Meu nome é Oleg Ermakov, trabalho na equipe de desenvolvimento de back-end do aplicativo Yandex.Taxi. É habitual realizar levantamentos diários, onde cada um de nós fala sobre as tarefas realizadas durante o dia. É assim que acontece ...
Os nomes dos funcionários podem mudar, mas as tarefas são bastante reais!Às 12:45, toda a equipe se reúne na sala de reuniões. A primeira palavra é usada por Ivan, um desenvolvedor trainee.
Ivan:
Trabalhei na tarefa de exibir todas as opções possíveis para as quantias que o passageiro poderia dar ao motorista a um custo conhecido da viagem. A tarefa é bem conhecida - é chamada "Mudança de moedas". Levando em conta as especificidades, ele adicionou várias otimizações ao algoritmo. Fiz o pedido de revisão da piscina anteontem, mas desde então venho corrigindo os comentários.
Pelo sorriso contente de Anna, ficou claro quais comentários Ivan corrige.
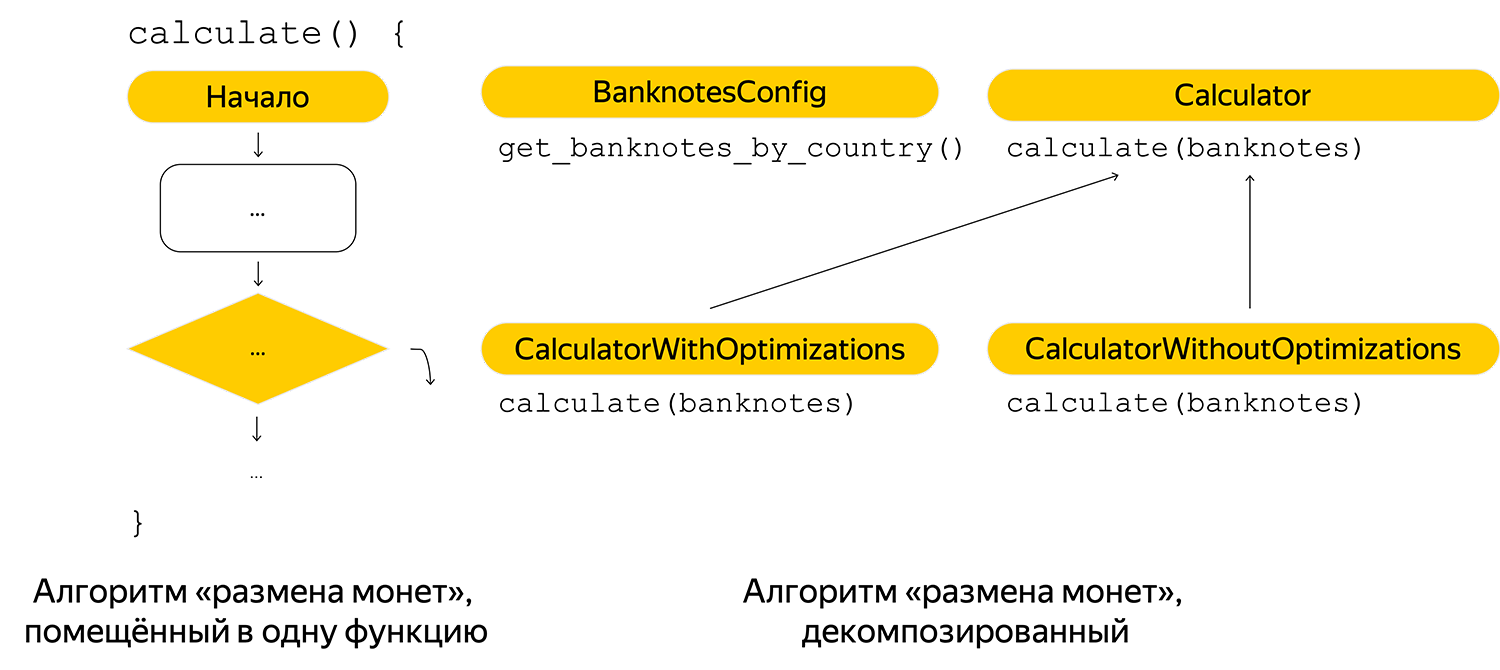
Antes de tudo, ele fez a decomposição mínima do algoritmo e estava recebendo as notas com inteligência. Na primeira implementação, as possíveis notas foram registradas no código e, portanto, foram levadas para a configuração por país.
Foram adicionados comentários para o futuro, para que qualquer leitor possa descobrir rapidamente o algoritmo:
for exception in self.exceptions[banknote]: exc_value = value + exception.delta if exc_value - cost >= banknote: continue if exc_value > cost >= exception.banknote: banknote_results.append(exc_value)
Bem, é claro, passei o resto do tempo cobrindo todo o código com testes.
RUB = [1, 2, 5, 10, 50, 100, 200, 500, 1000, 2000, 5000] CUSTOM_BANKNOTES = [1, 3, 7, 11] @pytest.mark.parametrize( 'cost, banknotes, expected_changes', [
Além dos testes usuais executados em todas as versões do projeto, ele escreveu um teste que usa um algoritmo sem otimizações (considere-o um fracasso completo). O resultado desse algoritmo para cada fatura dos primeiros 10 mil casos colocados em um arquivo e executados separadamente no algoritmo com otimizações para garantir que ele realmente funcione corretamente.
Vamos tirar um momento para nos distrair do stand-up e resumir os resultados locais de tudo o que Ivan diz. Ao escrever um código, o objetivo principal é garantir seu desempenho. Para atingir esse objetivo, você deve concluir as seguintes tarefas:
- Decomponha a lógica de negócios em fragmentos atômicos. A legibilidade é complicada ao exibir uma tela de código escrita em uma função.
- Adicione comentários às partes "particularmente complexas" do código. Nossa equipe tem a seguinte abordagem: se você fizer uma pergunta sobre a implementação na revisão de código (eles pedem para explicar o algoritmo), será necessário adicionar um comentário. Melhor ainda, pense com antecedência e adicione você mesmo.
- Escreva testes cobrindo os principais ramos da execução do algoritmo. Os testes não são apenas um método para verificar a integridade do código. Eles ainda servem como um exemplo do uso do seu módulo.
Infelizmente, mesmo especialistas com muitos anos de experiência nem sempre usam essas abordagens em seu trabalho. Na
escola de desenvolvimento de back-end que estamos fazendo agora, os alunos adquirem habilidades práticas na escrita de códigos arquitetônicos de alta qualidade. Nosso outro objetivo é disseminar práticas de cobertura de teste para o projeto.
Mas voltando ao stand-up. Depois de Ivan, Anna fala.
Anna:
Estou desenvolvendo um microsserviço para devolver imagens de promoção. Como você se lembra, o serviço inicialmente forneceu stubs de dados estáticos. Em seguida, os testadores pediram para personalizá-los, e eu os coloquei na configuração, e agora estou fazendo uma implementação "honesta" com o retorno de dados do banco de dados (PostgreSQL 10.9). A decomposição, originalmente estabelecida, me ajudou muito, na estrutura da qual a interface para receber dados na lógica de negócios não muda, e cada nova fonte (seja uma configuração, banco de dados ou um microsserviço externo) implementa apenas sua própria lógica.

Eu verifiquei o sistema escrito sob carga, os testes mostraram que o identificador começa a frear bruscamente quando vamos ao banco de dados. Segundo a explicação, vi que o índice não é usado. Até eu descobrir como consertar.
Vadim:
E que tipo de solicitação?
Anya:
Duas condições em OR:
SELECT * FROM table_1 JOIN table_2 ON table_1.some_id = table_2.some_id WHERE (table_2.attr1 = 'val' OR table_1.attr2 IN ('val1', 'val2')) AND table_1.deleted_at IS NULL AND table_2.deleted_at IS NULL ORDER BY table_2.created_at
A explicação da consulta mostrou que ele não usa um dos índices para os atributos attr1 da tabela_2 e attr2 da tabela_1.
Vadim:
Diante de um comportamento semelhante no MySQL, o problema está precisamente na condição de OR, por causa da qual apenas um índice é usado, por exemplo, attr2. E a segunda condição usa a verificação seq - uma passagem completa pela tabela. A solicitação pode ser dividida em duas solicitações independentes. Como opção, divida e congele o resultado da consulta no lado de back-end. Mas você precisa pensar em agrupar essas duas solicitações em uma transação ou combiná-las usando UNION - na verdade, no lado base:
SELECT * FROM table_1 JOIN table_2 ON table_1.some_id = table_2.some_id WHERE (table_2.attr1 = 'val') AND table_1.deleted_at IS NULL AND table_2.deleted_at IS NULL ORDER BY table_2.created_at SELECT * FROM table_1 JOIN table_2 ON table_1.some_id = table_2.some_id WHERE (table_1.attr2 IN ('val1' , 'val2')) AND table_1.deleted_at IS NULL AND table_2.deleted_at IS NULL ORDER BY table_2.created_at
Anya:
Obrigado, vou tentar ^ _ ^
Para resumir novamente:
- Quase todas as tarefas de desenvolvimento de produtos estão relacionadas à obtenção de registros de fontes externas (serviços ou bancos de dados). Você precisa abordar cuidadosamente a questão da decomposição de classes que descarregam dados. As classes projetadas corretamente permitirão que você escreva testes e modifique as fontes de dados sem problemas.
- Para trabalhar efetivamente com o banco de dados, você precisa conhecer os recursos de execução da consulta, por exemplo, entender como explicar.
Trabalhar com informações e organizar fluxos de dados é parte integrante das tarefas de qualquer desenvolvedor de back-end. A escola apresentará a arquitetura da interação de serviços (e fontes de dados). Os alunos aprenderão a trabalhar com bancos de dados arquitetonicamente e em termos de operação - migração e teste de dados.
O último a falar é Vadim.
Vadim:
Fiquei de plantão por uma semana, resolvi a sequência de incidentes. Um erro ridículo no código levou muito tempo: não havia logs sob demanda no produto, embora sua criação tenha sido escrita no código.
Pelo silêncio triste de todos os presentes, fica claro - todos já enfrentaram o problema .
Para obter todos os logs como parte da solicitação, request_id é usado, que é lançado em todos os registros no seguinte formato:
log_extra é um dicionário com meta-informações da solicitação, cujas chaves e valores serão gravados no log. Sem passar log_extra para a função de log, o registro não será associado a todos os outros logs, porque não terá request_id.
Eu tive que corrigir o erro no serviço, lançá-lo novamente e só depois lidar com o incidente. Esta não é a primeira vez que isso acontece. Para impedir que isso aconteça novamente, tentei corrigir o problema globalmente e me livrar do log_extra.
Primeiro, escrevi um wrapper sobre a execução padrão da solicitação:
async def handle(self, request, handler): log_extra = request['log_extra'] log_extra_manager.set_log_extra(log_extra) return await handler(request)
Foi necessário decidir como armazenar log_extra em uma única solicitação. Havia duas opções. O primeiro é alterar task_factory para eventloop de asyncio:
class LogExtraManager: __init__(self, context: Any, settings: typing.Optional[Dict[str, dict]], activations_parameters: list) -> None: loop = asyncio.get_event_loop() task_factory = loop.get_task_factory() if task_factory is None: task_factory = _default_task_factory @functools.wraps(task_factory) def log_extrad_factory(ev_loop, coro): child_task = task_factory(ev_loop, coro) parent_task = asyncio.Task.current_task(loop=ev_loop) log_extra = getattr(parent_task, LOG_EXTRA_CONTEXT_KEY, None) setattr(child_task, LOG_EXTRA_CONTEXT_KEY, log_extra) return child_task
A segunda opção é "empurrar" a transição para o Python 3.7 através do comando infrastructure para usar o contextvars :
log_extra_var = contextvars.ContextVar(LOG_EXTRA_CONTEXT_KEY) class LogExtraManager: def set_log_extra(log_extra: dict): log_extra_var.set(log_extra)
Bem, além disso, foi necessário encaminhar armazenado no contexto de log_extra no logger.
class LogExtraFactory(logging.LogRecord):
Resumo:
- No Yandex.Taxi (e em todos os lugares no Yandex) o assíncio é usado ativamente. É importante não apenas poder usá-lo, mas também entender sua estrutura interna.
- Desenvolva o hábito de ler os changelogs de todas as novas versões do idioma, pense em como você pode tornar a vida mais fácil para você e seus colegas com a ajuda de inovações.
- Ao trabalhar com bibliotecas padrão, não tenha medo de rastrear o código-fonte e entender o dispositivo. Essa é uma habilidade muito útil que permitirá entender melhor a operação do módulo e abrir novas possibilidades na implementação de recursos.
Os professores da escola consumiram mais de meio
quilo de sal e encheram muitos cones na operação assíncrona dos serviços. Eles falarão aos alunos sobre os recursos da operação assíncrona do Python - tanto no nível prático quanto na análise de pacotes internos.
Livros e links
Aprender Python pode ajudá-lo a:
- Três livros: Python Cookbook , Diving Into Python 3 e Python Tricks .
- Palestras em vídeo de pilares da indústria de TI, como Raymond Hettinger e David Beasley. Das palestras em vídeo da primeira, é possível distinguir o relatório “Além do PEP 8 - Boas práticas para um belo código inteligível”. Beasley aconselha você a assistir a uma apresentação sobre assíncio.
Para obter um entendimento mais alto da arquitetura, leia os livros:
- "Aplicativos altamente carregados . " Aqui, os problemas de interação com os dados são descritos em detalhes (codificação de dados, trabalho com dados distribuídos, replicação, particionamento, transações, etc.).
- “Microsserviços. Padrões de desenvolvimento e refatoração . ” O livro mostra as abordagens básicas da arquitetura de microsserviços, descreve as deficiências e os problemas que se deve enfrentar ao mudar de um monólito para microsserviços. Não há quase nada no post sobre eles, mas ainda assim eu aconselho você a ler este livro. Você começará a entender as tendências na construção de arquiteturas e aprenderá as práticas básicas de decomposição de código.
Outra das habilidades mais importantes que você pode desenvolver incessantemente é ler o código de outra pessoa. Se você repentinamente perceber que raramente lê o código de outra pessoa, aconselho a desenvolver o hábito de assistir regularmente a novos
repositórios populares.
O stand-up terminou, todos foram trabalhar.