A web moderna é quase impensável sem conteúdo de mídia: quase todas as nossas avós têm smartphones, todo mundo senta nas redes sociais e o tempo de inatividade dos serviços é caro para as empresas. A sua atenção está uma transcrição da história do Badoo sobre como organizou a entrega de fotos usando uma solução de hardware, quais problemas de desempenho foram encontrados no processo, o que os causou e como esses problemas foram resolvidos usando uma solução de software baseada no Nginx, garantindo tolerância a falhas em todos os níveis ( vídeo ). Agradecemos aos autores da história Oleg Sannis Efimov e Alexander Dymov, que compartilharam sua experiência na conferência Uptime day 4 .
A web moderna é quase impensável sem conteúdo de mídia: quase todas as nossas avós têm smartphones, todo mundo senta nas redes sociais e o tempo de inatividade dos serviços é caro para as empresas. A sua atenção está uma transcrição da história do Badoo sobre como organizou a entrega de fotos usando uma solução de hardware, quais problemas de desempenho foram encontrados no processo, o que os causou e como esses problemas foram resolvidos usando uma solução de software baseada no Nginx, garantindo tolerância a falhas em todos os níveis ( vídeo ). Agradecemos aos autores da história Oleg Sannis Efimov e Alexander Dymov, que compartilharam sua experiência na conferência Uptime day 4 .- Vamos começar com uma breve introdução sobre como armazenamos e armazenamos fotos em cache. Temos uma camada na qual os armazenamos e uma camada na qual armazenamos fotos em cache. Ao mesmo tempo, se queremos obter um grande sucesso e reduzir a carga em cem, é importante para nós que cada foto de um usuário individual esteja em um servidor de cache. Caso contrário, teríamos que colocar quantas vezes mais discos, quantos servidores mais temos. Temos uma taxa de acerto de cerca de 99%, ou seja, reduzimos a carga em nosso armazenamento em 100 vezes e, para fazer isso, mesmo há 10 anos, quando tudo isso foi construído, tínhamos 50 servidores. Portanto, para fornecer essas fotos, precisávamos de 50 domínios externos que esses servidores atendem.
Naturalmente, surgiu imediatamente a pergunta: se um servidor cair, ele estará indisponível, que parte do tráfego estamos perdendo? Examinamos o que está no mercado e decidimos comprar um pedaço de ferro para resolver todos os nossos problemas. A escolha recaiu sobre a decisão da empresa da rede F5 (que, aliás, comprou recentemente a NGINX, Inc): gerente de tráfego local do BIG-IP.

O que essa peça de hardware (LTM) faz: é um roteador de ferro que faz a redundância de ferro de suas portas externas e permite rotear o tráfego com base na topologia da rede, em algumas configurações e faz verificações de integridade. Era importante para nós que este pedaço de ferro pudesse ser programado. Dessa forma, poderíamos descrever a lógica de como as fotografias de um usuário específico foram tiradas de um cache específico. Como é isso? Há um pedaço de ferro que olha na Internet em um domínio, um ip, descarrega ssl, analisa solicitações de HTTP, o IRule seleciona o número do cache para onde ir e permite que o tráfego vá para lá. Ao mesmo tempo, ele faz verificações de integridade e, se alguma máquina estiver indisponível, fizemos nesse momento para que o tráfego fosse para um servidor de backup. Do ponto de vista da configuração, é claro, existem algumas nuances, mas, em geral, tudo é bastante simples: prescrevemos uma placa, combinamos algum número com o nosso IP na rede, dizemos que ouviremos nas portas 80 e 443, dizemos: se o servidor estiver indisponível, você precisará iniciar o tráfego no backup, neste caso o 35º, e descreveremos um monte de lógica de como essa arquitetura deve ser desmontada. O único problema era que a linguagem que programava a peça de hardware era Tcl. Se alguém se lembra disso ... essa linguagem é mais somente para gravação do que uma linguagem conveniente para programação:

O que conseguimos? Temos um hardware que fornece alta disponibilidade de nossa infraestrutura, direciona todo o nosso tráfego, fornece cuidados de saúde e simplesmente funciona. Além disso, ele vem trabalhando há algum tempo: nos últimos 10 anos, não houve queixas a respeito. No início de 2018, já estávamos distribuindo cerca de 80 mil fotos por segundo. Isso representa cerca de 80 gigabits de tráfego de ambos os nossos data centers.
No entanto ...
No início de 2018, vimos uma imagem feia nas paradas: o tempo de resposta das fotos aumentou claramente. E deixou de nos servir. O problema é que esse comportamento era visível apenas no pico do tráfego - para nossa empresa, hoje é a noite de domingo a segunda-feira. Mas o resto do tempo, o sistema se comportou como de costume, sem sinais de danos.

No entanto, o problema teve que ser resolvido. Identificamos possíveis gargalos e começamos a eliminá-los. Antes de tudo, é claro, expandimos os uplinks externos, realizamos uma auditoria completa dos uplinks internos e encontramos todos os possíveis gargalos. Mas tudo isso não deu um resultado óbvio, o problema não desapareceu.
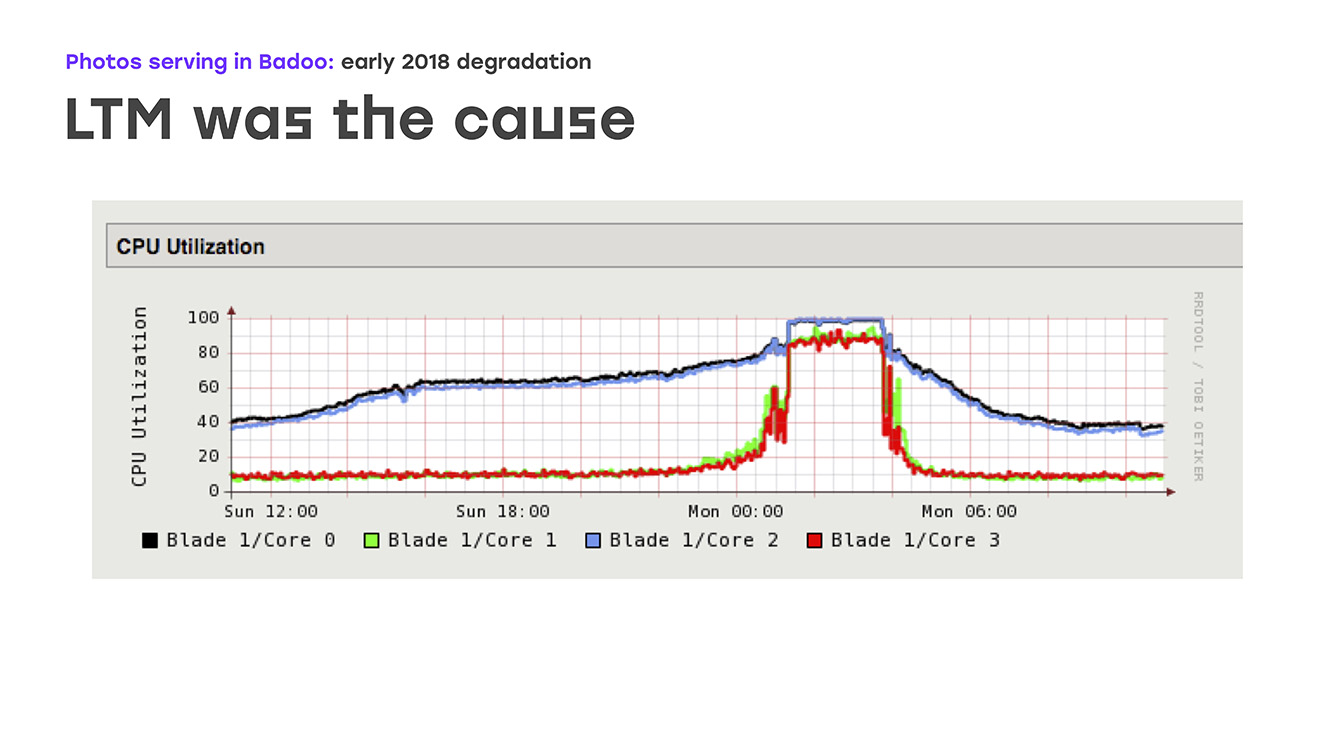
Outro possível gargalo foi o desempenho dos próprios caches de fotos. E decidimos que talvez o problema estivesse sobre eles. Bem, expandimos o desempenho - principalmente portas de rede em caches de fotos. Mas, novamente, nenhuma melhoria aparente foi vista. No final, prestamos muita atenção ao desempenho do próprio LTM, e aqui vimos uma imagem triste nos gráficos: o carregamento de todas as CPUs começa a funcionar sem problemas, mas repentinamente repousa na prateleira. Ao mesmo tempo, o LTM para de responder adequadamente às verificações de integridade e aos uplinks e começa a desativá-los aleatoriamente, o que leva a uma grave degradação do desempenho.
Ou seja, identificamos a origem do problema, identificamos o gargalo. Resta decidir o que faremos.
A primeira coisa que podemos sugerir é a atualização do LTM. Mas existem algumas nuances, porque esse ferro é único, você não vai ao supermercado mais próximo e não o compra. Este é um contrato separado, um contrato de licença separado e levará muito tempo. A segunda opção é começar a pensar por si mesmo, criar sua própria solução em seus componentes, de preferência usando um programa de acesso aberto. Resta apenas decidir exatamente o que escolheremos para isso e quanto tempo gastaremos na solução desse problema, porque os usuários não receberam fotos. Portanto, tudo isso deve ser feito muito, muito rapidamente, pode-se dizer - ontem.
Como a tarefa parecia “fazer algo o mais rápido possível e usar o hardware que possuímos”, a primeira coisa que pensamos foi simplesmente remover algumas máquinas não mais poderosas da frente, colocar o Nginx com o qual sabemos como trabalhar e tentamos implementar toda a lógica que o pedaço de ferro costumava fazer. Ou seja, deixamos nosso hardware, configuramos mais 4 servidores que precisávamos configurar, criamos domínios externos para eles, semelhante a 10 anos atrás ... Perdemos um pouco de disponibilidade se essas máquinas falhassem, mas menos resolveu o problema de nossos usuários localmente.
Consequentemente, a lógica permanece a mesma: colocamos o Nginx, ele pode fazer o descarregamento de SSL, de alguma forma podemos programar a lógica de roteamento, verificações de integridade nas configurações e apenas duplicar a lógica que tínhamos antes.
Nos sentamos para escrever configurações. A princípio, parecia que tudo era muito simples, mas, infelizmente, é muito difícil encontrar manuais para cada tarefa. Portanto, não recomendamos apenas o google "como configurar o Nginx para fotos": é melhor consultar a documentação oficial, que mostra quais configurações valem a pena ser tocadas. Mas é melhor escolher um parâmetro específico. Bem, então tudo é simples: descrevemos os servidores que temos, descrevemos certificados ... Mas o mais interessante é, de fato, a lógica do roteamento em si.
Inicialmente, pareceu-nos que simplesmente descrevemos nossa localização, correspondemos ao número de nosso cache de fotos, descrevemos com nossas mãos ou com o gerador quantos upstream precisamos, em cada upstream indicamos o servidor ao qual o tráfego deve ir e um servidor de backup no caso do servidor principal indisponível:

Mas, provavelmente, se tudo fosse tão simples, simplesmente iríamos para casa e não diríamos nada. Infelizmente, com as configurações padrão do Nginx, que, em geral, foram feitas ao longo de muitos anos de desenvolvimento e não exatamente para esse caso ... a configuração fica assim: se algum servidor upstream apresentar um erro de solicitação ou tempo limite, o Nginx sempre muda o tráfego para o próximo. Ao mesmo tempo, após o primeiro arquivo, o servidor também será desligado por 10 segundos, por engano e por tempo limite - isso nem pode ser configurado. Ou seja, se removermos ou redefinirmos a opção de tempo limite na diretiva upstream, embora o Nginx não processe essa solicitação e responda com algum erro não tão bom, o servidor será desligado.

Para evitar isso, fizemos duas coisas:
a) proibiram o Nginx de fazer isso manualmente - e, infelizmente, a única maneira de fazer isso é simplesmente definir as configurações de falha máxima.
b) lembrou que em outros projetos usamos um módulo que permite realizar verificações de saúde em segundo plano - portanto, fizemos verificações de saúde razoavelmente frequentes para que tivéssemos um mínimo em caso de acidente.
Infelizmente, isso não é tudo, porque, literalmente, as duas primeiras semanas desse esquema mostraram que a verificação de integridade do TCP também é uma coisa não confiável: não o Nginx ou o Nginx no estado D podem ser gerados no servidor upstream, neste caso o kernel aceitará a conexão, a verificação de integridade passará, mas não funcionará. Portanto, imediatamente o substituímos por http'shny de verificação de saúde, fizemos um específico, que, se retornar 200, tudo funcionará nesse script. Você pode fazer lógica adicional - por exemplo, no caso de servidores de armazenamento em cache, verifique se o sistema de arquivos está montado corretamente:

E isso nos conviria, exceto que no momento o circuito repetia completamente o que o pedaço de ferro fazia. Mas queríamos fazer melhor. Anteriormente, tínhamos um servidor de backup, e provavelmente isso não é muito bom, porque se você tiver cem servidores, quando várias falhas ao mesmo tempo, é improvável que um servidor de backup lide com a carga. Portanto, decidimos distribuir a reserva por todos os servidores: fizemos outro upstream separado, anotamos todos os servidores com determinados parâmetros de acordo com o tipo de carga que eles podem suportar, adicionamos as mesmas verificações de saúde que tínhamos antes :

Como é impossível ir para outro upstream dentro de um upstream, era necessário garantir que, caso o mainstream principal não estivesse disponível, no qual o cache de fotos correto fosse simplesmente gravado, simplesmente passássemos para fallback via error_page, de onde fomos fazer backup em abril:

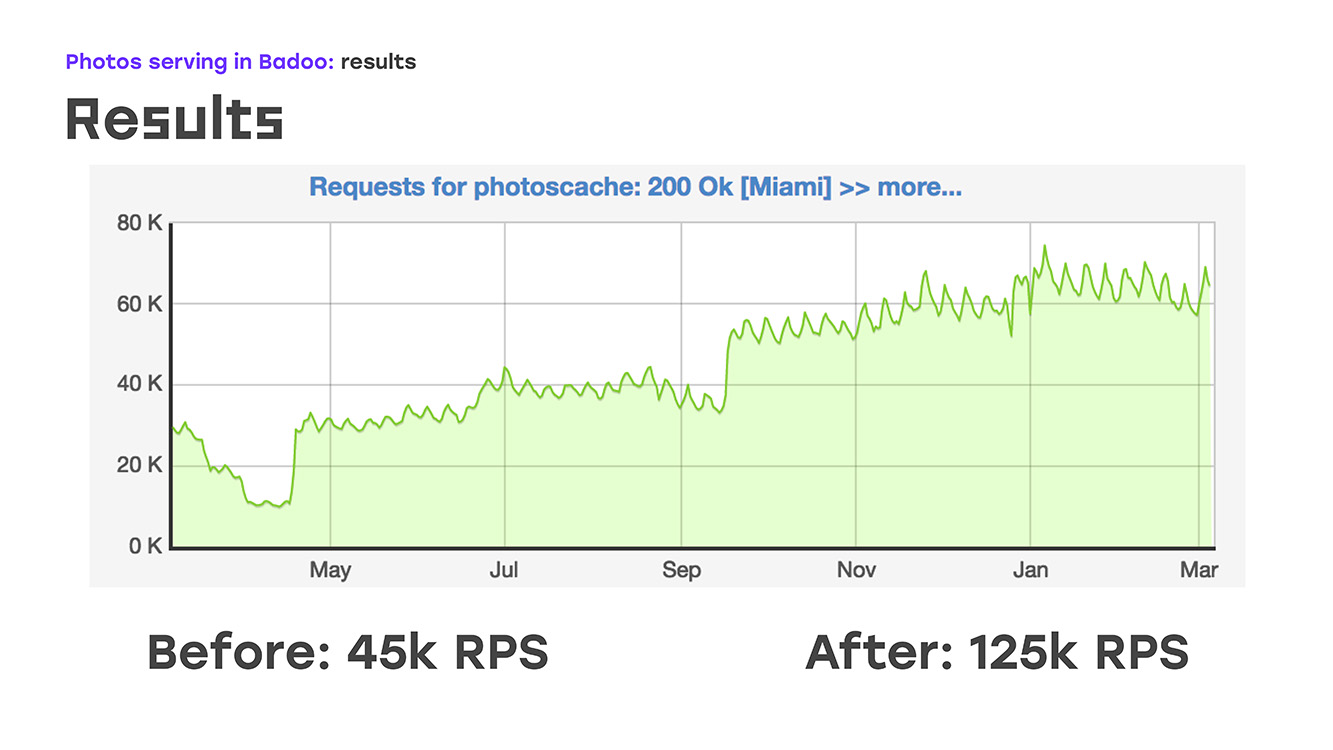
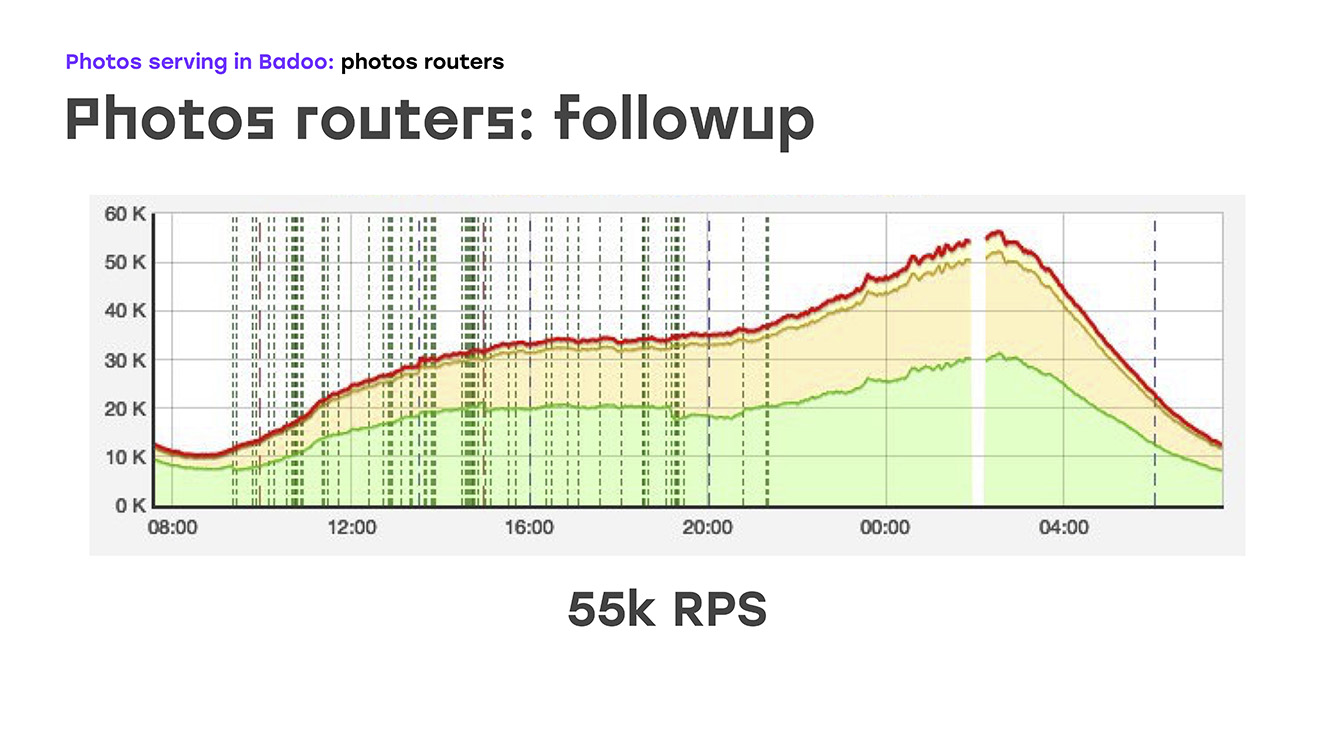
E, literalmente, adicionando quatro servidores, obtivemos o seguinte: substituímos parte da carga - removida do LTM para esses servidores, implementamos a mesma lógica usando hardware e software padrão e obtivemos imediatamente o bônus de que esses servidores podem ser dimensionados porque podem ser simplesmente coloque o quanto você precisar. Bem, o único aspecto negativo é que perdemos alta disponibilidade para usuários externos. Mas naquele momento eu tive que sacrificar isso, porque tive que resolver imediatamente o problema. Portanto, removemos uma parte da carga, ou seja, cerca de 40% naquele momento, o LTM se sentiu bem e, literalmente, duas semanas após o início do problema, começamos a enviar não 45k solicitações por segundo, mas 55k. De fato, crescemos 20%. Esse é claramente o tráfego que não fornecemos ao usuário. E depois disso, começaram a pensar em como resolver o problema restante - para fornecer alta acessibilidade externa.
Tivemos uma pausa durante a qual discutimos qual solução usaremos para isso. Houve sugestões para garantir a confiabilidade usando o DNS, usando alguns scripts auto-escritos, protocolos de roteamento dinâmico ... havia muitas opções, mas ficou claro que, para uma saída fotográfica verdadeiramente confiável, é necessário introduzir outra camada que monitore isso. Chamamos esses diretores de fotografia de máquinas. Como o software em que confiamos, eu escolhi o Keepalived:

Para começar - no que Keepalived consiste. O primeiro é o protocolo VRRP, amplamente conhecido pelos operadores de rede, localizado no equipamento de rede que fornece tolerância a falhas para o endereço IP externo ao qual os clientes se conectam. A segunda parte é o IPVS, servidor virtual IP, para balancear os roteadores de fotos e garantir a tolerância a falhas nesse nível. E o terceiro são exames de saúde.
Vamos começar com a primeira parte: VRRP - como ela é? Há um certo IP virtual no qual há uma entrada no dns badoocdn.com em que os clientes estão conectados. Em algum momento, temos um endereço IP em um servidor. Os pacotes de manutenção mantida são executados entre os servidores usando o protocolo VRRP e, se o assistente desaparecer do radar - o servidor reiniciado ou outra coisa, o servidor de backup gera automaticamente esse endereço IP automaticamente - não são necessárias etapas manuais. O mestre e o backup diferem, principalmente a prioridade: quanto maior, maior a probabilidade de a máquina se tornar mestre. Uma grande vantagem é que não é necessário configurar endereços IP no próprio servidor, basta descrevê-los na configuração e, ao mesmo tempo, os endereços IP precisam de algumas regras de roteamento personalizadas, isso é descrito diretamente na configuração, a mesma sintaxe descrita. no pacote VRRP. Você não encontrará nada estranho.
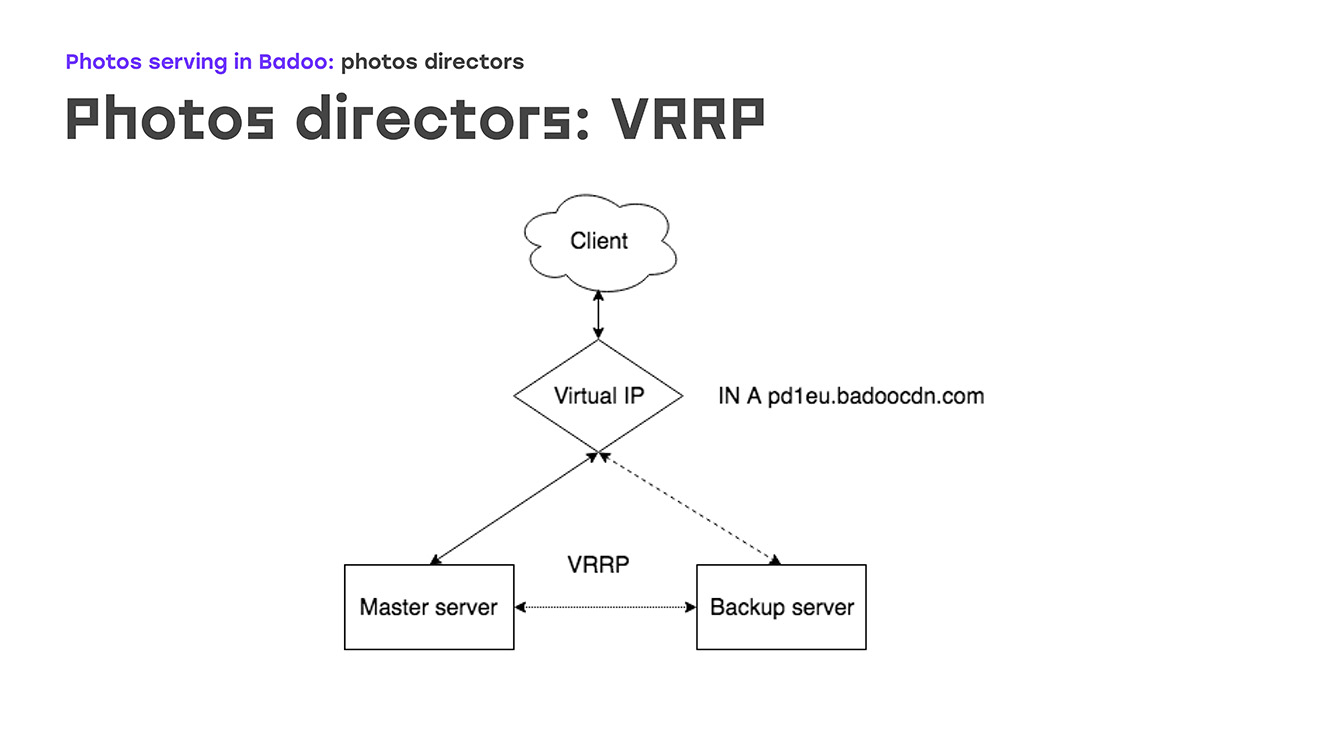
Como é na prática? O que acontece se um dos servidores ficar inativo? Assim que o mestre desaparece, nosso backup para de receber anúncios e se torna automaticamente mestre. Depois de algum tempo, consertamos o mestre, reinicializamos e levantamos o Keepalived - as aventuras vêm com uma prioridade mais alta que o backup, e o backup volta automaticamente, remove os endereços IP, não são necessárias ações manuais.

Assim, garantimos a tolerância a falhas do endereço IP externo. A próxima parte é equilibrar o tráfego dos roteadores de fotos que já o terminam com um endereço IP externo. Com os protocolos de balanceamento, tudo fica bem claro. Este é um round-robin simples ou coisas um pouco mais complexas, wrr, conexão de lista e assim por diante. Isso é descrito em princípio na documentação, não há nada de especial. Mas o método de entrega ... Aqui nos concentramos em mais detalhes - por que eles escolheram um deles. Estes são NAT, roteamento direto e TUN. O fato é que imediatamente estipulamos o retorno de 100 gigabits de tráfego dos sites. Se isso for estimado, você precisa de 10 cartões de gigabit, certo? Placas de 10 gigabit em um servidor - isso já está além do escopo de pelo menos o nosso conceito de "equipamento padrão". E então lembramos que não estamos apenas dando algum tráfego, estamos dando fotos.
Qual é o recurso? - A enorme diferença entre tráfego de entrada e saída. O tráfego de entrada é muito pequeno, a saída é muito grande:
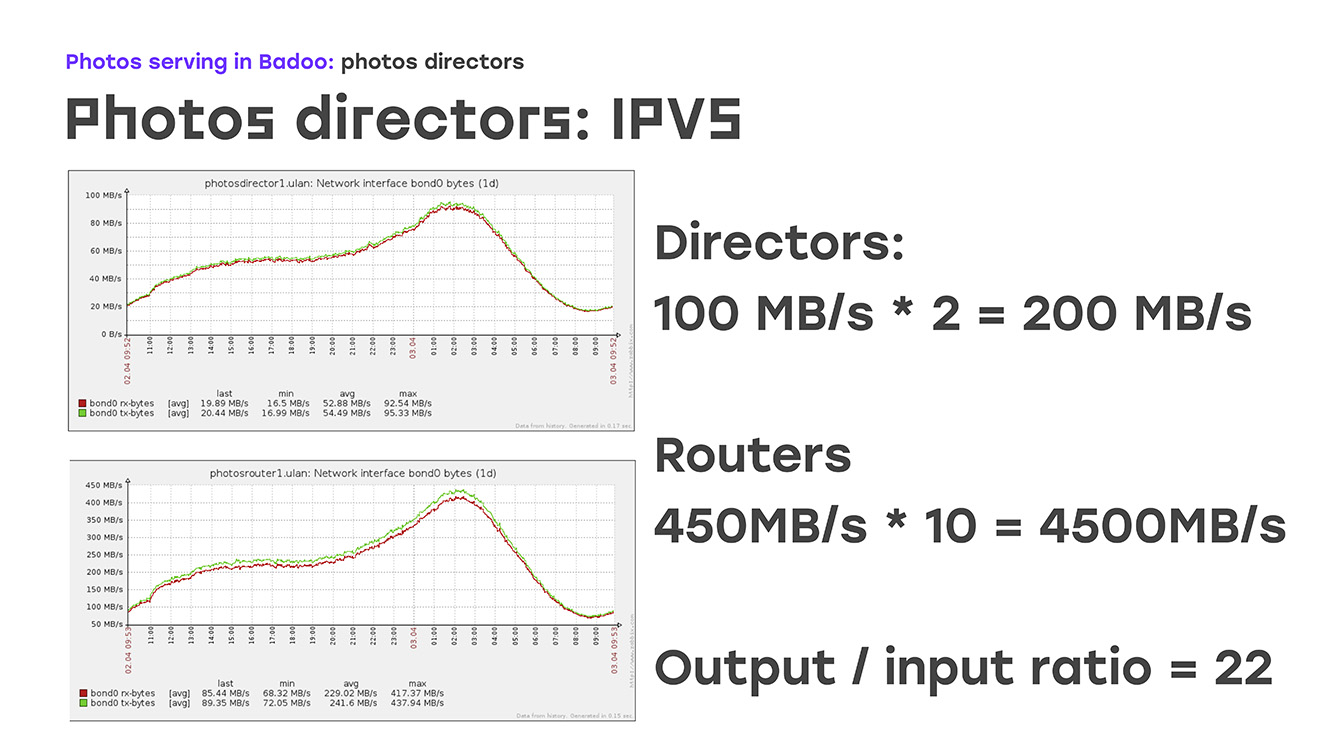
Se você observar esses gráficos, poderá ver que no momento cerca de 200 MB por segundo está chegando ao diretor, este é o dia mais comum. Estamos devolvendo 4.500 MB por segundo, a proporção é de cerca de 1/22. Já está claro que, para garantir totalmente o tráfego de saída para 22 servidores em funcionamento, basta um que aceite essa conexão. Aqui, o algoritmo de roteamento direto, o algoritmo de roteamento, vem em nosso auxílio.
Como é isso? De acordo com nossa tabela, o diretor de fotografia transfere as conexões para os roteadores de fotos. Mas os roteadores de fotos enviam o tráfego de retorno diretamente para a Internet, enviam para o cliente, não retornam ao diretor de fotografia, portanto, com o número mínimo de máquinas, fornecemos tolerância total a falhas e bombeamento de todo o tráfego. Nas configurações, fica assim: especificamos o algoritmo, no nosso caso, é um rr simples, fornecemos um método de roteamento direto e depois começamos a listar todos os servidores reais, quantos temos. O que determinará esse tráfego. Caso tenhamos mais um ou dois servidores lá, essa necessidade surge - basta adicionar esta seção na configuração e não nos preocupamos. Na parte dos servidores reais, na parte do roteador de fotos, esse método requer configuração mínima, é perfeitamente descrito na documentação e não há armadilhas por lá.
O que é especialmente interessante - essa solução não implica uma alteração radical da rede local, foi importante para nós, tivemos que resolvê-la com um custo mínimo. Se você observar a
saída do comando admin do IPVS , veremos como ela se parece. Aqui temos um servidor virtual, na porta 443, que escuta, aceita a conexão, todos os servidores em funcionamento estão listados e é claro que a conexão é a mesma, mais ou menos. Se olharmos para as estatísticas no mesmo servidor virtual, temos pacotes recebidos, conexões recebidas, mas absolutamente nenhum envio. As conexões de saída vão diretamente para o cliente. Bem, fomos capazes de desequilibrar. Agora, o que acontece se um dos roteadores de fotos entrar em falha? Afinal, ferro é ferro. Pode entrar em pânico do kernel, pode quebrar, a fonte de alimentação pode queimar. Qualquer coisa. Para isso, são necessárias verificações de saúde. Eles podem ser os mais simples - verificando como a porta está aberta conosco - ou alguns mais complexos, até alguns scripts auto-escritos que até checam a lógica de negócios.
Paramos em algum lugar no meio: temos uma solicitação https para um local específico, um script é chamado se responder com a 200ª resposta, acreditamos que tudo está normal neste servidor, que está ativo e que você pode ativá-lo com bastante calma.
Como, novamente, parece na prática. Desligue o servidor, digamos para o serviço - BIOS piscando, por exemplo. Nos logs, temos um tempo limite imediatamente, vemos a primeira linha; depois de três tentativas, ela é marcada como "invertida" e é simplesmente excluída da lista.

Há um segundo comportamento possível quando simplesmente VS é definido como zero, mas se a foto for retornada, ela não funcionará bem. O servidor sobe, o Nginx começa por lá, ali as verificações de integridade entendem que a conexão passa, que está tudo bem, e o servidor aparece em nossa lista, e a carga começa automaticamente a ser aplicada a ele imediatamente. Ao mesmo tempo, nenhuma ação manual é necessária do administrador de plantão. À noite, o servidor é reiniciado - o departamento de monitoramento não nos chama sobre isso à noite. Eles informam que sim, tudo está normal.
, , .
, , , . , Keepalivede, , , DBus, SMTP, SNMP, Zabbix'. , , , - , , , IP- . , , . nginx -, . , , : -, health-check' , , , , - - . - , amazon -, , , anomaly detection, , machine learning, , , , , , . .
: , , , - , , , HTTPS health-check'. , , , , , .
? 2018-. , , LTM, - 40 60 , 2018- .