Particionar ("particionar") no SQL Server, com aparente simplicidade ("o que está lá - você espalha a tabela e os índices por grupos de arquivos, obtém lucro em administração e desempenho") é um tópico bastante extenso. A seguir, tentarei descrever como criar e aplicar um esquema de função e partição e quais problemas você pode encontrar. Não falarei sobre os benefícios, exceto por uma coisa - alternar seções, quando você remove instantaneamente um grande conjunto de dados de uma tabela ou vice-versa - carrega instantaneamente um conjunto não menos grande em uma tabela.
Como o
msdn afirma: “Os dados de tabelas e índices particionados são divididos em blocos que podem ser distribuídos por vários grupos de arquivos no banco de dados. Os dados são particionados horizontalmente, portanto, os grupos de linhas são mapeados para seções individuais. Todas as seções do mesmo índice ou tabela devem estar no mesmo banco de dados. Uma tabela ou índice é considerado como uma única entidade lógica ao executar consultas ou atualizações de dados. ”
As principais vantagens também estão listadas lá:
- Transfira e acesse subconjuntos de dados de maneira rápida e eficiente, mantendo a integridade do conjunto de dados
- As operações de manutenção podem ser executadas mais rapidamente com uma ou mais seções;
- Você pode aumentar a velocidade de execução da consulta, dependendo das consultas que geralmente são executadas na sua configuração de hardware.
Em outras palavras, o particionamento é usado para dimensionamento horizontal. As tabelas / índices são "espalhados" por diferentes grupos de arquivos, que podem ser localizados em diferentes discos físicos, o que aumenta significativamente a conveniência da administração e, teoricamente, permite melhorar o desempenho das consultas a esses dados - você pode ler apenas a seção desejada (menos dados) ou ler tudo em paralelo (os dispositivos são diferentes, leia rapidamente). Na prática, tudo é um pouco mais complicado e o aumento do desempenho de consultas em tabelas particionadas pode funcionar apenas se suas consultas usarem a seleção pelo campo pelo qual você particionou. Se você ainda não possui experiência com tabelas particionadas, lembre-se de que o desempenho das suas consultas pode não mudar, mas pode se deteriorar após a partição da tabela.
Vamos falar sobre a vantagem absoluta que você definitivamente se dá bem com o particionamento (mas que você também precisa poder usar) - este é um aumento garantido na conveniência de gerenciar seu banco de dados. Por exemplo, você tem uma tabela com um bilhão de registros, dos quais 900 milhões são dos períodos antigos (“fechados”) e são somente leitura. Com a ajuda do corte, você pode transferir esses dados antigos para um grupo de arquivos somente leitura separado, fazer backup e não mais arrastá-los para todos os seus backups diários - a velocidade de criação de uma cópia de backup aumentará e o tamanho diminuirá. Você pode recriar o índice não sobre a tabela inteira, mas sobre as seções selecionadas. Além disso, a disponibilidade do seu banco de dados está aumentando - se um dos dispositivos que contém o grupo de arquivos com a seção falhar, o restante ainda estará disponível.
Para alcançar os benefícios restantes (alternar instantaneamente as seções; aumentar a produtividade) - é necessário projetar especificamente a estrutura de dados e escrever consultas.
Suponho que já envergonhei bastante o leitor e agora posso continuar praticando.
Primeiro, crie um banco de dados com 4 grupos de arquivos nos quais realizaremos experimentos:
create database [PartitionTest] on primary (name ='PTestPrimary', filename = 'E:\data\partitionTestPrimary.mdf', size = 8092KB, filegrowth = 1024KB) , filegroup [fg1] (name ='PTestFG1', filename = 'E:\data\partitionTestFG1.ndf', size = 8092KB, filegrowth = 1024KB) , filegroup [fg2] (name ='PTestFG2', filename = 'E:\data\partitionTestFG2.ndf', size = 8092KB, filegrowth = 1024KB) , filegroup [fg3] (name ='PTestFG3', filename = 'E:\data\partitionTestFG3.ndf', size = 8092KB, filegrowth = 1024KB) log on (name = 'PTest_Log', filename = 'E:\data\partitionTest_log.ldf', size = 2048KB, filegrowth = 1024KB); go alter database [PartitionTest] set recovery simple; go use partitionTest;
Crie uma tabela que iremos atormentar.
create table ptest (id int identity(1,1), dt datetime, dummy_int int, dummy_char char(6000));
E preencha com dados por um ano:
;with nums as ( select 0 n union all select 1 union all select 2 union all select 3 union all select 4 union all select 5 union all select 6 union all select 7 union all select 8 union all select 9 ) insert into ptest(dt, dummy_int, dummy_char) select dateadd(hh, rn-1, '20180101') dt, rn dummy_int, 'dummy char column #' + cast(rn as varchar) from ( select row_number() over(order by (select (null))) rn from nums n1, nums n2, nums n3, nums n4 )t where rn < 8761
Agora, a tabela pTest contém um registro para cada hora de 2018.
Agora você precisa criar uma função de partição que descreva as condições de contorno para dividir dados em seções. O SQL Server oferece suporte apenas ao particionamento de intervalo.
Dividiremos nossa tabela de acordo com a coluna dt (datetime) para que cada seção contenha dados por 4 meses (aqui eu estraguei tudo - de fato, a primeira seção conterá dados para 3, a segunda para 4, a terceira por 5 meses, mas para fins de demonstração - isso não é um problema)
create partition function pfTest (datetime) as range for values ('20180401', '20180801')
Tudo parece estar normal, mas aqui eu deliberadamente cometi um "erro". Se você observar a sintaxe no
msdn , verá que, durante a criação, pode especificar a qual seção a borda especificada pertencerá - à esquerda ou à direita. Por padrão, por algum motivo desconhecido, a borda especificada se refere à seção "esquerda"; portanto, no meu caso, seria correto criar uma função de partição da seguinte maneira:
create partition function pfTest (datetime) as range right for values ('20180401', '20180801')
Enquanto eu realmente executei:
create partition function pfTest (datetime) as range left for values ('20180401', '20180801')
Mas voltaremos a isso mais tarde e recriaremos nossa função de partição. Enquanto isso, continuamos com o que aconteceu para entender o que aconteceu e por que não é muito bom para nós.
Depois de criar a função de partição, você precisa criar um esquema de partição. Liga claramente as seções aos grupos de arquivos:
create partition scheme psTest as partition pfTest to ([FG1], [FG2], [FG3])
Como você pode ver, as três seções estarão em diferentes grupos de arquivos. Agora é hora de particionar nossa mesa. Para fazer isso, precisamos criar um índice em cluster e, em vez de especificar o grupo de arquivos no qual ele deve estar localizado, especifique o esquema de particionamento:
create clustered index cix_pTest_id on pTest(id) on psTest(dt)
E aqui também cometi um “erro” no esquema atual - eu poderia muito bem ter criado um índice clusterizado exclusivo nessa coluna; no entanto, ao criar um índice exclusivo, a coluna usada para particionar deve ser incluída no índice. E quero mostrar o que você pode encontrar com essa configuração.
Agora vamos ver o que obtivemos na configuração atual (a
solicitação é retirada daqui ):
SELECT sc.name + N'.' + so.name as [Schema.Table], si.index_id as [Index ID], si.type_desc as [Structure], si.name as [Index], stat.row_count AS [Rows], stat.in_row_reserved_page_count * 8./1024./1024. as [In-Row GB], stat.lob_reserved_page_count * 8./1024./1024. as [LOB GB], p.partition_number AS [Partition

Assim, obtivemos três seções sem muito êxito - as primeiras armazenam dados do início dos tempos até 01/01/2018 00:00:00 inclusive, a segunda - de 01/01/2018 00:00:01 a 08/01/2018 00:00:00 inclusive, a terceira, de 01/08/2018 00:00:01 até o fim do mundo (perdi deliberadamente a fração de segundo, porque não me lembro em qual graduação o SQL Server grava essas frações, mas o significado é transmitido corretamente).
Agora crie um índice não clusterizado no campo dummy_int, "alinhado" de acordo com o mesmo esquema de particionamento.
Por que precisamos de um índice alinhado?precisamos de um índice alinhado para que possamos executar a operação de alternar uma seção (switch) - e essa é uma daquelas operações para as quais, muitas vezes, elas se preocupam com o particionamento. Se houver pelo menos um índice não alinhado na tabela, você não poderá alternar a seção
create nonclustered index nix_pTest_dummyINT on pTest(dummy_int) on psTest(dt);
E vamos ver por que eu disse que suas consultas podem ficar mais lentas após a implementação do corte. Execute a solicitação:
SET STATISTICS TIME, IO ON; select id from pTest where dummy_int = 54 SET STATISTICS TIME, IO OFF;
E vamos ver as estatísticas de execução:
Table 'ptest'. Scan count 3, logical reads 6, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
E o plano de implementação:

Como nosso índice é "alinhado" por seções, condicionalmente, cada seção tem seu próprio índice, que é "desconectado" com índices de outras seções. Como não impusemos condições no campo pelo qual o índice é particionado, o SQL Server é forçado a executar a Pesquisa de Índice em cada seção; na verdade, 3 Pesquisa de Índice em vez de uma.
Vamos tentar excluir uma seção:
SET STATISTICS TIME, IO ON; select id from pTest where dummy_int = 54 and dt < '20180801' SET STATISTICS TIME, IO OFF;
E vamos ver as estatísticas de execução:
Table 'ptest'. Scan count 2, logical reads 4, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Sim, uma seção foi excluída e a busca pelo valor desejado foi realizada em apenas duas seções.
Isso é algo que deve ser lembrado ao decidir o particionamento. Se você tiver consultas que não usem uma restrição no campo pelo qual a tabela é particionada, você pode ter um problema.
Não precisamos mais do índice não agrupado, então eu o apago
drop index nix_pTest_dummyINT on pTest;
E por que um índice não cluster era necessário?em geral, eu não precisava, podia mostrar a mesma coisa com o índice de cluster, não sei por que o criei, mas desde que fiz e fiz capturas de tela - não desapareça
Agora, considere o seguinte cenário: arquivamos os dados dessa tabela a cada 4 meses - removemos os dados antigos e adicionamos uma seção pelos próximos quatro meses (a organização da “janela deslizante” é descrita no msdn e em vários blogs).
Dividimos a tarefa em subtarefas pequenas e compreensíveis:
- Adicione uma seção para dados de 01/01/2019 a 01/04/2019
- Crie uma tabela de estágio vazia
- Alterne a seção de dados até 01/04/2018 na tabela de estágios
- Livre-se da seção vazia
Vamos lá:
1. Anunciamos que a nova seção será criada no grupo de arquivos FG1, porque em breve será liberada de nós:
alter partition scheme psTest next used [FG1];
E mude a função de partição adicionando uma nova borda:
SET STATISTICS TIME, IO ON; alter partition function pfTest() split range ('20190101'); SET STATISTICS TIME, IO OFF;
Analisamos as estatísticas:
Table 'ptest'. Scan count 1, logical reads 76171, physical reads 0, read-ahead reads 753, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 1, logical reads 7440, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Existem 8809 páginas na tabela (índice de cluster); portanto, o número de leituras está além do bem e do mal. Vamos ver o que temos agora nas seções.

Em geral, tudo estava como esperado - uma nova seção com um limite superior apareceu (lembre-se de que as condições de limite para nós pertencem à seção esquerda) 01/01/2019 e uma seção vazia na qual haverá outros dados com uma data mais longa.
Tudo parece estar bem, mas por que existem tantas leituras? Observamos atentamente a figura acima e vemos que os dados da terceira seção que estavam no FG3 terminaram no FG1, mas a próxima seção, vazia, no FG3.
2. Crie uma tabela de estágio.
Para alternar (alternar) uma seção para uma tabela e vice-versa, precisamos de uma tabela vazia na qual todas as mesmas restrições e índices são criados como em nossa tabela particionada. A tabela deve estar no mesmo grupo de arquivos da seção que queremos “alternar” lá. A primeira seção (arquivada) está no FG1, então criamos uma tabela e um índice de cluster no mesmo local:
create table stageTest (id int identity(1,1), dt datetime, dummy_int int, dummy_char char(6000)) ; create clustered index cix_stageTest_id on stageTest(id) on [FG1];
Você não precisa particionar esta tabela.
3. Agora estamos prontos para mudar:
SET STATISTICS TIME, IO ON; alter table pTest switch partition 1 to stageTest SET STATISTICS TIME, IO OFF;
E aqui está o que temos:
4947, 16, 1, 59 ALTER TABLE SWITCH statement failed. There is no identical index in source table 'PartitionTest.dbo.pTest' for the index 'cix_stageTest_id' in target table 'PartitionTest.dbo.stageTest' .
Engraçado, vamos ver o que temos nos índices:
select o.name tblName, i.name indexName, c.name columnName, ic.is_included_column from sys.indexes i join sys.objects o on i.object_id = o.object_id join sys.index_columns ic on ic.object_id = i.object_id and ic.index_id = i.index_id join sys.columns c on ic.column_id = c.column_id and o.object_id = c.object_id where o.name in ('pTest', 'stageTest')
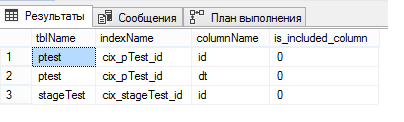
Lembre-se, eu escrevi que era necessário criar um índice clusterizado exclusivo em uma tabela particionada? É exatamente por isso que foi necessário. Ao criar um índice clusterizado exclusivo, o SQL Server exigiria a inclusão explícita da coluna pela qual particionamos a tabela no índice; portanto, ele mesmo a adicionou e esqueceu de dizê-lo. E eu realmente não entendo o porquê.
Mas, em geral, o problema é compreensível, recriamos o índice de cluster na tabela de estágio.
create clustered index cix_stageTest_id on stageTest(id, dt) with (drop_existing = on) on [FG1];
E agora, mais uma vez, tentamos mudar a seção:
SET STATISTICS TIME, IO ON; alter table pTest switch partition 1 to stageTest SET STATISTICS TIME, IO OFF;
Ta Dam! A seção é alternada, veja o que nos custou:
SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 3 ms.
Mas nada. Mudar uma seção para uma tabela vazia e vice-versa (uma tabela completa para uma seção vazia) é uma operação exclusivamente em metadados e é exatamente por isso que o particionamento é uma coisa muito, muito legal.
Vamos ver o que há com nossas seções:

E tudo está ótimo com eles. Na primeira seção, não há mais registros, eles foram deixados com segurança para a tabela stageTest. Podemos seguir em frente
4. Tudo o que resta para nós é excluir nossa primeira seção vazia. Vamos fazer isso e ver o que acontece:
SET STATISTICS TIME, IO ON; alter partition function pfTest() merge range ('20180401'); SET STATISTICS TIME, IO OFF;
E isso também é uma operação apenas em metadados, no nosso caso. Nós olhamos para as seções:

Temos apenas três seções, cada uma em seu próprio grupo de arquivos. Missão cumprida. O que poderia ser melhorado aqui? Bem, primeiro, eu gostaria que os valores-limite se referissem às seções "certas", para que as seções contenham todos os dados por 4 meses. E eu gostaria que a criação de uma nova seção custasse menos. Leia os dados dez vezes mais que a tabela em si - falida.
Não podemos fazer nada com o primeiro agora, mas com o segundo vamos tentar. Vamos criar uma nova seção que conterá dados de 01/01/2019 a 01/04/2019, e não até o final dos tempos:
alter partition scheme psTest next used [FG2]; SET STATISTICS TIME, IO ON; alter partition function pfTest() split range ('20190401'); SET STATISTICS TIME, IO OFF;
E nós vemos:
SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms.
Ha! Então agora esta operação é apenas em metadados? Sim, se você "dividir" uma seção vazia - esta é uma operação apenas em metadados, portanto, será a decisão certa manter as seções vazias garantidas esquerda e direita e, se necessário, selecionar uma nova - "cortá-las" a partir daí.
Agora vamos ver o que acontece se eu quiser retornar os dados da tabela de estágio para a tabela particionada. Para fazer isso, precisarei de:
- Crie uma nova seção à esquerda para dados
- Mude a tabela para esta seção
Tentamos (e lembramos que stageTest em FG1):
alter partition scheme psTest next used [FG1]; SET STATISTICS TIME, IO ON; alter partition function pfTest() split range ('20180401'); SET STATISTICS TIME, IO OFF;
Vemos:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'ptest'. Scan count 1, logical reads 2939, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Bem, não é ruim, ou seja, leia apenas a seção esquerda (que dividimos) e é isso. Ok Para alternar uma tabela não-vazia não particionada para uma seção de tabela particionada, a tabela de origem deve ter restrições para que o SQL Server saiba que tudo ficará bem e a alternância pode ser feita como uma operação nos metadados (em vez de ler tudo em uma linha e verificar se a seção corresponde às condições ou não ):
alter table stageTest add constraint check_dt check (dt <= '20180401')
Tentando mudar:
SET STATISTICS TIME, IO ON; alter table stageTest switch to pTest partition 1 SET STATISTICS TIME, IO OFF;
Estatísticas:
SQL Server Execution Times: CPU time = 15 ms, elapsed time = 39 ms.
Novamente, a operação está apenas em metadados. Examinamos o que há em nossas seções:

Ok Parece resolvido. E agora tentaremos recriar a função e o esquema de particionamento (excluí o esquema e a função de particionamento, recriei e recarreguei a tabela e recriei o índice de cluster usando o novo esquema de particionamento):
create partition function pfTest (datetime) as range right for values ('20180401', '20180801')
Vamos ver quais seções temos agora:

Bem, agora temos três seções "lógicas" - desde o início dos tempos até 01/04/2018 00:00:00 (não incluso), de 01/01/2018 00:00:00 (inclusive) a 01/01/2018 00:00:00 ( não inclusivo) e o terceiro, tudo que seja maior ou igual a 01/01/2018 00:00:00.
Agora vamos tentar executar a mesma tarefa de arquivar dados que realizamos com a função de partição anterior.
1. Adicione uma nova seção:
alter partition scheme psTest next used [FG1]; SET STATISTICS TIME, IO ON; alter partition function pfTest() split range ('20190101'); SET STATISTICS TIME, IO OFF;
Analisamos as estatísticas:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'ptest'. Scan count 1, logical reads 3685, physical reads 0, read-ahead reads 4, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 1, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Nada mal, pelo menos razoavelmente - leia apenas a última seção. Analisamos o que temos nas seções:

Observe que agora, a terceira seção concluída permaneceu no FG3 e uma nova seção vazia foi criada no FG1.
2. Criamos uma tabela de estágio e o índice de cluster CORRETO nela
create table stageTest (id int identity(1,1), dt datetime, dummy_int int, dummy_char char(6000)) ; create clustered index cix_stageTest_id on stageTest(id, dt) on [FG1];
3. Seção de comutação
SET STATISTICS TIME, IO ON; alter table pTest switch partition 1 to stageTest SET STATISTICS TIME, IO OFF;
As estatísticas dizem que a operação de metadados é:
SQL Server Execution Times: CPU time = 0 ms, elapsed time = 5 ms.
Agora, tudo sem surpresas.
4. Remova a seção desnecessária
SET STATISTICS TIME, IO ON; alter partition function pfTest() merge range ('20180401'); SET STATISTICS TIME, IO OFF;
E aqui temos uma surpresa:
Table 'ptest'. Scan count 1, logical reads 27057, physical reads 0, read-ahead reads 251, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Examinamos o que temos com as seções:

E aqui fica claro: nossa seção 2 passou do grupo de arquivos fg2 para o grupo de arquivos fg1. Class. Podemos fazer algo sobre isso?
Talvez apenas precisemos sempre ter uma seção vazia e "destruir" a borda entre a seção esquerda "sempre vazia" e a seção que "trocamos" para outra tabela.
Em conclusão:- Use a sintaxe completa para criar a função de partição, não confie nos valores padrão - você pode não conseguir o que queria.
- Mantenha a esquerda e a direita na seção vazia - elas serão muito úteis para organizar uma "janela deslizante".
- Dividir e mesclar seções não vazias - sempre dói, evite-o se possível.
- Verifique suas consultas - se elas não usarem o filtro da coluna pela qual planeja particionar a tabela e você precisar trocar de seção - o desempenho delas poderá diminuir significativamente.
- Se você quiser fazer algo, primeiro teste não em produção.
Espero que o material tenha sido útil. Talvez tenha ficado amassado, se você acha que algo do declarado não foi divulgado, escreva, tentarei finalizá-lo. Obrigado pela atenção.