
Neste artigo, gostaria de propor uma alternativa ao estilo tradicional de design de teste usando conceitos de programação funcional no Scala. Essa abordagem foi inspirada por muitos meses de dor ao manter dezenas de testes com falha e um desejo ardente de torná-los mais diretos e mais compreensíveis.
Embora o código esteja no Scala, as idéias propostas são apropriadas para desenvolvedores e engenheiros de controle de qualidade que usam linguagens que suportam programação funcional. Você pode encontrar um link do Github com a solução completa e um exemplo no final do artigo.
O problema
Se você já teve que lidar com testes (não importa quais: testes de unidade, integracionais ou funcionais), eles provavelmente foram escritos como um conjunto de instruções seqüenciais. Por exemplo:
Na minha experiência, essa maneira de escrever testes é preferida pela maioria dos desenvolvedores. Nosso projeto tem cerca de mil testes em diferentes níveis de isolamento, e todos eles foram escritos com esse estilo até recentemente. À medida que o projeto crescia, começamos a notar sérios problemas e lentidão na manutenção de tais testes: corrigi-los levaria pelo menos a mesma quantidade de tempo que a escrita do código de produção.
Ao escrever novos testes, sempre tínhamos que encontrar maneiras de preparar dados do zero, geralmente copiando e colando as etapas dos testes vizinhos. Como resultado, quando o modelo de dados do aplicativo mudava, o castelo de cartas desmoronava, e teríamos que reparar todos os testes com falha: no pior cenário - mergulhando profundamente em cada teste e reescrevendo-o.
Quando um teste falha "honestamente" - ou seja, devido a um bug real na lógica de negócios - era impossível entender o que deu errado sem a depuração. Como os testes eram tão difíceis de entender, ninguém tinha o conhecimento completo sempre à mão sobre como o sistema deveria se comportar.
Toda essa dor, na minha opinião, é um sintoma dos dois problemas mais profundos desse design de teste:
- Não existe uma estrutura clara e prática para os testes. Todo teste é um floco de neve único. A falta de estrutura leva à verbosidade, que consome muito tempo e desmotiva. Detalhes insignificantes desviam o que é mais importante - o requisito que o teste afirma. Copiar e colar torna-se a principal abordagem para escrever novos casos de teste.
- Os testes não ajudam os desenvolvedores a localizar defeitos; eles apenas sinalizam que há algum tipo de problema. Para entender o estado em que o teste é executado, você deve plotá-lo em sua cabeça ou usar um depurador.
Modelagem
Podemos fazer melhor? (Alerta de spoiler: nós podemos.) Vamos considerar que tipo de estrutura esse teste pode ter.
val db: Database = Database.forURL(TestConfig.generateNewUrl()) migrateDb(db) insertUser(db, id = 1, name = "test", role = "customer") insertPackage(db, id = 1, name = "test", userId = 1, status = "new") insertPackageItems(db, id = 1, packageId = 1, name = "test", price = 30) insertPackageItems(db, id = 2, packageId = 1, name = "test", price = 20) insertPackageItems(db, id = 3, packageId = 1, name = "test", price = 40)
Como regra geral, o código em teste espera alguns parâmetros explícitos (identificadores, tamanhos, quantidades, filtros, para citar alguns), além de alguns dados externos (de um banco de dados, fila ou outro serviço do mundo real). Para que nosso teste seja executado de forma confiável, ele precisa de um dispositivo elétrico - um estado para colocar o sistema, os provedores de dados ou ambos.
Com esse acessório, preparamos uma dependência para inicializar o código em teste - preencha um banco de dados, crie uma fila de um tipo específico etc.
val svc = new SomeProductionLogic(db) val result = svc.calculatePrice(packageId = 1)
Após executar o código em teste em alguns parâmetros de entrada, recebemos uma saída - explícita (retornada pelo código em teste) e implícita (as alterações no estado).
result shouldBe 90
Por fim, verificamos se a saída é a esperada, finalizando o teste com uma ou mais asserções .
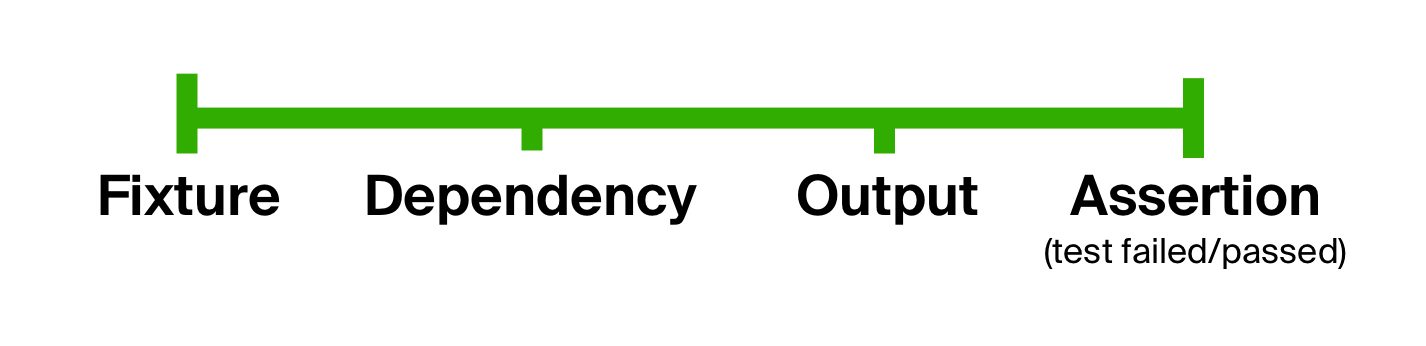
Pode-se concluir que os testes geralmente consistem nos mesmos estágios: preparação de entrada, execução de código e asserção de resultado. Podemos usar esse fato para nos livrar do primeiro problema de nossos testes , ou seja, de forma excessivamente liberal, dividindo explicitamente o corpo de um teste em etapas. Essa idéia não é nova, como pode ser vista nos testes no estilo BDD ( desenvolvimento orientado a comportamento ).
E quanto à extensibilidade? Qualquer etapa do processo de teste pode, por sua vez, conter qualquer quantidade de etapas intermediárias. Por exemplo, poderíamos dar um passo grande e complicado, como construir um equipamento e dividi-lo em vários, encadeados um após o outro. Dessa forma, o processo de teste pode ser infinitamente extensível, mas, no final das contas, sempre consistindo nas mesmas poucas etapas gerais.

Executando testes
Vamos tentar implementar a ideia de dividir o teste em estágios, mas primeiro, devemos determinar que tipo de resultado gostaríamos de ver.
No geral, gostaríamos de escrever e manter testes para se tornar menos trabalhoso e mais agradável. Quanto menos instruções explícitas e não exclusivas um teste tiver, menos alterações deverão ser feitas após a alteração dos contratos ou refatoração, e menos tempo levará para a leitura do teste. O design do teste deve promover a reutilização de trechos de código comuns e desencorajar cópias e colagens irracionais. Também seria bom se os testes tivessem uma forma unificada. A previsibilidade melhora a legibilidade e economiza tempo. Por exemplo, imagine quanto tempo levaria mais tempo para os cientistas aspirantes aprenderem todas as fórmulas se os livros os escrevessem livremente em linguagem comum, em oposição à matemática.
Assim, nosso objetivo é ocultar qualquer coisa perturbadora e desnecessária, deixando apenas o que é criticamente importante para a compreensão: o que está sendo testado, quais são as entradas e saídas esperadas.
Vamos voltar ao nosso modelo da estrutura do teste.
Tecnicamente, todas as etapas podem ser representadas por um tipo de dados e cada transição - por uma função. É possível passar do tipo de dado inicial para o final, aplicando cada função ao resultado do anterior. Em outras palavras, usando a composição das funções de preparação de dados (vamos chamá-lo de prepare ), execução de código ( execute ) e verificação do resultado esperado ( check ). A entrada para essa composição seria o primeiro passo - o acessório. Vamos chamar a função de ordem superior resultante como a função de ciclo de vida do teste .
Teste a função do ciclo de vida def runTestCycle[FX, DEP, OUT, F[_]]( fixture: FX, prepare: FX => DEP, execute: DEP => OUT, check: OUT => F[Assertion] ): F[Assertion] =
Surge uma questão: de onde vêm essas funções? Bem, quanto à preparação de dados, há apenas uma quantidade limitada de maneiras de fazê-lo - preenchendo um banco de dados, zombando etc. Portanto, é útil escrever variantes especializadas da função de prepare compartilhada em todos os testes. Como resultado, seria mais fácil criar funções especializadas no ciclo de vida do teste para cada caso, o que ocultaria implementações concretas da preparação de dados. Como a execução e as asserções de código são mais ou menos exclusivas para cada teste (ou grupo de testes), a execute e a check devem ser escritas sempre explicitamente.
Função de ciclo de vida de teste adaptada para teste de integração em um banco de dados Ao delegar todas as nuances administrativas na função do ciclo de vida do teste, temos a capacidade de estender o processo de teste sem tocar em nenhum teste. Utilizando a composição da função, podemos interferir em qualquer etapa do processo e extrair ou adicionar dados.
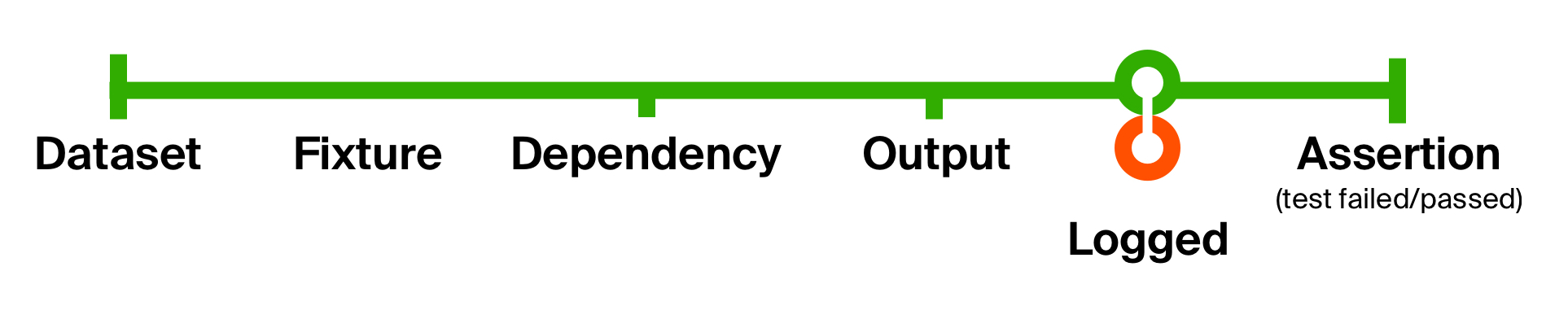
Para ilustrar melhor as capacidades dessa abordagem, vamos resolver o segundo problema do nosso teste inicial - a falta de informações suplementares para identificar problemas. Vamos adicionar o log de qualquer execução de código que tenha retornado. Nosso registro não altera o tipo de dados; produz apenas um efeito colateral - enviando uma mensagem para o console. Após o efeito colateral, retornamos como está.
Teste a função do ciclo de vida com registro def logged[T](implicit loggedT: Logged[T]): T => T = (that: T) => {
Com essa alteração simples, adicionamos o registro da saída do código executado em todos os testes . A vantagem dessas funções pequenas é que elas são fáceis de entender, compor e eliminar quando necessário.

Como resultado, nosso teste agora se parece com o seguinte:
val fixture: SomeMagicalFixture = ???
O corpo do teste tornou-se conciso, o equipamento e as verificações podem ser reutilizados em outros testes, e não preparamos o banco de dados manualmente em nenhum outro lugar. Apenas um pequeno problema permanece ...
Preparação do acessório
No código acima, estávamos trabalhando com a suposição de que o acessório seria dado a nós de algum lugar. Como os dados são o ingrediente crítico de testes simples e de manutenção, precisamos abordar como fazê-los facilmente.
Suponha que nossa loja em teste tenha um banco de dados relacional de tamanho médio típico (por uma questão de simplicidade, neste exemplo ele possui apenas 4 tabelas, mas, na realidade, pode ter centenas). Algumas tabelas têm dados referenciais, alguns - dados comerciais e tudo isso pode ser agrupado logicamente em uma ou mais entidades complexas. As relações são vinculadas a chaves estrangeiras ; para criar um Bonus , é necessário um Package , que por sua vez precisa de um User e assim por diante.

As soluções alternativas e os hacks levam apenas à inconsistência dos dados e, como resultado, a horas e horas de depuração. Por esse motivo, não estamos fazendo alterações no esquema de forma alguma.
Poderíamos usar alguns métodos de produção para preenchê-lo, mas mesmo sob escrutínio superficial, isso levanta muitas questões difíceis. O que preparará os dados nos testes para esse código de produção? Teríamos que reescrever os testes se o contrato desse código fosse alterado? E se os dados vierem de algum outro lugar e não houver métodos a serem usados? Quantas solicitações seriam necessárias para criar uma entidade que depende de muitas outras?
Preenchimento de banco de dados no teste inicial insertUser(db, id = 1, name = "test", role = "customer") insertPackage(db, id = 1, name = "test", userId = 1, status = "new") insertPackageItems(db, id = 1, packageId = 1, name = "test", price = 30) insertPackageItems(db, id = 2, packageId = 1, name = "test", price = 20) insertPackageItems(db, id = 3, packageId = 1, name = "test", price = 40)
Os métodos auxiliares dispersos, como os do nosso primeiro exemplo, são o mesmo problema sob uma aparência diferente. Eles colocam a responsabilidade de gerenciar dependências sobre nós mesmos, o que estamos tentando evitar.
Idealmente, gostaríamos de alguma estrutura de dados que apresentasse todo o estado do sistema de uma só vez. Um candidato certo seria uma tabela (ou um conjunto de dados , como em PHP ou Python) que não teria nada a mais, além de campos críticos para a lógica de negócios. Se isso mudar, manter os testes seria fácil: apenas mudamos os campos no conjunto de dados. Exemplo:
val dataTable: Seq[DataRow] = Table( ("Package ID", "Customer's role", "Item prices", "Bonus value", "Expected final price") , (1, "customer", Vector(40, 20, 30) , Vector.empty , 90.0) , (2, "customer", Vector(250) , Vector.empty , 225.0) , (3, "customer", Vector(100, 120, 30) , Vector(40) , 210.0) , (4, "customer", Vector(100, 120, 30, 100) , Vector(20, 20) , 279.0) , (5, "vip" , Vector(100, 120, 30, 100, 50), Vector(10, 20, 10), 252.0) )
Da nossa tabela, criamos chaves - links de entidade por ID. Se uma entidade depende de outra, uma chave para essa outra entidade também é criada. Pode acontecer que duas entidades diferentes criem uma dependência com o mesmo ID, o que pode levar a uma violação da chave primária . No entanto, nesse estágio, é incrivelmente barato desduplicar chaves - como tudo o que elas contêm são IDs, podemos colocá-las em uma coleção que desduplica para nós, por exemplo, um Set . Se isso for insuficiente, sempre podemos implementar a desduplicação mais inteligente como uma função separada e compor na função de ciclo de vida do teste.
Chaves (exemplo) sealed trait Key case class PackageKey(id: Int, userId: Int) extends Key case class PackageItemKey(id: Int, packageId: Int) extends Key case class UserKey(id: Int) extends Key case class BonusKey(id: Int, packageId: Int) extends Key
A geração de dados falsos para campos (por exemplo, nomes) é delegada em uma classe separada. Posteriormente, usando essa classe e regras de conversão para chaves, obtemos os objetos Row destinados à inserção no banco de dados.
Linhas (exemplo) object SampleData { def name: String = "test name" def role: String = "customer" def price: Int = 1000 def bonusAmount: Int = 0 def status: String = "new" } sealed trait Row case class PackageRow(id: Int, name: String, userId: Int, status: String) extends Row case class PackageItemRow(id: Int, packageId: Int, name: String, price: Int) extends Row case class UserRow(id: Int, name: String, role: String) extends Row case class BonusRow(id: Int, packageId: Int, bonusAmount: Int) extends Row
Como os dados falsos geralmente não são suficientes, precisamos de uma maneira de substituir campos específicos. Felizmente, as lentes são exatamente o que precisamos - podemos usá-las para percorrer todas as linhas criadas e alterar apenas os campos de que precisamos. Como as lentes são funções disfarçadas, podemos compor como sempre, que é o ponto mais forte.
Lense (exemplo) def changeUserRole(userId: Int, newRole: String): Set[Row] => Set[Row] = (rows: Set[Row]) => rows.modifyAll(_.each.when[UserRow]) .using(r => if (r.id == userId) r.modify(_.role).setTo(newRole) else r)
Graças à composição, podemos aplicar diferentes otimizações e melhorias dentro do processo: por exemplo, podemos agrupar linhas pela tabela para inseri-las com um único INSERT para reduzir o tempo de execução do teste ou registrar todo o estado do banco de dados.
Função de preparação do aparelho def makeFixture[STATE, FX, ROW, F[_]]( state: STATE, applyOverrides: F[ROW] => F[ROW] = x => x ): FX = (extractKeys andThen deduplicateKeys andThen enrichWithSampleData andThen applyOverrides andThen logged andThen buildFixture) (state)
Finalmente, a coisa toda nos fornece um suporte. No teste em si, nada extra é mostrado, exceto o conjunto de dados inicial - todos os detalhes são ocultados pela composição da função.

Nosso conjunto de testes agora fica assim:
val dataTable: Seq[DataRow] = Table( ("Package ID", "Customer's role", "Item prices", "Bonus value", "Expected final price") , (1, "customer", Vector(40, 20, 30) , Vector.empty , 90.0) , (2, "customer", Vector(250) , Vector.empty , 225.0) , (3, "customer", Vector(100, 120, 30) , Vector(40) , 210.0) , (4, "customer", Vector(100, 120, 30, 100) , Vector(20, 20) , 279.0) , (5, "vip" , Vector(100, 120, 30, 100, 50), Vector(10, 20, 10), 252.0) ) "If the buyer's role is" - { "a customer" - { "And the total price of items" - { "< 250 after applying bonuses - no discount" - { "(case: no bonuses)" in calculatePriceFor(dataTable, 1) "(case: has bonuses)" in calculatePriceFor(dataTable, 3) } ">= 250 after applying bonuses" - { "If there are no bonuses - 10% off on the subtotal" in calculatePriceFor(dataTable, 2) "If there are bonuses - 10% off on the subtotal after applying bonuses" in calculatePriceFor(dataTable, 4) } } } "a vip - then they get a 20% off before applying bonuses and then all the other rules apply" in calculatePriceFor(dataTable, 5) }
E o código auxiliar:
Adicionar novos casos de teste à tabela é uma tarefa trivial que nos concentra em cobrir mais casos marginais e não em escrever código padrão.
Reutilizando a preparação do acessório em diferentes projetos
Ok, escrevemos muito código para preparar equipamentos em um projeto específico, gastando bastante tempo no processo. E se tivermos vários projetos? Estamos fadados a reinventar a coisa toda do zero toda vez?
Podemos abstrair a preparação do dispositivo elétrico sobre um modelo de domínio concreto. No mundo da programação funcional, existe um conceito de tipeclasses . Sem se aprofundar nos detalhes, eles não são como classes no OOP, mas mais como interfaces, pois definem um determinado comportamento de algum grupo de tipos. A diferença fundamental é que eles não são herdados, mas instanciados como variáveis. No entanto, semelhante à herança, a resolução de instâncias de classe de tipo ocorre em tempo de compilação . Nesse sentido, as classes de tipo podem ser entendidas como métodos de extensão do Kotlin e C # .
Para registrar um objeto, não precisamos saber o que há dentro, quais campos e métodos ele possui. Tudo o que importa é ter um log() comportamento log() com uma assinatura específica. Estender todas as classes com uma interface de Logged seria extremamente tedioso e, mesmo assim, não seria possível em muitos casos - por exemplo, para bibliotecas ou classes padrão. Com tipeclasses, isso é muito mais fácil. Podemos criar uma instância de uma classe chamada Logged , por exemplo, para um equipamento registrá-lo em um formato legível por humanos. Para todo o resto que não tenha uma instância de Logged , podemos fornecer um fallback: uma instância para o tipo Any que usa um método padrão toString() para registrar todos os objetos em sua representação interna gratuitamente.
Um exemplo da classe de tipo Logged e suas instâncias trait Logged[A] { def log(a: A)(implicit logger: Logger): A }
Além do registro, podemos usar essa abordagem durante todo o processo de fabricação de acessórios. Nossa solução propõe uma maneira abstrata de criar acessórios de banco de dados e um conjunto de classes para acompanhá-lo. É o projeto que utiliza a responsabilidade da solução implementar as instâncias dessas classes para que tudo funcione.
Ao projetar esta ferramenta de preparação de acessórios, usei os princípios do SOLID como uma bússola para garantir que seja sustentável e extensível:
- O princípio da responsabilidade única : cada classe descreve um e apenas um comportamento de um tipo.
- O Princípio Aberto / Fechado : não modificamos nenhuma das classes de produção; em vez disso, os estendemos com instâncias de classes de tipo.
- O Princípio da Substituição de Liskov não se aplica aqui, pois não usamos herança.
- O princípio de segregação de interface : usamos muitas classes de tipos especializadas em oposição a globais.
- Princípio da inversão de dependência : a função de preparação do equipamento não depende de tipos concretos, mas de classes abstratas.
Depois de garantir que todos os princípios sejam atendidos, podemos assumir com segurança que nossa solução é sustentável e extensível o suficiente para ser usada em diferentes projetos.
Depois de escrever a função do ciclo de vida do teste e a solução para a preparação do dispositivo, que também é independente de um modelo de domínio concreto em qualquer aplicativo, estamos prontos para melhorar todos os testes restantes.
Bottom line
Mudamos do estilo tradicional de design de teste (passo a passo) para funcional. O estilo passo a passo é útil no início e em projetos de tamanho menor, porque não restringe os desenvolvedores e não requer nenhum conhecimento especializado. No entanto, quando a quantidade de testes se torna muito grande, esse estilo tende a cair. Escrever testes no estilo funcional provavelmente não resolverá todos os seus problemas de teste, mas poderá melhorar significativamente a escala e a manutenção de testes em projetos, onde existem centenas ou milhares deles. Testes escritos no estilo funcional acabam sendo mais concisos e focados nas coisas essenciais (como dados, código sob teste e resultado esperado), não nas etapas intermediárias.
Além disso, exploramos o quão poderosas podem ser a composição de funções e as classes de tipos na programação funcional. Com a ajuda deles, é bastante simples projetar soluções com a capacidade de expansão e reutilização em mente.
Desde a adoção do estilo, há vários meses, nossa equipe teve que se esforçar para se adaptar, mas no final, aproveitamos o resultado. Novos testes são gravados mais rapidamente, os logs tornam a vida muito mais confortável e os conjuntos de dados são úteis para verificar sempre que houver dúvidas sobre os meandros da lógica. Nossa equipe tem como objetivo mudar todos os testes para esse novo estilo gradualmente.
Link para a solução e um exemplo completo pode ser encontrado aqui: Github . Divirta-se com seus testes!