Dados de séries temporais ou séries temporais são dados que mudam com o tempo. Cotações de moeda, telemetria de movimentos de transporte, estatísticas de acesso ao servidor ou carga da CPU são dados de séries temporais. Para armazená-los, são necessárias ferramentas específicas - bancos de dados temporais. Existem dezenas de ferramentas, por exemplo, InfluxDB ou ClickHouse. Mas mesmo as melhores soluções de armazenamento de séries temporais têm desvantagens. Todos os armazenamentos de séries temporais são de baixo nível, adequados apenas para dados de séries temporais, e a execução e a injeção na pilha atual são caras e dolorosas.

Mas, se você tiver uma pilha do PostgreSQL, poderá esquecer o InfluxDB e todos os outros bancos de dados temporais. Instale duas extensões, TimescaleDB e PipelineDB, e armazene, processe e analise dados de séries temporais diretamente no ecossistema do PostgreSQL. Sem a introdução de soluções de terceiros, sem as desvantagens dos armazenamentos temporais e sem os problemas de executá-los. Quais são essas extensões, quais são suas vantagens e capacidades, dirão a
Ivan Muratov ( binakot ) - chefe do departamento de desenvolvimento da "First Monitoring Company".
O que são dados de séries temporais ou séries temporais?
São dados sobre o processo coletado em diferentes momentos de sua vida.
Por exemplo, a localização do carro: velocidade, coordenadas, direção ou uso de recursos no servidor com dados sobre a carga na CPU, RAM usada e espaço livre em disco.
As séries temporais têm vários recursos.
- Em uma cinta de fixação . Qualquer registro de série temporal possui um campo com um registro de data e hora no qual o valor foi registrado.
- As características do processo, chamadas de níveis da série : velocidade, coordenadas, carregamento de dados.
- Quase sempre com esses dados, eles funcionam no modo somente acréscimo . Isso significa que os novos dados não substituem os antigos. Somente dados obsoletos são excluídos.
- As entradas não são consideradas separadamente uma da outra . Os dados são usados apenas coletivamente para janelas de tempo, intervalos ou períodos.
Soluções populares de armazenamento
O gráfico que tirei do
db-engines.com mostra a popularidade de vários modelos de armazenamento nos últimos dois anos.
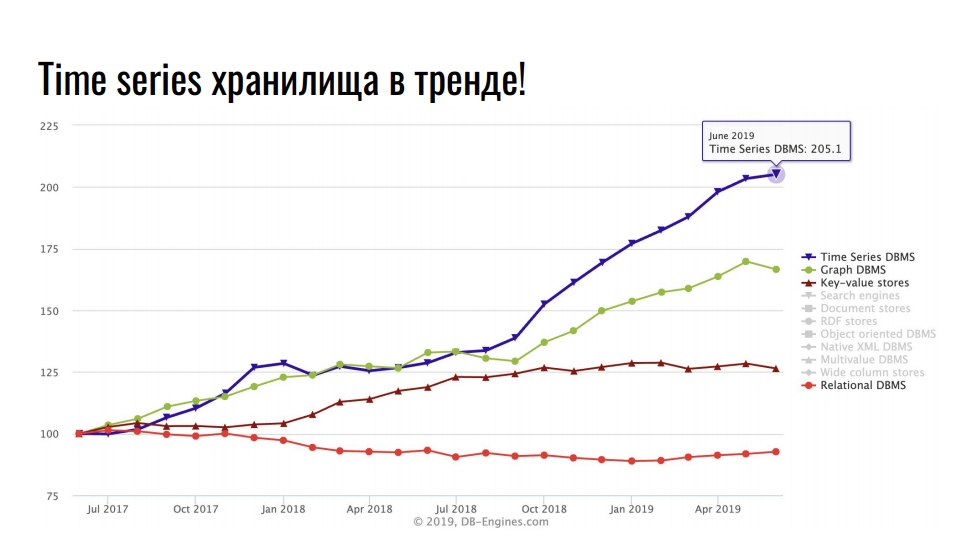
A posição de liderança é ocupada por armazenamentos de séries temporais, em segundo lugar - bancos de dados gráficos, em seguida - bancos de dados relacionais e de valor-chave. A popularidade de repositórios especializados está associada a um intenso crescimento na integração de tecnologias da informação: Big Data, redes sociais, IoT, monitoramento de infraestrutura de alta carga. Além de dados comerciais úteis, até logs e métricas ocupam uma enorme quantidade de recursos.
Soluções populares de armazenamento para dados de séries temporais
O gráfico mostra soluções especializadas para armazenar dados de séries temporais. A escala é logarítmica.
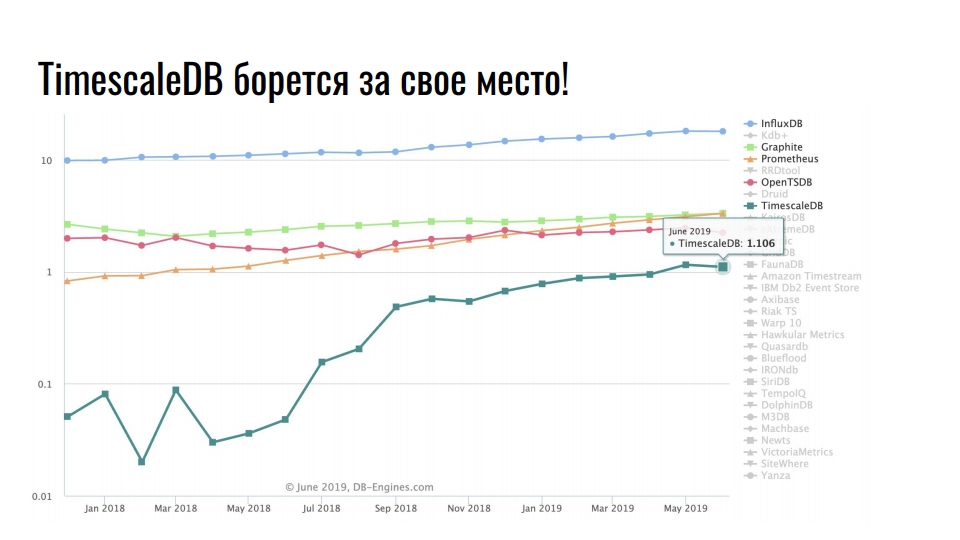
Líder estável InfluxDB. Todo mundo que se deparou com dados de séries temporais já ouviu falar sobre este produto. Mas o gráfico mostra um aumento de dez vezes no TimescaleDB - uma extensão do DBMS relacional está lutando por um lugar ao sol entre os produtos que foram originalmente desenvolvidos sob a série temporal.
O PostgreSQL não é apenas um bom banco de dados, mas também uma plataforma extensível para o desenvolvimento de soluções especializadas.
Postgres, Postgis e TimescaleDB
A Primeira Empresa de Monitoramento monitora o movimento de veículos usando satélites. Nós rastreamos 20.000 veículos e armazenamos dados de movimentação por dois anos. No total, temos 10 TB de dados de telemetria atuais. Em média, cada veículo envia 5 registros de telemetria por minuto enquanto dirige. Os dados são enviados via equipamento de navegação para nossos servidores telemáticos. Eles recebem 500 pacotes de navegação por segundo.
Há algum tempo, decidimos atualizar globalmente a infraestrutura e passar de um monólito para microsserviços. Chamamos o novo sistema de Waliot, e ele já está em produção - 90% de todos os veículos são transferidos para ele.
Muita coisa mudou na infraestrutura, mas o link central permaneceu inalterado - esse é o banco de dados PostgreSQL. Agora estamos trabalhando na versão 10 e nos preparando para passar para 11. Além do PostgreSQL, como armazenamento principal, na pilha, usamos o PostGIS para computação geoespacial e o TimescaleDB para armazenar uma grande variedade de dados de séries temporais.
Por que o PostgreSQL?
Por que estamos tentando usar um banco de dados relacional para armazenar séries temporais, em vez de soluções especializadas
ClickHouse para esse tipo de dados? Porque, tendo como pano de fundo a experiência acumulada e as impressões de trabalhar com o PostgreSQL, não queremos usar uma solução desconhecida como armazenamento principal.
Mudar para uma nova solução é um risco.
Existem muitas soluções especializadas para armazenar e processar dados de séries temporais. A documentação nem sempre é suficiente, e uma grande variedade de soluções nem sempre é boa. Parece que os desenvolvedores de cada novo produto querem escrever tudo do zero, porque algo não foi agradável na solução anterior. Para entender o que exatamente não gostou, você precisa procurar informações, analisar e comparar. Uma enorme variedade de
tops ,
classificações e
comparações são bastante assustadores do que motivadores para tentar algo. Você precisará gastar muito tempo para experimentar todas as soluções. Não podemos nos dar ao luxo de adaptar apenas uma solução por vários meses. Essa é uma tarefa difícil, e o tempo gasto nunca será recompensado. Portanto, escolhemos extensões para o PostgreSQL.
Durante a fase de desenvolvimento da infraestrutura da Waliot, consideramos o InfluxDB o principal repositório de telemetria. Mas quando me deparei com o TimescaleDB e fiz testes, não havia dúvidas sobre a escolha. O PostgreSQL com a extensão TimescaleDB permite usar outras extensões no mesmo armazenamento PostGIS ou PipelineDB. Não precisamos extrair dados, transformar, conduzir análises e transferi-los pela rede. Tudo está em um servidor ou em um sistema em cluster - os dados não precisam ser arrastados. Todos os cálculos são realizados no mesmo nível.
Recentemente,
Nikolay Samokhvalov , o autor da conta postgresmen,
publicou um link para um artigo interessante sobre o uso do SQL para processamento de dados de streaming. Cinco em cada seis autores do artigo participam do desenvolvimento de vários produtos Apache e trabalham com o processamento de fluxo. Portanto, o artigo menciona o Apache Spark, o Apache Flink, o Apache Beam, o Apache Calcite e o KSQL da Confluent.
Mas não o artigo em si é interessante, mas o
tópico do Hacker News , no qual é discutido. O autor do tópico escreve que, com base no artigo, ele implementou quase todas as idéias baseadas no PostgreSQL 11. Ele usou extensões CitusDB para dimensionamento e sharding horizontal, PipelineDB para computação em fluxo e visualizações materializadas, TimescaleDB para armazenar dados e seções de séries temporais. Ele também usa vários invólucros de dados estrangeiros.
Uma mistura maluca de PostgreSQL e suas extensões mais uma vez confirma que o PostgreSQL não é apenas um DBMS - é uma plataforma.
E quando o armazenamento conectável for entregue ... Ugh!
Ironicamente, ao pesquisar as soluções, encontramos o
Outflux , o desenvolvimento da equipe do
TimescaleDB , que eles publicaram em 1º de abril. O que você acha que ela faz? Este é um utilitário para migrar do InfluxDB para o TimescaleDB em um comando ...
Hype do Postgres!
Não subestime o poder do hype! Costumamos brincar que "o desenvolvimento é impulsionado pelo hype", porque influencia nossas percepções sobre os componentes de ajuste e infraestrutura. No
HighLoad ++, discutimos muito sobre o PostgreSQL, ClickHouse, Tarantool - esses são desenvolvimentos exagerados. Só não diga que isso não afeta suas preferências e a escolha de soluções para a infraestrutura ... Claro, esse não é o principal fator, mas há algum efeito?
Trabalho com PostgreSQL há 5 anos. Eu gosto desta solução. Ele resolve quase todas as minhas tarefas com um estrondo. Toda vez que algo dava errado nessa base, minhas mãos tortas eram culpadas. Portanto, a escolha foi predeterminada.
TimescaleDB VS PipelineDB
Vamos seguir para as extensões TimescaleDB e PipelineDB. O que seus criadores dizem sobre extensões?
O TimescaleDB é um banco de dados de séries temporais de código aberto otimizado para inserção rápida e consultas complexas.
O PipelineDB é uma extensão de alto desempenho projetada para executar consultas SQL contínuas
para dados de séries temporais .
Além de trabalhar com dados de séries temporais, eles têm uma história semelhante. O Timescale foi fundado em 2015 e o Pipeline em 2013. As primeiras versões de trabalho apareceram em 2017 e 2015, respectivamente. Levou dois anos para as equipes liberarem a funcionalidade mínima. Os lançamentos de produção de ambas as extensões ocorreram em outubro passado, com uma diferença de uma semana. Aparentemente, com pressa um após o outro.
O GitHub tem um monte de estrelas e garfos, que, como sempre, não são um único commit. É assim que o código aberto funciona, não há nada a ser feito. Mas há muitas estrelas: o
TimescaleDB tem mais que o
PipelineDB e ainda mais que o próprio PostgreSQL.
As extensões parecem ser semelhantes, mas se posicionam de maneira diferente.
O TimescaleDB alega ter inserido milhões de registros por segundo e armazenado centenas de bilhões de linhas e dezenas de terabytes de dados. A extensão é mais rápida que o InfluxDB, Cassandra, MongoDB ou PostgreSQL de baunilha. Suporta replicação de streaming e ferramentas de backup. O TimescaleDB é uma extensão, não um fork do PostgreSQL.
O PipelineDB armazena apenas o resultado dos cálculos de streaming, sem a necessidade de armazenar dados brutos para seus cálculos. A extensão é capaz de agregação contínua em fluxos de dados em tempo real, combinando com tabelas convencionais para cálculos no contexto de um domínio de domínio. O PipelineDB é uma extensão, não um garfo, mas inicialmente era um garfo.
Timescaledb
Agora em detalhes sobre as extensões. Vamos começar com o TimescaleDB. Trabalho com ele há quase 2 anos. Arrastou-o para produção antes da versão de lançamento. Vejamos exemplos de como aplicá-lo.
Armazenamento para métricas de infraestrutura . Temos métricas de consumo de recursos de contêiner do Docker, métricas de confirmação de tempo, identificador de contêiner e campos de consumo de recursos, por exemplo, memória livre. Precisamos exibir estatísticas para todos os contêineres com uma quantidade média de janelas de memória livre por 10 segundos. A consulta que você vê resolve esse problema e o TimescaleDB pode ser usado como um repositório para métricas de infraestrutura.
SELECT time_bucket('10 seconds', time) AS period, container_id, avg(free_mem) FROM metrics WHERE time < now() - interval '10 minutes' GROUP BY period, container_id ORDER BY period DESC, container_id;
period | container_id | avg -----------------------+--------------+--- 2019-06-24 12:01:00+00 | 16 | 72202 2019-06-24 12:01:00+00 | 73 | 837725 2019-06-24 12:01:00+00 | 96 | 412237 2019-06-24 12:00:50+00 | 16 | 1173393 2019-06-24 12:00:50+00 | 73 | 90104 2019-06-24 12:00:50+00 | 96 | 784596
Para cálculos . Precisamos calcular o número de caminhões que deixaram Krasnodar e sua tonelagem total por dias.
SELECT time_bucket('1 day', time) AS day, count(*) AS trucks_exiting, sum(weight) / 1000 AS tonnage FROM vehicles INNER JOIN cities ON cities.name = 'Krasnodar' WHERE ST_Within(last_location, ST_Polygon(cities.geom, 4326)) AND NOT ST_Within(current_location, ST_Polygon(cities.geom, 4326)) GROUP BY day ORDER BY day DESC LIMIT 3;
Ele também usa funções da extensão PostGIS para calcular o transporte que saiu da cidade, em vez de apenas se mover nela.
Monitoramento da taxa de câmbio . O terceiro exemplo é sobre criptomoedas. A solicitação permite exibir como o preço do Ethereum mudou em relação ao Bitcoin e ao dólar americano nas últimas 2 semanas por dia.
SELECT time_bucket('14 days', c.time) AS period, last(c.closing_price, c.time) AS closing_price_btc, last(c.closing_price, c.time) * last(b.closing_price, c.time) filter (WHERE b.currency_code = 'USD') AS closing_price_usd FROM crypto_prices c JOIN btc_prices b ON time_bucket('1 day', c.time) = time_bucket('1 day', b.time) WHERE c.currency_code = 'ETH' GROUP BY period ORDER BY period DESC;
Tudo isso é claro e conveniente para nós, SQL.
O que há de tão legal no TimescaleDB?
Por que não usar as ferramentas de particionamento de tabela internas? E por que se preocupar em quebrar mesas? A resposta óbvia é a
velocidade de inserção nesses bancos de dados . O gráfico mostra as medições reais da taxa de inserção do número de linhas por segundo entre a tabela convencional de baunilha PostgreSQL 10 sem seção e a tabela de tabelas TimescaleDB.
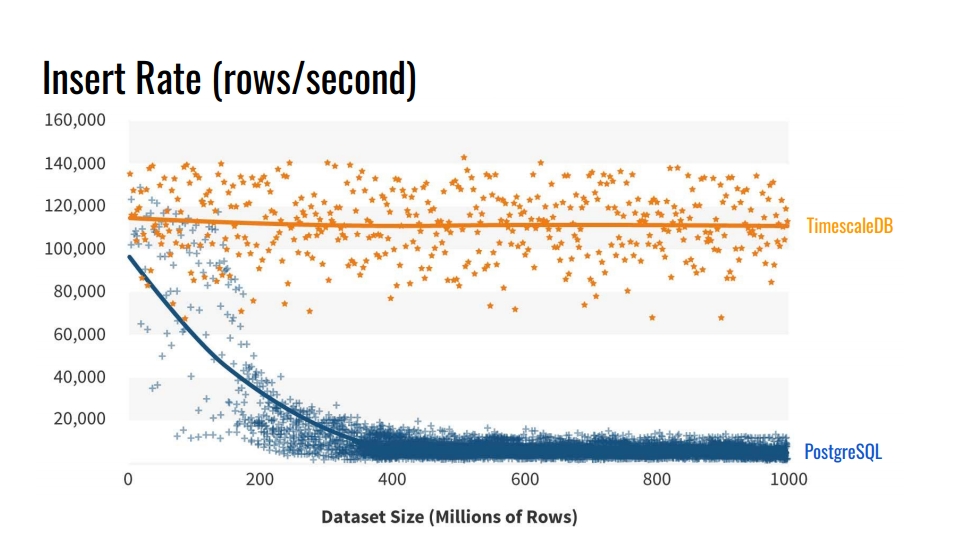
Esse benchmark grava 1 bilhão de linhas em uma máquina, simulando um cenário para coletar métricas da infraestrutura. O registro contém tempo, o identificador do componente de infraestrutura e 10 métricas. O benchmark foi executado na VM do Azure com 8 núcleos e 28 gigabytes de RAM, além de unidades SSD de rede. A inserção foi realizada em lotes de 10 mil registros.
De onde vem essa degradação do desempenho do PostgreSQL? Porque quando você insere, você também precisa atualizar os índices da tabela. Quando eles não se encaixam no cache, começamos a carregar discos. O particionamento resolve esse problema se os índices da seção na qual inserimos os dados forem colocados na RAM.
Vamos olhar para o gráfico a seguir. Isso compara o sistema de particionamento declarativo embutido no PostgreSQL 10 e a hiper tabela TimescaleDB. No eixo horizontal, o número de seções.
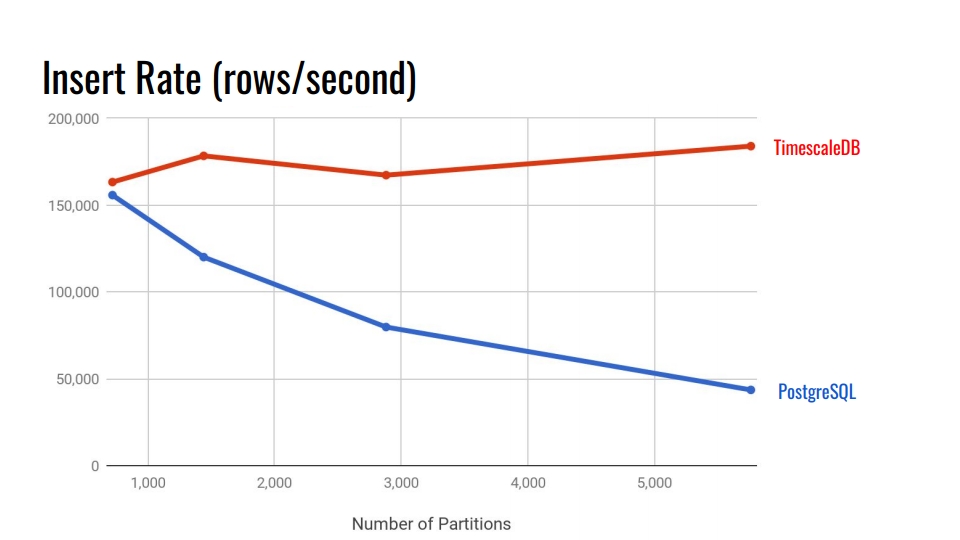
No TimescaleDB, a degradação é insignificante com o aumento de seções. Os desenvolvedores de extensões afirmam que estão indo bem com 10.000 seções em uma única instância do PostgreSQL.
No PostgreSQL, a implementação nativa degrada significativamente após 3.000. Em geral, o particionamento declarativo no PostgreSQL é um grande passo à frente, mas funciona apenas para tabelas com menos carga. Por exemplo, para mercadorias, compradores e outras entidades de domínio que entram no sistema de maneira não tão intensa quanto as métricas.
Nas versões 11 e 12 do PostgreSQL, o suporte ao particionamento nativo será exibido e você poderá tentar executar testes comparativos para dados de séries temporais com novas versões. Mas, parece-me que o TimescaleDB ainda é melhor. Todos os benchmarks do TimescaleDB podem ser encontrados no
github e try.
Principais recursos
Espero que você já tenha interesse na extensão. Vamos examinar os principais recursos do TimescaleDB para consolidar esse sentimento.
Particionando através de tabelas de hipertensão . O TimescaleDB usa o termo "hipertabela" para tabelas às quais a função create_hypertable () foi aplicada. Depois disso, a tabela se tornará o pai de todas as seções herdadas - pedaços. A tabela pai em si não conterá nenhum dado, mas será um ponto de entrada para todas as consultas e um modelo ao criar automaticamente novas seções. Todas as seções são armazenadas não no esquema principal dos seus dados, mas em um esquema especial. Isso é conveniente porque não vemos milhares dessas seções no esquema de dados.
A extensão é integrada ao agendador e ao executor de consultas . Por meio de ganchos especiais no PostgreSQL, o TimescaleDB entende quando acessa uma hipertabela. O TimescaleDB analisa a consulta e redireciona as consultas apenas para as seções necessárias com base nas condições especificadas na própria chamada SQL. Isso permite que você paralelize o trabalho com as seções durante a extração de uma quantidade significativa de dados.
A extensão não impõe restrições ao SQL . Você pode usar livremente uniões, agregados, funções de janela, CTEs e índices adicionais. Se você viu a lista de restrições para o sistema de particionamento interno, isso deve agradá-lo.
Recursos úteis adicionais específicos para dados de séries temporais:
- "Time_bucket" - "date_trun" de uma pessoa saudável;
- histogramas - preenchimento dos intervalos perdidos usando interpolação ou o último valor conhecido;
- trabalhador em segundo plano - serviços que permitem executar operações em segundo plano: limpeza de seções antigas, reorganização.
O TimescaleDB permite que você fique no poderoso ecossistema PostgreSQL . Esta extensão não quebra o PostgreSQL; portanto, todas as soluções de alta disponibilidade, sistemas de backup e ferramentas de monitoramento continuarão funcionando. O TimescaleDB é amigo de Grafana, Periscope, Prometheus, Telegraf, Zabbix, Kubernetes, Kafka, Seeq, JackDB.
A Grafana já possui suporte nativo ao
TimescaleDB como fonte de dados. A Grafana entende imediatamente que o PostscreSQL possui o TimescaleDB. O construtor de solicitações no Grafana nos painéis entende funções adicionais do TimescaleDB, como "time_bucket", "first", "last". Você pode criar gráficos diretamente do banco de dados relacional com essas funções de séries temporais sem consultas gigantescas.
O Prometheus possui um adaptador que permite mesclar dados dele e usar o TimescaleDB como um data warehouse confiável. Use um adaptador para não armazenar dados no Prometheus por anos.
Há também um
plug-in Telegraf . A solução permite remover completamente o Prometheus. Os dados da infraestrutura são imediatamente transferidos para o TimescaleDB e lidos pelo Telegraf.
Licenças e Notícias
Não faz muito tempo, a empresa mudou para um novo modelo de licenciamento. A maior parte do código é licenciada sob o Apache 2.0. Uma pequena porção é gratuita, mas é licenciada sob TSL.
Existe uma versão Enterprise com uma licença comercial. Não se preocupe, nem todos os presentes na versão Enterprise. Basicamente, existem automações, como a remoção automática de partes obsoletas, que podem ser feitas através de um "cron" simples e coisas semelhantes.
Agora a empresa está trabalhando ativamente em uma solução de cluster. Talvez ele caia na versão Enterprise. Há também uma versão em nuvem para startups que desejam entrar no mercado antes que os investidores fiquem sem dinheiro.
Das notícias:
- um milhão de downloads no último ano e meio;
- Investimento de US $ 31 milhões;
- Colaboração ativa com o MS Azure em relação às soluções de IoT.
Resumir
O TimescaleDB foi projetado para armazenar dados de séries temporais. Este é um poderoso sistema de particionamento com restrições mínimas em comparação com as nativas no PostgreSQL.
Infelizmente, a extensão ainda não possui uma versão multinode. Se você deseja um multimaster ou shard, precisa brincar, por exemplo, com o CitusDB. Se você deseja replicação lógica, isso vai doer. Mas sempre dói com ela.
Pipelinedb
Agora vamos falar sobre a segunda extensão. Infelizmente, não fomos capazes de testá-lo adequadamente em batalha. Agora está passando pelo estágio de adaptação em nosso sistema. É verdade que há um problema que abordarei mais perto do fim.
Como no caso anterior, começamos com exemplos reais. É mais fácil entender os benefícios da expansão e a motivação para usá-la.
Coleta de estatísticas . Imagine que coletamos estatísticas sobre as visitas ao nosso site. Precisamos de análises das páginas mais populares, do número de usuários únicos e de alguma idéia de atrasos nos recursos. Tudo isso deve ser atualizado em tempo real. Mas não queremos tocar na tabela de dados todas as vezes e criar uma consulta ou atualizar a exibição na parte superior da tabela.
CREATE CONTINUOUS VIEW v AS SELECT url::text, count(*) AS total_count, count(DISTINCT cookie::text) AS uniques, percentile_cont(0.99) WITHIN GROUP (ORDER BY latency::integer) AS p99_latency FROM page_views GROUP BY url;
url | total_count | uniques | p99_latency -----------+-------------+---------+------------ some/url/0 | 633 | 51 | 178 some/url/1 | 688 | 37 | 139 some/url/2 | 508 | 88 | 121 some/url/3 | 848 | 36 | 59 some/url/4 | 126 | 64 | 159
O processamento de streaming e a extensão PipelineDB são úteis. A extensão adiciona a abstração CONTINUES VIEW. Na versão russa, isso pode parecer uma "apresentação contínua". Essa visualização é atualizada automaticamente quando inserida na tabela com os registros de visitas, mas apenas com base em novos dados, sem a leitura já registrada previamente.
Fluxo de dados . O PipelineDB não se limita apenas ao novo tipo de exibição. Suponha que realizemos testes A / B e coletemos análises em tempo real sobre a eficácia de uma nova solução de negócios. Mas não queremos armazenar os dados nas próprias ações do usuário. Estamos interessados apenas no resultado - qual grupo tem mais conversões.
Para evitar o armazenamento direto de dados brutos para computação em fluxo, precisamos de uma abstração como
fluxos - fluxo de dados . O PipelineDB apresenta esse recurso. Você pode criar fluxos como tabelas regulares. Sob o capô, será "FOREIGN TABLE" baseado na fila ZeroMQ, que a extensão imperceptivelmente usa de nós. Os dados entram na fila interna do ZeroMQ e acionam uma atualização para a exibição contínua.
CREATE STREAM ab_event_stream ( name text, ab_group text, event_type varchar(1), cookie varchar(32) ); CREATE CONTINUOUS VIEW ab_test_monitor AS SELECT name, ab_group, sum(CASE WHENevent_type = 'v' THEN 1 ELSE 0 END) AS view_count, sum(CASE WHENevent_type = 'c' THEN 1 ELSE 0 END) AS conversion_count, count(DISTINCT cookie) AS uniques FROM ab_event_stream GROUP BY name, ab_group;
Em seguida, criamos "VISÃO CONTÍNUA" com base nos dados de um fluxo criado anteriormente. Quando os dados chegarem no fluxo, a exibição será atualizada com base nesses dados. Depois disso, os dados serão simplesmente descartados, não sendo salvos em nenhum lugar e não ocupando espaço em disco. Isso permite que você crie análises em uma quantidade quase ilimitada de dados, carregando-os no fluxo de dados do PipelineDB e lendo o resultado do cálculo de uma exibição contínua.
Computação em fluxo Depois de criarmos o fluxo de dados e a visualização contínua, podemos trabalhar com a computação em fluxo. Parece assim.
INSERT INTO ab_event_stream (name, ab_group, event_type, cookie) SELECT round(random() * 2) AS name, round(random() * 4) AS ab_group, (CASE WHENrandom() > 0.4 THEN 'v' ELSE 'c' END) AS event_type, md5(random()::text) AS cookie FROM generate_series(0, 100000); SELECT ab_group, uniques FROM ab_test_monitor; SELECT ab_group, view_count * 100 / (conversion_count + view_count) AS conversion_rate FROM ab_test_monitor;
O primeiro "SELECT" fornece ao grupo "ab" e o número de visitantes únicos. O segundo - fornece a proporção entre os grupos - conversão. Isso é tudo o teste A / B em cinco chamadas SQL em um banco de dados relacional.
A visualização é atualizada dinamicamente. Você não pode esperar pelo processamento de toda a matriz de dados, mas ler os resultados intermediários que já foram processados. As visualizações são lidas da mesma maneira que o PostgreSQL comum. Você também pode combinar uma visualização com tabelas ou até outras visualizações. Não há restrições.
Topologia
O Kafka recebe telemetria, o tópico no Kafka envia esses dados para o PostgreSQL e os agregamos ainda mais. Por exemplo, combinamos com alguma tabela comum e redirecionamos os dados para o fluxo. Além disso, ele provoca a atualização da apresentação contínua correspondente, a partir da qual os clientes do banco de dados já podem ler os dados finais.
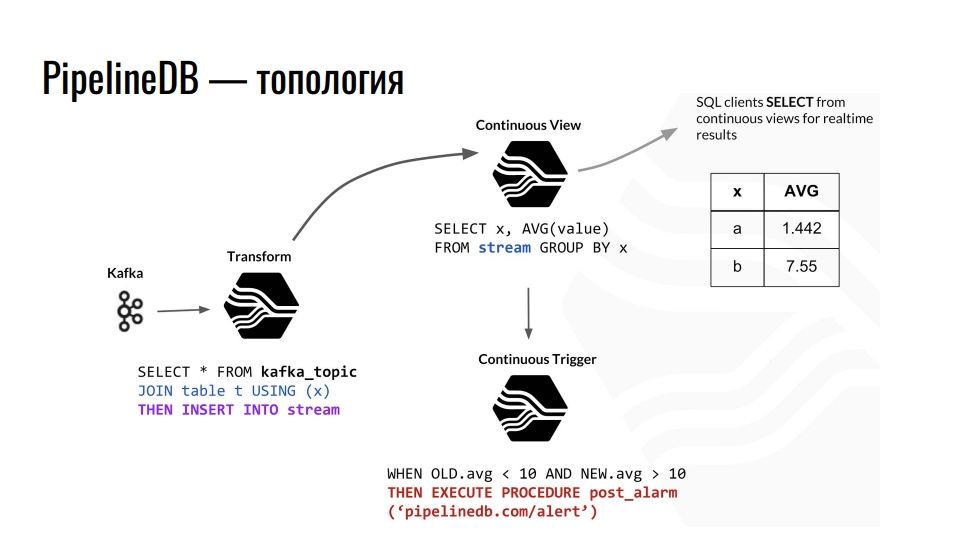 Um exemplo da topologia dos componentes do PipelineDB dentro do PostgreSQL. O circuito é emprestado de uma apresentação de Derek Nelson.
Um exemplo da topologia dos componentes do PipelineDB dentro do PostgreSQL. O circuito é emprestado de uma apresentação de Derek Nelson.Além de fluxos e visualizações, a extensão também fornece uma abstração de "transformação" - conversores ou mutadores. Essa visualização, mas destinava-se a converter o fluxo de dados recebidos em uma saída modificada. Usando esses mutadores, você pode alterar a apresentação dos dados ou filtrá-los. Do mutador, tudo cai na visualização CONTINUOUS VIEW. Já fazemos consultas sobre negócios. Qualquer pessoa familiarizada com programação funcional deve entender a ideia.
No PipelineDB, podemos acionar nossos modos de exibição e executar ações, por exemplo, "alerta". Com todos esses cálculos, nunca armazenamos os dados brutos, com base nos quais todos os calculamos. Estes podem ser terabytes, que são carregados sequencialmente em um servidor com um disco de cem gigabytes. Afinal, estamos interessados apenas no resultado dos cálculos.
Principais recursos
A extensão PipelineDB é mais difícil de aprender do que o TimescaleDB. No TimescaleDB, criamos uma tabela, dizemos que ela é uma hipertabela e aproveitamos a vida usando várias funções adicionais que a extensão oferece.
O PipelineDB resolve o problema de streaming de computação em bancos de dados relacionais . A tarefa de transmitir o processamento de dados é mais complicada do que o particionamento em termos de integração e uso. No entanto, nem todo mundo tem dados enormes e bilhões de linhas. Por que complicar a infraestrutura se houver o PipelineDB? A extensão fornece suas próprias implementações de representações, fluxos, conversores e agregados para processamento de fluxo. Também é
integrado ao planejador de consultas e o executor de consultas permite implementar o conceito de computação em fluxo em um banco de dados relacional.
Como o TimescaleDB, a extensão PipelineDB
não impõe restrições SQL no PostgreSQL . Existem vários recursos, por exemplo, você não pode combinar dois fluxos, mas isso não é necessário.
Suporte para estruturas de dados probabilísticas e algoritmos . A extensão usa o filtro Bloom para SELECT DISTINCT, HyperLogLog para COUNT (DISTINCT) e T-Digest para percentile_count () diretamente no SQL. Isso melhora a produtividade.
Ecossistema A extensão permite que você trabalhe com as soluções habituais de alta disponibilidade, ferramentas de monitoramento e tudo o mais familiar no PostgreSQL.
Dadas as especificidades da computação em fluxo, o PipelineDB tem
integrações com o Apache Kafka e com o Amazon Kinesis, um serviço de análise em tempo real. Como o PipelineDB não é mais um fork, mas uma extensão, a integração com o restante do zoológico também deve estar pronta para uso. Um imperativo, mas não vivemos em um mundo ideal, e vale a pena conferir tudo.
Licenças e Notícias
Todo o código é licenciado no Apache 2.0. Há uma assinatura paga para o suporte de diferentes galerias de tiro, bem como uma versão em cluster com uma licença comercial. Com base no PipelineDB, a empresa fornece o serviço de análise Stride.
Antes de começar a falar sobre a extensão, eu disse que existe um "mas". É hora de falar sobre ele. Em 1 de maio de 2019, a equipe do PipelineDB anunciou que agora faz parte do Confluent. Esta é a empresa que desenvolve o KSQL - um mecanismo para transmitir dados no Kafka com sintaxe SQL. Agora Victor Gamov, co-fundador do podcast Debriefing, está trabalhando lá.
O que se segue disso? O PipelineDB congelou na versão 1.0.0. Além de corrigir bugs críticos, nada está planejado nele. Devido à aquisição, esperamos a integração do Uber do Kafka com o PostgreSQL. Talvez seja Confluent baseado em armazenamento conectável que faça algo legal.
O que fazer Vá para TimescaleDB. Na versão mais recente, eles fizeram sua “VISÃO CONTÍNUA” com blackjack. Obviamente, agora a funcionalidade não é tão legal quanto no PipelineDB, mas é uma questão de tempo.
Resumir
O PipelineDB foi projetado para processamento de dados de streaming de alto desempenho. Ele permite que você execute cálculos em grandes conjuntos de dados sem precisar salvar os dados em si.
Com o PipelineDB, quando enviamos um fluxo de dados para o PostgreSQL em um fluxo, os consideramos virtuais. Não salvamos dados, mas agregamos, calculamos e descartamos. Você pode criar um servidor de 200 gigabytes e eliminar terabytes de dados através de fluxos. Obteremos o resultado, mas os dados serão descartados.
Se, por algum motivo, a "VISÃO CONTÍNUA" do TimescaleDB não for suficiente para você, tente o PipelineDB. Este é um projeto de código aberto sob a licença Apache. Não vai a lugar nenhum, embora não esteja mais sendo desenvolvido ativamente. Mas as coisas podem mudar, o Confluent ainda não escreveu sobre planos de expansão.
Usando TimescaleDB e PipelineDB
Com o PostgreSQL e duas extensões,
podemos armazenar e processar grandes matrizes de dados de séries temporais . Você pode pensar em muitos aplicativos. Vejamos um exemplo da minha área de assunto - monitoramento de veículos.

O equipamento de navegação envia continuamente gravações de telemetria para nossos servidores. Eles analisam vários protocolos de texto e binários em um formato comum e enviam dados para Kafka em um tópico especial. A partir daí, eles passam pela integração com o PipelineDB no fluxo de dados de telemetria no PostgreSQL. Esse fluxo atualiza a exibição do estado atual dos veículos e da análise geral da frota e, com base no gatilho, provoca o registro de registros de telemetria na hipertela TimescaleDB.
Com extensões, temos três vantagens.
- Análise em tempo real.
- Dados de séries temporais de armazenamento.
- Diminuição do volume de telemetria armazenada. Usando o mutador PipelineDB, agregamos dados, por exemplo, por um minuto, calculando os valores médios.
O Grafana possui suporte interno para os recursos do TimescaleDB. Portanto, é possível criar gráficos de acordo com as métricas de negócios diretamente da caixa, até as trilhas no mapa por coordenadas. O departamento de análise ficará feliz.
Para "tocar" tudo você mesmo, veja
a demonstração no GitHub e execute a
imagem do
Docker - dentro da montagem, a partir do PostgreSQL, TimescaleDB e PipelineDB mais recentes.
Total
O PostgreSQL permite combinar várias extensões, além de adicionar seus próprios tipos de dados e funções para resolver problemas específicos. No nosso caso, o uso das extensões TimescaleDB e PostGIS cobre quase completamente as necessidades de armazenamento de dados de séries temporais e cálculos geoespaciais. Com a extensão PipelineDB, podemos realizar cálculos contínuos para várias análises e estatísticas, e o uso de colunas JSONB nos permite armazenar dados fracamente estruturados em um banco de dados relacional. As soluções de código aberto são suficientes com a cabeça - não usamos soluções comerciais.
Essas extensões praticamente não impõem restrições ao ecossistema em torno do PostgreSQL, como soluções de alta disponibilidade, sistemas de backup, ferramentas de monitoramento e análise de logs. Não precisamos do MongoDB se houver colunas JSONB e não precisamos do InfluxDB se houver TimescaleDB.
Você gosta da história de Ivan e quer compartilhar algo semelhante? Inscreva-se antes de 7 de setembro no HighLoad ++ em Moscou. O programa está sendo preenchido gradualmente. , , , , . , !