Olá pessoal! Estamos publicando uma tradução do artigo preparado para os alunos do novo grupo do curso Data Engineer . Se você estiver interessado em aprender a construir um sistema de processamento de dados eficiente e escalável a um custo mínimo, consulte a gravação da master class de Yegor Mateshuk!

Algumas semanas atrás, escrevi um artigo sobre o Hadoop, que abordava vários
partes e descobriu qual o papel que ele desempenha no campo da engenharia de dados. Neste artigo, eu
Vou dar uma breve descrição dos vários formatos de arquivo no Hadoop. É rápido e fácil
tópico. Se você está tentando entender como o Hadoop funciona e que lugar ele ocupa no trabalho
Engenheiro de dados, confira meu artigo no Hadoop aqui .
Os formatos de arquivo Hadoop são divididos em duas categorias: orientado a linhas e orientado a colunas
orientado.
Orientado a linhas:
Linhas de dados de um tipo são armazenadas juntas, formando um contínuo
armazenamento: SequenceFile, MapFile, Avro Datafile. Assim, se necessário
acessar apenas uma pequena quantidade de dados de uma linha, de qualquer maneira a linha inteira
será lido na memória. Atrasos de serialização podem, até certo ponto
aliviar o problema, mas completamente da sobrecarga de ler toda a linha de dados com
unidade não será capaz de se livrar. Armazenamento orientado a linhas
adequado nos casos em que é necessário processar toda a linha ao mesmo tempo
dados.
Orientado a colunas:
O arquivo inteiro é dividido em várias colunas de dados e todas as colunas de dados
armazenados juntos: Parquet, RCFile, ORCFile. Formato orientado a colunas (coluna
orientado), permite que você pule colunas desnecessárias ao ler dados, o que é adequado para
situações em que é necessária uma pequena quantidade de linhas. Mas esse formato de leitura e escrita
requer mais espaço de memória, pois toda a linha de cache deve estar na memória
(para obter uma coluna de várias linhas). Ao mesmo tempo, não é adequado para
streaming, porque após uma falha na gravação, o arquivo atual não pode ser
restaurados e dados de orientação linear podem ser reutilizados
sincronizados a partir do último ponto de sincronização no caso de um erro de gravação, portanto,
por exemplo, o Flume usa um formato de armazenamento orientado a linhas.

Figura 1 (esquerda). Tabela lógica mostrada
Figura 2 (direita). Local orientado a linhas (arquivo de sequência)

Figura 3. Layout orientado a colunas
Se você ainda não entendeu completamente o que é a orientação de coluna ou linha,
não se preocupe. Você pode seguir este link para entender a diferença entre os dois.
Aqui estão alguns formatos de arquivo amplamente usados no sistema Hadoop:
Arquivo de sequência
O formato do armazenamento muda dependendo se o armazenamento está compactado,
Ele usa compactação de gravação ou compactação de bloco:

Figura 4. A estrutura interna do arquivo de sequência sem compactação e com compactação de registros.
Sem compressão:
Armazenando na ordem correspondente ao comprimento do registro, Comprimento da chave, Valor do grau,
Valor da chave e valor do valor. Intervalo é o número de bytes. Serialização
realizada usando o especificado.
Compressão de registro:
Somente o valor é compactado e o codec compactado é armazenado no cabeçalho.
Compressão de bloco:
Vários registros são compactados para que você possa usar
aproveite as semelhanças entre as duas entradas e economize espaço. Bandeiras
as sincronizações são adicionadas ao início e ao fim do bloco. Valor mínimo do bloco
definido pelo atributo o.seqfile.compress.blocksizeset.

Figura 4. A estrutura interna do arquivo de sequência com compactação de bloco.
Arquivo de mapa
Um arquivo de mapa é um tipo de arquivo de sequência. Depois de adicionar o índice a
o arquivo de sequência e sua classificação resultam em um arquivo de mapa. O índice é armazenado como um separado
arquivo, que geralmente contém os índices de cada uma das 128 entradas. Os índices podem ser
carregado na memória para recuperação rápida, porque os arquivos nos quais os dados são armazenados,
organizados na ordem especificada pela chave.
As entradas do arquivo de mapa devem estar em ordem. Caso contrário, nós
obtenha uma IOException.
Tipos de arquivo de mapa derivados:
- SetFile: um arquivo de mapa especial para armazenar uma sequência de chaves do tipo
Gravável As chaves são escritas em uma ordem específica. - ArrayFile: a chave é um número inteiro indicando a posição na matriz, valor
digite gravável. - BloomMapFile: otimizado para o método get () de um arquivo de mapa usando
filtros dinâmicos Bloom. O filtro é armazenado na memória e o método usual
get () é chamado para ler somente se o valor da chave
existe.
Os arquivos listados abaixo no sistema Hadoop incluem RCFile, ORCFile e Parquet.
A versão orientada a colunas do Avro é Trevni.
Arquivo RC
Arquivo Colunista de Registros do Hive - esse tipo de arquivo primeiro divide os dados em grupos de linhas,
e dentro de um grupo de linhas, os dados são armazenados em colunas. Sua estrutura é a seguinte
caminho:

Figura 5. Localização dos dados do arquivo RC em um bloco HDFS.
Compare com o puro orientado a linhas e a coluna:
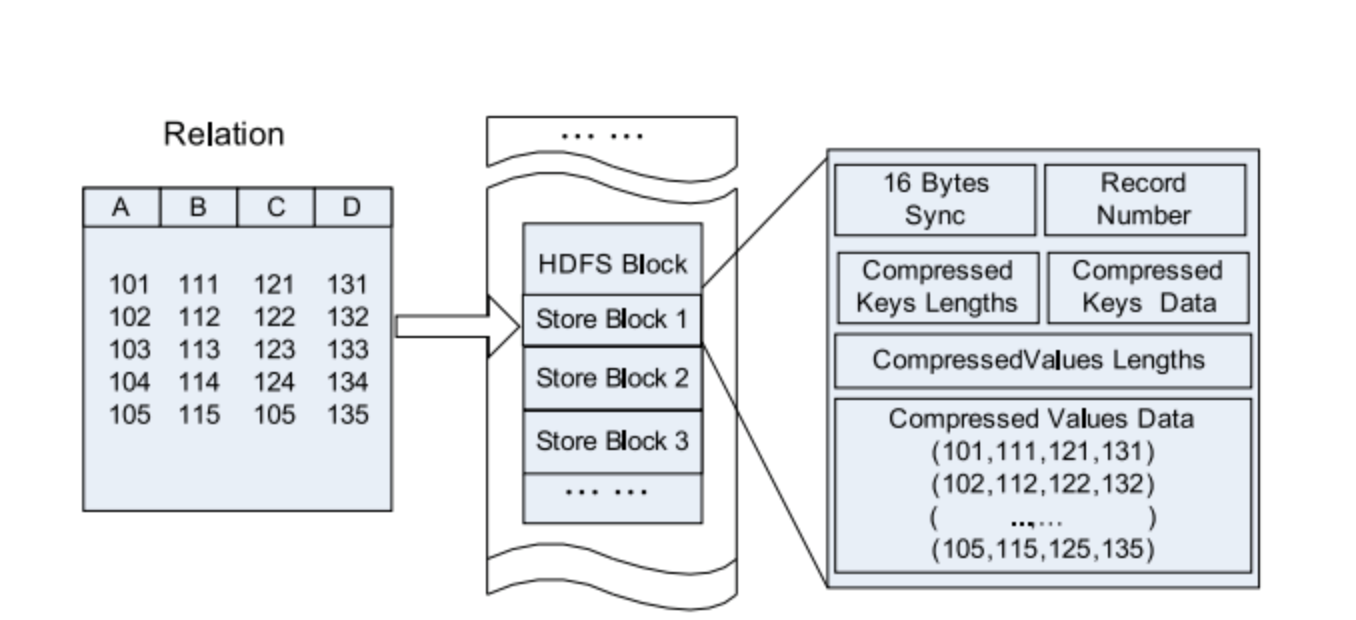
Figura 6. Armazenamento linha por linha no bloco HDFS.

Figura 7. Agrupando por colunas em um bloco HDFS.
Arquivo ORC
ORCFile (arquivo de colunas de registro otimizado) - é um formato mais eficiente
arquivo que rcfile. Divide internamente os dados em tiras de 250M cada.
Cada faixa possui um índice, dados e rodapé. O índice armazena o mínimo e
o valor máximo de cada coluna, bem como a posição de cada linha na coluna.

Figura 8. Localização dos dados no arquivo ORC
O Hive usa os seguintes comandos para usar o arquivo .orc:
Parquet
Formato de armazenamento orientado a coluna genérico com base no Google Dremel.
Especialmente bom para o processamento de dados com um alto grau de aninhamento.
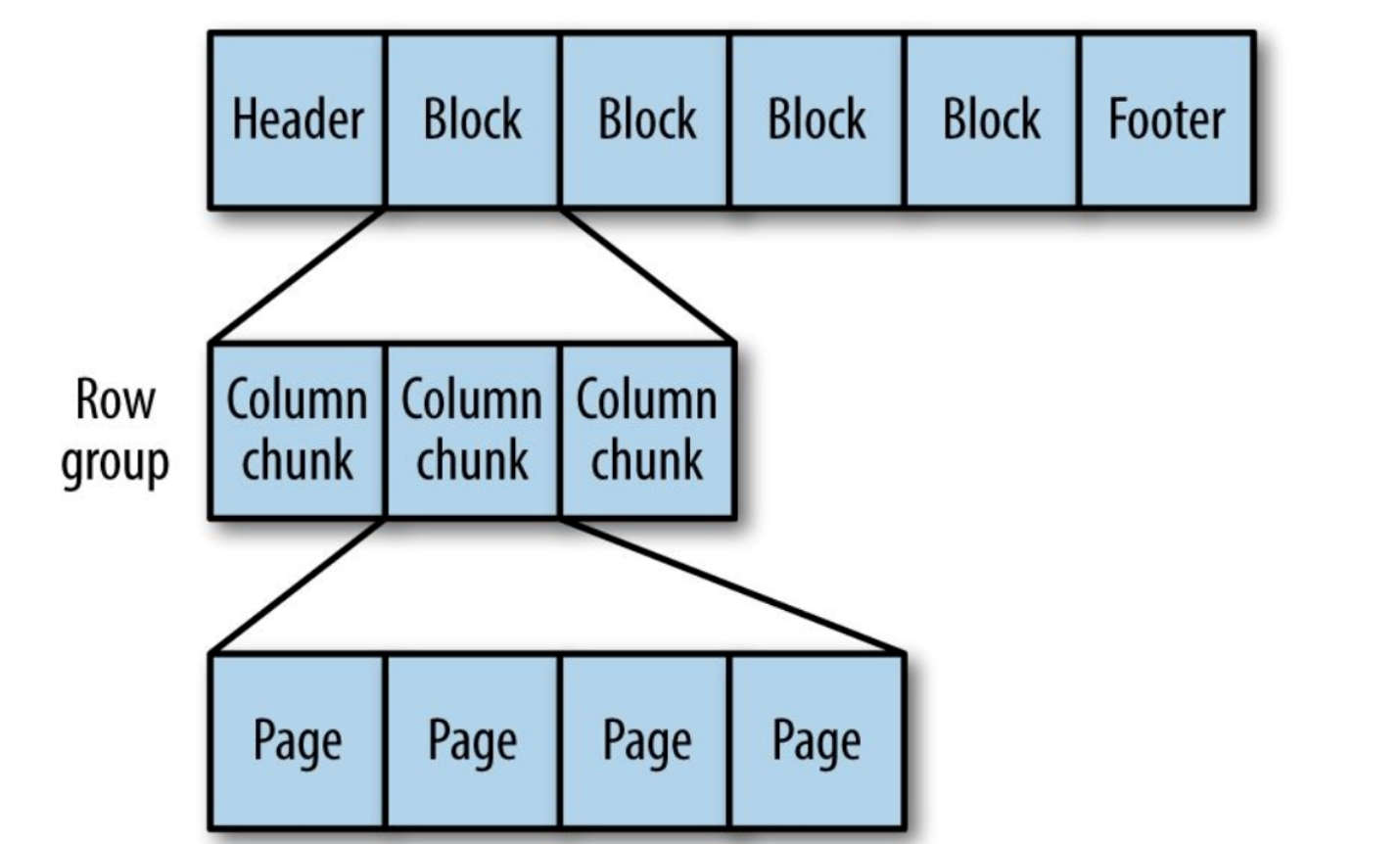
Figura 9. A estrutura interna do arquivo Parquet.
O Parquet transforma estruturas aninhadas em armazenamento de coluna plana,
representado pelo nível de repetição e pelo nível de definição (R e D) e usa
metadados para restaurar registros enquanto lê dados para recuperar todos
arquivo A seguir, você verá um exemplo de R e D:
AddressBook { contacts: { phoneNumber: “555 987 6543” } contacts: { } } AddressBook { }

Isso é tudo. Agora você conhece as diferenças nos formatos de arquivo no Hadoop. Se
encontrar erros ou imprecisões, não hesite em entrar em contato
para mim Você pode entrar em contato comigo no LinkedIn .