O teste de unidade é ótimo, mas um não é suficiente. Freqüentemente, você também deseja garantir que o aplicativo em execução funcione. O teste de integração vem em socorro. É cada vez mais usado para testar serviços, e o Docker permite gerenciar convenientemente seu ambiente de teste. Mas, como sempre, as coisas não são tão simples quando há muito mais microsserviços e dependências.
Yuri Badalyants, do RIT ++, contou como, no 2GIS, eles estão testando vários serviços e um zoológico de tecnologia inteiro. Sob o corte, a versão deste relatório é complementada e atualizada sob a cuidadosa supervisão do orador: quais opções você tentou, o que criou, que problemas não precisa resolver agora. Será sobre Docker, Testcontainers e também sobre Scala.
Sobre o palestrante: Yuri Badalyants (@
LMnet ) iniciou sua carreira em 2011 como desenvolvedor web, trabalhou com PHP, JavaScript e Java. Agora ele escreve sobre Scala em 2GIS.
Cassino
A 2GIS fornece mapas de cidades e diretórios de empresas convenientes há 20 anos e, recentemente, temos uma
nova versão com um mapa ilimitado da Rússia. Vou contar sobre a experiência adquirida enquanto trabalhei na equipe do cassino. Essa equipe está envolvida em três áreas principais:
- Publicidade - quais anunciantes exibir, quais ocultar, quais aumentar e como diminuir a classificação.
- O BigData está relacionado à publicidade e sua personalização, além da construção de análises e métricas.
- O Crawler é um programa que procura organizações na Internet para adicioná-las automaticamente ao banco de dados.
Essas três áreas são as principais tarefas, as quais, por sua vez, possuem um grande número de subtarefas. Atualmente, existem mais de 25 microsserviços escritos em Scala. Este é exclusivamente nosso código, no entanto, também usamos sistemas de terceiros, por exemplo, PostgreSQL, Cassandra e Kafka. Armazenamos os dados no Hadoop e os processamos no Spark. Além disso, usamos os métodos de aprendizado de máquina fornecidos pela equipe de ciência de dados.
Como resultado, temos um grande número de serviços e microsserviços, um grande número de dependências e, é claro, tudo isso precisa ser testado de alguma maneira.
Obviamente, escrevemos testes de unidade. No entanto, mesmo que todos os testes sejam verdes, isso não significa que tudo funcione. Algo pode dar errado durante a fase de integração de componentes ou microsserviços. Portanto, escrevemos testes de integração.
Testes de integração
Cada microsserviço desenvolvido pela equipe do Casino resolve seu problema de negócios e está localizado em um repositório separado no GitLab. Este artigo focará no teste de integração em um repositório (microsserviço) com dependências bloqueadas, que é de responsabilidade dos próprios desenvolvedores. A equipe de controle de qualidade está testando a interação dos microsserviços e não vou abordar esse tópico.
Quando entrei para a equipe, no final de 2016, havia aproximadamente o seguinte esquema de teste de integração:
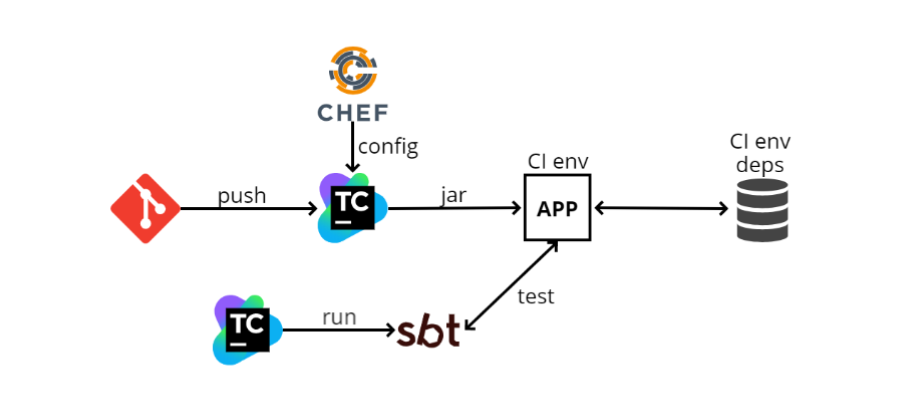
- O desenvolvedor envia seu código no GIT, após o qual o código do microsserviço entra no TeamCity. O TeamCity começa a criar código e executar testes.
- O TeamCity pega o arquivo de configuração (config) do Chef (um sistema de gerenciamento de configurações semelhante ao Ansible, escrito apenas em Ruby). O Chef também serve para automatizar a implantação. Quando tenho 100 máquinas, não quero ir a cada uma delas e instalar o que preciso no SSH, e o Chef me permite automatizar isso.
- O TeamCity coleta o arquivo jar (desde que escrevemos no Scala, o artefato que publicamos é o jar) e o programa o carrega no ambiente do IC. Nosso aplicativo é implantado lá, também existem algumas dependências. No diagrama, uma das dependências é representada como um banco de dados. Pode haver tantas dependências quanto possível e, graças ao Chef, nosso aplicativo as conhece e começa a interagir com elas.
- Em seguida, o TeamCity lança o SBT (este é o nosso sistema de compilação, onde a compilação e os testes são executados) e executa os próprios testes. Eles são relativamente semelhantes aos testes de unidade, mas trabalham principalmente com esse princípio: vá via http para um endereço específico, verifique algum método e veja o que ele retorna; ou faça alguma preparação e veja se o que é necessário retornou.
O que se pode dizer sobre esse esquema? Mais importante ainda, funciona. Quando tudo está configurado, a execução de testes é fácil, pois eles se parecem com testes de unidade. Mas as vantagens terminam aí.
E os contras começam.
O ambiente do IC está sempre ativado , e isso é um desperdício extra de recursos. Como o Chef é uma configuração estática, você sempre deve ter algum tipo de máquina onde todas as dependências serão configuradas, onde os aplicativos serão implantados independentemente. Essa máquina consumirá recursos extras, pois os testes são executados periodicamente e a máquina deve estar pronta o tempo todo. Além disso, o ambiente do IC está incluído em todas as dependências.
Não é possível executar testes em duas ramificações ao mesmo tempo . Isso segue o parágrafo anterior: como temos um ambiente, simplesmente não podemos executá-los em paralelo.
Não é possível testar iniciar, parar e reiniciar . Vou explicar por que isso é necessário: todas as nossas aplicações obedecem à lógica do chamado
desligamento normal , ou seja, quando obtemos o SIGTERM, não paramos o processo no meio, mas interceptamos esse sinal e entendemos que precisamos desligar o programa. Nesse ponto, certa lógica é ativada, por exemplo, as solicitações HTTP "em andamento" são processadas ou, se trabalhamos com o Kafka, cometemos todos os erros - em outras palavras, executamos determinadas ações para poder concluir o trabalho com segurança e depois, quando tudo estiver pronto, desligue.
Essa lógica nem sempre é simples e você pode testá-la com esse esquema apenas manualmente, porque a partir dos testes não controlamos o ciclo de vida do aplicativo. Acontece que o TeamCity de alguma forma implantou algo através do Chef, enquanto os testes estão em um estágio diferente e não sabem como o aplicativo é implantado.
O próximo ponto negativo é que é muito
difícil configurar tudo isso localmente . Ou seja, existem muitas dependências, elas têm suas próprias configurações, precisam ser geradas na máquina local. O próprio aplicativo também possui seu próprio arquivo de configuração, no qual existem muitos valores. Os testes em si têm uma configuração que precisa ser correspondida com a configuração do aplicativo e também pode haver mais de um valor de configuração. Parece que tudo isso não parece tão assustador, como "vá e conserte as configurações em três lugares", mas, na realidade, pode levar horas para os novos funcionários fazerem isso.
CI do GitLab + Docker
Com o tempo, esse esquema se transformou em outro:
GitLab CI e
Docker . Isso não aconteceu porque o esquema anterior não era o ideal, mas porque a empresa mudou ligeiramente de rumo em termos de organização administrativa.
Anteriormente, cada equipe, e nós temos muitos deles, como queríamos ou como poderíamos, e implantamos seu trabalho. Por exemplo, tínhamos TeamCity, Chef e outras equipes que poderiam usar Jenkins ou Ansible.
Agora estamos caminhando para a nuvem local e o Kubernetes, e há uma equipe separada que gerencia tudo isso, tanto o GitLab CI quanto o Kubernetes. Outras equipes apenas usam isso como um serviço. Isso é muito mais conveniente, pois você não precisa administrar tudo isso manualmente.
Usando o Kubernetes, implantamos o seguinte esquema:

- Em vez do TeamCity, o Gitlab CI agora é usado.
- O GitLab CI cria uma imagem do docker e a implanta no Kubernetes. A configuração agora é armazenada diretamente no repositório e não separadamente no Chef. Portanto, para a implantação, você não precisa trabalhar com um serviço de configuração de terceiros.
- As dependências são levantadas com antecedência, também no Kubernetes.
- Em seguida, o GitLab CI lança o SBT e os testes em uma etapa separada.
Tudo é bastante semelhante ao esquema anterior e não é fundamentalmente diferente, ou seja, até os prós e os contras serão exatamente os mesmos, mas o Docker aparece.
Com o docker, você pode fazer coisas diferentes e mais divertidas, e um deles é o docker-compondo.
Docker-compor
Esse é um tipo de "sobreposição" no Docker, que permite executar várias imagens do docker como uma única entidade.
Um bom exemplo de onde o docker-compose realmente ajuda é o Kafka. Ela precisa do ZooKeeper para executar. Se você levantar o Kafka e o ZooKeeper sem compor a janela de encaixe, precisará criar o ZooKeeper separadamente na janela de encaixe, separadamente - Kafka, e manter esses dois contêineres consistentes. Isso não é muito conveniente e o docker-compose permite que você descreva os dois contêineres em um arquivo docker-compose.yml e use o
docker-compose run Kafka simple
docker-compose run Kafka aumentar o Kafka e o ZooKeeper.
Você pode criar testes de integração na janela de encaixe-composição. Vamos ver como ficará.

- Mais uma vez, empurre tudo no GitLab.
- O GitLab CI lança a janela de encaixe-composição.
- No docker-compose, o aplicativo é ativado, todas as dependências e o SBT são ativados, e o SBT realiza os testes para esse aplicativo - tudo acontece dentro do docker-compondo.
Graças a esse esquema, não há necessidade de manter um ambiente e dependências separados, porque tudo vai diretamente para o corredor de IC do GitLab, onde apenas o docker e o docker-componham. Durante o início, ele irá bombear as imagens necessárias e executá-las.
Além disso, você pode testar diferentes ramos ao mesmo tempo, porque tudo acontece no corredor.
Agora
é mais fácil configurar o ambiente
localmente , mas você ainda precisa coordenar vários locais. O ponto é que agora, quando fazemos a configuração local, não precisamos colocar tudo na máquina local, tudo está escrito no arquivo docker-compose.yml. Portanto, você deve configurar em dois locais diferentes - este é o docker-compose.yml e a configuração dos nossos testes.
Quanto às desvantagens,
ainda é impossível testar iniciar, parar e reiniciar , porque a partir do SBT, a partir de testes, não controlamos o ciclo de vida do aplicativo. É executado pelo docker-compose, executa o SBT e os testes são executados no SBT. Portanto, não há gerenciamento de ciclo de vida completo do aplicativo. Também há dificuldades com o lançamento, sobre o qual gostaria de falar mais.
docker-compor 2
Nos dias de docker-compose 2, docker-compose.yml, o arquivo era assim:
version: '2.1' services: web: build: . depends_on: db: condition: service_healthy redis: condition: service_started redis: image: redis db: image: db healthcheck: test: "some test here"
Os serviços são registrados aqui, ou seja, o que iremos aumentar como parte dessa janela de encaixe. Nesse caso, apenas peguei um exemplo da documentação do docker-compose. Existem três serviços: web, redis e db (banco de dados).
Web é a nossa aplicação, e redis e db são algum tipo de dependência.
Há um item no bloco da Web chamado
depends_on . Isso sugere que o aplicativo Web depende de alguns outros contêineres e é descrito abaixo nos quais: do banco de dados e redis.
Além disso, há uma cláusula de
condition . Para redis, é
service_started , o que significa que, até que o redis seja iniciado, o contêiner não tentará iniciar o aplicativo da web.
Quanto ao banco de dados, sua condição é
service_healthy e a verificação de integridade é descrita abaixo. Ou seja, precisamos não apenas iniciar o contêiner do docker, mas também executar uma determinada verificação de integridade. Pode ser qualquer lógica personalizada.
Por exemplo, usamos o PostgreSQL, que usa a extensão PostGIS, e ele precisa de algum tempo para inicializar. Quando iniciamos o contêiner do docker, não podemos trabalhar imediatamente com a extensão postgis - precisamos aguardar a inicialização da extensão. Portanto, apenas
SELECT PostGIS_Version(); consultas
SELECT PostGIS_Version(); para
SELECT PostGIS_Version(); . Até que a extensão seja inicializada, a solicitação gerará um erro e, quando a extensão for inicializada, começará a retornar a versão. Isso é muito conveniente e lógico -
primeiro aumentaremos todas as dependências e depois o aplicativo .
docker-compor 3
Quando o docker-compose 3 saiu, começamos a usá-lo.
Mas na documentação para isso, um item apareceu na alteração da lógica depende_on. Os desenvolvedores do docker decidiram que uma descrição do gráfico de dependência era suficiente. Isso significa que, ao iniciar o
docker-compose run web , o aplicativo em si e o banco de dados do qual depende serão iniciados simultaneamente.

O próximo parágrafo da documentação diz que depende_on não é mais uma condição.
Portanto, se você ainda deseja obter a funcionalidade usada na segunda versão, precisará levar tudo em suas próprias mãos.
A página
Controlando pedidos de inicialização oferece várias soluções. A primeira opção é usar
wait-for-it.sh .
Agora o docker-compose.yml parece um pouco diferente:
version: '3' services: web: build: . depends_on: [ db, redis ] redis: image: redis command: [ "./wait-for-it.sh", ... ] db: image: redis command: [ "./wait-for-db.sh", ... ]
depends_on é apenas uma matriz, não há condições.
Em nossas dependências, redefinimos o comando, ou seja, no docker-compose você pode anexar um comando com o qual o contêiner do docker é iniciado.
Lá devemos escrever wait-for-it.sh, e outra coisa. Em vez dos três pontos no exemplo acima, devemos escrever o que precisamos esperar, bem como o comando original que inicia o contêiner do docker.
Para fazer isso, você precisa encontrar o arquivo docker, copiar o comando para redis e colá-lo, o mesmo vale para o banco de dados. Uma
desvantagem enorme é que a
abstração é interrompida - não quero saber qual comando inicia o contêiner do docker. Esses comandos podem não ser triviais, muito complexos, mas não quero me preocupar, só quero inserir o
docker run e é isso.
Pessoalmente, não gosto muito dessa solução, mas tínhamos alguns serviços que funcionam assim.
Script na parte superior da janela de encaixe
Então decidi que havia chegado a hora de "
construir bicicletas" e tinha o
docker-compose-run.sh :
version: '3' services: postgres: ... my_service: depends_on: [ postgres ] ... sbt: depends_on: [ my_service ] ...
Deixe-me dar um exemplo semi-realista: existe o postgres no docker-compose.yml, existe o aplicativo my_service, que depende do postgres, e o SBT, no qual os testes são executados e o que depende do meu serviço.
Eu executo o programa não através da
docker run , mas através do script docker-compose-run.sh.
Primeiro, ele inicia a dependência mais profunda primeiro, no meu caso, é o postgres. O script inicia a dependência no modo "daemon", ou seja, não bloqueia o terminal:
docker-compose up -d postgres
Então, espero que a condição seja atendida pela função wait_until. É quase o mesmo que wait-for-it.sh, apenas, por assim dizer, em um estilo imperativo. Enquanto o PostGIS está inicializando, o terminal está bloqueado, ou seja, o programa também espera e, se não esperar, um erro é gerado e os testes param de funcionar.
wait_until 10 2 docker-compose exec -T postgres psql
Quando o PostGIS for inicializado, continue com a próxima etapa e faça o mesmo com o serviço. Para ele, o teste é um pouco mais simples: a porta 80 deve ser ligada.
docker-compose up -d my_service wait_until 10 2 docker-compose exec -T \ my_service sh -c "netstat -ntlp | grep 80 || exit 1"
A última etapa é executar o SBT através do comando run, no qual os testes são executados.
docker-compose run sbt down $?
Assim, tudo é gerado na ordem correta, mas manualmente.
No final, a função
down é chamada, que aceita o resultado do comando anterior. Se for "0", os testes foram aprovados e simplesmente desativamos o docker-composite; caso contrário, primeiro "cuspimos" os logs para descobrir o que deu errado e, em seguida, desativamos o docker-compondo.
function down { echo "Exiting with code $1" if [[ $1 -eq 0 ]]; then docker-compose down exit $1 else docker-compose logs -t postgres my_service docker-compose down exit $1 fi }
Esse esquema funciona, mas não escala bem. Cada serviço precisará descrever seu docker-compose-run.sh com sua própria lógica. Além disso, a configuração de inicialização se estende entre o docker-compose-run.sh e o docker-compose.yml. Bem, em geral, parece que não estamos usando o docker-compose, mas estamos lutando com suas deficiências.
Executando a janela de encaixe a partir do código
Quando o esquema anterior foi criado, pensei: se eu já tenho tudo na janela de encaixe, por que não executá-lo a partir do código? Comecei a procurar uma solução e encontrei várias opções.
A primeira opção é simplesmente
usar o cliente docker . Existem dois principais clientes docker no mundo da JVM:
docker-java e
spotify docker-client .
O cliente docker permite executar comandos do docker diretamente do código usando a API. Ou seja, em vez de concatenar cadeias para criar comandos como
`docker run ...` , você pode simplesmente formar um comando no código e executá-lo. É muito mais conveniente.
Esse método funciona bem e, com certeza, eles podem fazer tudo, no entanto, esse é um nível muito baixo. Eu teria que criar meu próprio analógico de docker-compositing, que é uma tarefa muito grande.
A próxima opção é a
biblioteca docker-it-scala , que agrupa esses dois clientes e permite escolher qual back-end usar. Ela pode executar os contêineres que você precisa.
Mas o menos desta biblioteca é que ela não possui uma API muito flexível e não há controle do ciclo de vida.
Também não gostei dessa opção, continuei pesquisando e encontrei os
contêineres de teste . Eu gostaria de lhe contar mais sobre isso.
Contêineres de teste
Esse é um tipo de biblioteca java para iniciar e testar contêineres de docker. Há uma fachada Scala, testcontainers-scala. Fora da caixa, existem vários serviços populares, por exemplo, PostgreSQL, MySQL, Nginx, Kafka, Selenium. Você pode executar qualquer outro contêiner. A biblioteca possui uma API bastante simples e flexível, na qual vou me aprofundar mais detalhadamente.
Contêineres predefinidos
Então, como trabalhar com contêineres predefinidos, que estão na biblioteca: de fato, tudo é bem simples, pois os contêineres são representados como objetos:
val pgContainer: PostgreSQLContainer = PostgreSQLContainer("postgres:9.6") pgContainer.start() val pgUrl: String = pgContainer.jdbcUrl val pgPort: Int = pgContainer.mappedPort(5432) pgContainer.stop()
Nesse caso, criamos o
PostgreSQLContainer , podemos iniciá-lo e começar a trabalhar com ele. Em seguida, obtemos o
jbdcUrl , com o qual você pode se conectar ao PostgreSQL. Depois disso, temos o
mappedPort .
Isso significa que o PostgreSQL se destaca da porta 5432 do docker, e o Testcontainers vê essa porta e a atribui automaticamente a alguma porta aleatória. Ou seja, a partir dos testes que vemos, por exemplo, 32422. A atribuição acontece automaticamente.
Contêiner personalizado
A seguinte exibição, o chamado contêiner personalizado, também é bastante simples:
class GenericContainer( imageName: String, exposedPorts: Seq[Int] = Seq(), env: Map[String, String] = Map(), command: Seq[String] = Seq(), classpathResourceMapping: Seq[(String, String, BindMode)] = Seq(), waitStrategy: Option[WaitStrategy] = None ) ...
Há um
GenericContainer do qual você precisa herdar e substituir vários campos. Certifique-se de definir apenas
imageName - este é o nome do contêiner que queremos criar.
Você pode definir
exposedPorts : aquelas portas que o contêiner se destacará. No env, você pode definir variáveis de ambiente e também definir o
command para executar.
classpathResourceMapping permite lançar recursos do caminho de classe no contêiner do Docker. Isso é muito conveniente, por exemplo, se a configuração do aplicativo estiver diretamente nos recursos de teste. Você simplesmente mapeia o interior, e o aplicativo dentro do docker obtém acesso a essa configuração.
waitStrategy é uma coisa muito conveniente que estava faltando no docker-compose 3; na verdade, é o HealthCheck. Existem várias
waitStrategy predefinidas, por exemplo, você pode esperar até que uma ligação de porta ocorra ou um método http específico retornará 200. Mas você pode gravar qualquer um dos seus HealthCheck.
Como você escreve o HealthCheck simplesmente no seu código, você pode usar, primeiro, um idioma normal, não o bash, e, segundo, quaisquer bibliotecas disponíveis no seu código: se você deseja criar o HealthCheck personalizado no Cassandra - leve o driver e escreva qualquer HealthCheck.
Executando testes
E agora um pouco sobre como executar testes:
class PostgresqlSpec extends FlatSpec with ForAllTestContainer { override val container = PostgreSQLContainer() "PostgreSQL container" should "be started" in { Class.forName(container.driverClassName) val connection = DriverManager .getConnection(container.jdbcUrl, container.username, container.password) // test some stuff } }
Vou falar sobre o
ScalaTest , o padrão de fato para testes no mundo do Scala.
Por exemplo, queremos escrever testes para o Postgres. Crie um teste
PostgresqlSpec e herde-o do
ForAllTestContainer . Essa é uma característica fornecida pela biblioteca. Ele iniciará os contêineres necessários antes de todos os testes e os interromperá após todos os testes. Ou você pode usar o
ForeachTestContainer , em seguida, os contêineres iniciam antes de cada teste e param depois de cada um deles.
Então você precisa redefinir o contêiner. Isso pode ser feito substituindo a propriedade do
container . No meu caso, estou usando o
PostgreSQLContainer .
Então escrevemos testes. No exemplo, eu crio uma conexão, recebo jdbcUrl, nome de usuário, senha, escreva testes específicos, envie solicitações.
Normalmente, os testes de integração requerem vários contêineres. Eu posso criá-los usando
MultipleContainers :
val pgContainer = PostgreSQLContainer() val myContainer = MyContainer() override val container = MultipleContainers(pgContainer, myContainer)
Ou seja, eu crio contêineres, os adiciono a
MultipleContainers e os uso como
container .
O esquema para executar testes com Testcontainers é o seguinte:

- Empurre o código no GitLa.
- O corredor de CI do GitLab lança o SBT.
- O SBT executa testes. Dentro dos testes, nosso aplicativo e dependências são lançados.
As vantagens deste esquema:
- Não há necessidade de manter um ambiente e dependências separados, tudo acontece no corredor.
- Você pode testar diferentes ramos ao mesmo tempo.
- Você pode testar iniciar, parar e reiniciar, porque podemos controlar o ciclo de vida do aplicativo (tudo começa no código de teste).
- Existem HealthChecks flexíveis que estavam em falta.
- Não há arquivos * .sh no repositório, você pode configurar os testes no aplicativo da maneira mais flexível possível.
- Graças ao mapeamento classpathResource, você pode usar a mesma configuração nos testes e no aplicativo.
- Você pode configurar testes a partir do código.
- Tudo isso é executado com a mesma facilidade tanto no IC quanto no local, porque esses são apenas testes que parecem e são executados como testes de unidade, apenas tudo acontece no contêiner do docker.
Acontece que tudo é suspeito e bom, mas isso é apenas à primeira vista; de fato, encontramos vários problemas.
Contêineres dependentes
O primeiro problema que encontramos foram os
contêineres dependentes . Digamos que exista algum tipo de teste:
class MySpec extends FlatSpec with ForAllTestContainer { val pgCont = PostgreSQLContainer() val appCont = AppContainer(pgCont.jdbcUrl, pgCont.username, pgCont.password) override val container = MultipleContainers(appCont, pgCont) // tests here }
Executa o postgres e o AppContainer. O appContainer do postgres recebe jdbcUrl, o nome de usuário e a senha da conexão. Em seguida, MultipleContainers é criado e o próprio teste é descrito.
Eu executo o programa e vejo um erro:
Exception encountered when invoking run on a nested suite - Mapped port can only be obtained after the container is started
O ponto é que a porta atribuída não pode ser tomada até que o contêiner seja iniciado. Por que isso está acontecendo?
O fato é que
ForAllTestContainer ou
ForEachTestContainer iniciam contêineres imediatamente antes dos testes e não no momento em que crio instâncias de contêiner. Acontece que, no momento em que crio o AppContainer, ainda não tenho o
PostgreSQLContainer ativado, o que significa que não consigo obter a porta atribuída e preciso que ela forme
jdbcUrl .
O problema é que a essência do contêiner é mutável: possui vários estados. Por exemplo, pode ser desligado e ligado.
Como resolver este problema? O primeiro método que eu chamaria de "preguiçoso".
class MyTest extends FreeSpec with BeforeAndAfterAll { lazy val pgCont = PostgreSQLContainer() lazy val appCont = AppContainer(pgCont.jdbcUrl, pgCont.username, pgCont.password) override def beforeAll(): Unit = { super.beforeAll() pgCont.start() appCont.start() } override def afterAll(): Unit = { super.afterAll() appCont.stop() pgCont.stop() } // tests here }
A idéia principal é criar contêineres usando
val preguiçoso . Então eles não serão inicializados imediatamente no construtor de teste, mas aguardarão a primeira chamada. Inicializaremos nos
afterAll e
afterAll , fornecidos pela
BeforeAndAfterAll BeforeAndAfterAll do ScalaTest. No
beforeAll contêineres são iniciados e no
afterAll , eles são desativados. Como os contêineres são declarados preguiçosos, no momento em que o método start é chamado beforeAll, eles serão criados, inicializados e iniciados.
No entanto, ainda ocorre um erro que não consigo ingressar no localhost: 32787:
org.postgresql.util.PSQLException: Connection to localhost:32787 refused. Check that the hostname and port are correct and that the postmaster is accepting TCP/IP connections.
Parece que usamos o jdbcUrl, por que o localhost aparece? Vamos ver como o jdbcUrl funciona:
@Override public String getJdbcUrl() { return "jdbc:postgresql://" + getContainerIpAddress() + ":" + getMappedPort(POSTGRESQL_PORT) + "/" + databaseName; }
É apenas uma concatenação de strings. Tudo fica claro com constantes, elas não podem quebrar.
getMappedPort deve funcionar, porque já o corrigimos.
databaseName é uma constante codificada. Mas com
getContainerIpAddress mais interessante. Por nome, podemos assumir que ele deve retornar o endereço IP do contêiner. Mas se você executar esse código, ele sempre retornará localhost. Como se viu, esse método não se destina à interação entre contêineres:
getContainerIpAddress fornece interação a partir de testes dentro do contêiner .
Recomendação do desenvolvedor de testcontainers:
crie uma rede personalizada para comunicação entre contêineres . O Docker-compose funciona assim: cria uma rede e resolve tudo por conta própria.
Então você precisa criar uma rede.
class MyTest extends FreeSpec with BeforeAndAfterAll { val network: Network = Network.newNetwork() val dbName = "some_db" val pgContainerAlias = "postgres" val jdbcUrl = s"jdbc:postgresql://$pgContainerAlias:5432/$dbName" lazy val pgCont = { val c = PostgreSQLContainer("postgres:9.6") c.container.withNetwork(network) c.container.withNetworkAliases(pgContainerAlias) c.container.withDatabaseName(dbName) c } lazy val appCont = { val c = AppContainer(jdbcUrl, pgCont.username, pgCont.password) c.container.withNetwork(network) c } override def beforeAll(): Unit = { super.beforeAll() pgCont.start() appCont.start() } override def afterAll(): Unit = { super.afterAll() appCont.stop() pgCont.stop() network.close() } // tests here }
Agora temos que configurar manualmente nosso jdbcUrl. Também precisamos ativar nossos contêineres na rede e definir o alias para o PostgreSQLContainer para que ele seja acessível na rede por algum nome de domínio. No final, você deve se lembrar de "matar" a rede.
Finalmente, esse programa funcionará.
Nas versões recentes do testcontainers-scala, a inicialização lenta do contêiner é suportada imediatamente:
class MyTest extends FreeSpec with ForAllTestContainer with BeforeAndAfterAll { val network: Network = Network.newNetwork() val dbName = "some_db" val pgContainerAlias = "postgres" val jdbcUrl = s"jdbc:postgresql://$pgContainerAlias:5432/$dbName" lazy val pgCont = { val c = PostgreSQLContainer("postgres:9.6") c.container.withNetwork(network) c.container.withNetworkAliases(pgContainerAlias) c.container.withDatabaseName(dbName) c } lazy val appCont = { val c = AppContainer(jdbcUrl, pgCont.username, pgCont.password) c.container.withNetwork(network) c } override val container = MultipleContainers(pgCont, appCont) override def afterAll(): Unit = { super.afterAll() network.close() } // tests here }
Você pode usar
ForAllTestContainer e
MultipleContainers novamente. No
beforeAll não precisa mais
beforeAll manualmente
beforeAll ordem de início. Agora
MultipleContainers pode trabalhar com val lento e executá-los na ordem correta, e não faz inicialização estrita imediatamente após a criação. Ao mesmo tempo, as manipulações com a rede personalizada e o jdbcUrl também precisam ser feitas manualmente.
Zombaria
No entanto, ainda existem problemas. Por exemplo moki. Às vezes, não é muito conveniente criar algum tipo de dependência em um contêiner de docker. Usamos o Spark JobServer, que cria tarefas do Spark e controla seu ciclo de vida no Spark. Usamos dois de seus métodos: "create" e "give status".
Para executar o Spark JobServer dentro da janela de encaixe. É necessário elevar o Spark e, até recentemente, ele não possuía um contêiner de ancoragem e era necessário montá-lo você mesmo. Além disso, o Spark JobServer usa o PostgreSQL para armazenar estados. Como resultado, você precisa fazer muito trabalho difícil quando realmente precisa apenas de dois métodos com uma API simples.
Mas você pode espiar a implementação do Spark JobServer e criar uma simulação que se comporta da mesma maneira, mas não requer as dependências do Spark JobServer original.
Parece com isso (no exemplo, um pseudocódigo simplificado):
val hostIp = ??? AppContainer(sparkJobServerMockHost = hostIp) val sparkJobServerMock = new SparkJobServerMock() sparkJobServerMock.init(someData) val apiResult = appApi.callMethod() assert(apiResult == someData)
http- API Spark JobServer. - , . , , , mock.
- , . : «» config; , host.
SparkJobServerMock , host-, docker-, , , docker-.
? docker-, , gateway , docker-.
, Testcontainers API. , Testcontainers docker-java-, . «» docker-:
val client: com.github.dockerjava.api.DockerClient = DockerClientFactory .instance .client val networkInfo: com.github.dockerjava.api.model.Network = client .inspectNetworkCmd() .withNetworkId(network.getId) .exec() val hostIp: String = networkInfo .getIpam .getConfig .get(0) .getGateway
-,
DockerClient . Testcontainers
DockerClientFactory . c
inspectNetworkCmd . , info, gateway.
, , .
— . Docker : Windows, Mac, . Linux. , , Linux .
, Testcontainers . , docker-. :
Testcontainers.exposeHostPorts(sparkJobServerMockPort)
,
. docker-.
`host.testcontainers.internal` .
, :
val sparkJobServerMockHost = "host.testcontainers.internal" val sparkJobServerMockPort = 33333 Testcontainers.exposeHostPorts(sparkJobServerPort) AppContainer(sparkJobServerMockHost, sparkJobServerMockPort)
Testcontainers
, , Testcontainers , . Java-, Scala-. :
- . , testcontainers-java JUnit, testcontainers-scala ScalaTest, testcontainers-java . Scala- .
- Scala . . , . , predefined Java-. , .
- API . API, . , . , , .
Sumário
. Docker , , , , network gateway.
Testcontainers — , . API , .
Java-, . — . .
, docker-, .
— , , , . .?, .
— - ?Kubernetes, . end-to-end , , , , .
, , unit-, .
— Kubernetes ?-, , -, , , , Spark Kubernetes ; , .
, , unit-, , , break point , , .
, , , CI , .
, minicube — Mac, . , , , , .
— ? : master? , - , , 2.1, 2.2, ?ImageName, Postgres 9.6.
val pgContainer: PostgreSQLContainer = PostgreSQLContainer("postgres:9.6")
9.6, 10. [ ], .
Image tag — , — , . , latest .
— , ?, CI , GitLab CI , , Branch Name.
— , , , ? - , ? 20- , ?-, , . , , , , , .
- , , full-time , , , .
commit', , , , Android, iOS . . , , , , — .
, , -: - , - . , - .
Deseja mais detalhes sobre os microsserviços e não apenas sobre o Scala - nosso programa ScalaConf tem respostas para várias perguntas. Mais interessados na arquitetura e nas interconexões de suas várias partes - visite o HighLoad ++ nos dias 7 e 8 de novembro.
Tudo é muito saboroso, e não está claro o que escolher; em seguida, assine a newsletter em que falamos sobre relatórios e coletamos materiais úteis sobre o assunto.