Em geral, o reconhecimento facial e a identificação das pessoas de acordo com os resultados parecem sexo adolescente para idosos - todo mundo fala muito sobre ele, mas pouca prática. É claro que não estamos mais surpresos que, após baixar fotos de encontros amigáveis, o Facebook / VK sugere marcar as pessoas encontradas na imagem, mas aqui sabemos intuitivamente que as redes sociais têm uma boa ajuda na forma de gráfico de conexões de uma pessoa. E se não houver esse gráfico? No entanto, vamos começar em ordem.

Inicialmente, o reconhecimento de rosto e a identificação de "amigo / inimigo" cresceram devido às necessidades domésticas - os toxicodependentes entraram na porta de um colega, monitoraram constantemente a imagem da câmera de vídeo instalada e até desmontaram onde o vizinho e o estrangeiro não desejavam não
Portanto, em apenas uma semana, um protótipo foi montado no joelho, consistindo em uma câmera IP, um dispositivo de placa única, um sensor de movimento e a biblioteca de reconhecimento de reconhecimento facial face_recognition Python. Como a biblioteca python estava em um hardware único e bastante poderoso ... digamos com cuidado, não muito rápido, decidimos criar o processo de processamento da seguinte maneira:
- o sensor de movimento determina se há movimento na área de espaço confiada a ele e sinaliza sua presença;
- um serviço escrito baseado no gstreamer, que recebe constantemente um fluxo de uma câmera IP, corta 5 segundos antes e 10 segundos após a detecção e o envia à biblioteca de reconhecimento para análise;
- ela, por sua vez, assiste ao vídeo, encontra rostos lá, compara-os com amostras conhecidas e, se desconhecido, entrega o vídeo ao canal do Telegram, depois deveria ser controlado no mesmo local para eliminar imediatamente os falsos positivos - por exemplo, quando um vizinho virou-se para a câmera do lado errado das amostras.
Todo o processo foi colado pelo nosso amado Erlang e, no processo de teste em colegas, ele provou sua capacidade mínima de trabalho.
No entanto, o modelo montado não encontrou aplicação na vida real - não por causa de sua imperfeição técnica, o que sem dúvida foi - como mostra a experiência, coletada no joelho em escritórios com efeito de estufa tem uma tendência muito ruim a entrar em campo e no momento da demonstração ao cliente , e por causa dos organizacionais, os moradores da entrada recusaram a maioria de qualquer videovigilância.
O projeto foi para a prateleira e periodicamente cutucou com um palito para demonstrações durante as vendas e o desejo de reencarnar na casa pessoal.
Tudo mudou desde o momento em que tivemos um projeto mais específico e bastante comercial sobre o mesmo tópico. Como não seria possível cortar cantos usando um sensor de movimento diretamente da declaração do problema, tive que me aprofundar nas nuances de busca e reconhecimento de rostos em três cabeças (ok, duas e meia, se você contar a minha) diretamente no fluxo. E então uma revelação aconteceu.
O problema é que a maioria das descobertas sobre esse assunto são esboços puramente acadêmicos sobre o tema: "Eu tive que escrever um artigo em uma revista sobre um tema da moda e obter uma marca para publicar". Não deprecio os méritos dos cientistas - entre os artigos que achei úteis e interessantes, mas, infelizmente, tenho que admitir que a reprodutibilidade do trabalho de seu código publicado no Github deixa muito a desejar ou parece um empreendimento dúbio com o tempo perdido no final.
Muitas estruturas para redes neurais e aprendizado de máquina eram muitas vezes difíceis de levantar - o reconhecimento de face era uma tarefa estreita e separada para eles, desinteressante em uma ampla gama de problemas que eles resolveram. Em outras palavras, pegar um exemplo pronto e executá-lo no hardware de destino apenas para verificar como funciona e se funciona, não funcionou. Esse não foi um exemplo; a necessidade de obtê-lo sugeriu uma busca azeda do conjunto de determinadas bibliotecas de determinadas versões para sistemas operacionais estritamente definidos. I.e. para pegar e voar em movimento - literalmente migalhas como o reconhecimento facial mencionado anteriormente, que usamos para os trabalhos anteriores.
As grandes empresas, como sempre, nos salvaram. A Intel e a Nvidia há muito sentem o impulso crescente e a atratividade comercial dessa classe de tarefas, mas como fornecedores de equipamentos, eles distribuem suas estruturas para resolver problemas específicos de aplicativos gratuitamente.
Nosso projeto provavelmente não era de pesquisa, mas de natureza experimental; portanto, não analisamos e comparamos as soluções de fornecedores individuais, mas simplesmente pegamos o primeiro com o objetivo de coletar um protótipo pronto e testá-lo em batalha, enquanto recebíamos a resposta mais rápida possível. Portanto, a escolha caiu muito rapidamente no
Intel OpenVINO - uma biblioteca para a aplicação prática de aprendizado de máquina em tarefas aplicadas.
Para começar, montamos um suporte, que tradicionalmente é um conjunto de nettop com um processador Intel Core i3 e câmeras IP de fornecedores chineses no mercado. A câmera foi conectada diretamente ao nettop e forneceu um fluxo RTSP com um FPS não muito grande, com base no pressuposto de que as pessoas ainda não corriam na frente dela, como nas competições. A velocidade de processamento de um quadro (busca e reconhecimento de rostos) flutuou na região de dezenas a centenas de milissegundos, o que foi suficiente para incorporar o mecanismo de busca de pessoas que usam amostras existentes. Além disso, também tínhamos um plano de backup - a Intel possui um coprocessador especial para acelerar os cálculos das redes neurais do
Neural Compute Stick 2 , que poderíamos usar se não tivéssemos um processador de uso geral. Mas - até agora nada aconteceu.
Após concluir a montagem e verificar a funcionalidade dos exemplos básicos - um recurso distinto do Intel SDK estava em um guia passo a passo e muito detalhado - começamos a construir o software.
A principal tarefa que enfrentamos era procurar uma pessoa no campo de visão da câmera, sua identificação e notificação oportuna de sua presença. Assim, além de reconhecer rostos e compará-los com padrões (como fazer isso, naquele momento, causava menos perguntas do que tudo o resto), precisávamos fornecer coisas secundárias ao plano de interface. Ou seja, devemos receber quadros com os rostos das pessoas necessárias da mesma câmera para sua identificação subseqüente. Por que, a partir da mesma câmera, também acho bastante óbvio - o ponto de instalação da câmera no objeto e a ótica da lente introduz certas distorções, que, presumivelmente, podem afetar a qualidade do reconhecimento, usamos uma fonte diferente de dados de origem que uma ferramenta de rastreamento.
I.e. Além do próprio manipulador de fluxo, precisamos de pelo menos um arquivo de vídeo e um analisador de arquivo de vídeo que isolem todos os rostos detectados da gravação e salvem os mais adequados como referência.
Como sempre, tomamos o familiar Erlang e PostgreSQL como cola entre ffmpeg, aplicativos na OpenVINO e Telegram Bot API para alertas. Além disso, precisávamos de uma interface da web para fornecer o conjunto mínimo de procedimentos para gerenciar o complexo, que nosso colega de front-end havia carregado no VueJS.
A lógica do trabalho era a seguinte:
- sob controle de um plano de controle (em Erlang), o ffmpeg grava um fluxo da câmera para o vídeo em fatias de cinco minutos, um processo separado garante que os registros sejam armazenados em um volume estritamente especificado e limpa o mais antigo quando esse limite for atingido;
- através da interface do usuário da web, é possível visualizar qualquer registro, eles são organizados em ordem cronológica, o que, embora não sem dificuldade, permite isolar o fragmento desejado e enviá-lo para processamento;
- o processamento consiste em analisar o vídeo e extrair quadros com rostos detectados, apenas o software baseado no OpenVINO (devo dizer, aqui conseguimos reduzir um pouco o ângulo - o software para analisar o fluxo e analisar arquivos é quase idêntico, e é por isso que a maioria foi para uma biblioteca compartilhada, e os próprios utilitários diferem apenas na cadeia de processamento no módulo modular). O processamento ocorre no vídeo, isolando as faces encontradas usando uma rede neural especialmente treinada. Os fragmentos resultantes do quadro que contém faces caem em outra rede neural, que forma um vetor de 256 elementos, que são, de fato, as coordenadas dos pontos de referência do rosto de uma pessoa. Esse vetor, o quadro detectado e as coordenadas do retângulo da face encontrada são armazenados no banco de dados;
- além disso, após a conclusão do processamento, o operador abre a variedade de quadros desenhados, fica horrorizado com o número e passa a procurar pessoas-alvo. As amostras selecionadas podem ser adicionadas a uma pessoa existente ou criar uma nova. Após a conclusão do processamento da tarefa, os resultados da análise são excluídos, com exceção dos vetores armazenados mapeados para os registros de observáveis;
- consequentemente, podemos examinar os quadros e os vetores de detecção a qualquer momento e editar, excluindo amostras sem êxito;
- paralelo ao ciclo de detecção em segundo plano, o serviço de análise de fluxo sempre funciona, o que faz a mesma coisa, mas com o fluxo da câmera. Ele seleciona faces no fluxo observado e as compara com amostras do banco de dados, que se baseia na simples suposição de que os vetores de uma pessoa estarão mais próximos um do outro do que todos os outros vetores. Um cálculo em pares da distância entre os vetores ocorre, quando o limite é atingido, um registro de detecção e um quadro são colocados no banco de dados. Além disso, uma pessoa é adicionada à lista de paradas em um futuro próximo, o que evita várias notificações sobre a mesma pessoa;
- o plano de controle verifica periodicamente o registro de detecção e, no caso de novas entradas, notifica com uma mensagem com a foto anexada e destacando o rosto através do bot para aqueles que são permitidos de acordo com as configurações.
Parece algo como isto:
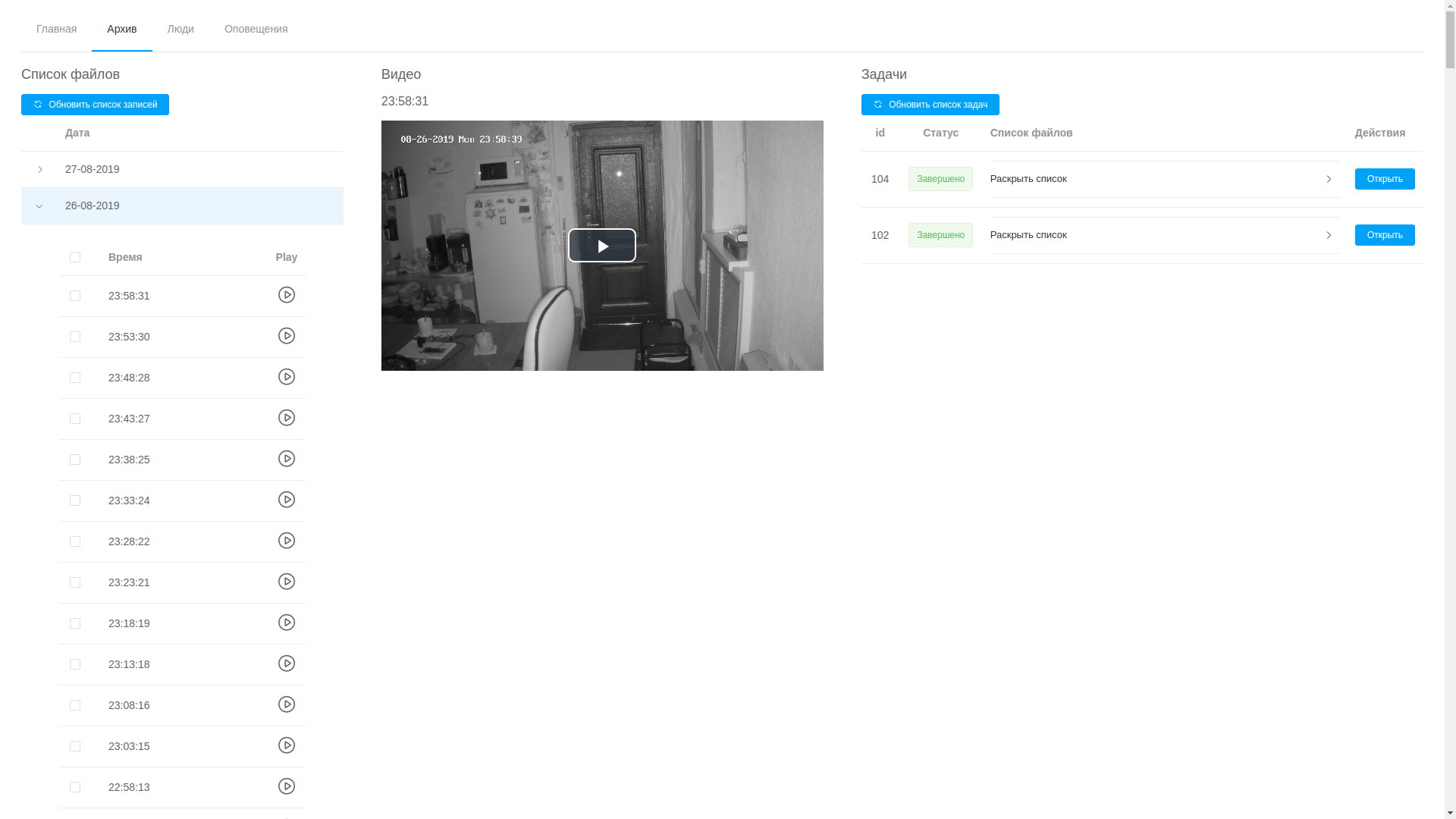 Ver arquivo
Ver arquivo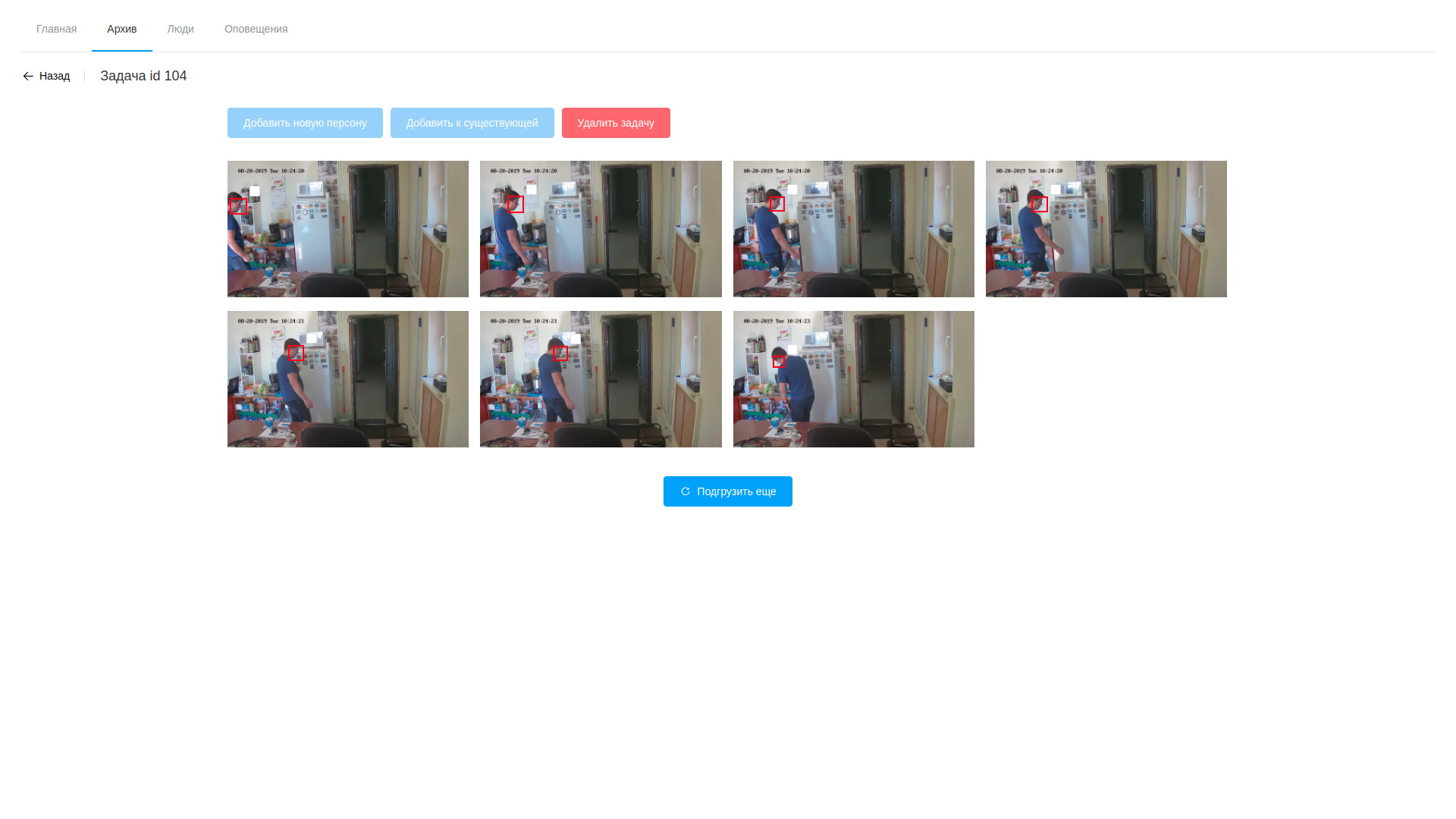 Resultados da análise de vídeo
Resultados da análise de vídeo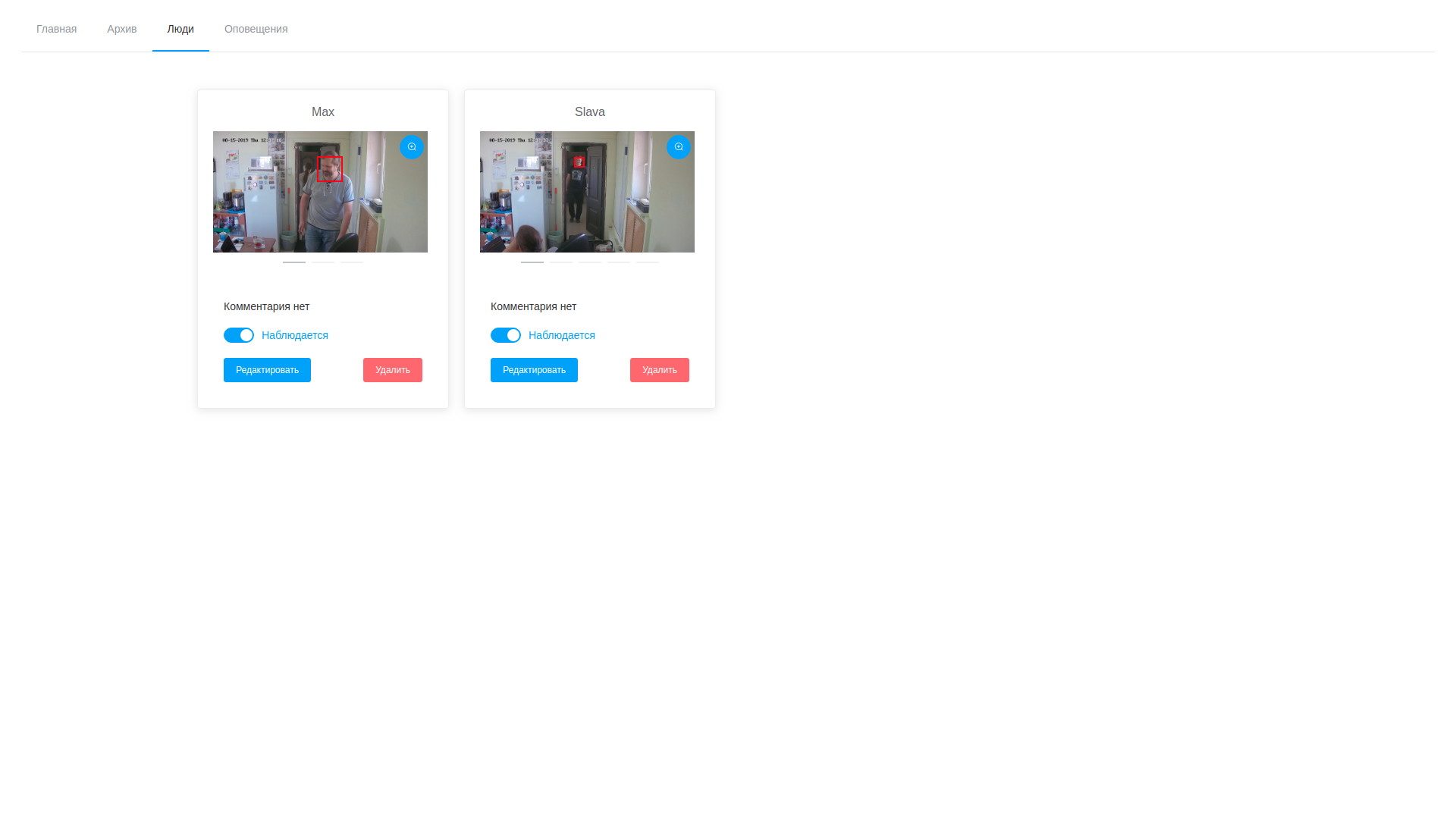 Lista de personalidades observadas
Lista de personalidades observadasA solução resultante é, de muitas maneiras, controversa e, às vezes, nem ideal, tanto em termos de produtividade quanto em termos de redução do tempo de reação. Mas, repito, não tínhamos o objetivo de obter um sistema eficaz imediatamente, mas simplesmente seguir esse caminho e preencher o número máximo de cones, identificar caminhos estreitos e possíveis problemas não óbvios.
O sistema montado foi testado em condições de estufa por uma semana. Durante esse período, foram observadas as seguintes observações:
- existe uma clara dependência da qualidade do reconhecimento da qualidade das amostras originais. Se a pessoa observada passar pela zona de observação muito rapidamente, com um alto grau de probabilidade, ela não deixará os dados para amostragem e não será reconhecida. No entanto, acho que é uma questão de ajustar o sistema, incluindo parâmetros de iluminação e de fluxo de vídeo;
- como o sistema opera com o reconhecimento de elementos do rosto (olhos, nariz, boca, sobrancelhas etc.), é fácil enganar colocando um obstáculo visual entre o rosto e a câmera (cabelos, óculos escuros, capuz etc.) - o rosto, provavelmente, será encontrado, mas a comparação com as amostras não funcionará devido à forte discrepância entre os vetores de detecção e as amostras;
- óculos comuns não afetam muito - tivemos exemplos de respostas positivas em pessoas com óculos e respostas falso-negativas em pessoas que usam óculos para testes;
- se a barba estava nas amostras originais e desapareceu, o número de operações é reduzido (o autor dessas linhas reduziu a barba para 2 mm e o número de operações foi reduzido pela metade);
- também ocorreram falsos positivos, é uma ocasião para imersão adicional na matemática da questão e, possivelmente, uma solução para a questão da correspondência parcial dos vetores e o método ideal para calcular a distância entre eles. No entanto, os testes de campo devem revelar ainda mais problemas a esse respeito.
O que está por vir? Verificando o sistema em batalha, otimizando o ciclo de processamento de detecção, simplificando o procedimento de busca de eventos no arquivo de vídeo, adicionando mais dados à análise (idade, sexo, emoções) e outras 100.500 tarefas pequenas e não tão necessárias que ainda precisam ser realizadas. Mas o primeiro passo no caminho de mil passos que já demos. Se alguém compartilhar sua experiência na solução de tais problemas ou fornecer links interessantes sobre esse assunto, ficarei muito agradecido.