AntipovSN e MihhaCF
Parte dois, na qual Athos tem todas as regras, mas falta ao Conde de la Fer alguma coisa
UPD Part One está aqui
UPD parte três aqui
Introdução dos autores:
Boa tarde Hoje continuamos a série de artigos dedicados à pontuação e ao uso da teoria dos grafos. Você pode se familiarizar com o primeiro artigo aqui .
Todas as alegorias, inserções etc. de quadrinhos são projetadas para aliviar um pouco a narrativa e não permitir que ela caia em uma palestra tediosa. Pedimos desculpas a todos que não entendem nosso humor
O objetivo deste artigo: em não mais de 30 minutos, descrever as principais maneiras de armazenar dados de gráficos e descrever as regras e os princípios de construção de nosso modelo de pontuação para um mutuário.
Termos e definições:
- Uma tabela de hash é uma estrutura de dados que implementa a interface do array associativo; permite armazenar pares (chave, valor) e executar três operações: a operação de adicionar um novo par, a operação de pesquisa e a operação de excluir um par por chave. A pesquisa por tabela de hash, em média, é realizada durante o tempo O (1).
Os auditores contratados pela Korol PJSC para avaliar a credibilidade da One for All NPO encontraram alguns problemas. Por um lado, é muito simples descrever o esquema de interação de 10 a 15 empresas e realizar uma avaliação inicial da interação entre empresas; basta ter uma folha de papel e uma caneta à mão. Mas e se você tiver informações sobre a interação de dezenas ou centenas de milhares de empresas? Por exemplo, se você precisar descrever as interações de Aramis com todas as suas paixões ou D'artagnan com todos com quem ele lutou?
Como armazenar dados sobre essas interações?
Quais estruturas e abordagens de dados usar?
Os auditores teriam que plantar um corpo monástico inteiro de escritores para este trabalho.
Não faremos isso e forneceremos aos nossos auditores o conhecimento e as tecnologias do futuro ( enviaremos o Prometheus na forma de um T-800 a eles, o que lhes dará a luz do conhecimento ).
Bem, vamos começar a responder às perguntas colocadas. Que haja luz!
Como escrevemos e desenhamos aqui , um gráfico é uma proporção de 2 conjuntos - um conjunto de nós e um conjunto de arestas. Qual é a melhor maneira de armazenar um gráfico?
Antes de responder à pergunta de como armazenar o gráfico, você precisa decidir exatamente o que queremos armazenar e de que forma.
De acordo com a teoria dos grafos, os nós dos grafos podem ser quaisquer objetos com qualquer conjunto de parâmetros (esse fato será útil mais tarde para modelos avançados / adaptativos para o cálculo de uma bola de pontuação).
Então, o que precisamos armazenar?
No mínimo, o identificador do nó e os identificadores de seus vizinhos (a quem ele está associado). A presença desses dados já permite pesquisar em largura e profundidade.
Preciso armazenar dados da aresta do gráfico? Sim, se estamos lidando com um gráfico ponderado. No nosso caso, estamos lidando com um gráfico ponderado e, no primeiro artigo , desenhamos exatamente esse gráfico.
Esta informação é suficiente? Não.
De onde vieram as costelas? Nos livros, essas informações estão simplesmente lá, alguém as coletou e processou antes de nós. No final da Idade Média (exatamente na época em que os mosqueteiros viviam), ninguém se preocupava em calcular os pesos dos limites do nosso conde. Nós temos que fazer isso sozinhos. Neste e no próximo artigo, não descreveremos a metodologia específica para calcular o peso de uma aresta; isso será feito no artigo 4. Agora é importante para nós decidir quais informações sobre nosso gráfico armazenaremos.
Portanto, no nosso caso, existem três parâmetros principais que precisamos conhecer para calcular corretamente a pontuação:
- Uma avaliação interna de um nó - consiste em indicadores que caracterizam o nó (rotatividade, dívida, multas, etc.). No nosso exemplo, estes serão:
- Avaliação - um nó bom ou ruim em relação à NPO "Um por todos";
- Classificação do nó - o rei tem a classificação mais alta, Bonacieux - a mais baixa;
- O volume de fundos, em outras palavras, solvência.
- Avaliação das costelas. No nosso caso, a avaliação da conexão será para cada nó - isso significa que o relacionamento Bonacieux - Constance pode não ser igual à conexão Constance - Bonacieux, porque eles têm diferentes possibilidades de influenciar um ao outro.
- Nível do nó - não será armazenado, mas é um indicador importante.
Não pergunte de onde todos esses números vêm no modelo, D'artanyan vê isso. Na vida real, esses indicadores também não serão calculados por nós (comércio, dívidas, multas, etc., tomamos de fontes existentes, não estamos na Idade Média, mais ou menos).
De todas as opções acima, verifica-se que, além dos identificadores dos nós, devemos armazenar os parâmetros de cada nó e os pesos das arestas que obtemos com base na agregação dos parâmetros dos nós.
Total, as seguintes informações estão sujeitas a armazenamento:
- Nome do nó;
- Parâmetros do nó
- Nó Vizinhos;
- Peso da costela para cada vizinho.
Ótimo! Nós descobrimos o que precisamos armazenar. Agora - como guardar.
E novamente uma pequena digressão.
Como será o nosso processo de pontuação de forma simplificada:
- Coleta de dados de objetos;
- Formação de um objeto que descreverá o modelo gráfico. É nesta instalação que realizaremos todas as nossas operações de pontuação.
Com base nessas duas etapas, temos três opções:
- Armazenamos dados sobre o objeto de pontuação no servidor SQL / NoSQL. Todas as operações relacionadas a cálculos, algoritmos etc. são realizadas diretamente no servidor;
- Armazenamos dados sobre o objeto de pontuação no servidor SQL / NoSQL. Com base nesses dados, criamos um objeto separado (por exemplo, uma tabela de hash) com o qual realizamos todos os cálculos básicos;
- Os dados sobre o objeto de pontuação são armazenados na RAM. Com base nesses dados, criamos um objeto separado (por exemplo, uma tabela de hash) com o qual realizamos todos os cálculos básicos.
Requisitos básicos para esse processo:
- Velocidade de trabalho;
- Confiabilidade
- Verificabilidade.
Agora vamos conversar. Vamos sentar, como nossos mosqueteiros, sobre uma xícara do que eles beberam lá, chá, por exemplo. O principal é que não interferimos em todos os tipos de galos com os guardas.
Se for necessário armazenamento a longo prazo, você poderá selecionar uma tabela com os campos significativos correspondentes. No NoSQL ou RAM, é melhor armazenar dados na forma de uma lista ou diretório (tabela de hash) de objetos.
{ 'Id': 1, 'Title': ' ', 'Rang': 4, 'Type': '', 'Profit': 10000 }
Com os picos mais ou menos claros. Qual é a melhor maneira de representar os arcos / arestas de um gráfico? Para fazer isso, você precisa entender o princípio básico de qualquer operação analítica no gráfico - o acesso a qualquer arco / borda deve ocorrer muito rapidamente, preferencialmente, o tempo de acesso deve ser O (1). Um array ou matriz imediatamente vem à mente - uma estrutura na qual qualquer elemento pode ser acessado rapidamente por índice.
[i, j] - o elemento da matriz indica o arco do gráfico, onde i é o identificador do vértice inicial, j é o identificador do vértice final, o acesso e a seleção do vértice inicial ocorrem diretamente pelo identificador do vértice inicial. A interseção de i e j armazena o peso da aresta.
Existem várias desvantagens nessa visualização:
- Geralmente, a estrutura é redundante, especialmente se o gráfico for escasso (um pequeno número de arestas), existem muitos valores vazios que indicam que não há conexão.
- Para encontrar todos os vizinhos do vértice, é necessário classificar a matriz de todos os elementos da i-ésima linha da matriz de relacionamento.
- Uma matriz com muitas colunas não pode ser armazenada no banco de dados.
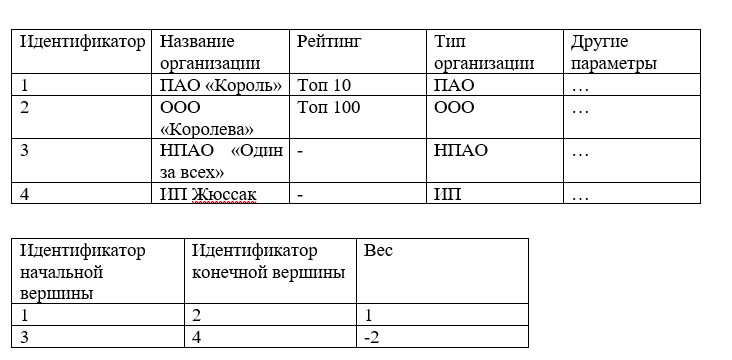
A próxima opção para armazenar arcos / arestas é uma tabela, ou seja, um conjunto de colunas e linhas.
Por exemplo:

Essa estrutura pode ser facilmente armazenada em um banco de dados relacional e, ao executar consultas SQL, você pode selecionar os valores necessários, mas quando se trata de RAM, a complexidade de encontrar todas as arestas do vértice aumenta e, no caso geral, leva O (n) onde n é o número de todas as arestas do gráfico.
Existe outro método muito bom de armazenamento de gráficos para uso em quase todos os sistemas, sem os inconvenientes descritos acima - essa é uma referência de valor-chave ou tabela de hash. A obtenção de todas as arestas do vértice desejado ocorre com a velocidade O (1).
Um ponto negativo significativo é que nem todas as linguagens de programação suportam esse design.
Como se pode imaginar uma estrutura semelhante em diferentes sistemas?
No banco de dados relacional, você pode implementar o relacionamento das tabelas de objetos e arestas (parágrafo anterior)
NoSQL
{ 'Id': 1, 'Title': ' ', 'Rang': 4, 'Type': '', 'Profit': 10000, 'Relations': [{3,2}, {4,5}, … {n, -5}] }
Ao acessar um objeto por sua chave, obtemos imediatamente um conjunto de conexões. Se tivermos um gráfico não ponderado, em vez de uma matriz de objetos, você pode passar uma matriz de identificadores de relações de vizinhos: [3,4, ... n]. Na forma de uma referência, a chave é o valor, esta opção é semelhante à anterior. No diretório, o valor-chave, você pode armazenar o mesmo objeto do exemplo anterior. A chave, é claro, será o identificador do vértice (pode haver um número, pode haver uma string etc., o que permite um sistema de desenvolvimento específico). Também no diretório, você pode armazenar apenas matrizes de links e informações sobre os vértices em outro diretório.
Graf[1] = { 'Id': 1, 'Title': ' ', 'Rang': 4, 'Type': '', 'Profit': 10000, 'Relations': [{3,2}, {4,5}, … {n, -5}] }
ou
graf['one_for_all'] = 'Relations': [{3,2}, {4,5}, … {n, -5}]
Para o nosso exemplo, escolhemos a opção de armazenar dados na RAM com a criação de uma tabela de hash para a pontuação dos dados. Os resultados intermediários serão gravados em um arquivo no servidor.
Temos estruturas de armazenamento mal e mal definidas, agora é hora de descobrir por onde começar a construir nosso modelo analítico. Vamos começar com um simples - definimos a interação com os vizinhos mais próximos e com os vizinhos dos vizinhos (amigos de amigos).
Assim, é possível determinar a interação com todos os vértices interconectados. De acordo com nossas observações, a interação com vizinhos mais profundos que o nível 2 é interessante apenas em casos especiais e é calculada por outros métodos. A complexidade desse cálculo é 0 muito grande (2 ^ n).
Para calcular a bola, usaremos um algoritmo de pesquisa de profundidade ligeiramente modificado.
O refinamento será o seguinte:
- Não precisamos encontrar um vértice específico, mas ordenar todos os vértices até uma profundidade de n, para nossa tarefa n = 2.
- Não devemos armazenar informações desnecessárias e devemos assumir que o cálculo pode ser feito para qualquer nó no gráfico, para que o nível do nó não seja armazenado no gráfico.
- Se 2 ou mais caminhos levam ao topo, todos os caminhos são avaliados, porque estamos lidando com comunicações bidirecionais e é necessário avaliar completamente a interação dos nós.
- Você precisa determinar o nível de aninhamento de qualquer vértice para um cálculo específico.
Bem, bem, os cálculos teóricos básicos foram feitos, mesmo que pareçam a alguém algo simples e banal. Mas para nós gascões, tudo isso é importante e interessante, quase o mesmo que entrar nos mosqueteiros reais.
Passamos à implementação prática. Um por todos e todos por um!
Eu te encontro! Definitivamente vamos nos encontrar! Talvez daqui a 10 ou 20 anos! Mas conheça!
O próximo artigo está encerrado!