próprios componentes. Eles ainda precisam ser testados. Mas onde?
No nosso caso, o Binders é responsável por conectar os componentes:
Nossos testes devem confirmar o seguinte:
1. Transformadores (mapeadores).
Algumas conexões possuem mapeadores e você precisa garantir que eles convertam corretamente os elementos. Na maioria dos casos, um teste de unidade muito simples é suficiente para isso, pois os mapeadores geralmente também são muito simples:
@Test fun testCase1() { val transformer = Transformer() val testInput = TODO() val actualOutput = transformer.invoke(testInput) val expectedOutput = TODO() assertEquals(expectedOutput, actualOutput) }
2. Comunicação.
Você precisa garantir que as conexões estejam configuradas corretamente. Qual é o objetivo do trabalho de componentes e mapeadores individuais, se por algum motivo a conexão entre eles não tiver sido estabelecida? Tudo isso pode ser testado configurando o ambiente de ligação com stubs, fontes de inicialização e verificando se os resultados esperados são recebidos no lado do cliente:
class BindingEnvironmentTest { lateinit var component1: ObservableSource<Component1.Output> lateinit var component2: Consumer<Component2.Input> lateinit var bindings: BindingEnvironment @Before fun setUp() { val component1 = PublishRelay.create() val component2 = mock() val bindings = BindingEnvironment(component1, component2) } @Test fun testBindings() { val simulatedOutputOnLeftSide = TODO() val expectedInputOnRightSide = TODO() component1.accept(simulatedOutputOnLeftSide) verify(component2).accept(expectedInputOnRightSide) } }
E, embora para testar você precise escrever sobre a mesma quantidade de código que em outras abordagens, no entanto, componentes autossuficientes facilitam o teste de partes individuais, pois as tarefas são claramente separadas.
Alimento para o pensamento
Embora a descrição do nosso sistema na forma de um gráfico de caixas pretas seja boa para o entendimento geral, isso só funciona desde que o tamanho do sistema seja relativamente pequeno.
Cinco a oito linhas de ligação são aceitáveis. Mas, tendo conectado mais, será bastante difícil entender o que está acontecendo:
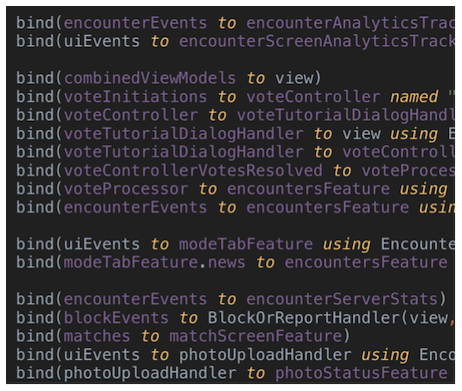

Fomos confrontados com o fato de que, com um aumento no número de links (havia ainda mais do que no fragmento de código apresentado), a situação se tornou ainda mais complicada. O motivo não estava apenas no número de linhas - algum tipo de ligação poderia ser agrupado e extraído para diferentes métodos - mas também porque se tornou cada vez mais difícil manter tudo à vista. E este é sempre um mau sinal. Se dezenas de componentes diferentes estão localizados no mesmo nível, é impossível imaginar todas as interações possíveis.
O motivo é o uso de componentes - caixas pretas ou algo mais?
Obviamente, se o escopo que você está descrevendo for inicialmente complexo, nenhuma abordagem o salvará do problema mencionado até você dividir o sistema em partes menores. Vai ser complicado, mesmo sem uma lista enorme de ligações, simplesmente não será tão óbvio. Além disso, é muito melhor se a complexidade for expressa explicitamente e não oculta. É melhor ver uma lista crescente de junções de linha única que lembram quantos componentes individuais você tem que desconhecem sobre esses links ocultos nas classes em diferentes chamadas de método.
Como os componentes são simples (são caixas pretas e processos adicionais não fluem para eles), é mais fácil separá-los, o que significa que este é um passo na direção certa. Mudamos a dificuldade para um lugar - para a lista de ligações, um olhar que permite avaliar a situação geral e começar a pensar em como sair dessa bagunça.
Encontrar uma solução nos levou muito tempo e ainda está em andamento. Planejamos falar sobre como lidar com esse problema nos seguintes artigos. Fique em contato!