Nota perev. : Esse material continua uma maravilhosa série de artigos do evangelista de tecnologia da AWS Adrian Hornsby, que se propôs a explicar de maneira simples e clara a importância de experimentos projetados para mitigar as consequências de falhas nos sistemas de TI.
"Se você não conseguiu preparar o plano, planeja falhar." - Benjamin Franklin
Na
primeira parte desta série de artigos, apresentei o conceito de engenharia do caos e expliquei como ele ajuda a encontrar e corrigir falhas no sistema antes que causem falhas na produção. Também falou sobre como a engenharia do caos contribui para mudanças culturais positivas nas organizações.
No final da primeira parte, prometi falar sobre "ferramentas e métodos para introduzir falhas nos sistemas". Infelizmente, minha cabeça tinha planos próprios a esse respeito, e neste artigo tentarei responder à pergunta mais popular que surgir das pessoas que desejam se engajar na engenharia do caos:
O que quebrar primeiro? Ótima pergunta! No entanto, ele não parece se preocupar com esse panda ...
 Não mexa com o caos panda!Resposta curta
Não mexa com o caos panda!Resposta curta : Procure serviços críticos no caminho da solicitação.
Uma resposta longa, porém mais inteligível : Para entender por onde começar os experimentos com o caos, preste atenção em três áreas:
- Veja o histórico de falhas e identifique padrões;
- Decidir sobre dependências críticas ;
- Use o chamado. efeito de excesso de confiança .
É engraçado, mas essa parte com o mesmo sucesso poderia ser chamada de
"Jornada ao autoconhecimento e à iluminação" . Nele, começaremos a "brincar" com algumas ferramentas interessantes.
1. A resposta está no passado
Se você se lembra, na primeira parte, apresentei o conceito de correção de erros (COE) - o método pelo qual analisamos nossas falhas: falhas em tecnologia, processo ou organização - para entender suas causas e evitar repetições futuras . Em geral, isso deve começar.
"Para entender o presente, você precisa conhecer o passado." - Karl Sagan
Veja o histórico de falhas, coloque tags no SOE ou postmortem'ah e classifique-as. Identifique padrões comuns que geralmente levam a problemas e, para cada SOE, faça a si mesmo a seguinte pergunta:
"Isso poderia ter sido previsto e, portanto, evitado pela introdução de um mau funcionamento?"Lembro-me de um fracasso no início da minha carreira. Poderia ter sido facilmente evitado se tivéssemos algumas experiências simples de caos:
Sob condições normais, as instâncias de back-end respondem às verificações de integridade do ELB (balanceador de carga ). O ELB usa essas verificações para redirecionar solicitações para instâncias íntegras. Quando uma determinada instância é "não íntegra", o ELB para de enviar solicitações para ela. Uma vez, após uma campanha de marketing bem-sucedida, o tráfego aumentou e os back-end começaram a responder às verificações de saúde mais lentamente que o normal. Deve-se dizer que essas verificações de integridade foram profundas , ou seja, o estado das dependências foi verificado.
No entanto, por um tempo, tudo estava em ordem.
Então, já em condições bastante estressantes, uma das instâncias começou a executar uma tarefa cron regular e não crítica da categoria ETL. A combinação de alto tráfego e cronjob aumentou a utilização da CPU em quase 100%. A sobrecarga do processador diminuiu ainda mais as respostas às verificações de integridade - tanto que o ELB decidiu que a instância estava com problemas. Como esperado, o balanceador parou de distribuir tráfego para ele, o que, por sua vez, levou a um aumento na carga nas instâncias restantes no grupo.
De repente, todas as outras instâncias também começaram a falhar na verificação de saúde.
O início de uma nova instância exigiu o download e a instalação de pacotes e demorou muito mais tempo que o ELB necessário para desconectá-los - um por um - no grupo de dimensionamento automático. É claro que logo todo o processo alcançou um ponto crítico e a aplicação caiu.
Então entendemos para sempre os seguintes pontos:
- Para instalar o software ao criar uma nova instância por um longo tempo, é melhor dar preferência à abordagem imutável e à Golden AMI .
- Em situações difíceis, as respostas às verificações de saúde e aos ELBs devem ter precedência - a última coisa que você deseja fazer é dificultar a vida das instâncias restantes.
- O armazenamento em cache local de verificações de integridade (mesmo por alguns segundos) ajuda muito.
- Em uma situação difícil, não execute tarefas cron e outros processos não críticos - economize recursos para as tarefas mais importantes.
- Ao dimensionar automaticamente, use instâncias menores. Um grupo de 10 cópias pequenas é melhor que 4 cópias grandes; se uma instância cair, no primeiro caso, 10% do tráfego será distribuído em 9 pontos, no segundo - 25% do tráfego em três pontos.
Então,
isso poderia ser previsto e, portanto, evitado com a introdução do problema?Sim , e de várias maneiras.
Primeiro, simulando alta utilização da CPU com ferramentas como
stress-ng ou
cpuburn :
❯ stress-ng --matrix 1 -t 60s
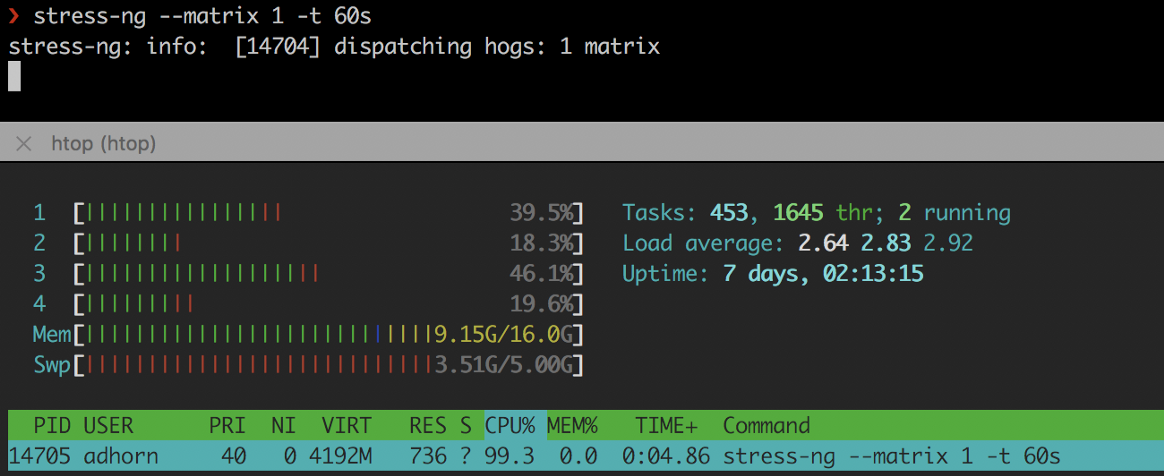 stress-ng
stress-ngEm segundo lugar, sobrecarregando a instância usando
wrk e outros utilitários semelhantes:
❯ wrk -t12 -c400 -d20s http://127.0.0.1/api/health
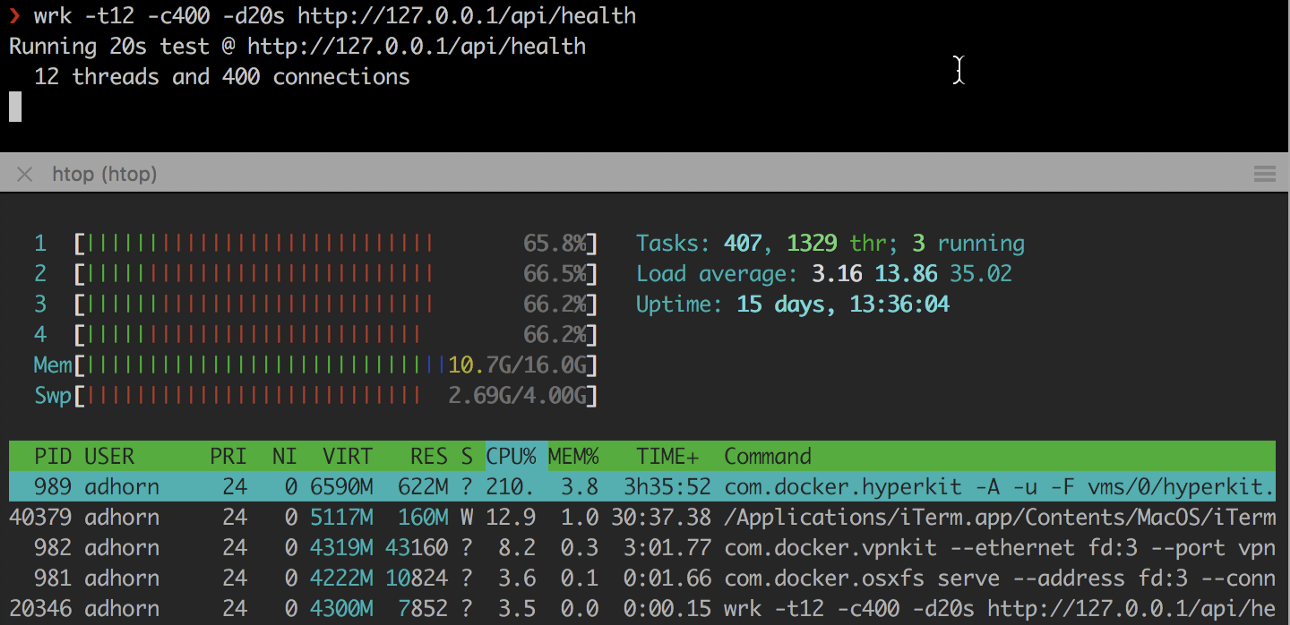
Os experimentos são relativamente simples, mas podem fornecer um bom alimento para o pensamento sem ter que experimentar o estresse de uma falha real.
No entanto,
não pare por aí . Tente reproduzir a falha em um ambiente de teste e verifique sua resposta à pergunta “
Isso poderia ter sido previsto e, portanto, evitado pela introdução de um mau funcionamento? " Este é um experimento de mini-caos dentro de um experimento de caos para testar suposições, mas começando com uma falha.
 Foi um sonho, ou realmente aconteceu?
Foi um sonho, ou realmente aconteceu?Portanto, estude o histórico de falhas, analise o
COE , identifique-os e classifique-os de acordo com o "raio do dano" - ou, mais precisamente, de acordo com o número de clientes afetados - e procure padrões. Pergunte a si mesmo se isso poderia ter sido previsto e evitado com a introdução do problema. Verifique sua resposta.
Em seguida, mude para os padrões mais comuns com o maior intervalo.
2. Construa um mapa de dependência
Reserve um momento para pensar em seu aplicativo. Existe um mapa claro de suas dependências? Você sabe qual o impacto que eles terão no caso de uma falha?
Se você não estiver familiarizado com o código do seu aplicativo ou ele se tornou muito grande, pode ser difícil entender o que o código faz e quais são suas dependências. Compreender essas dependências e seu possível impacto sobre o aplicativo e os usuários é fundamental para entender por onde começar a engenharia do caos: o componente com o maior raio de destruição será o ponto de partida.
Identificar e documentar dependências é chamado "
mapeamento de dependências ". Geralmente, ele é realizado para aplicativos com uma extensa base de códigos, utilizando ferramentas para criação de perfil de código
(criação de perfil de código) e instrumentação
(instrumentação) . Você também pode criar mapas monitorando o tráfego de rede.
No entanto, nem todas as dependências são iguais (o que complica ainda mais o processo). Alguns são
críticos , outros são
secundários (pelo menos teoricamente, porque as falhas geralmente resultam de problemas de dependência considerados não críticos) .
Sem dependências críticas, um serviço não pode funcionar. Dependências não críticas "
não devem " afetar o serviço em caso de queda. Para entender as dependências, você precisa ter um entendimento claro das APIs usadas pelo aplicativo. Pode ser muito mais complicado do que parece - pelo menos para aplicativos grandes.
Comece classificando todas as APIs. Destaque o mais
significativo e crítico . Pegue as
dependências do repositório de códigos, examine os
logs de conexão e veja a
documentação (é claro, se existir - caso contrário, você ainda terá mais problemas). Use as ferramentas para
criação de
perfil e rastreamento , filtre chamadas externas.
Você pode usar programas como o
netstat , um utilitário de linha de comando que exibe uma lista de todas as conexões de rede (soquetes ativos) no sistema. Por exemplo, para exibir todas as conexões atuais, digite:
❯ netstat -a | more

Na AWS, você pode usar a VPC de logs de fluxo - um método que permite coletar informações sobre o tráfego IP que vai para ou a partir das interfaces de rede nas VPCs. Esses logs podem ajudar com outras tarefas, por exemplo, encontrar uma resposta para a pergunta por que determinado tráfego não atinge a instância.
Você também pode usar o
AWS X-Ray . O X-Ray permite obter uma visão geral detalhada das solicitações à medida que elas avançam no aplicativo e também cria um mapa dos componentes básicos do aplicativo. É muito conveniente se você precisar identificar dependências.
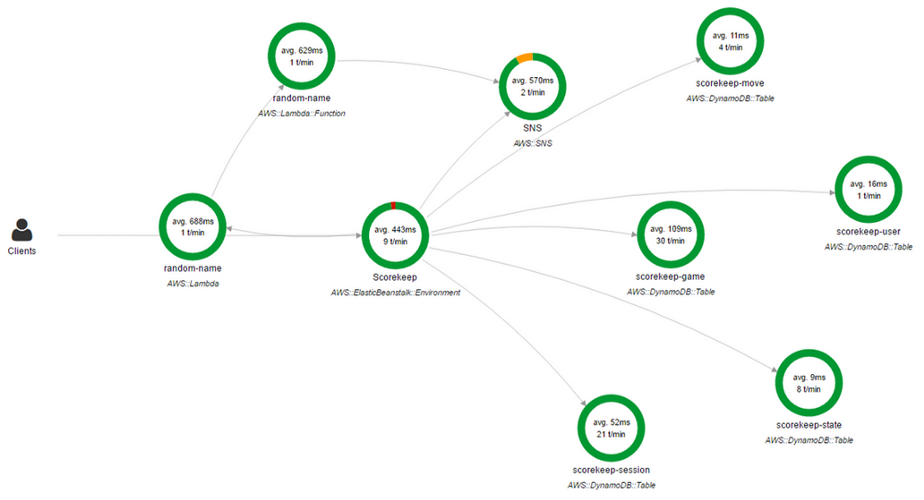 Console do AWS X-Ray
Console do AWS X-RayUm mapa de dependência de rede é apenas uma solução parcial. Sim, mostra qual aplicativo está associado a qual, mas existem outras dependências.
Muitos aplicativos usam o DNS para conectar-se a dependências, enquanto outros podem usar o mecanismo de descoberta de serviço ou mesmo endereços IP codificados em arquivos de configuração (por exemplo, em
/etc/hosts ).
Por exemplo, você pode criar um
DNS blackhole usando
iptables e ver o que quebra. Para fazer isso, digite o seguinte comando:
❯ iptables -I OUTPUT -p udp --dport 53 -j REJECT -m comment --comment "Reject DNS"
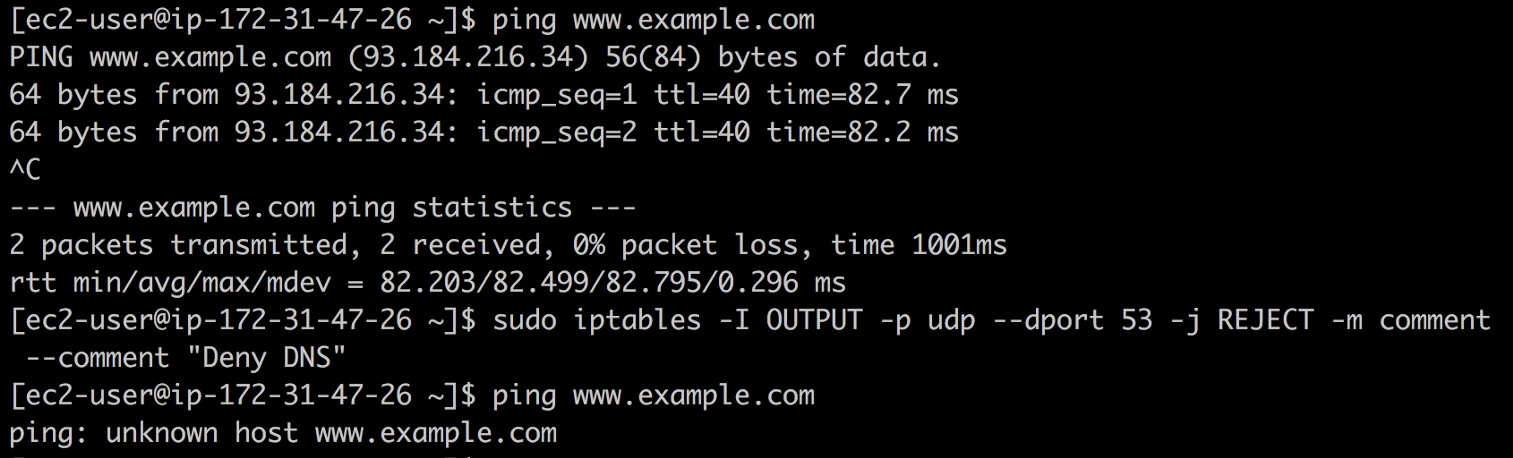 DNS do buraco negro
DNS do buraco negroSe você encontrar endereços IP em
/etc/hosts ou outros arquivos de configuração sobre os quais você não conhece nada (sim, infelizmente, isso acontece), o
iptables pode ser resgatado novamente. Digamos que você encontre
8.8.8.8 e não saiba que esse é o endereço do servidor DNS público do Google. Usando o
iptables você pode fechar o tráfego de entrada e saída neste endereço usando os seguintes comandos:
❯ iptables -A INPUT -s 8.8.8.8 -j DROP -m comment --comment "Reject from 8.8.8.8" ❯ iptables -A OUTPUT -d 8.8.8.8 -j DROP -m comment --comment "Reject to 8.8.8.8"
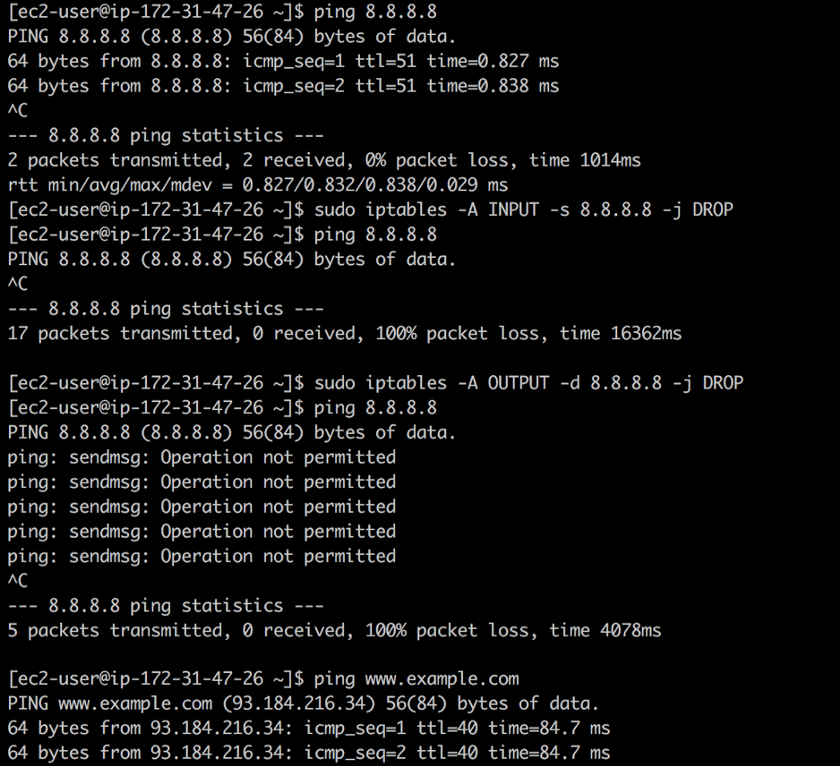 Fechar acesso
Fechar acessoA primeira regra descarta todos os pacotes do DNS público do Google: o
ping funciona, mas os pacotes não são retornados. A segunda regra descarta todos os pacotes provenientes do seu sistema na direção do DNS público do Google. Em resposta ao
ping , obtemos a
Operação não permitida .
Nota: neste caso em particular, seria melhor usar whois 8.8.8.8 , mas este é apenas um exemplo.Você pode se aprofundar ainda mais na toca do coelho, pois tudo o que usa TCP e UDP realmente depende do IP. Na maioria dos casos, o IP está vinculado ao ARP. Não se esqueça dos firewalls ...
 Se você escolher uma pílula vermelha, permanecerá no País das Maravilhas e mostrarei a profundidade da toca do coelho ”
Se você escolher uma pílula vermelha, permanecerá no País das Maravilhas e mostrarei a profundidade da toca do coelho ”Uma abordagem mais radical é
desligar os carros um por um e ver o que está quebrado ... tornar-se um "macaco do caos". Obviamente, muitos sistemas de produção não são projetados para um ataque tão bruto, mas pelo menos podem ser tentados em um ambiente de teste.
Construir um mapa de dependência geralmente é um exercício muito longo. Falei recentemente com um cliente que passei quase 2 anos desenvolvendo uma ferramenta que, no modo semiautomático, gera mapas de dependência para centenas de microsserviços e equipes.
O resultado, no entanto, é extremamente interessante e útil. Você aprenderá muito sobre seu sistema, suas dependências e operações. Novamente, seja paciente: a jornada em si é da maior importância.
3. Cuidado com a arrogância
"Quem sonha com o quê, acredita nisso." - Demóstenes
Você já ouviu falar do
efeito do excesso de confiança ?
Segundo a Wikipedia, o efeito do excesso de confiança é "uma distorção cognitiva na qual a confiança de uma pessoa em suas ações e decisões é muito maior que a precisão objetiva desses julgamentos, especialmente quando o nível de confiança é relativamente alto".
 Baseado no instinto e na experiência ...
Baseado no instinto e na experiência ...Pela minha própria experiência, posso dizer que essa distorção é uma ótima dica sobre por onde começar a engenharia do caos.
Cuidado com o operador autoconfiante:
Charlie: "Essa coisa não cai há cinco anos, está tudo bem!"
Falha: "Espere ... estarei em breve!"
O viés como conseqüência da autoconfiança é uma coisa insidiosa e até perigosa devido a vários fatores que a afetam. Isto é especialmente verdade quando os membros da equipe colocam sua alma em uma determinada tecnologia ou passam muito tempo em "correções".
Resumir
A busca por um ponto de partida para a engenharia do caos sempre produz mais resultados do que o esperado, e as equipes que começam a quebrar tudo rapidamente perdem de vista a essência mais global e interessante da
engenharia (caos) - a aplicação criativa de
métodos científicos e
evidências empíricas para design, desenvolvimento , operação, manutenção e aprimoramento de sistemas (de software).
Sobre isso, a segunda parte chega ao fim. Escreva críticas, compartilhe opiniões ou bata palmas no
Medium .
Na próxima parte, analisarei realmente as ferramentas e técnicas para introduzir falhas no sistema. Até tchau! ATUALIZADO (19 de dezembro): a
tradução da terceira parte ficou disponível.
PS do tradutor
Leia também em nosso blog: