O tema Captcha não é novo, inclusive para Habr. No entanto, os algoritmos captcha estão mudando, assim como os algoritmos para resolvê-los. Portanto, propõe-se lembrar o antigo e operar a seguinte versão do captcha:

Ao longo do caminho, entenda o trabalho de uma simples rede neural na prática e também melhore seus resultados.
Imediatamente faça uma reserva de que não entraremos em pensamentos sobre como o neurônio funciona e o que fazer com tudo isso, o artigo não afirma ser científico, mas fornece apenas um pequeno tutorial.
Dançar do fogão. Em vez de se juntar
Talvez as palavras de alguém sejam repetidas, mas a maioria dos livros sobre Deep Learning começa realmente com o fato de o leitor receber dados pré-preparados com os quais ele começa a trabalhar. De alguma forma MNIST - 60.000 dígitos manuscritos, CIFAR-10, etc. Após a leitura, uma pessoa sai preparada ... para esses conjuntos de dados. Não está totalmente claro como usar seus dados e, o mais importante, como melhorar algo ao criar sua própria rede neural.
É por isso que o artigo no
pyimagesearch.com sobre como trabalhar com seus próprios dados, bem como sua
tradução, foi muito útil.
Mas, como se costuma dizer, o rabanete não é mais doce: mesmo com a tradução do artigo mastigado sobre keras, há muitos pontos cegos. Novamente, é oferecido um conjunto de dados pré-preparado, apenas com gatos, cães e pandas. Tem que preencher os vazios você mesmo.
No entanto, este artigo e código serão tomados como base.
Coletamos dados no captcha
Não há nada de novo aqui. Precisamos de amostras captcha, como a rede aprenderá com eles sob nossa orientação. Você pode extrair o captcha você mesmo, ou pode levar um pouco aqui -
29.000 captchas . Agora você precisa cortar os números de cada captcha. Não é necessário cortar todos os 29.000 captcha, especialmente porque 1 captcha fornece 5 dígitos. 500 captcha será mais que suficiente.
Como cortar? É possível no Photoshop, mas é melhor ter uma faca melhor.
Então, aqui está o código da faca python -
download . (para Windows. Primeiro crie as pastas C: \ 1 \ test e C: \ 1 \ test-out).
A saída será um dump de números de 1 a 9 (não há zeros no captcha).
Em seguida, é necessário analisar esse bloqueio dos números em pastas de 1 a 9 e colocar em cada pasta pelo número correspondente. Mais ou menos ocupação. Mas em um dia você pode obter até 1000 dígitos.
Se, ao escolher uma figura, torna-se dúvida qual dos números, é melhor excluir esta amostra. E tudo bem se os números forem barulhentos ou entrarem incompletamente no "quadro":


Você precisa coletar 200 amostras de cada dígito em cada pasta. Você pode delegar esse trabalho a serviços de terceiros, mas é melhor fazer tudo sozinho para não procurar números correspondentes incorretamente mais tarde.
Rede neural. Teste
Tyat, tyat, nossas redes arrastaram o homem mortoAntes de começar a trabalhar com seus próprios dados, é melhor seguir o artigo acima e executar o código para entender que todos os componentes (keras, tensorflow etc.) estão instalados e funcionando corretamente.
Usaremos uma rede simples cuja sintaxe de inicialização é da linha de comando (!):
python train_simple_nn.py --dataset animals --model output/simple_nn.model --label-bin output/simple_nn_lb.pickle --plot output/simple_nn_plot.png
* O Tensorflow pode escrever ao trabalhar com erros em seus próprios arquivos e métodos obsoletos, você pode corrigi-lo manualmente ou simplesmente ignorá-lo.
O principal é que, após a conclusão do programa, dois arquivos aparecem na pasta do projeto: simple_nn_lb.pickle e simple_nn.model, e a imagem do animal com uma taxa de inscrição e reconhecimento é exibida, por exemplo:

Rede neural - dados próprios
Agora que o teste de integridade da rede foi verificado, você pode conectar seus próprios dados e começar a treinar a rede.
Coloque nas pastas da pasta dat com números que contêm amostras selecionadas para cada dígito.
Por conveniência, colocaremos a pasta dat na pasta do projeto (por exemplo, ao lado da pasta animals).
Agora, a sintaxe para iniciar o aprendizado em rede será:
python train_simple_nn.py --dataset dat --model output/simple_nn.model --label-bin output/simple_nn_lb.pickle --plot output/simple_nn_plot.png
No entanto, é muito cedo para começar o treinamento.
Você precisa corrigir o arquivo train_simple_nn.py.
1. No final do arquivo:
Isso adicionará informações.
2)
image = cv2.resize(image, (32, 32)).flatten()
mude para
image = cv2.resize(image, (16, 37)).flatten()
Aqui redimensionamos a imagem de entrada. Por que exatamente esse tamanho? Como a maioria dos dígitos cortados tem esse tamanho ou é reduzida a ele. Se você dimensionar para 32x32 pixels, a imagem ficará distorcida. Sim, e por que fazer isso?
Além disso, colocamos essa alteração em teste:
try: image = cv2.resize(image, (16, 37)).flatten() except: continue
Porque o programa não pode digerir algumas fotos e problemas Nenhum, portanto, elas são ignoradas.
3. Agora, a coisa mais importante. Onde há um comentário no código
definir arquitetura 3072-1024-512-3 com Keras
A arquitetura de rede no artigo é definida como 3072-1024-512-3. Isso significa que a rede recebe 3072 (32 pixels * 32 pixels * 3) na entrada, depois na camada 1024, na camada 512 e na saída 3 opções - um gato, um cachorro ou um panda.
No nosso caso, a entrada é 1776 (16 pixels * 37 pixels * 3), depois a camada 1024, a camada 512, na saída de 9 variantes de números.
Portanto, nosso código:
model.add(Dense(1024, input_shape=(1776,), activation="sigmoid"))model.add(Dense(512, activation="sigmoid"))
* 9 saídas não precisam ser indicadas adicionalmente, porque o próprio programa determina o número de saídas pelo número de pastas no conjunto de dados.
Lançamos
python train_simple_nn.py --dataset dat --model output/simple_nn.model --label-bin output/simple_nn_lb.pickle --plot output/simple_nn_plot.png
Como as imagens com números são pequenas, a rede aprende muito rapidamente (5 a 10 minutos), mesmo em hardware fraco, usando apenas a CPU.
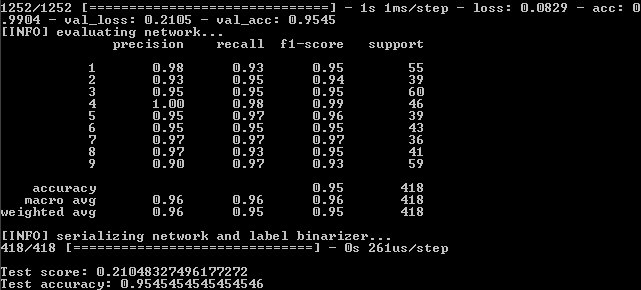
Depois de executar o programa na linha de comandos, consulte os resultados:
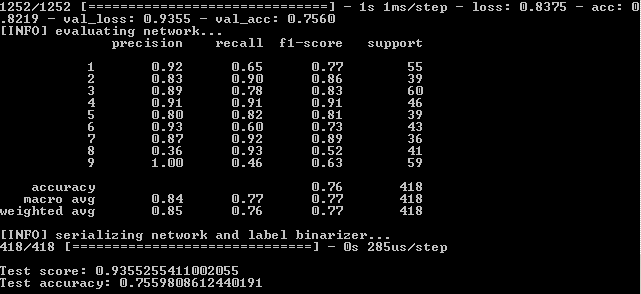
Isso significa que, no conjunto de treinamento, a fidelidade foi alcançada - 82,19%, no controle - 75,6% e no teste - 75,59%.
Precisamos nos concentrar no último indicador em sua maior parte. Por que os outros também são importantes, será explicado mais adiante.
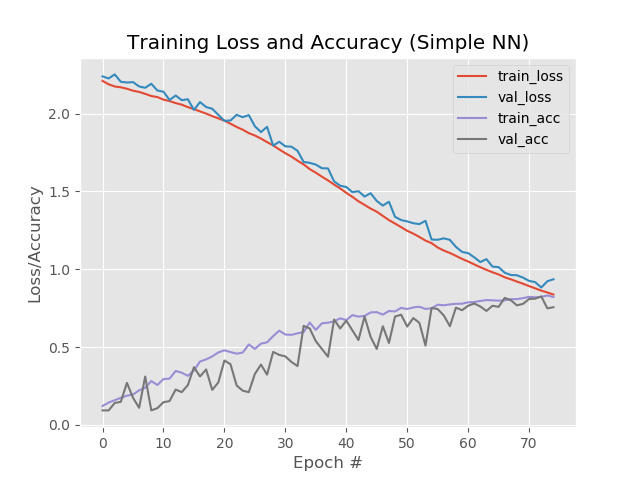
Vamos também ver a parte gráfica do trabalho da rede neural. Está na pasta de saída do projeto simple_nn_plot.png:
Mais rápido, mais alto, mais forte. Melhorando resultados
Um pouco sobre como configurar uma rede neural, veja
aqui .
A opção autêntica é a seguinte.
Adicione eras.
No código, mudamos
EPOCHS = 75
em
EPOCHS = 200
Aumente o "número de vezes" em que a rede passará por treinamento.
Resultado:
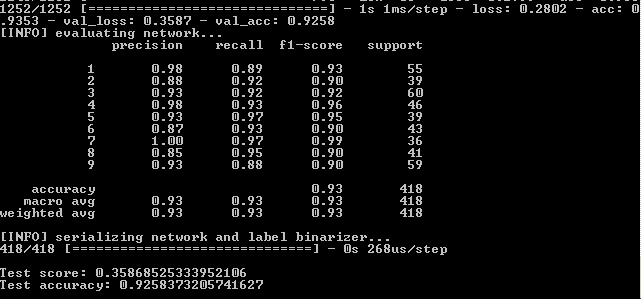
Assim, 93,5%, 92,6%, 92,6%.
Nas imagens:
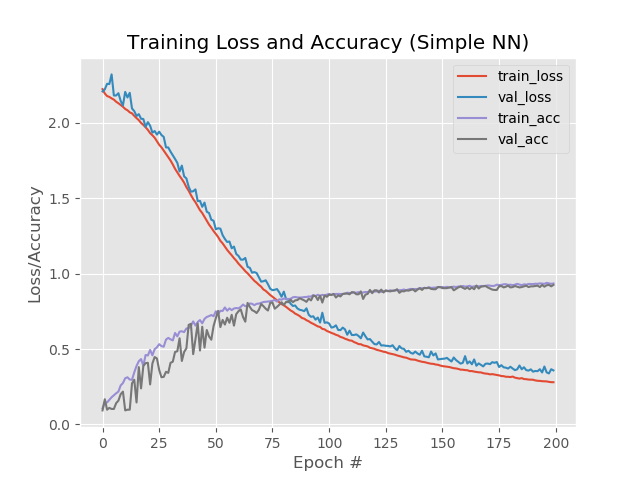
Aqui é perceptível que as linhas azul e vermelha após a 130ª era começam a se dispersar, e isso diz que um aumento adicional no número de épocas não funcionará. Veja isso.
No código, mudamos
EPOCHS = 200
em
EPOCHS = 500
e fugir novamente.
Resultado:
Então nós temos:
99%, 95,5%, 95,5%.
E no gráfico:
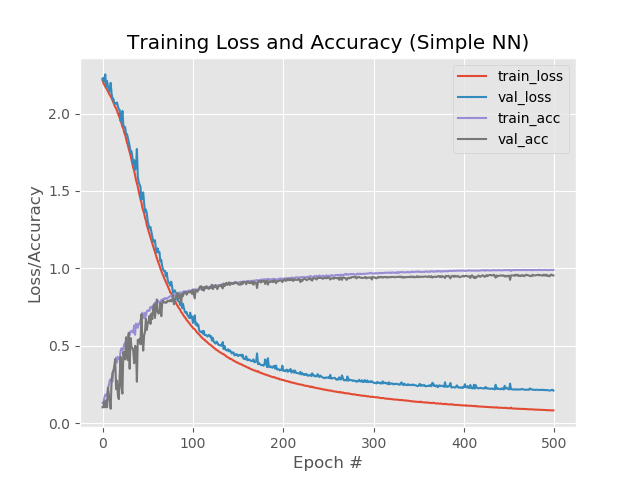
Bem, o aumento no número de épocas foi claramente para a rede. No entanto, esse resultado é enganoso.
Vamos verificar a operação da rede usando um exemplo real.
Para esses fins, o script predict.py está na pasta do projeto. Antes de começar, prepare.
Na pasta de imagens do projeto, colocamos os arquivos com as imagens dos números do captcha, que a rede não havia encontrado anteriormente no processo de aprendizado. I.e. é necessário obter dígitos que não sejam do dat dataset dat.
No próprio arquivo, corrigimos duas linhas para o tamanho padrão da imagem:
ap.add_argument("-w", "--width", type=int, default=16, help="target spatial dimension width") ap.add_argument("-e", "--height", type=int, default=37, help="target spatial dimension height")
Execute a partir da linha de comando:
python predict.py --image images/1.jpg --model output/simple_nn.model --label-bin output/simple_nn_lb.pickle --flatten 1
E vemos o resultado:
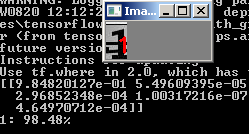
Outra foto:
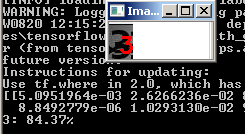
No entanto, ele não funciona com todos os números ruidosos:
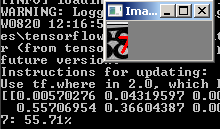
O que pode ser feito aqui?
- Aumente o número de cópias de números nas pastas para treinamento.
- Tente outros métodos.
Vamos tentar outros métodos
Como você pode ver no último gráfico, as linhas azul e vermelha divergem em torno da 130ª era. Isso significa que o aprendizado após a 130ª era é ineficaz. Fixamos o resultado na 130ª época: 89,3%, 88%, 88% e verificamos se outros métodos para melhorar a rede funcionam.
Reduza a velocidade do aprendizado. INIT_LR = 0.01
em
INIT_LR = 0.001
Resultado:
41%, 39%, 39%
Bem, por.
Adicione uma camada oculta adicional. model.add(Dense(512, activation="sigmoid"))
em
model.add(Dense(512, activation="sigmoid")) model.add(Dense(258, activation="sigmoid"))
Resultado:
56%, 62%, 62%
Melhor, mas não.
No entanto, se você aumentar o número de eras para 250:
84%, 83%, 83%
Ao mesmo tempo, as linhas vermelha e azul não se separam após a 130ª era:
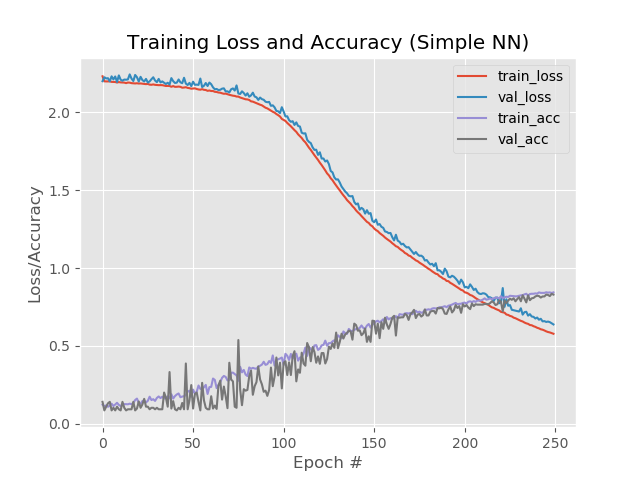 Economize 250 eras e aplique o desbaste
Economize 250 eras e aplique o desbaste :
from keras.layers.core import Dropout
Insira o desbaste entre as camadas:
model.add(Dense(1024, input_shape=(1776,), activation="sigmoid")) model.add(Dropout(0.3)) model.add(Dense(512, activation="sigmoid")) model.add(Dropout(0.3)) model.add(Dense(258, activation="sigmoid")) model.add(Dropout(0.3))
Resultado:
53%, 65%, 65%
O primeiro valor é mais baixo que o restante, isso indica que a rede não está aprendendo. Para fazer isso, é recomendável aumentar o número de eras.
model.add(Dense(1024, input_shape=(1776,), activation="sigmoid")) model.add(Dropout(0.3)) model.add(Dense(512, activation="sigmoid")) model.add(Dropout(0.3))
Resultado:
88%, 92%, 92%
Com 1 camada extra, desbaste e 500 eras:
model.add(Dense(1024, input_shape=(1776,), activation="sigmoid")) model.add(Dropout(0.3)) model.add(Dense(512, activation="sigmoid")) model.add(Dropout(0.3)) model.add(Dense(258, activation="sigmoid"))
Resultado:
92,4%, 92,6%, 92,58%
Apesar de uma porcentagem menor em comparação com um simples aumento de eras para 500, o gráfico parece mais uniforme:
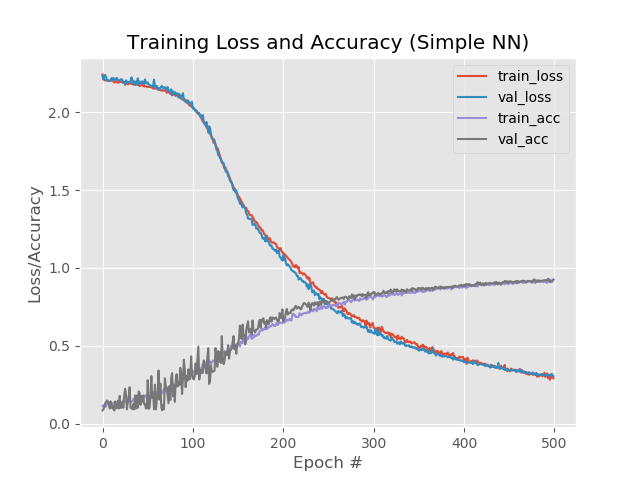
E a rede processa imagens que caíram anteriormente:
Agora, coletaremos tudo em um arquivo, que cortará a imagem com o captcha na entrada em 5 dígitos, executará cada dígito na rede neural e enviará o resultado ao intérprete python.
Aqui é mais simples. No arquivo que nos cortou os números do captcha, adicione o arquivo que lida com previsões.
Agora, o programa não apenas corta o captcha em 5 partes, mas também exibe todos os números reconhecidos no intérprete:

Novamente, é preciso lembrar que o programa não fornece 100% do resultado e, geralmente, um dos 5 dígitos está incorreto. Mas este é um bom resultado, considerando que no conjunto de treinamento existem apenas 170-200 cópias para cada número.
O reconhecimento Captcha dura de 3 a 5 segundos em um computador de potência média.
De que outra forma você pode tentar melhorar a rede? Você pode ler no livro "Biblioteca Keras - uma ferramenta de aprendizado profundo" A. Dzhulli, S. Pala.
O script final que corta o captcha e reconhece está
aqui .
Começa sem parâmetros.
Scripts reciclados para
treinamento e
teste da rede.
Captcha para o teste, inclusive com falsos positivos -
aqui .
O modelo para o trabalho está
aqui .
Os números nas pastas estão
aqui .