
Em um
artigo anterior
, contei uma breve história do desenvolvimento de produtos internos e externos do DublGIS. Hoje, mergulhamos nos detalhes do desenvolvimento de um dos produtos, a saber, a exportação de dados. Vou falar sobre a arquitetura do projeto e as soluções técnicas individuais que nos permitiram desenvolver gradualmente o projeto e adaptá-lo às mudanças nos requisitos ao longo do tempo.
Um breve resumo do último artigo
Existem vários produtos internos que coletam grandes quantidades de dados do mapa, um diretório de organizações, publicidade, feedback do usuário, revisões, fotos e várias análises. Esses produtos se comunicam através do barramento de dados ou da Rest Api. E existe um processo de exportação separado que coleta todos esses dados em uma pilha, processa e decompõe no formato desejado, empacota e forma um "pacote" pronto para entrega aos seus produtos finais. A entrega ocorre através do servidor de atualização para versões para PC e móvel ou no back-end on-line da versão on-line do 2GIS.
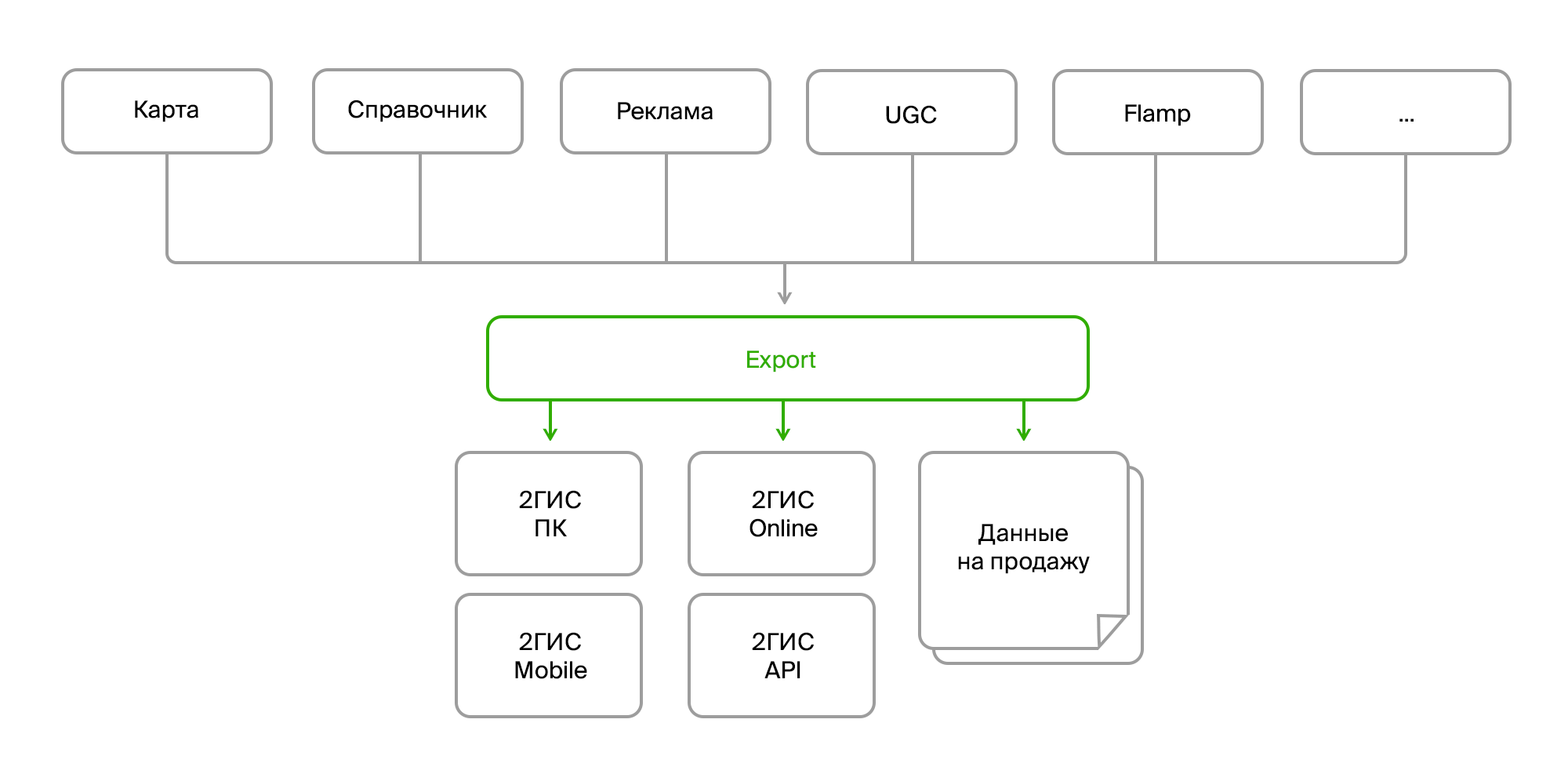
Dados de origem
Então, na entrada temos:
- várias fontes dos mesmos dados;
- diferentes métodos de entrega (Firebird, bus, FTP, RestAPI);
- estrutura diferente dos mesmos objetos;
- mudanças constantes na estrutura de dados;
- diferentes formatos (dados brutos no banco de dados, XML, JSON).
Do ponto de vista do consumidor:
- novamente, formatos diferentes (seus formatos de dados para diferentes versões do produto, formatos separados para venda);
- mudanças constantes de formato;
- dados agregados (você precisa combinar diferentes objetos em um, coletar dados sobre a empresa de todas as filiais, complementá-los com links para fotos, críticas, paradas mais próximas, etc.);
- pré-processamento e pós-processamento complexos (atualização de alguns dados com base em outros, conversão de dados, geração de dados ausentes, por exemplo, organização de mini-logotipos publicitários em edifícios, exclusão ou correção de dados incorretos);
- requisitos de consistência e validade dos dados;
- TODOS os dados são necessários.
Aqui vale a pena focar no último parágrafo. Como você sabe, a principal característica do 2GIS é o trabalho offline. Ou seja, a maioria dos dados que você vê nas versões para PC e celular está no seu dispositivo. Mas essa é uma variedade enorme: centenas de milhares de objetos geográficos (mares, florestas, rios, estradas, prédios, entradas, varandas, assinaturas, plantas, modelos 3D), dezenas e centenas de milhares de empresas e suas filiais com contatos, horário de trabalho, atributos adicionais como a conta média e a disponibilidade de Wi-Fi. E, é claro, textos e fotos publicitários.
E tudo está mudando constantemente, adicionado, excluído.
E para não nos afogarmos nesse fluxo interminável de mudanças, ao desenvolver a arquitetura de exportação, tivemos que nos concentrar em várias áreas principais:
- fontes de dados;
- métodos de entrega;
- algoritmos de processamento;
- formatos de dados do consumidor.
Nós abstraímos de diferentes fontes e formatos de dados
Diferentes fontes apresentam as seguintes dificuldades:
- eles fornecem os mesmos dados em diferentes formatos;
- ter um conjunto diferente de entidades ou atributos que precisam ser reduzidos a um único objeto de domínio.
Este é um problema bastante padrão e é resolvido como padrão. Só precisamos criar uma interface para o recebimento de dados, e uma implementação específica já está indo para onde é necessária e os dados serão obtidos da forma que precisamos.

Exemplo de interface:
public interface ISource : IDisposable { ISourceReader GetDeletedRows(); ISourceReader GetInsertedOrUpdatedRows(); byte[] GetDataVersion(); } public interface ISourceReader : IDisposable { bool Read(); object this[string columnName] { get; } }
Um exemplo da implementação da obtenção de empresas:
internal class FirmSetSource : ISource { public ISourceReader GetDeletedRows() { if(_lastDataVersion == null) return null; var query = DataContext.ExecuteObject<EsbFirmDeleted>(_lastDataVersion); return new DeletedIdsSourceReader<long>( query.Select(x => x.Id).GetEnumerator()); } public ISourceReader GetInsertedOrUpdatedRows() { return new EnumeratorSourceReader(typeof(FirmSet), GetNewOrChangedRows().GetEnumerator()); } public virtual byte[] GetDataVersion() { return DataContext.ExecuteObject<EsbFirm>().Max(x => x.RowVersion); } }
Essa abstração permite parcialmente resolver o problema com diferenças no modelo de domínio, mas não completamente. Uma limitação significativa é a necessidade de receber dados de forma incremental, ou seja, receber apenas suas atualizações e não sugar a coisa toda sempre. Nesse caso, é bastante inconveniente rastrear o relacionamento entre os dados para coletar alguns agregados. E é relativamente difícil fazer tudo sem erros. Portanto, decidimos que, nesta etapa, extrairemos dados das fontes um a um e resolveremos o problema com o modelo de domínio em um nível diferente.
Modelo de domínio
Para não depender de alterações no conjunto de dados e de sua estrutura nas fontes de dados, o banco de dados de exportação foi criado com uma lista relativamente estável de tabelas, que finalmente caiu em nosso domínio. Se a origem 1 não tiver atributos para a entidade A (objeto de dados na próxima figura), eles receberão um valor padrão ou serão opcionais. E se a entidade B fosse algum tipo de agregado de dados de origem ou mesmo fontes diferentes, cada parte poderia ser obtida separadamente e montada como um todo no próximo estágio.

Nós abstraímos do método de entrega de dados
De fato, ter seu próprio banco de dados na exportação e a aparência da interface
ISourceReader já resolvem esse problema. Mas há um ponto não resolvido: modelos de aquisição de dados ligeiramente diferentes. Em um caso, obtemos e capturamos um instantâneo no momento atual, no outro - deltas de alterações no barramento, no terceiro - também o status atual no momento da solicitação, mas com informações sobre objetos excluídos do momento da solicitação anterior.
Para trazer uniformidade a esse zoológico, adicionaremos mais um banco de dados ao qual mesclaremos todos os dados de todas as fontes.
Você fica com essa foto.
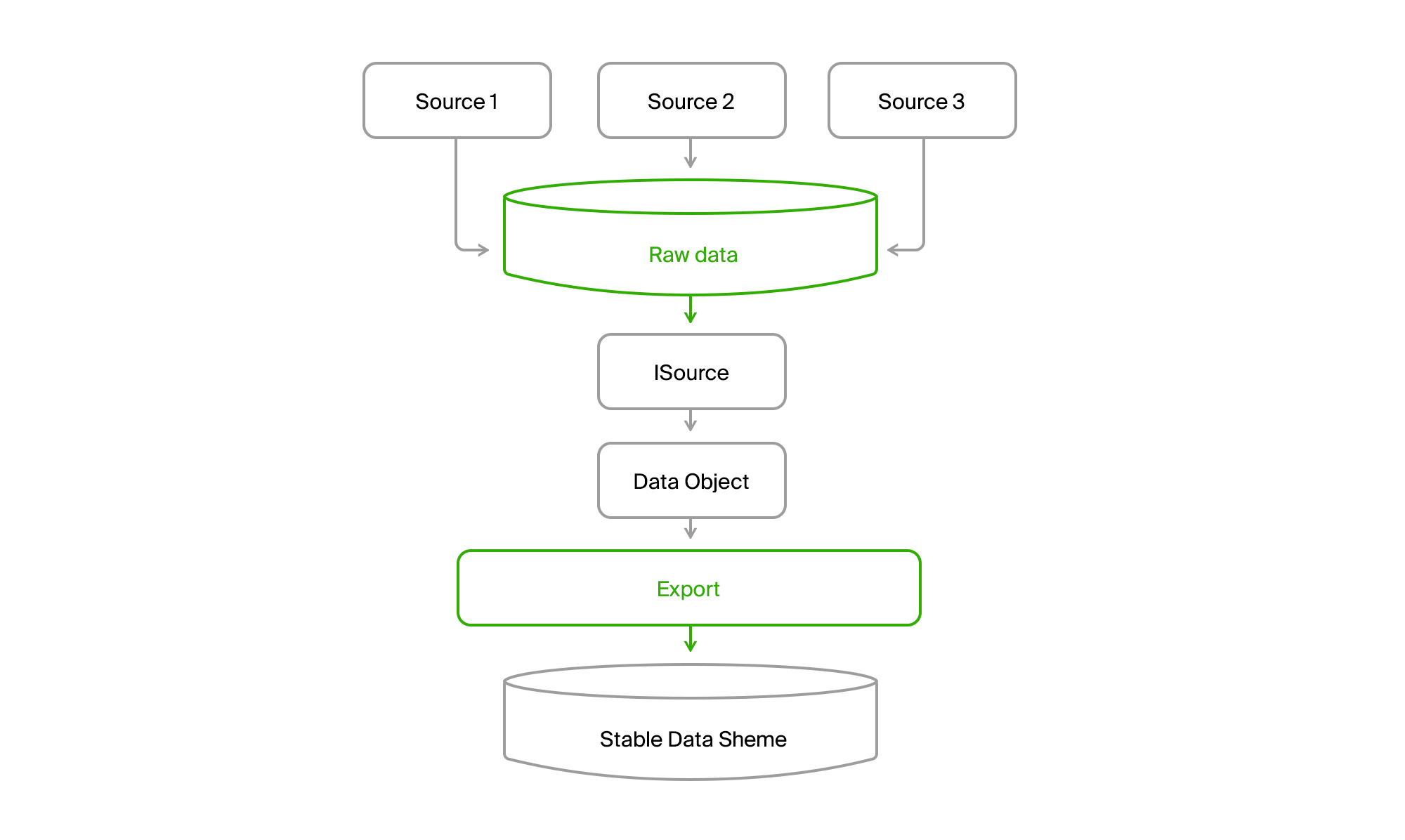
Como resultado, lemos todos os dados de qualquer canal em todas as cidades para o banco de dados central. Quase sempre a entrega é incremental, ou seja, somente as mudanças ocorrem. O antigo DGPP, enquanto vivo, permaneceu uma fonte alternativa. Foi capaz de bombear dados de um DBMS para outro não era nenhum.
Além disso, a exportação através do ISource extraiu dados da cidade do DGPP ou EMDB para seu banco de dados de sincronização estável e os converteu em seu modelo de domínio.
Resta apenas processá-los e enviá-los em formatos de consumidor.
Abstraindo de algoritmos de preparação de dados
E aqui surge mais uma dificuldade. Em primeiro lugar, diferentes consumidores desejam dados em seus formatos. Além disso, eles querem conjuntos de dados diferentes. E no anexo, os dados offline devem ser o mais compactos e estruturados possível, para que possam ser lidos rapidamente. Como resultado, obtemos formatos binários desenvolvidos pelas equipes de produtos finais. E esses são os caras que trabalham em uma pilha de tecnologia completamente diferente. Temos o familiar e amado por desenvolver o back-end do .NET e, às vezes, Java, eles têm principalmente C ++ e python.
Em geral, um zoológico de tecnologia.
No início do rápido desenvolvimento, quando tínhamos apenas o DGPP (consulte o
artigo anterior) e a versão para PC do 2GIS, o formato dos dados finais era um binário, preparado por uma biblioteca especial escrita em C ++ e envolvida em um objeto COM. Parece que a integração de código heterogêneo não é. Nós conectamos a referência, a interface .NET é gerada - e a impulsionamos. E a primeira vez que fizemos.
Mas, como sempre, surgiram alguns problemas.
- Nossos dados começaram a crescer rapidamente. Novos tipos de dados apareceram, novas grandes cidades como Moscou.
- OSs de 64 bits começaram a se espalhar ativamente.
- Problemas no COM precisavam ser depurados de alguma forma.
Vamos analisar os pontos.
O crescimento de dados que são completamente necessários para nossos produtos levou ao fato de que o processamento deles começou a consumir uma grande quantidade de RAM. E, ao conectar a biblioteca COM ao nosso processo .NET x86, recebemos automaticamente o processo x86, ou seja, um máximo de operadores 3Gb com maior espaço de endereço. As equipes não tinham suporte de biblioteca para recursos x64, mas a própria biblioteca tinha a capacidade de usar o disco em vez da memória, o que mitigou um pouco o problema.
Mas a depuração ainda era muito difícil. Era necessário iniciar a exportação, aguardar a preparação dos dados, começar a adicionar esses dados à biblioteca. E após o erro aparecer, você precisa entender dos logs o que deu errado e repetir o processo novamente. Não é bom, muito ruim.
A solução é como de costume na superfície. É suficiente levar todo o código externo para um processo separado e estabelecer comunicação através de arquivos intermediários em um formato binário ou de texto simples.
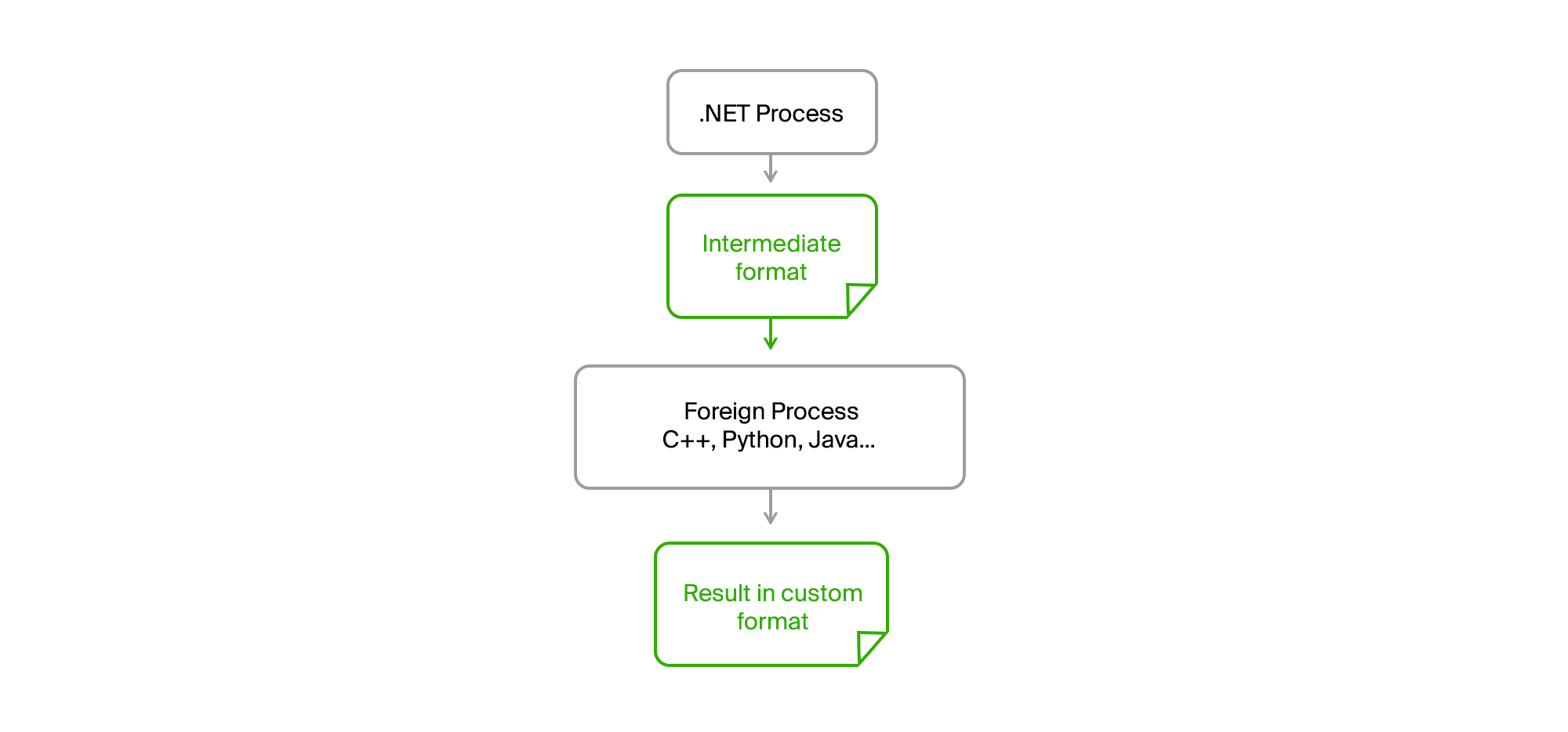
Como resultado, nosso processo .NET original tornou-se completamente qualquer CPU. Nenhum vazamento de memória ou erros críticos no código de terceiros não o afetam mais. A exportação preparou os dados, carregou-os em um arquivo intermediário, alimentou-os no utilitário e recebeu o resultado deles também na forma de um arquivo. Os caras de equipes de terceiros escreveram seus algoritmos em suas próprias linguagens (C ++ ou Python) e poderiam depurá-los em dados reais em caso de erros em sua máquina sem a necessidade de começar a exportar.
Nós apenas tivemos que formar acordos na interface do utilitário, que foram fornecidos com o tempo de execução, possuímos uma lista acordada de parâmetros necessários e exibimos mensagens e erros informativos em stdout no formato necessário.
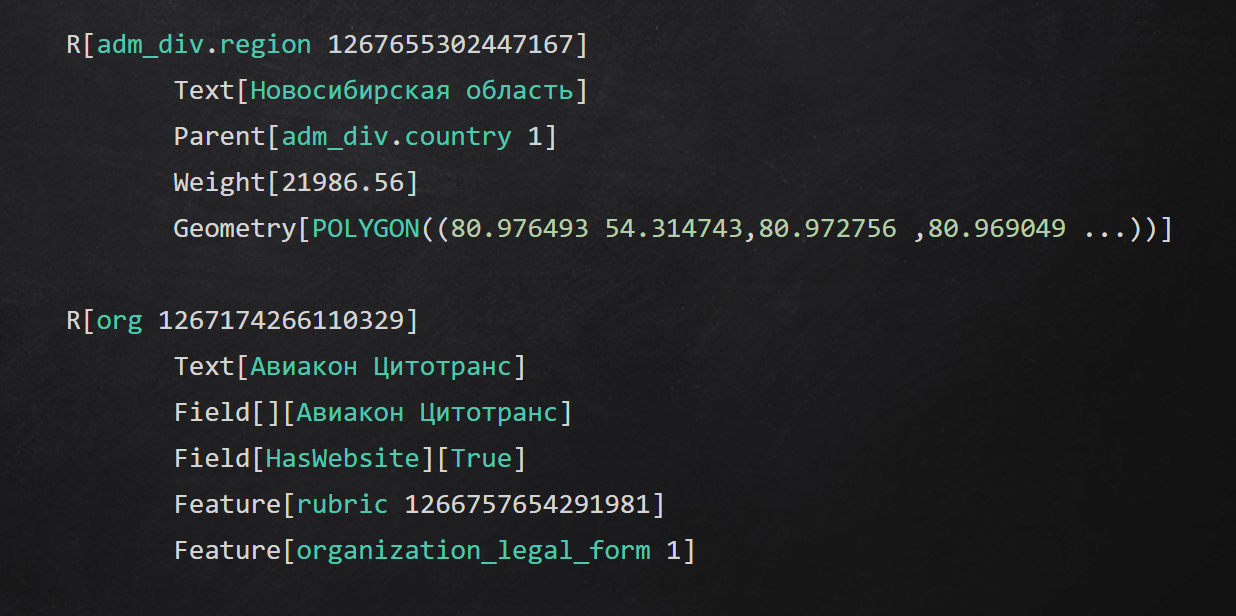 Exemplo de formato de texto intermediário
Exemplo de formato de texto intermediárioSumário
No artigo, falei sobre algumas abordagens que usamos em diferentes níveis do aplicativo para isolar o processo de preparação de dados:
- ocultou detalhes de acesso a fontes de dados atrás de interfaces;
- abstraídos dos canais de entrega de dados usando armazenamento intermediário;
- faça seu domínio estável e converta os dados originais nele;
- realizou etapas individuais de processamento de dados em processos e usou código em outros idiomas.
Obrigado por chegar ao fim. Vou responder a todas as perguntas nos comentários, não se esqueça de perguntar.