Este artigo descreve o processo de analisar a sentença do idioma russo usando gramática livre de contexto e o algoritmo de análise LR.
O processamento de linguagem natural é a direção geral da inteligência artificial e da linguística matemática. Estuda os problemas da análise computacional e síntese de linguagens naturais.
Em geral, o processo de análise de sentenças em linguagem natural é o seguinte: (1) divisão de sentenças em unidades sintáticas - palavras e frases; (2) determinação dos parâmetros gramaticais de cada unidade; (3) a definição da relação sintática entre unidades. A saída é uma árvore de análise abstrata.
1. Dividindo frases em unidades sintáticas
Uma sentença de linguagem natural consiste em formas de palavras e frases fortes. Um número de formas de palavras de uma determinada palavra é chamado de paradigma.
Por exemplo
"": [, , , , , ]
As frases - conjunções compostas, predicados ou expressões estáveis - não mudam e não podem ser decompostas em unidades menores sem perda de significado. Além disso, com uma palavra queremos dizer qualquer unidade sintática - uma forma de palavra ou frase.
Cada palavra em uma frase é determinada por um triplo:
- forma / sequência de palavras ("escrita")
- forma normal da palavra ("gravação")
- um conjunto de parâmetros gramaticais (['VERBO', 'cantar', 'musc', 'tran', 'passado'])
Assim, o detalhamento da frase "
Claramente, ele não comparecerá à reunião " terá a seguinte forma:
[' ', '', '', '', '', ''] ' ' - ,
2. Definição de parâmetros gramaticais (grammems)
Um grama é um elemento de uma categoria gramatical; gramáticas diferentes da mesma categoria são mutuamente exclusivas e não podem ser expressas juntas. Para cada forma de palavra, definimos um conjunto de sete gramas:
[ , , , , , , ]
Como fonte, usaremos o dicionário
OpenCorpora e sua interface,
pymorphy2 . Para procurar uma regra na gramática para um determinado conjunto de gramas, vamos apresentá-las na forma geral:
'' [NOUN,plur,neut,accs] -> [NOUN,?numb,?per,?gend,accs,None,None] '?' ,
3. Definição da relação sintática entre palavras
Para determinar a relação sintática entre as palavras, usaremos gramática livre de contexto e análise LR.
Análise de gramática e LR
A gramática formal é uma maneira de descrever uma linguagem na forma das chamadas produções. Por exemplo:
a -> ab | ac
significa a regra 'a' gera 'ab' OU 'ac'.
Os não-terminais são objetos que denotam qualquer essência da linguagem (sentença, fórmula, etc.).
Terminais - objetos diretamente presentes no idioma correspondente à gramática e com significado específico e imutável (letras, palavras, fórmulas etc.). Gramáticas livres de contexto são gramáticas em que os lados esquerdo de todos os produtos são não terminais únicos.
Para descrever o idioma russo, usaremos a teoria da gramática dos componentes (
gramática da estrutura das frases ), que afirma que qualquer unidade gramatical complexa consiste em duas unidades mais simples e não interceptadas, chamadas componentes imediatos. Os seguintes componentes são distinguidos:
(1) Grupo nominal (NP) NP[case='nomn'] -> N[case='nomn'] | ADJ[case='nomn'] NP[case='nomn'] | …
Ou seja, uma frase nominal nominativa é um substantivo no caso nominativo OU um adjetivo no caso nominativo + uma frase nominal nominativa OU outro.
(2) Grupo verbal (VP) VP[tran] -> V[tran] NP[case='ablt'] | ADJ VP[tran] | …
Em outras palavras, um grupo de verbos transitivos é um verbo transitivo + um grupo substantivo ablativo OU um adjetivo curto + grupo de verbos transitivos OU outro.
(3) Grupo Preposicional (PP) PP -> PREP NP[case='datv'] | ...
Um grupo preposicional é uma preposição + um grupo dativo nominal OU outro.
(4) Oferta completa (S) S -> NP[case='nomn'] VP[tran]
Uma frase completa existe se, e somente se, os grupos de substantivos e verbos corresponderem em número, pessoa e gênero.
def agreement(self, node_left, node_right): ... if (numb1 and numb2): if (numb1 != numb2): return False; if (per1 and per2): if (per1 != per2): return False; if (gend1 and gend2): if (gend1 != gend2): return False; return True;
Uma frase incompleta é uma frase em que a parte nominal é omitida. Como regra, nessas frases o grupo de verbos é expresso por um verbo impessoal. Por exemplo, "
eu quero andar ", "está
ficando claro ". Uma sentença elíptica é uma sentença em que a parte do verbo é omitida e substituída por um traço. Por exemplo, "
Atrás das costas há uma floresta. À direita e à esquerda existem pântanos ".
Para determinar se esta frase pertence à linguagem gramatical, usaremos o algoritmo de análise LR. Esse algoritmo envolve a construção de uma árvore de análise de baixo para cima (das folhas para a raiz). O elemento chave do algoritmo é o método de "transferência-convolução" (inglês
shift-reduzem ):
(1) lemos os caracteres da linha de entrada até que exista uma cadeia que corresponda ao lado direito de algumas regras, coloque a cadeia encontrada na pilha (transferência);
(2) substitua a cadeia encontrada pela regra pela gramática (convolução).
Se todas as cadeias de cadeia foram quebradas, essa frase pertence ao idioma gramatical e existe pelo menos uma árvore de análise.
ÁrvorePara representar a conexão sintática, a sentença usa uma árvore binária, onde as folhas são palavras (terminais) com um conjunto de gramas e os nós são regras (pré-terminais). A raiz é a sentença (não terminal).
Um nó da árvore é definido da seguinte maneira:
class Node: def __init__(self, word=None, tag=None, grammemes=None, leaf=False): self.word = word;
A construção de uma árvore começa com folhas, às quais é atribuída uma sequência de palavras ou frases, bem como um conjunto de suas gramáticas.
def build(self, sent): for word in sent: new_node = Node(word[0], word[1], word[2], leaf=True) self.nodes.append(new_node)
Em seguida, a análise LR é realizada. Cada convolução corresponde à união de dois nós ou folhas sob um ancestral comum. Um nó ancestral recebe uma tag pré-terminal que corresponde à regra gramatical; além disso, o ancestral recebe gramáticas do membro principal do grupo, por exemplo, no grupo de verbos V [tran] PRCL (por exemplo,
“gostaria de” ), os sinais serão retirados do verbo transitivo V [tran] e não de uma partícula de PRCL; e no grupo substantivo NP [case = 'nomn'] NP [case = 'gent'] (por exemplo,
“pai de filhos” ) os sinais serão retirados do substantivo no nominativo.
É importante notar que a convolução ocorre na ordem estabelecida:
def reduce(self): self.reduce_ADJ() # self.reduce_NP() # self.reduce_PP() # self.reduce_VP() # self.reduce_S() #
Essa ordem é importante porque exclui a possibilidade de "perder" alguns membros da proposta. Primeiro, os adjetivos são formados juntamente com modificadores (por exemplo,
insanamente bonitos ), depois grupos nominais, preposicionais e finalmente verbais. Depois disso, há uma busca por sentenças completas / incompletas, se não houver, a árvore não possui uma raiz e, portanto, a sentença não pertence ao idioma gramatical.
Considere um exemplo condicional de construção de uma árvore:
sent = " " def build(self, sent): for word in sent: new_node = Node(word[0], word[1], word[2], leaf=True) self.nodes.append(new_node)

NP[case='nomn'] -> NPRO[case='nomn'] NP[case='accs'] -> N[case='accs'] NP[case='datv'] -> ADJ[case='datv'] NP[case='datv']

VP[tran] -> V[tran] NP[case='accs']

VP[tran] -> VP[tran] NP[case='datv']

S -> NP[case='nomn'] VP[tran]
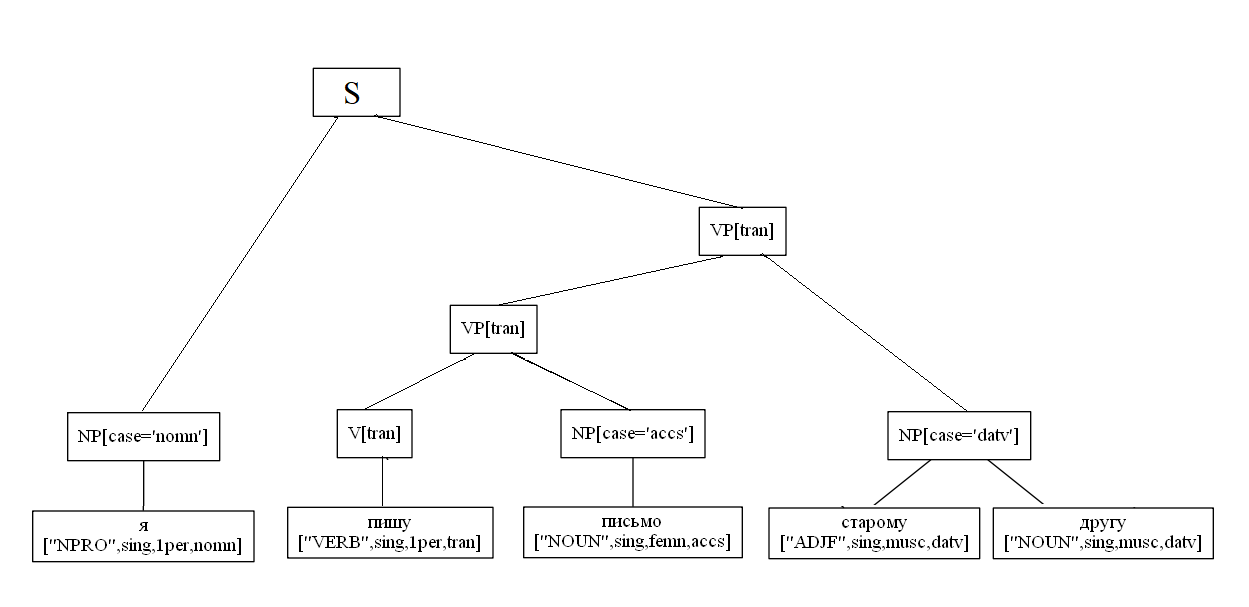
Um exemplo específico de análise de uma frase em duas partes:
import analyzer parser = analyzer.Parser() sent = " , ." t = parser.parse(sent) t[0].display() S NP[case='nomn'] ['NOUN', 'sing', 'femn', 'nomn'] VP[tran] VP[tran] ['VERB', 'sing', '3per', 'tran', 'pres'] NP[case='datv'] ['NOUN', 'sing', 'datv'] S NP[case='nomn'] ['NOUN', 'sing', 'femn', 'nomn'] VP[tran] PP PREP ['PREP'] NP[case='ablt'] ['NOUN', 'sing', 'femn', 'ablt'] VP[tran] ['VERB', 'sing', '3per', 'tran', 'pres']
Os problemas
A linguagem natural é ambígua, seu entendimento depende de vários fatores - das características da estrutura gramatical da língua, da cultura nacional, do interlocutor etc. Listamos os principais problemas do processamento de linguagem de máquina.
- Divulgação de anáfora. Uma pessoa viva entende a anáfora com base no senso comum e no contexto, mas para um computador isso obviamente nem sempre é fácil.
- A homonímia é uma coincidência no som e na ortografia de unidades linguísticas cujos significados não estão relacionados entre si. Uma solução são métodos probabilísticos. Na sentença " conheço bem isso " , a probabilidade de que " isto " seja um pronome e não uma partícula será maior. Tais métodos requerem um gabinete suficientemente grande.
- A ordem livre das palavras leva ao fato de que a interpretação da sentença pode ser ambígua. Por exemplo, "O ser determina a consciência " - o que determina o que? Em russo, a ordem das palavras livres é compensada pela morfologia desenvolvida, palavras de serviço e sinais de pontuação, mas na maioria dos casos, para o computador, isso apresenta um problema adicional.
- Nem todas as pessoas escrevem corretamente. Na rede, as pessoas tendem a usar abreviações, neologismos, elipses e outras coisas que podem contradizer a norma literária. Por isso, o uso de gramáticas e dicionários sem contexto nem sempre é possível.
Conclusão
O projeto
está disponível para uso e edição. Ele contém o analisador em si, a árvore de análise, bem como a gramática e gramática russa do idioma russo e um pequeno dicionário de uniões compostas e predicados que não estão no dicionário OpenCorpora. No momento, para sentenças longas e complexas, o analisador pode encontrar três ou mais árvores. Para resolver esse problema, são feitas alterações na gramática e também é planejado o uso de métodos probabilísticos.