No mundo da criptografia, existem muitas maneiras fáceis de criptografar uma mensagem. Cada um deles é bom à sua maneira. Um deles será discutido.
Ylchu Schzzkgow
Ou traduzido de "Cifra de César" para o russo - Cifra de César .

- Qual é a sua essência?
- Ele codifica a mensagem, trocando cada letra por N pontos. A cifra clássica de César move as letras três passos à frente. Em palavras simples - era "abv", tornou-se "onde".
"Mas e as letras no final do alfabeto?" E os espaços?
Eles estão bem. Se mudar a letra, a cifra vai além do escopo do alfabeto - começa a contar novamente. Ou seja, as letras "Eyuya" se transformam em "abv". E os espaços permanecem espaços.
- N deve necessariamente ser igual a três?
Nem um pouco. N pode diferir de três. Qualquer N entre [1: M-1] é permitido, onde M é o número de letras no alfabeto.
É fácil decifrar essa cifra se você souber sobre a sua existência. Mas não foi sua "confiabilidade" que me atraiu, mas outra coisa.
Gravata
Um dia de verão, eu queria saber:
- Mas e se eu criptografar uma palavra usando César e obter uma palavra existente na saída?
- Quantas palavras são "shifters"?
- E haverá um padrão se N for alterado?
Comecei a procurar respostas para essas perguntas nos mesmos minutos.
Tarefa: Encontre todas as palavras
Retiro. Dos shows de Mikhail Zadornov e da experiência pessoal, entendi duas coisas:
- Os americanos não se ofendem com o discurso de comediantes russos.
- A língua russa é forte e poderosa. E há muitas palavras nele.
Por isso, decidi tomar o idioma inglês como minha base. Além disso, era uma vez uma informação de que os que falam inglês conseguiram montar um dicionário completo de palavras em inglês. O que me levou a encontrar esse conjunto de dados.
A primeira linha de pesquisa lenta me levou a este repositório . O autor prometeu 479 mil palavras em inglês em formatos convenientes. Gostei do arquivo json, no qual todas as palavras foram dispostas de forma conveniente para serem carregadas no dicionário Python.
Após a primeira autópsia, verificou-se que havia menos palavras - 370 101 peças. "Mas isso não importa, porque, para um bom exemplo, será suficiente", pensei.
words = json.load(open('words_dictionary.json', 'r')) len(words.keys()) >> 370101
Primeiro você precisa criar um alfabeto. Decidi fazer uma lista da maneira mais conveniente para mim. Também era necessário lembrar o número de letras no alfabeto:
abc = list('abcdefghijklmnopqrstuvwxyz') abc_len = len(abc)
A princípio, foi interessante transformar a palavra em criptografada. Aqui está o que aconteceu:
Decidi fazer um grande ciclo de todas as palavras e começar a traduzi-las uma a uma. Mas me deparei com um problema. Verificou-se que algumas palavras continham um sinal "-", que era surpreendente e natural ao mesmo tempo.
Sem pensar duas vezes, contei o número de tais palavras e verificou-se que havia apenas duas delas. Após o que ele excluiu os dois, porque dificilmente afetará o resultado. Para me ajudar, nasceu esta função:
O dicionário parecia:
{'a': 1, 'aa': 1, 'aaa': 1, 'aah': 1, ... }
Portanto, decidi não ser inteligente e substituí-los por palavras codificadas. Para fazer isso, escreveu uma função:
E, é claro, precisávamos de um grande ciclo que passasse por todas as palavras, encontrasse as palavras-shifters e salvasse o resultado. Aqui está:
Você deve ter notado que nos parâmetros da função é "min_len = 0". Ele será necessário no futuro. A peculiaridade desse conjunto de dados era um conjunto de palavras "estranho". Tais como: "aa", "aah" e combinações semelhantes. Foram eles que deram o primeiro resultado - 660 deslocadores de palavras.
Portanto, eu tive que colocar um limite de cinco, pelo menos, cinco caracteres, para que as palavras fossem agradáveis aos olhos e semelhantes às existentes.
words_result = check_all(words_cesar, min_len=5) words_result >> {'abime': 'delph', 'biabo': 'elder', 'bifer': 'elihu', 'cobra': 'freud', 'colob': 'frore', 'oxime': 'ralph', 'pelta': 'showd', 'primero': 'sulphur', 'teloi': 'whorl', 'xerox': 'ahura'}
Sim, dez palavras invertidas foram encontradas graças ao algoritmo. Minha combinação favorita:
primero [Primeiro] → enxofre [Enxofre]. A maioria dos outros pares que o tradutor do Google não reconhece.
Nesse estágio, saciei parcialmente a sede de conhecimento. Mas adiante havia perguntas como: "E o outro N?"
E usando esta função, encontrei a resposta:
O ciclo terminou em 10 a 15 segundos. Resta apenas ver os resultados. Mas, como eu acho que é mais interessante quando há um cronograma. E aqui está a função final, que nos mostrará o resultado:
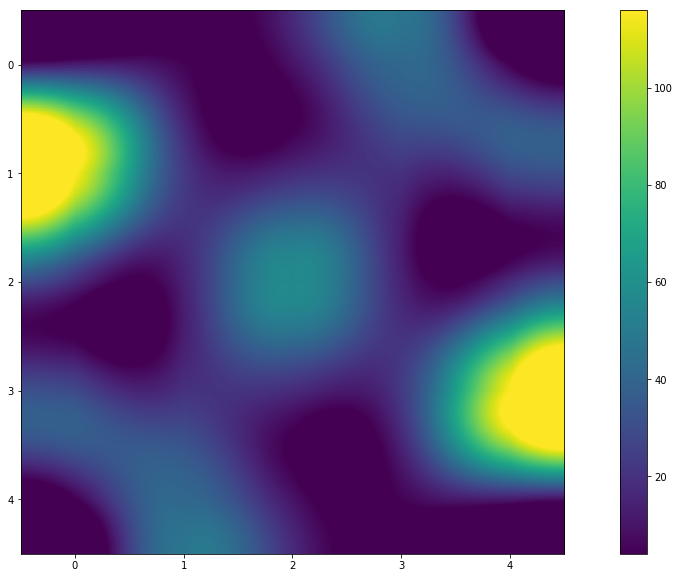
Sumário
Respostas às perguntas no início
"E se eu criptografar uma palavra usando César e receber uma palavra existente na saída?"
- Isso é possível, mesmo muito. Alguns N dão muito mais palavras que outros.
- Quantas palavras “shifters” existem?
- Depende de N, o comprimento mínimo e, é claro, do conjunto de dados. No meu caso, com N = 3, o comprimento mínimo de palavras de 0 e 5 é o número de palavras: 660 e 10, respectivamente.
- E haverá um padrão se você alterar N?
Aparentemente sim! No gráfico (ou mapa de calor), você pode ver que as cores são simétricas. E os valores na matriz de resultados indicam isso. E a resposta para a pergunta "Por que isso acontece?" Vou deixar para o leitor.
Contras deste trabalho
- Conjunto de dados não muito correto. Muitas palavras não são óbvias. Embora possa ser assim. Estas são palavras " todas " do idioma inglês.
- Código
sempre pode ser melhorado. - "Código de César" é um caso especial do "código ateniense", em que a fórmula:
Novaletra=A∗Letraanterior+B
Para "Cifra de César" A = 1. A propósito, ele tem mais nuances, o que significa mais interessante.
Meu arquivo de trabalho com o resultado e uma lista de flip words estão neste repositório
Efzp zzhgl!