"Consultor +" - um sistema de referência para advogados, contadores e assim por diante. Funciona de forma estável como um relógio. Nesta postagem, sugerimos que você defina esse relógio um pouco para as suas necessidades em termos de saída de texto, a saber: veja como você pode processar as informações de texto que o sistema fornece com python. Ao longo do caminho, trabalhe com os elementos de texto declarados no título.
Sombra em cima do muro
Como advogado, que trabalhou por muito tempo com o programa de ajuda "Consultant +", sempre me faltava uma função comum nesse sistema. Esta função foi a seguinte. Quando qualquer alteração aparece no ato regulatório, os funcionários da K + publicam uma visão geral das alterações na forma de duas colunas de texto:

A coluna da esquerda é como era antes, a coluna da direita é a norma que está em vigor agora. Agora (alguns anos atrás), a funcionalidade foi atualizada e as alterações são destacadas
em negrito e imediatamente visíveis. Tudo isso é muito conveniente. Mas há coisas desconfortáveis.
Em primeiro lugar, algumas normas não são dadas, porque o volume deles é muito grande para os funcionários da K + e você precisa acessar os links do sistema. Em segundo lugar, não é possível pegar e copiar essas duas colunas colando-as em uma tabela regular de excel ou word.
Talvez isso tenha sido feito intencionalmente para que os usuários trabalhem mais ativamente com o sistema, incluindo a transferência de nada a partir daí.
Bem, tem que consertar.
A tarefa : espalhar o texto em duas colunas, onde é possível e onde não - basta remover a norma e colocar tudo isso em uma planilha do Excel. Ao mesmo tempo, vamos ver como você pode alterar a fonte, o alinhamento e outras insignificâncias no texto usando python.
Para um exemplo que alimenta nosso programa futuro, extraímos do K + as alterações na Lei "On JSC". Essa lei é frequentemente alterada, portanto haverá trabalho a ser feito.
Salve as alterações em um arquivo txt comum (por exemplo, a edição de .txt). Você obtém algo como o seguinte:

Portanto, fica claro que cada alteração é separada da outra por uma linha sólida que, após salvar, assumiu a forma de numerosos “???”. Há também um cabeçalho de alteração a ser considerado. Tudo parece simples, exceto em certos pontos.
Portanto, encontre alterações que tenham o seguinte formato:

Além disso, o assunto é agravado pelo fato de que alterações individuais diferem significativamente em comprimento.
Prosseguimos para o K +.
Crie um novo arquivo consult.py e adicione as primeiras linhas:
from __future__ import unicode_literals import codecs import openpyxl
O módulo openpyxl já é familiar, permite que você trabalhe com o Excel, mas os outros dois são novos. Sua função é processar corretamente caracteres russos, que geralmente são lidos incorretamente pelos programas.
Com antecedência, crie um novo arquivo excel vazio fora do programa, nomeando-o, por exemplo, revision2.xlsx. Vamos abrir esse arquivo com o nosso programa e gravar os dados lá. Este será o nosso arquivo final.
Portanto, o programa abre o arquivo excel e o insere:
wb = openpyxl.load_workbook('2.xlsx') sheet=wb.get_active_sheet() x=1 y=0 test=[] test2=[] test3=[]
Também acima, criamos 3 listas vazias onde coletamos dados: test, test2, test3.
Em seguida, na variável 'a', colocaremos tudo o que pode cair na forma do nome da mudança. Em y - haverá uma linha divisória. É o mesmo comprimento:
a=('','','','','','','') y='?????????????????????????????????????????????????????????????????????????'
Agora a parte divertida.
with open ('.txt',encoding='cp1251') as f: lines = (line.strip() for line in f) for line in lines: if line.startswith(''): continue col1=line[:35] col2=line[39:] col3=line[35:39] if line.startswith(a): sheet.cell(row=x, column=1).value=line
Abrimos o arquivo .txt codificado em cp1251. Cada linha foi limpa de espaços desde o final e o começo pelo método strip.
Se a linha começar com a palavra "antigo", nós a ignoramos. Por que precisamos manter o "velho" e o "novo", isso já está claro. Em seguida, dividimos a linha: do início para 35 caracteres e de 39 para o final. Ou seja, eliminamos a lacuna no meio:

Colocamos o conteúdo do espaço no meio da linha em col3, porque pode não ser um espaço se a alteração for escrita em uma linha em uma linha:

Além disso, se a linha começa com o cabeçalho de alteração (escrevemos esses cabeçalhos na variável a), escrevemos imediatamente essa linha para o Excel sem divisão e adicionamos a linha - x + = 1 (ou x = x + 1). que encontramos, sentimos falta.
Considere o seguinte snippet de código:
if len(col2)==0:
Se o comprimento de 2 partes da sequência for 0, ou seja, ele não existir, test2 obterá a primeira parte da sequência. Se houver um espaço na linha, mas a segunda parte da linha estiver ausente, a primeira e a segunda parte da linha, respectivamente, serão testadas e testadas2.
Se houver um espaço na linha, e a linha não estiver vazia e seu comprimento tiver mais de 60 caracteres, ele será adicionado ao teste3.
Se a linha estiver vazia, ou seja, passamos por toda a alteração, escrevemos tudo o que coletamos nas células do Excel, verificando simultaneamente o vazio no teste (para que não fique vazio) e a duração do teste3.
Por fim, salve o arquivo excel:
wb.save('2.xlsx')
Estilos, alinhamento de fonte e texto em python
Adicione um pouco de beleza à nossa mesa.
Em particular, faremos com que, ao enviar dados, os cabeçalhos de mudança sejam destacados em negrito e o texto em si seja menor e formatado para facilitar a leitura.
Python permite que você faça isso. Para fazer isso, precisamos adicionar e alterar o código nos locais em que registramos os resultados em um arquivo do Excel:
from openpyxl.styles import Font, Color,NamedStyle, Alignment
al= Alignment(horizontal="justify", vertical="top") ft = Font(name='Calibri', size=9) ft2 = Font(name='Calibri', size=9,bold=True)
if line.startswith(a): sheet.cell(row=x, column=1).value=line
if line==y:
if len(test3)>0:
Na verdade, apenas adicionamos os métodos aplicáveis .font e .alignment.
Todo o programa assumiu a forma:
Código from __future__ import unicode_literals import codecs import openpyxl from openpyxl.styles import Font, Color,NamedStyle, Alignment """ 1. Consultant+ , .txt ????????????????????????????????????????????????????????????????????????? 15 1 48 15) 15) excel . word - txt : .txt : 2.xlsx """
Portanto, no final, depois de processar o arquivo pelo programa, temos uma tabela bastante decente com alterações na lei:
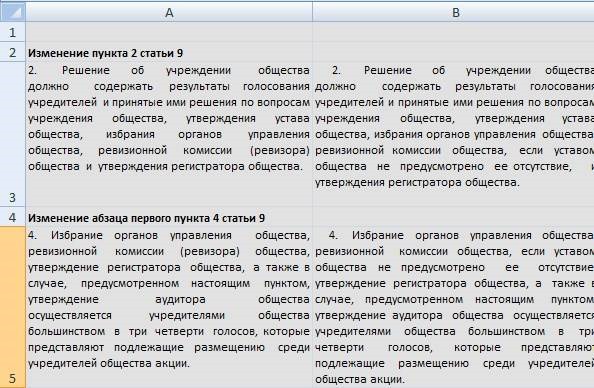
O programa pode ser baixado no link -
aqui .
Um arquivo de exemplo para processamento pelo programa está
aqui .