
Uma das tarefas mais importantes no aprendizado de máquina é a detecção de objetos. Recentemente, uma série de algoritmos de aprendizado de máquina baseados no Deep Learning para detecção de objetos foi publicada. Esses algoritmos ocupam um dos lugares centrais em aplicações práticas de visão computacional, em particular, os atualmente populares carros autônomos. Mas todos esses métodos são métodos de ensino com um professor, ou seja, eles precisam de um grande conjunto de dados (grande conjunto de dados). Naturalmente, existe um desejo de ter um modelo capaz de aprender com dados "brutos" (não alocados). Tentei analisar os métodos existentes e também indicar possíveis formas de desenvolvimento. Peço a todos que desejam misericórdia sob kat, será interessante.
Status atual da pergunta
Naturalmente, a formulação desse problema existe há muito tempo (quase desde os primeiros dias da existência do aprendizado de máquina) e há um número suficiente de trabalhos sobre esse tópico. Por exemplo, um dos meus
detectores de objetos não supervisionados espacialmente invariantes favoritos
com redes neurais convolucionais . Em resumo, os autores estão treinando o Variable Auto Encoder (VAE), mas essa abordagem levanta várias questões para mim.
Um pouco de filosofia
Então, o que é um objeto em uma imagem? Para responder a essa pergunta, precisamos responder à pergunta - por que dividimos o mundo em objetos? Após uma pequena reflexão sobre essa questão, eu tive apenas uma resposta para ela (não estou dizendo que não há outras, apenas não as encontrei) - estamos tentando encontrar uma representação do mundo que seja fácil para entender e controlar a quantidade de informações necessárias para descrever o mundo. no contexto da tarefa atual. Por exemplo, para a tarefa de classificar imagens (que geralmente é formulada incorretamente - raramente existem imagens com um objeto. Ou seja, resolvemos o problema não o que é mostrado na figura, mas qual objeto é "principal"), basta dizer que a figura é "carro" por sua vez, para a tarefa de detectar objetos, queremos saber quais objetos "interessantes" (não estamos interessados em todas as folhas das árvores da foto) existem e onde eles estão, para a tarefa de descrever a cena, queremos obter o nome do processo "interessante" acontece lá, por exemplo, "pôr do sol" etc.
Acontece que os objetos são uma representação conveniente dos dados. Quais propriedades essa representação deve ter? A visualização deve conter o máximo possível de informações completas sobre a imagem. I.e. Com uma descrição do objeto, queremos restaurar a imagem original com o grau de precisão necessário.
Como isso pode ser expresso matematicamente? Imagine que a imagem é a realização de uma variável aleatória X, e a representação será a realização de uma variável aleatória Y. Tendo em vista o exposto, queremos que Y contenha o máximo de informações possível sobre X. Naturalmente, para isso, use o conceito de informação mútua.
Modelos de aprendizado de máquina para obter o máximo de informações
A detecção de objetos pode ser considerada como um modelo generativo, que recebe uma imagem na entrada
, e a saída é uma representação de objeto da imagem
.

Vamos agora lembrar a fórmula para calcular informações mútuas:
onde
distribuição da densidade articular também
marginalizado.
Aqui não irei aprofundar o porquê dessa fórmula ser assim, mas acreditaremos que internamente é muito lógico. A propósito, com base nas considerações descritas, não é necessário escolher exatamente informações mútuas, elas podem ser outras "informações", mas retornaremos a isso mais perto do fim.
Particularmente atencioso (ou aqueles que lêem livros sobre a teoria da informação) já notaram que a informação mútua nada mais é do que a divergência de Kullback-Lebler entre a distribuição conjunta e o trabalho dos marginais. Aqui surge uma pequena complicação - qualquer pessoa que tenha lido pelo menos alguns livros sobre aprendizado de máquina sabe que, se tivermos apenas amostras de duas distribuições (ou seja, não conhecemos as funções de distribuição), isso nem será otimizado, mas até avaliar a divergência de Kullback, A tarefa de Leibler é muito não trivial. Além disso, nossos amados GANs nasceram precisamente por esse motivo.
Felizmente, a maravilhosa idéia de usar o limite variacional mais baixo descrito em
Em limites variacionais de informações mútuas vem em nosso auxílio. Informações mútuas podem ser representadas como:
Ou
onde
- a distribuição da representação para uma determinada imagem, parametrizada por nossa grade neural e, a partir dessa distribuição, podemos amostrar, mas não precisamos ser capazes de estimar a densidade ou probabilidade de uma amostra específica (geralmente típica de muitos modelos generativos).
É uma função de certa densidade parametrizada pela segunda rede neural (no caso mais geral, precisamos de 2 redes neurais, embora em alguns casos elas possam ser representadas pela primeira), aqui devemos poder calcular as probabilidades das amostras resultantes.
Valor
chamado limite inferior variacional.
Agora podemos resolver a abordagem do nosso problema, a saber, aumentar não a informação mútua em si, mas seu limite variacional mais baixo. Se a distribuição
escolhido corretamente, então no ponto máximo do limite variacional e da informação mútua coincidirá, mas no caso prático (quando a distribuição
não consigo imaginar exatamente
, mas consiste em uma família bastante grande de funções) será muito próxima, o que também nos convém.
Se alguém não souber como isso funciona, recomendo que você considere cuidadosamente o algoritmo EM. Aqui está um caso completamente semelhante.
O que está acontecendo aqui? De fato, temos a funcionalidade para treinar o codificador automático. Se Y é o resultado na saída de uma rede neural com alguma imagem na entrada, isso significa que
onde
função de transformação de rede neural. E aproximar a distribuição inversa por gaussiana, ou seja,
nós obtemos:
E esse é um recurso clássico para codificador automático.
Codificador automático não é suficiente
Eu acho que muitos já querem treinar o codificador automático e esperam que em sua camada oculta haja neurônios que respondam a objetos específicos. Em geral, há confirmação de algo semelhante e acontece a
criação de recursos de alto nível usando o aprendizado não supervisionado em larga escala . Mas ainda assim isso é completamente impraticável. E as pessoas mais atentas já notaram que os autores deste artigo usavam regularização - adicionaram um termo que fornece escassez na camada oculta e escreveram em preto e branco que nada disso acontece sem esse termo.
O princípio de maximizar informações mútuas é suficiente para aprender uma idéia "conveniente"? Obviamente, não, porque podemos escolher Y igual a X (ou seja, usar a própria imagem como sua representação) ou qualquer transformação bijetiva, a informação mútua chega ao infinito neste caso. Não pode haver mais desse valor, mas, como sabemos, é uma péssima idéia.
Precisamos de um critério adicional para a "conveniência" da apresentação. Os autores do artigo acima consideraram a escassez como "conveniência". Este é um tipo de realização da hipótese de que deve haver alguns "objetos importantes" na imagem. Mas iremos mais além - queremos não apenas aprender o fato de que esse objeto está na imagem, mas também queremos saber onde ele está, quanto é sobreposto, etc. Surge a questão: como fazer a rede neural interpretar a saída de um neurônio como, por exemplo, a coordenada de um objeto? A resposta é óbvia - a saída desse neurônio deve ser usada precisamente para isso. Ou seja, conhecendo a idéia, devemos ser capazes de gerar imagens "semelhantes" à original.
A idéia geral foi emprestada dos caras do Facebook.
O codificador terá a seguinte aparência:

onde
- algum vetor descrevendo o objeto,
- coordenadas do objeto,
- a escala do objeto,
- a posição do objeto em profundidade,
- a probabilidade de o objeto estar presente.
Ou seja, a rede neural de entrada recebe uma imagem de um tamanho predeterminado no qual queremos encontrar objetos e emite uma série de descrições. Se queremos uma rede de passagem única, infelizmente essa matriz terá que ter um tamanho fixo. Se quisermos encontrar todos os objetos, teremos que usar redes de recrutamento.
O decodificador será assim:
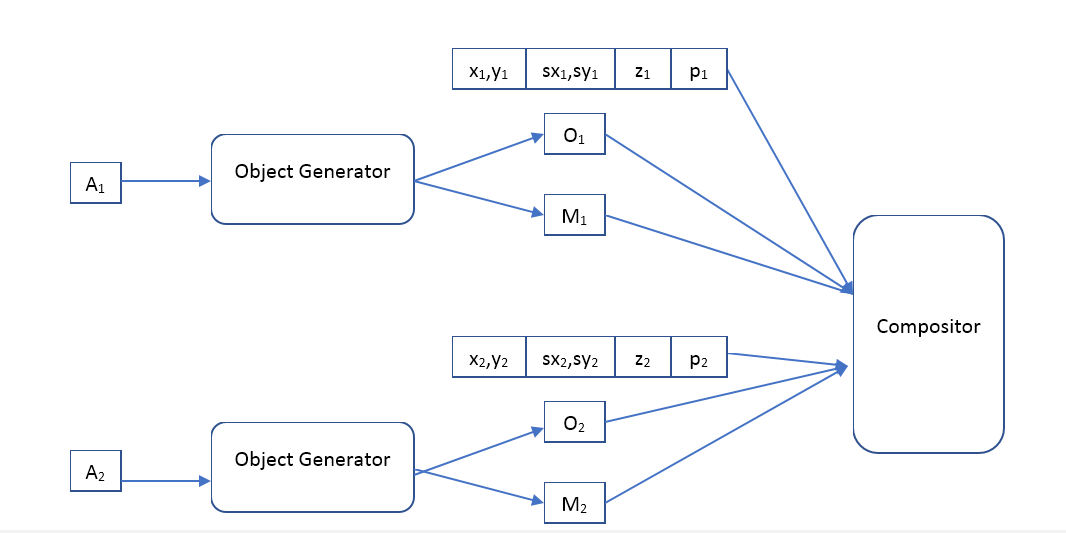
Onde Object Generator é uma rede que recebe um vetor de descrição de objeto na entrada e fornece
- a imagem (de um certo tamanho padrão) do objeto e a máscara de pixels opacos (máscara de opacidade).
Compositor - recebe a imagem de entrada de todos os objetos, máscara, posição, escala, profundidade e forma a imagem de saída, que deve ser semelhante à original.
Qual é a diferença entre nossa abordagem e o VAE?
Parece que queremos usar um codificador automático com a mesma arquitetura dos autores do artigo
Detecção de objetos não supervisionados espacialmente invariantes com redes neurais convolucionais , então a questão é qual é a diferença. Tanto o auto-codificador quanto o lá, apenas na segunda versão é variacional.
Do ponto de vista teórico, a diferença é muito grande. O VAE é um modelo generativo e sua tarefa é fazer 2 distribuições (imagens iniciais e geradas) o mais semelhante possível. De um modo geral, o VAE não garante que a imagem gerada a partir da "descrição" de um objeto gerado a partir da imagem original seja pelo menos um pouco semelhante à original. A propósito, os autores dos
próprios Bayes Variacionais de Codificação Automática do VAE falam sobre isso. Então, por que ainda funciona? Penso que a arquitetura selecionada das redes neurais e a "descrição" ajudam a aumentar as informações mútuas da imagem e da "descrição", mas não consegui encontrar nenhuma evidência matemática para essa hipótese. Uma pergunta para os leitores: alguém pode explicar os resultados dos autores - a imagem restaurada é muito semelhante à original, por quê?
Além disso, o uso do VAE força os autores a especificar a distribuição de "descrições", e o método de maximizar informações mútuas não faz suposições sobre isso. O que nos dá liberdade adicional, por exemplo, podemos tentar agrupar vetores em um modelo já treinado
descrições e aparência - talvez esse sistema aprenda as classes de objetos? Deve-se notar que esse agrupamento usando VAE não faz sentido; por exemplo, os autores do artigo usam uma distribuição gaussiana para esses vetores.
Os experimentos
Infelizmente, agora o trabalho leva uma quantidade enorme de tempo e não é possível concluí-lo em um período aceitável. Se alguém quiser escrever milhares de linhas de código, treinar centenas de modelos de aprendizado de máquina e conduzir muitas experiências interessantes, simplesmente porque isso lhe dá prazer - ficarei feliz em juntar forças. Escreva de forma pessoal.
O campo para experimentos aqui é muito amplo. Tenho planos de começar treinando o codificador automático clássico (mapeamento determinístico de imagens para descrições e uma distribuição inversa gaussiana) e ver o que ele aprende. Nos primeiros experimentos, será suficiente usar o compositor descrito pelos caras do Facebook, mas no futuro acho que será muito interessante tocar com vários compositores, e é possível torná-los também aprendíveis. Compare diferentes regularizadores: sem ele, Esparso, etc. Compare o uso de modelos feedforward e recursivos. Em seguida, use modelos de distribuição mais avançados para distribuição inversa, por exemplo, uma
estimativa de densidade usando o Real NVP . Veja como fica melhor ou pior com modelos mais flexíveis. Veja o que acontecerá se a exibição de imagens nas descrições for tornada não determinística (gerada a partir de alguma distribuição condicional). E, finalmente, tente aplicar vários métodos de armazenamento em cluster aos vetores de descrição
e entender se esse sistema pode aprender classes de objetos.
Mas o mais importante é que eu realmente quero comparar a qualidade do modelo com base em maximizar informações mútuas e o modelo com o VAE.