Quando se trata de monitorar a segurança de uma rede corporativa ou departamental interna, muitos têm uma associação com o controle de vazamentos de informações e a implementação de soluções DLP. E se você tentar esclarecer a pergunta e perguntar como detecta ataques na rede interna, a resposta geralmente será a menção de sistemas de detecção de intrusão (IDS). E qual era a única opção há 10 a 20 anos, hoje está se tornando um anacronismo. Existe uma maneira mais eficaz e, em alguns lugares, a única opção possível para monitorar a rede interna - usar protocolos de fluxo, originalmente projetados para procurar problemas de rede (solução de problemas), mas eventualmente transformados em uma ferramenta de segurança muito interessante. Falaremos sobre o que são protocolos de fluxo e quais ajudam a detectar ataques de rede, onde é melhor implementar o monitoramento de fluxo, o que procurar ao implantar esse esquema e até mesmo como "buscá-lo" em equipamentos domésticos. como parte deste artigo.
Não vou me debruçar sobre a pergunta "Por que precisamos monitorar a segurança da infraestrutura interna?" A resposta parece ser clara. Mas se, no entanto, você gostaria de garantir mais uma vez que não existe nenhum lugar,
assista a um pequeno vídeo com uma história sobre como você pode acessar a rede corporativa protegida por um firewall de 17 maneiras. Portanto, assumiremos que entendemos que o monitoramento interno é uma coisa necessária e resta apenas entender como ele pode ser organizado.
Eu destacaria três fontes de dados principais para monitorar a infraestrutura no nível da rede:
- Tráfego "bruto", que capturamos e enviamos para análise em determinados sistemas de análise,
- eventos de dispositivos de rede através dos quais o tráfego passa,
- informações de tráfego recebidas usando um dos protocolos de fluxo.

Capturar o tráfego bruto é a opção mais popular entre os guardas de segurança, porque historicamente apareceu o primeiro. Os sistemas convencionais de detecção de ataques baseados em rede (o primeiro sistema comercial de detecção de ataques foi o NetRanger da WheelR, adquirido em 1998 pela Cisco) estavam apenas no negócio de capturar pacotes (e sessões posteriores) que procuravam assinaturas específicas (“regras decisivas” na terminologia FSTEC), sinalizando ataques. Obviamente, você pode analisar o tráfego bruto não apenas usando o IDS, mas também outras ferramentas (por exemplo, a funcionalidade Wireshark, tcpdum ou NBAR2 no Cisco IOS), mas elas geralmente não possuem uma base de conhecimento que distingue uma ferramenta de segurança da informação de uma ferramenta de TI comum.
Então, sistemas de detecção de ataques. O método mais antigo e popular de detectar ataques de rede, que lida bem com sua tarefa no perímetro (não importa o que seja - corporativo, data center, segmento etc.), mas passa nas modernas redes comutadas e definidas por software. No caso de uma rede construída com base em comutadores convencionais, a infraestrutura dos sensores de detecção de ataques se torna muito grande - você precisará colocar um sensor em cada conexão com o host cujos ataques você deseja monitorar. Qualquer fabricante, é claro, ficará feliz em vender centenas e milhares de sensores, mas acho que seu orçamento não pode suportar esses custos. Posso dizer que mesmo na Cisco (e somos os desenvolvedores do NGIPS) não fomos capazes de fazer isso, embora pareça que a questão do preço esteja diante de nós. não deve permanecer - esta é a nossa própria decisão. Além disso, surge a questão, mas como conectar o sensor nesta modalidade? Para a lacuna? E se o próprio sensor estiver desativado? Requer um módulo de desvio no sensor? Use divisores de torneira? Tudo isso torna a solução mais cara e insuportável para uma empresa de qualquer escala.
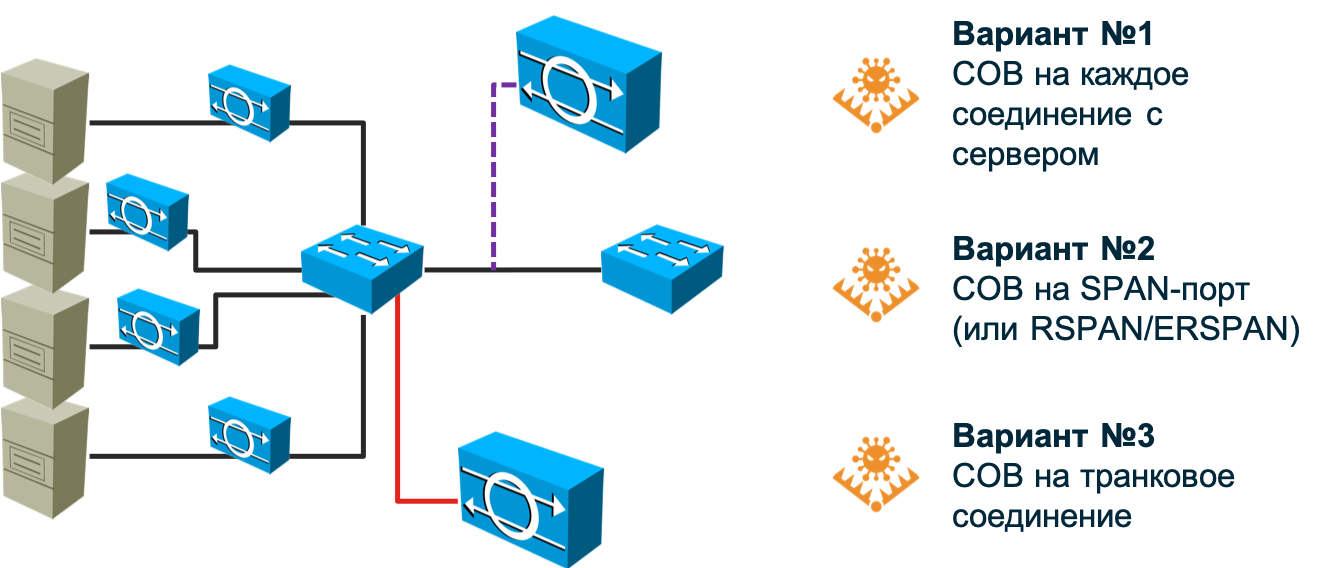
Você pode tentar "travar" o sensor na porta SPAN / RSPAN / ERSPAN e direcionar o tráfego para ele a partir das portas necessárias no switch. Essa opção remove parcialmente o problema descrito no parágrafo anterior, mas apresenta um problema diferente - a porta SPAN não pode aceitar absolutamente todo o tráfego que será enviado a ela - não terá largura de banda suficiente. Aconchegue algo para sacrificar. Deixe parte dos nós sem monitoramento (então será necessário priorizá-los primeiro) ou roteie não todo o tráfego do nó, mas apenas um determinado tipo. De qualquer forma, podemos pular alguns ataques. Além disso, a porta SPAN pode ser ocupada para outras necessidades. Como resultado, teremos que revisar a topologia de rede existente e, possivelmente, fazer ajustes para cobrir sua rede ao máximo com o número de sensores que você possui (e coordenar isso com a TI).
E se sua rede usa rotas assimétricas? E se você implementou ou planeja introduzir SDN? E se você precisar monitorar máquinas ou contêineres virtualizados cujo tráfego não atinja o comutador físico? Os fabricantes de IDS tradicional não gostam dessas perguntas porque não sabem como respondê-las. Talvez eles o levem ao fato de que todas essas tecnologias da moda são exageradas e você não precisa disso. Talvez eles falem sobre a necessidade de começar pequeno. Ou talvez eles digam que você precisa colocar uma debulhadora poderosa no centro da rede e direcionar todo o tráfego para ela usando balanceadores. Qualquer que seja a opção oferecida, você precisa entender claramente por si mesmo o quanto ela combina com você. E somente depois disso tome uma decisão sobre a escolha de uma abordagem para monitorar a segurança das informações da infraestrutura de rede. Voltando à captura de pacotes, quero dizer que esse método continua sendo muito popular e importante, mas seu principal objetivo é o controle de borda; os limites entre sua organização e a Internet, os limites entre o datacenter e o restante da rede, os limites entre o ICS e o segmento corporativo. Nesses locais, o IDS / IPS clássico ainda tem o direito de existir e fazer um bom trabalho de suas tarefas.

Vamos para a segunda opção. Uma análise de eventos de dispositivos de rede também pode ser usada para detectar ataques, mas não como o principal mecanismo, pois permite detectar apenas uma pequena classe de intrusões. Além disso, alguma reatividade é inerente a ele - um ataque deve ocorrer primeiro, depois deve ser corrigido por um dispositivo de rede, que de uma maneira ou de outra sinalizará um problema com a segurança da informação. Existem várias maneiras. Pode ser syslog, RMON ou SNMP. Os dois últimos protocolos para monitoramento de rede no contexto de segurança da informação são usados apenas se precisarmos detectar um ataque de DoS no próprio equipamento de rede, pois, usando o RMON e o SNMP, por exemplo, podemos monitorar a carga do processador central do dispositivo ou de suas interfaces. Esse é um dos "mais baratos" (todos têm syslog ou SNMP), mas também o mais ineficaz de todas as maneiras de monitorar a segurança das informações da infraestrutura interna - muitos ataques estão simplesmente ocultos. Obviamente, eles não devem ser negligenciados e a mesma análise de syslog ajuda a identificar alterações na configuração do dispositivo em tempo hábil, é um compromisso, mas não é muito adequado para detectar ataques em toda a rede.
A terceira opção é analisar informações sobre o tráfego que passa por um dispositivo que suporta um dos vários protocolos de fluxo. Nesse caso, independentemente do protocolo, a infraestrutura de fluxo consiste necessariamente em três componentes:
- Gere ou exporte fluxo. Essa função geralmente é atribuída a um roteador, comutador ou outro dispositivo de rede que, passando o tráfego de rede por si próprio, permite extrair parâmetros-chave dele, que são transferidos para o módulo de coleta. Por exemplo, o protocolo Cisco Netflow é suportado não apenas em roteadores e switches, incluindo virtuais e industriais, mas também em controladores sem fio, firewalls e até servidores.
- Fluxo de coleta. Dado que em uma rede moderna geralmente há mais de um dispositivo de rede, surge o problema de coletar e consolidar fluxos, que é resolvido usando os chamados coletores, que processam os fluxos recebidos e os transmitem para análise.
- Análise de fluxo. O analisador assume a principal tarefa intelectual e, aplicando vários algoritmos aos fluxos, tira certas conclusões. Por exemplo, como parte da função de TI, esse analisador pode identificar gargalos na rede ou analisar o perfil de carga de tráfego para otimizar ainda mais a rede. E, para segurança das informações, esse analisador pode detectar vazamentos de dados, a disseminação de códigos maliciosos ou ataques de DoS.
Você não deve pensar que essa arquitetura de três camadas é muito complicada - todas as outras opções (exceto, talvez, os sistemas de monitoramento de rede que funcionam com SNMP e RMON) também funcionam de acordo com ela. Temos um gerador de dados para análise, que é um dispositivo de rede ou um sensor independente. Temos um sistema de coleta de alarmes e um sistema de gerenciamento para toda a infraestrutura de monitoramento. Os dois últimos componentes podem ser combinados em um único nó, mas em redes mais ou menos grandes eles geralmente são separados por pelo menos dois dispositivos para garantir escalabilidade e confiabilidade.

Ao contrário da análise de pacotes, com base no estudo do cabeçalho e do corpo de dados de cada pacote e nas sessões que os compõem, a análise de fluxo depende da coleta de metadados sobre o tráfego de rede. Quando, quanto, onde e onde, como ... essas são as perguntas respondidas pela análise da telemetria de rede usando vários protocolos de fluxo. Inicialmente, eles eram usados para analisar estatísticas e procurar problemas de TI na rede, mas, com o desenvolvimento de mecanismos analíticos, tornou-se possível aplicá-los à mesma telemetria e para fins de segurança. Vale ressaltar aqui novamente que a análise de fluxo não substitui nem cancela a captura de pacotes. Cada um desses métodos possui seu próprio campo de aplicação. Porém, no contexto deste artigo, é a análise de fluxo mais adequada para monitorar a infraestrutura interna. Você tem dispositivos de rede (e não importa se eles funcionam em um paradigma definido por software ou de acordo com regras estáticas) que o ataque não pode passar. Ele pode ignorar o sensor IDS clássico, mas não há dispositivo de rede que suporte o protocolo de fluxo. Essa é a vantagem desse método.
Por outro lado, se você precisa de evidências para a aplicação da lei ou sua própria equipe de investigação de incidentes, não pode prescindir da captura de pacotes - a telemetria de rede não é uma cópia do tráfego que pode ser usado para coletar evidências; é necessário para detecção operacional e tomada de decisões no campo da segurança da informação. Por outro lado, usando a análise de telemetria, você pode "escrever" não todo o tráfego da rede (se houver alguma coisa, a Cisco está envolvida nos datacenters :-), mas apenas aquela envolvida no ataque. As ferramentas de análise de telemetria nesse sentido complementarão bem os mecanismos tradicionais de captura de pacotes, fornecendo o comando para captura e armazenamento seletivos. Caso contrário, você precisará ter uma infraestrutura de armazenamento colossal.
Imagine uma rede operando a uma velocidade de 250 Mbps. Se você deseja salvar todo esse volume, precisará de 31 MB de armazenamento por um segundo de transferência de tráfego, 1,8 GB por um minuto, 108 GB por uma hora e 2,6 TB por um dia. Para armazenar dados diários de uma rede com uma largura de banda de 10 Gbit / s, você precisa de 108 TB de armazenamento. Mas alguns reguladores exigem que você armazene dados de segurança por anos ... O registro "sob demanda", que ajuda a implementar a análise de fluxo, ajuda a reduzir esses valores em ordens de magnitude. A propósito, se falarmos sobre a proporção do volume gravado de dados de telemetria de rede e a captura total de dados, é de cerca de 1 a 500. Para os mesmos valores acima, o armazenamento de uma descriptografia completa de todo o tráfego diário será de 5 e 216 GB, respectivamente (você pode até gravar em uma unidade flash USB comum )
Se as ferramentas de análise de dados brutos da rede tiverem um método de captura quase igual ao do fornecedor, a situação será diferente com a análise dos fluxos. Existem várias opções para protocolos de fluxo, as diferenças que você precisa saber no contexto de segurança. O mais popular é o protocolo Netflow desenvolvido pela Cisco. Existem várias versões deste protocolo que diferem em seus recursos e na quantidade de informações registradas sobre o tráfego. A versão atual é a nona (Netflow v9), com base na qual o padrão da indústria Netflow v10, também conhecido como IPFIX, foi desenvolvido. Hoje, a maioria dos fornecedores de rede suporta exatamente Netflow ou IPFIX em seus equipamentos. Mas existem várias outras opções para protocolos de fluxo - sFlow, jFlow, cFlow, rFlow, NetStream, etc., dos quais o sFlow é mais popular. É ele quem é mais frequentemente apoiado pelos fabricantes nacionais de equipamentos de rede devido à facilidade de implementação. Quais são as principais diferenças entre o Netflow, como padrão de fato, e o sFlow? Eu destacaria alguns dos principais. Primeiro, o Netflow possui campos definidos pelo usuário em oposição aos campos fixos no sFlow. Em segundo lugar, e isso é a coisa mais importante em nosso caso, o sFlow coleta a chamada telemetria amostrada; diferente da não amostrada no Netflow e no IPFIX. Qual é a diferença entre eles?

Imagine que você decidiu ler o livro “
Centro de Operações de Segurança: Construindo, Operando e Mantendo seu SOC ” de meus colegas - Gary McIntyre, Joseph Muniz e Nadef Alfardan (você pode baixar parte do livro no link). Você tem três opções para atingir seu objetivo - ler o livro inteiro, percorrer os olhos, parar a cada 10 ou 20 páginas ou tentar encontrar uma recontagem dos principais conceitos em um blog ou serviço como o SmartReading. A telemetria não amostrada está lendo todas as "páginas" do tráfego de rede, ou seja, analisando metadados para cada pacote. A telemetria de amostragem é um estudo seletivo do tráfego, na esperança de que as amostras selecionadas tenham o que você precisa. Dependendo da velocidade do canal, a telemetria amostrada enviará para análise a cada 64, 200, 500, 1000, 2000 ou mesmo 10000 pacotes.

No contexto do monitoramento de segurança da informação, isso significa que a telemetria amostrada é adequada para detectar ataques DDoS, varredura e disseminação de código malicioso, mas pode ignorar ataques atômicos ou de vários pacotes que não caíram na amostra enviada para análise. A telemetria sem amostragem não possui essas deficiências. Usar a variedade de ataques detectáveis é muito mais amplo. Aqui está uma pequena lista de eventos que podem ser detectados usando as ferramentas de análise de telemetria de rede.
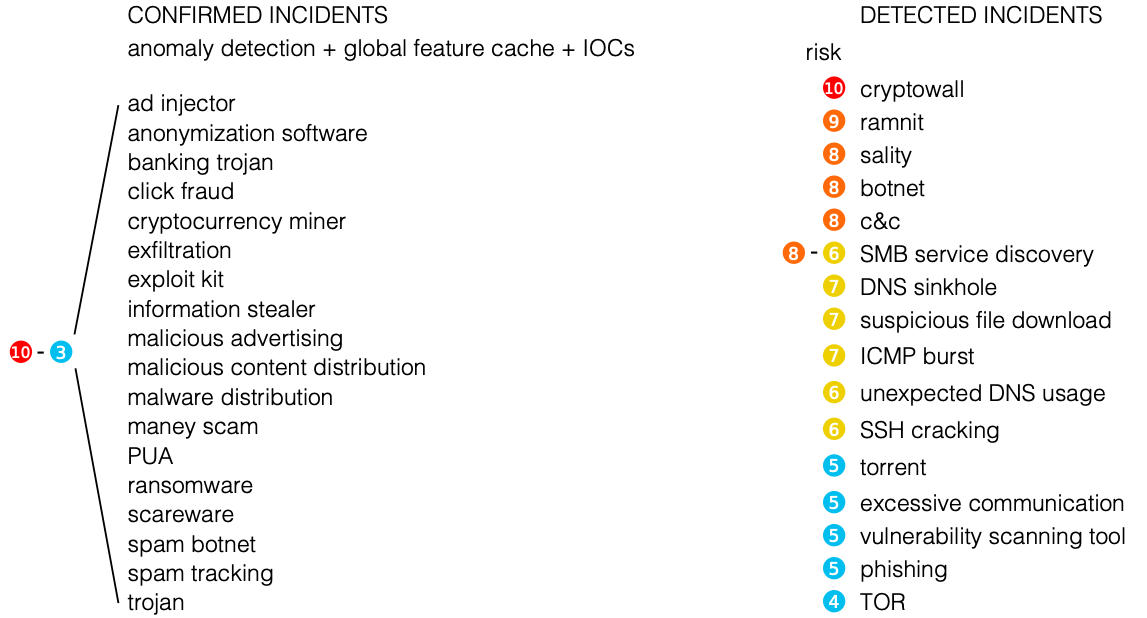
Certamente, algum analisador de fluxo aberto do Netflow não permitirá que você faça isso, pois sua principal tarefa é coletar telemetria e realizar análises básicas sobre ele do ponto de vista de TI. Para identificar ameaças à segurança da informação com base no fluxo, é necessário equipar o analisador com vários mecanismos e algoritmos, que identificarão problemas de segurança cibernética com base em campos padrão ou personalizados do Netflow, enriquecerão os dados padrão com dados externos de várias fontes de Threat Intelligence, etc.
Portanto, se você tiver uma opção, pare-a no Netflow ou IPFIX. Porém, mesmo que seu equipamento funcione apenas com o sFlow, como fabricantes nacionais, mesmo nesse caso, você poderá se beneficiar dele no contexto de segurança.

No verão de 2019, analisei as oportunidades que os fabricantes russos de hardware de rede têm, e todos eles, excluindo NSG, Polygon e Craftway, declararam suporte ao sFlow (pelo menos Zelax, Natex, Eltex, QTech, Rusteletech).
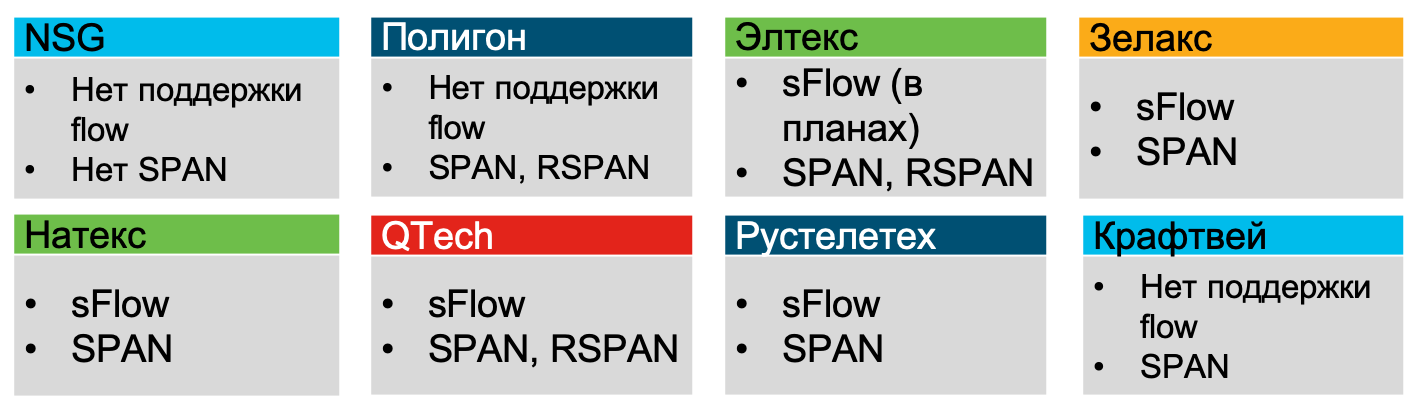
A próxima pergunta que você enfrentará é onde implementar o suporte ao fluxo por motivos de segurança? De fato, a questão não está totalmente correta. Em equipamentos modernos, o suporte a protocolos de fluxo está quase sempre lá. Portanto, reformularia a questão de maneira diferente - onde é a maneira mais eficiente de coletar telemetria do ponto de vista da segurança? A resposta será bastante óbvia - no nível de acesso, onde você verá 100% de todo o tráfego, onde você terá informações detalhadas sobre hosts (MAC, VLAN, ID da interface), onde você pode até rastrear o tráfego P2P entre hosts, o que é essencial para detectar varreduras ee a disseminação de código malicioso. No nível do kernel, talvez você não veja parte do tráfego, mas no nível do perímetro verá bem um quarto de todo o tráfego da rede. Mas se, por algum motivo, dispositivos estranhos forem instalados na sua rede, permitindo que os invasores "entrem e saiam", ignorando o perímetro, a análise da telemetria a partir dele não fornecerá nada. Portanto, para obter cobertura máxima, é recomendável incluir a coleção de telemetria no nível de acesso. Ao mesmo tempo, vale a pena notar que, mesmo se estivermos falando sobre virtualização ou contêineres, o suporte ao fluxo também é frequentemente encontrado em comutadores virtuais modernos, o que permite controlar o tráfego também.
Mas desde que eu levantei o tópico, preciso responder à pergunta, mas e se, afinal, o equipamento, físico ou virtual, não suportar protocolos de fluxo? Ou é proibida a sua inclusão (por exemplo, em segmentos industriais para garantir a confiabilidade)? Ou sua inclusão leva à alta utilização da CPU (isso acontece em equipamentos desatualizados)? Para resolver esse problema, existem sensores virtuais especializados (sensor de fluxo), que são essencialmente divisores comuns que transmitem o tráfego por si mesmos e o transmitem na forma de fluxo para o módulo de coleta. É verdade que, neste caso, temos muitos problemas sobre os quais falamos acima em relação às ferramentas de captura de pacotes. Ou seja, você precisa entender não apenas as vantagens da tecnologia de análise de fluxo, mas também suas limitações.
Outro ponto que é importante lembrar quando se fala em ferramentas de análise de fluxo. Se aplicarmos a métrica EPS (evento por segundo, eventos por segundo) a meios convencionais de geração de eventos de segurança, esse indicador não se aplicará à análise de telemetria; é substituído pelo FPS (fluxo por segundo). Como no caso do EPS, ele não pode ser calculado antecipadamente, mas você pode estimar o número aproximado de fluxos que um dispositivo específico gera, dependendo de sua tarefa. Na Internet, você pode encontrar tabelas com valores aproximados para diferentes tipos de dispositivos e condições corporativas, o que permitirá descobrir quais licenças são necessárias para as ferramentas de análise e qual será a arquitetura delas. O fato é que o sensor IDS é limitado por uma certa largura de banda, que será "puxada", e o coletor de fluxo tem suas próprias limitações, que devem ser entendidas. Portanto, em grandes redes geograficamente distribuídas, geralmente existem vários reservatórios. Quando descrevi
como a rede dentro da Cisco é monitorada , já citei o número de nossos coletores - existem 21. E isso ocorre em uma rede espalhada pelos cinco continentes e com cerca de meio milhão de dispositivos ativos).
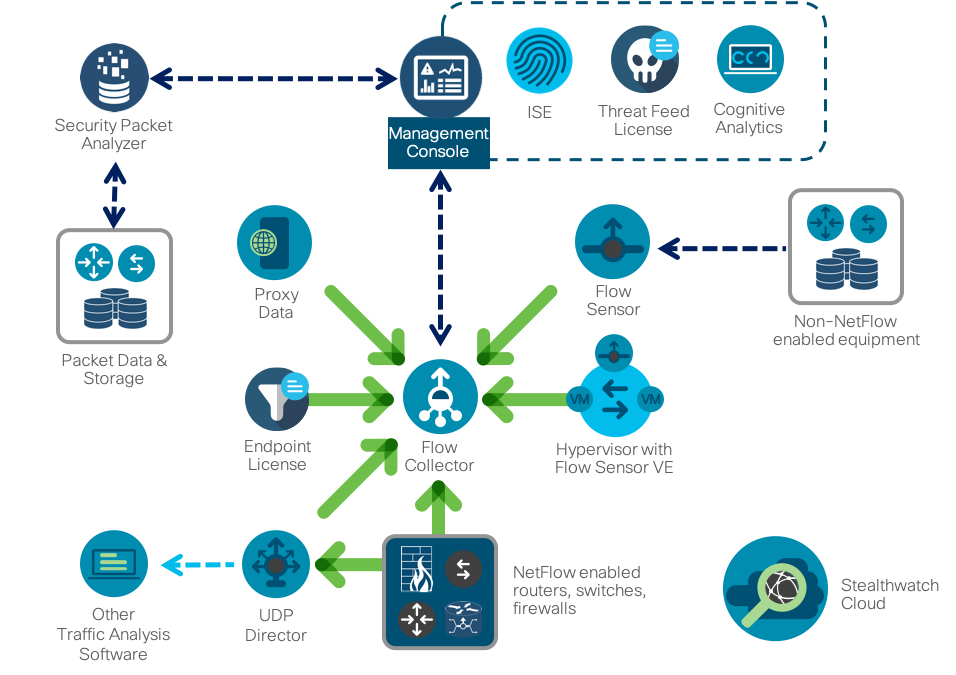
Como sistema de monitoramento Netflow, usamos nossa própria
solução Cisco Stealthwatch , focada especificamente na solução de problemas de segurança. Possui muitos mecanismos internos para detectar atividades anormais, suspeitas e obviamente maliciosas, o que permite detectar uma ampla variedade de ameaças - desde mineração de criptografia a vazamentos de informações, desde a disseminação de códigos maliciosos até fraudes. Como a maioria dos analisadores de fluxo, o Stealthwatch é construído de acordo com um esquema de três níveis (gerador - coletor - analisador), mas é complementado por vários recursos interessantes que são importantes no contexto do material em consideração. Primeiro, ele se integra às soluções de captura de pacotes (como o Cisco Security Packet Analyzer), que permitem gravar sessões de rede selecionadas para uma investigação e análise mais aprofundada. Em segundo lugar, especialmente para expandir tarefas de segurança, desenvolvemos um protocolo especial nvzFlow, que permite "traduzir" a atividade de aplicativos em nós finais (servidores, estações de trabalho etc.) em telemetria e transmiti-la ao coletor para análises adicionais. Se em sua versão original o Stealthwatch funcionar com qualquer protocolo de fluxo (sFlow, rFlow, Netflow, IPFIX, cFlow, jFlow, NetStream) no nível da rede, o suporte ao nvzFlow também permitirá a correlação de dados no nível do host. aumentando a eficiência de todo o sistema e vendo mais ataques do que os analisadores de fluxo de rede convencionais.
É claro que, falando em sistemas de análise de segurança Netflow, o mercado não se limita a uma única solução da Cisco. Você pode usar soluções comerciais e freeware ou shareware. Curiosamente, se eu usar o blog da Cisco como um exemplo de soluções concorrentes, direi algumas palavras sobre como a telemetria de rede pode ser analisada usando duas ferramentas populares, de nome semelhante, mas ainda diferentes - SiLK e ELK.
O SiLK é um conjunto de ferramentas (o Sistema para Conhecimento em Nível de Internet) para análise de tráfego, desenvolvido pelo American CERT / CC e que suporta, no contexto do artigo de hoje, o Netflow (5 e 9, as versões mais populares), IPFIX e sFlow e usando vários utilitários (rwfilter, rwcount, rwflowpack, etc.) para executar várias operações na telemetria de rede, a fim de detectar sinais de ações não autorizadas. Mas há alguns pontos importantes a serem observados. O SiLK é uma ferramenta de linha de comando e conduz análises operacionais, sempre que você insere um comando do formulário (detecção de pacotes ICMP maiores que 200 bytes):
rwfilter --flowtypes=all/all --proto=1 --bytes-per-packet=200- --pass=stdout | rwrwcut --fields=sIP,dIP,iType,iCode --num-recs=15não é muito conveniente. Você pode usar a GUI do iSiLK, mas isso não facilitará muito sua vida, resolvendo apenas a função de visualização, não a substituição do analista. E este é o segundo ponto. Diferentemente das soluções comerciais, que já possuem uma base analítica sólida, algoritmos de detecção de anomalias, algoritmos relacionados ao fluxo de trabalho, etc., no caso do SiLK, você terá que fazer tudo isso sozinho, o que exigirá o uso de competências ligeiramente diferentes das já utilizadas. ferramentas prontas para uso. Isso é ruim e não é ruim - esse é um recurso de quase qualquer ferramenta gratuita que vem do fato de você saber o que fazer, e isso só ajudará nisso (as ferramentas comerciais são menos dependentes das competências de seus usuários, embora também assuma que os analistas entendem pelo menos noções básicas de investigações e monitoramento de rede). Mas voltando ao SiLK. O ciclo de trabalho do analista com ele é o seguinte:
- Formulação de uma hipótese. Precisamos entender o que procuraremos dentro da telemetria de rede, para conhecer os atributos únicos pelos quais identificaremos certas anomalias ou ameaças.
- Construindo um modelo. Após formular uma hipótese, a programamos usando o mesmo Python, shell ou outras ferramentas não incluídas no SiLK.
- Teste. É a vez de verificar a validade de nossa hipótese, que é confirmada ou refutada usando os utilitários SiLK, começando com 'rw', 'set', 'bag'.
- Análise de dados reais. Na operação industrial, o SiLK nos ajuda a identificar algo e o analista deve responder às perguntas “Encontramos o que esperávamos?”, “Isso corresponde à nossa hipótese?”, “Como reduzir o número de falsos positivos?”, “Como melhorar o nível de reconhecimento? " etc.
- Melhoria. Na fase final, aprimoramos o que foi feito anteriormente - criamos modelos, melhoramos e otimizamos o código, reformulamos e refinamos as hipóteses etc.
Esse ciclo será aplicável ao mesmo Cisco Stealthwatch, apenas as últimas cinco etapas serão automatizadas ao máximo, reduzindo o número de erros de analistas e aumentando a velocidade da detecção de incidentes. Por exemplo, no SiLK, você pode enriquecer as estatísticas da rede com dados externos em IP malicioso usando seus próprios scripts e, no Cisco Stealthwatch, essa é uma função interna que exibe imediatamente um alarme se houver interação com os endereços IP da lista negra no tráfego de rede.
Se formos mais altos na pirâmide "paga" para o software de análise de fluxo, o SiLK absolutamente gratuito será seguido pelo shareware ELK, composto por três componentes principais - Elasticsearch (indexação, busca e análise de dados), Logstash (entrada / saída de dados) e Kibana ( visualização). Ao contrário do SiLK, onde você deve escrever tudo sozinho, o ELK já possui muitas bibliotecas / módulos prontos (alguns são pagos, outros não) que automatizam a análise da telemetria de rede. Por exemplo, o filtro GeoIP no Logstash permite vincular os endereços IP observados à sua localização geográfica (para o Stealthwatch, essa é uma função interna).
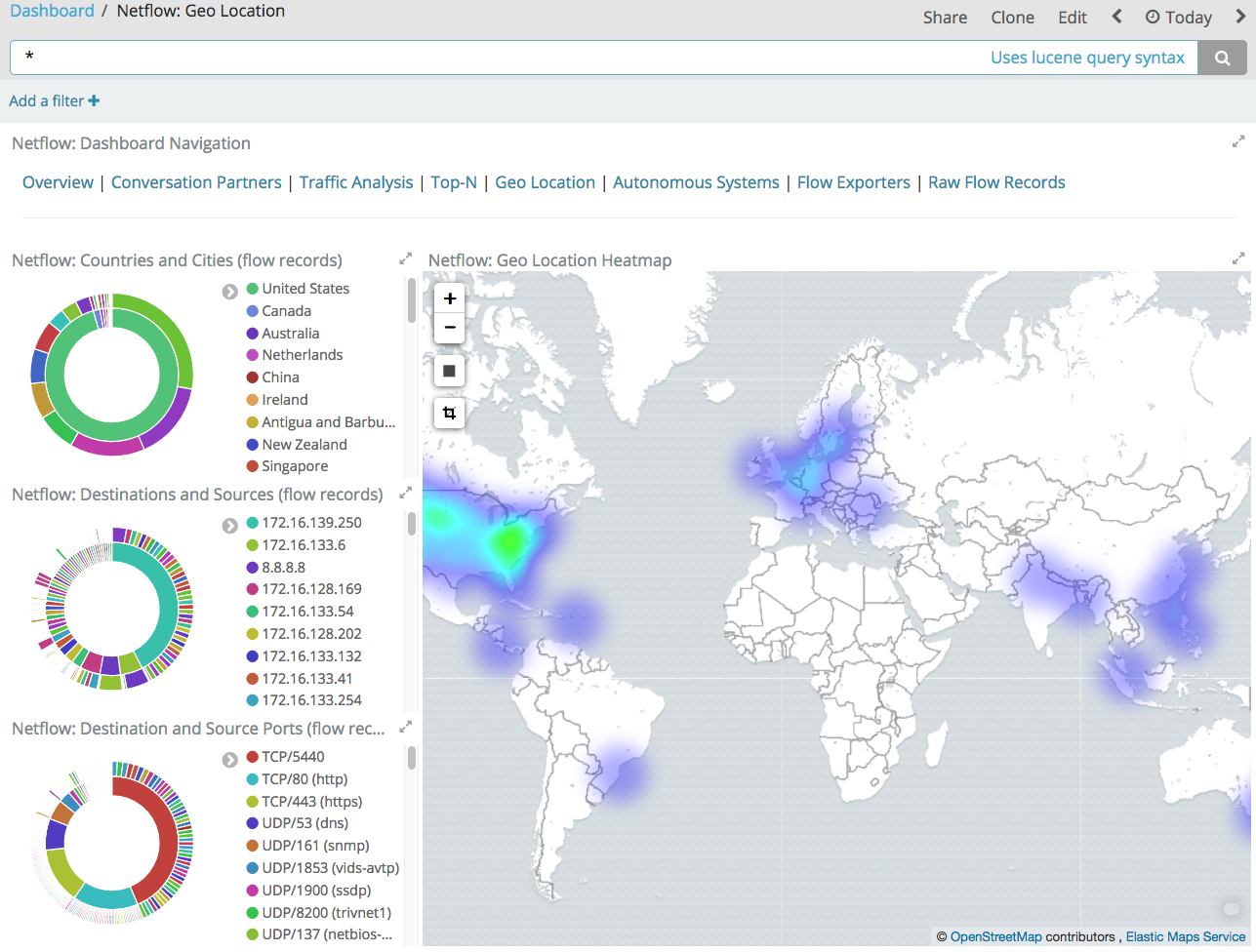
O ELK também possui uma comunidade bastante grande que está concluindo os componentes ausentes para esta solução de monitoramento. Por exemplo, para trabalhar com o Netflow, IPFIX e sFlow, você pode usar o módulo
elastiflow se não estiver familiarizado com o Logstash Netflow Module, que suporta apenas o Netflow.
Dando mais eficiência na coleta e na pesquisa de fluxo, o ELK atualmente não possui análises integradas para detectar anomalias e ameaças na telemetria de rede. Ou seja, seguindo o ciclo de vida descrito acima, você terá que descrever independentemente o modelo de violações e depois usá-lo no sistema de combate (não há modelos internos lá).
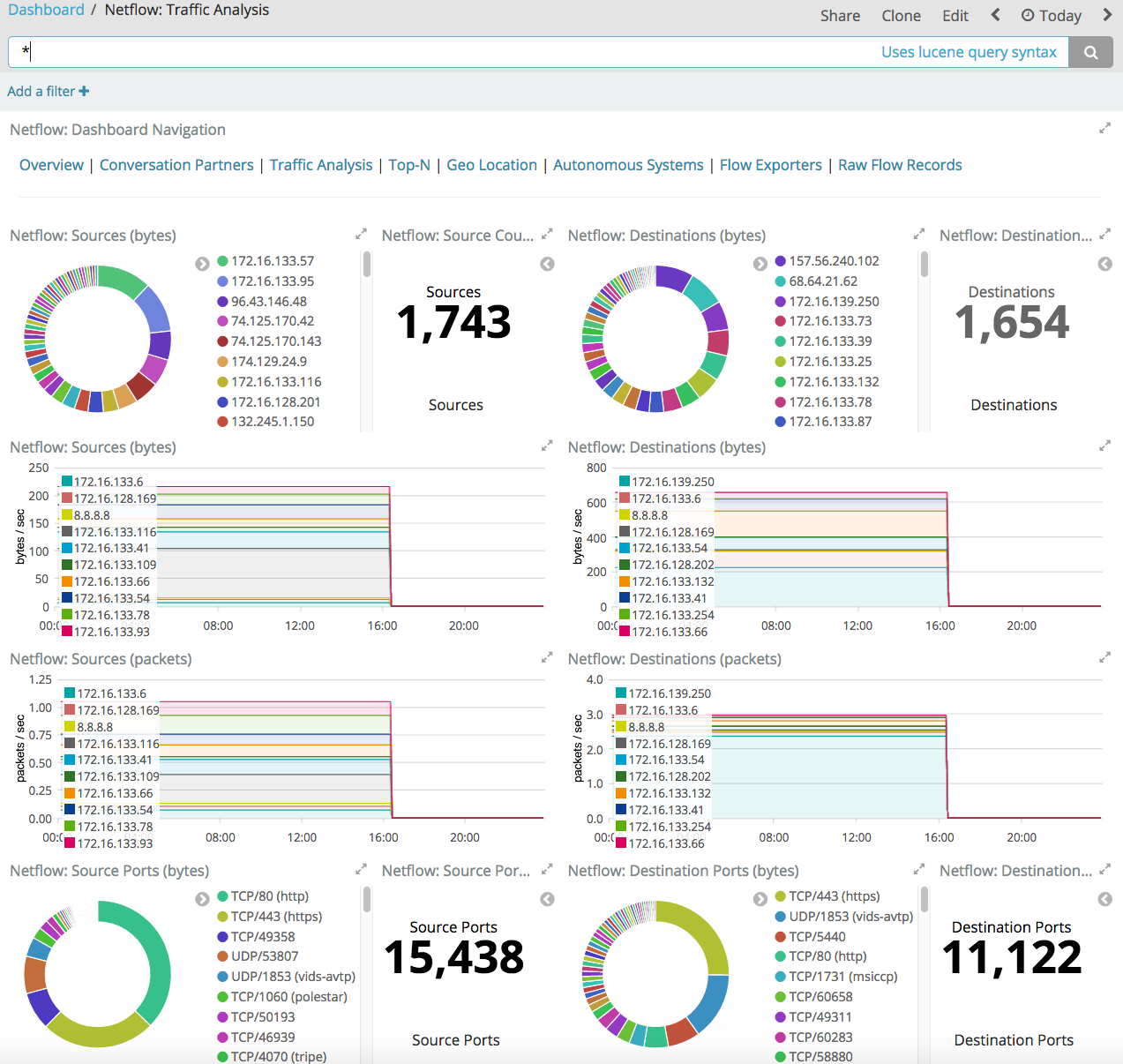
Obviamente, existem extensões mais sofisticadas para ELK que já contêm alguns modelos para detectar anomalias na telemetria de rede, mas essas extensões custam dinheiro e a questão é se o jogo vale a pena - escreva o mesmo modelo, compre você mesmo a implementação da sua ferramenta de monitoramento ou compre solução chave na mão para a classe Análise de tráfego de rede.
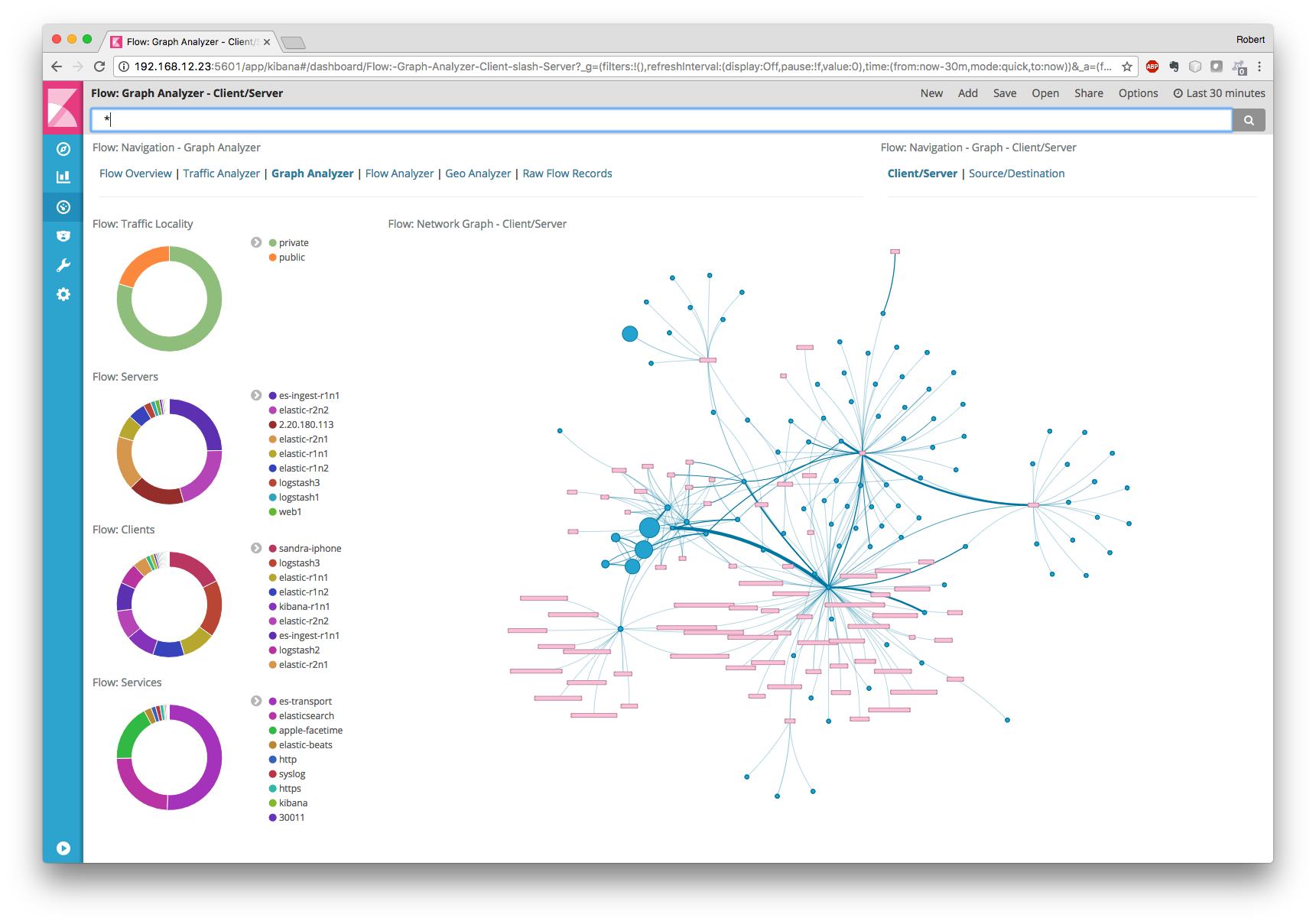 Em geral, não quero entrar no debate de que é melhor gastar dinheiro e comprar uma solução pronta para monitorar anomalias e ameaças na telemetria de rede (por exemplo, Cisco Stealthwatch) ou descobrir por conta própria e girar as mesmas ferramentas de fluxo SiLK, ELK ou nfdump ou OSU (para cada nova ameaça) ( Eu falei sobre os dois últimos na última vez)? Todo mundo escolhe por si mesmo e todo mundo tem seus próprios motivos para escolher uma das duas opções. Eu só queria mostrar que a telemetria de rede é uma ferramenta muito importante para garantir a segurança da rede de sua infraestrutura interna e você não deve negligenciá-la para não reabastecer a lista da empresa cujo nome é mencionado na mídia, juntamente com os epítetos "hackeados", "que não estavam em conformidade com os requisitos de segurança da informação "," Sem pensar na segurança dos dados e dos dados do cliente. "
Em geral, não quero entrar no debate de que é melhor gastar dinheiro e comprar uma solução pronta para monitorar anomalias e ameaças na telemetria de rede (por exemplo, Cisco Stealthwatch) ou descobrir por conta própria e girar as mesmas ferramentas de fluxo SiLK, ELK ou nfdump ou OSU (para cada nova ameaça) ( Eu falei sobre os dois últimos na última vez)? Todo mundo escolhe por si mesmo e todo mundo tem seus próprios motivos para escolher uma das duas opções. Eu só queria mostrar que a telemetria de rede é uma ferramenta muito importante para garantir a segurança da rede de sua infraestrutura interna e você não deve negligenciá-la para não reabastecer a lista da empresa cujo nome é mencionado na mídia, juntamente com os epítetos "hackeados", "que não estavam em conformidade com os requisitos de segurança da informação "," Sem pensar na segurança dos dados e dos dados do cliente. " Resumindo, gostaria de listar as principais dicas que você deve seguir ao criar o monitoramento de segurança da informação de sua infraestrutura interna:
Resumindo, gostaria de listar as principais dicas que você deve seguir ao criar o monitoramento de segurança da informação de sua infraestrutura interna:- Não se limite apenas ao perímetro! Use (e escolha) a infraestrutura de rede não apenas para transferir tráfego do ponto A para o ponto B, mas também para resolver problemas de segurança cibernética.
- Explore os mecanismos de monitoramento de segurança existentes no seu equipamento de rede e implante-os.
- Para monitoramento interno, dê preferência à análise de telemetria - ela permite detectar até 80-90% de todos os incidentes de segurança da informação, enquanto faz o que é impossível ao capturar pacotes de rede e economizar espaço para armazenar todos os eventos de segurança da informação.
- Para monitorar fluxos, use o Netflow v9 ou IPFIX - eles fornecem mais informações no contexto de segurança e permitem monitorar não apenas o IPv4, mas também o IPv6, o MPLS, etc.
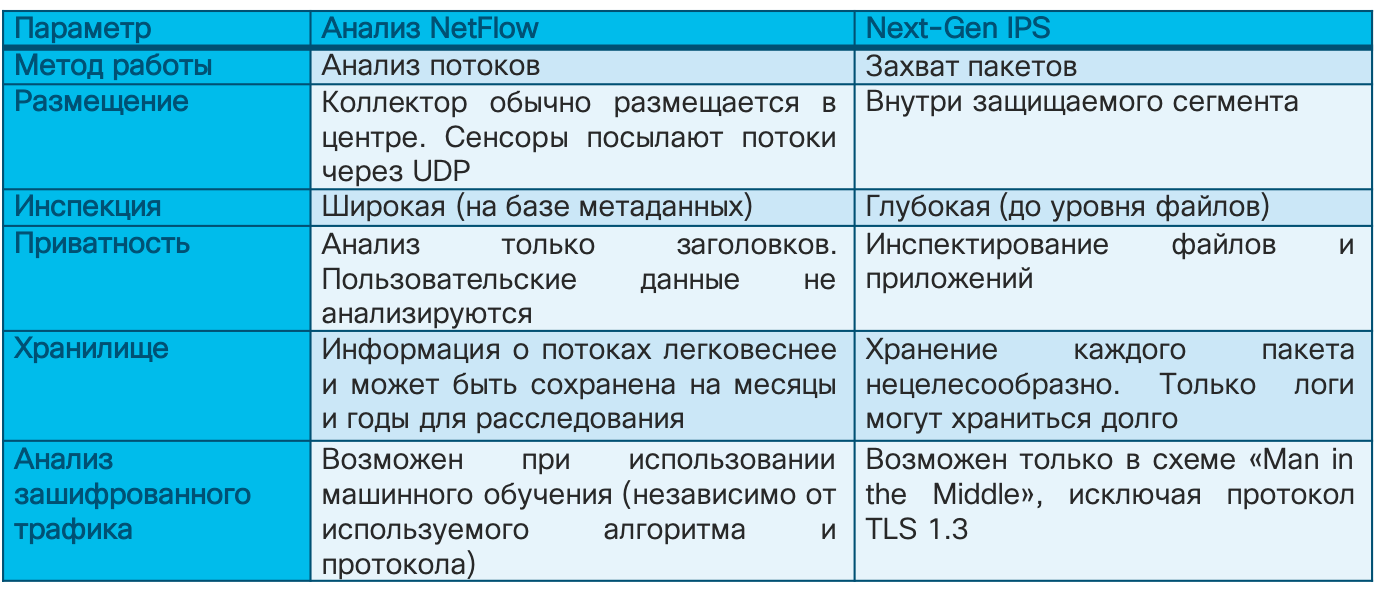
- flow- – . , Netflow IPFIX.
- – flow-. Netflow Generation Appliance.
- – 100% .
- , , flow- SPAN/RSPAN-.
- / / ( ).
 Quanto à última dica, gostaria de dar uma ilustração, que já citei anteriormente. Você percebe que, se antes o serviço Cisco IB construía quase completamente seu sistema de monitoramento de IS com base em sistemas de detecção de intrusão e métodos de assinatura, agora eles representam apenas 20% dos incidentes. Outros 20% são responsáveis por sistemas de análise de fluxo, o que sugere que essas soluções não são um capricho, mas uma ferramenta real nas atividades de serviços de segurança da informação de uma empresa moderna. Além disso, você tem a coisa mais importante para sua implementação - infraestrutura de rede, investimentos nos quais também podem ser protegidos atribuindo funções de monitoramento de IS à rede.
Quanto à última dica, gostaria de dar uma ilustração, que já citei anteriormente. Você percebe que, se antes o serviço Cisco IB construía quase completamente seu sistema de monitoramento de IS com base em sistemas de detecção de intrusão e métodos de assinatura, agora eles representam apenas 20% dos incidentes. Outros 20% são responsáveis por sistemas de análise de fluxo, o que sugere que essas soluções não são um capricho, mas uma ferramenta real nas atividades de serviços de segurança da informação de uma empresa moderna. Além disso, você tem a coisa mais importante para sua implementação - infraestrutura de rede, investimentos nos quais também podem ser protegidos atribuindo funções de monitoramento de IS à rede.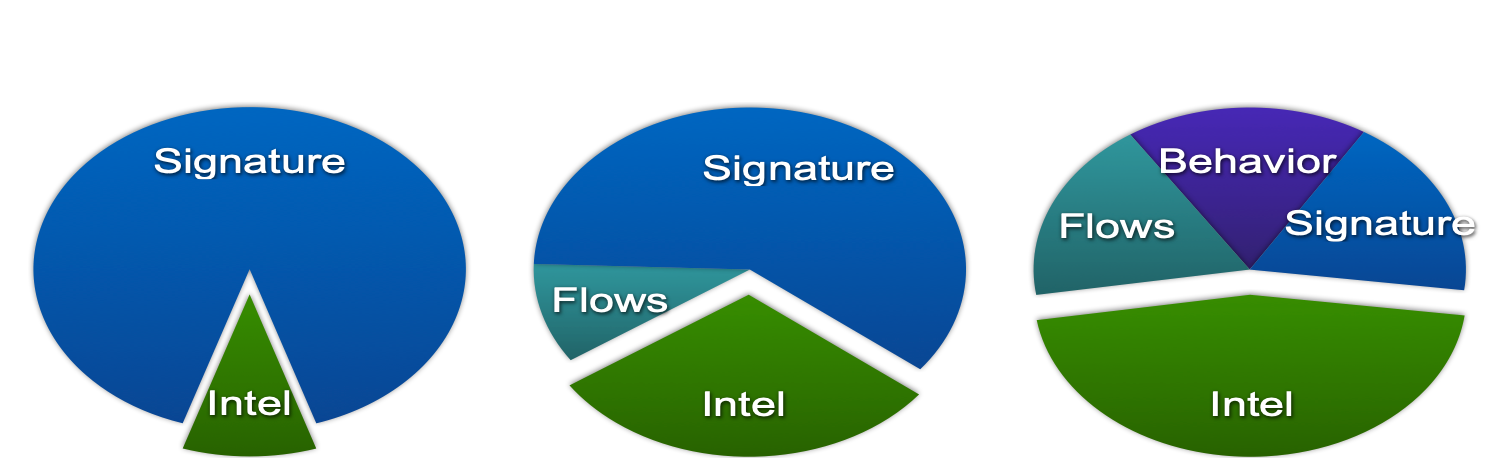 Eu deliberadamente não toquei no tópico de responder a anomalias ou ameaças identificadas nos fluxos de rede, mas acho que já está claro que o monitoramento não deve ser concluído apenas pela detecção de uma ameaça. Deve ser seguido por uma resposta e de preferência em modo automático ou automatizado. Mas este é o tópico de um material separado.Informações adicionais:
Eu deliberadamente não toquei no tópico de responder a anomalias ou ameaças identificadas nos fluxos de rede, mas acho que já está claro que o monitoramento não deve ser concluído apenas pela detecção de uma ameaça. Deve ser seguido por uma resposta e de preferência em modo automático ou automatizado. Mas este é o tópico de um material separado.Informações adicionais:Ameaça.
Se for mais fácil ouvir tudo o que foi escrito acima, você poderá assistir à apresentação de uma hora que formou a base desta nota.