O novo trabalho do Google oferece uma arquitetura de redes neurais que podem simular os instintos e reflexos inatos dos seres vivos, seguidos de treinamento adicional ao longo da vida.
E também reduzindo significativamente o número de conexões na rede, aumentando sua velocidade.
As redes neurais artificiais, embora semelhantes em princípio às biológicas, ainda são muito diferentes delas para serem usadas em sua forma pura para criar uma IA forte. Por exemplo, agora é impossível criar um modelo de pessoa em um simulador (ou um mouse ou até mesmo um inseto), dar a ele um “cérebro” na forma de uma rede neural moderna e treiná-lo. Isso simplesmente não funciona.
Mesmo tendo descartado as diferenças no mecanismo de aprendizagem (no cérebro, não existe um análogo exato do algoritmo de propagação de erro de retorno, por exemplo) e a falta de correlações de tempo em várias escalas, com base nas quais o cérebro biológico constrói seu trabalho, as redes neurais artificiais têm vários outros problemas que não permitem simular suficientemente cérebro vivo. É provável que, devido a esses problemas inerentes ao aparato matemático usado agora, o Aprendizado por Reforço, projetado para imitar o máximo possível o treinamento de seres vivos com base na recompensa, na prática não funcione tão bem quanto gostaríamos. Embora seja baseado em idéias realmente boas e corretas. Os próprios desenvolvedores brincam que o cérebro é RNN + A3C (ou seja, uma rede recorrente + algoritmo crítico de ator para seu treinamento).
Uma das diferenças mais notáveis entre o cérebro biológico e as redes neurais artificiais é que a estrutura do cérebro vivo é pré-configurada por milhões de anos de evolução. Embora o neocórtex, responsável pela maior atividade nervosa nos mamíferos, tenha uma estrutura aproximadamente uniforme, a estrutura geral do cérebro é claramente definida pelos genes. Além disso, outros animais que não os mamíferos (pássaros, peixes) não possuem um neocórtex, mas ao mesmo tempo exibem um comportamento complexo que não é alcançável pelas redes neurais modernas. Uma pessoa também tem limitações físicas na estrutura do cérebro, que são difíceis de explicar. Por exemplo, a resolução de um olho é de aproximadamente 100 megapixels (~ 100 milhões de hastes e cones fotossensíveis), o que significa que, por dois olhos, o fluxo de vídeo deve ter cerca de 200 megapixels com uma frequência de pelo menos 15 quadros por segundo. Mas, na realidade, o nervo óptico é capaz de passar por si mesmo não mais do que 2-3 megapixels. E suas conexões são direcionadas não à parte mais próxima do cérebro, mas à parte occipital ao córtex visual.
Portanto, sem prejudicar a importância do neocórtex (grosso modo, pode ser considerado no nascimento como um análogo das redes neurais modernas iniciadas aleatoriamente), os fatos sugerem que mesmo uma pessoa desempenha um papel enorme em uma estrutura cerebral predeterminada. Por exemplo, se um bebê tiver apenas alguns minutos para mostrar sua língua, graças aos neurônios-espelho, ele também ficará com a língua para fora. O mesmo acontece com o riso das crianças. É sabido que os bebês desde o nascimento foram “costurados” com excelente reconhecimento dos rostos humanos. Mais importante, porém, o sistema nervoso de todos os seres vivos é otimizado para suas condições de vida. O bebê não chorará por horas se estiver com fome. Ele vai se cansar. Ou com medo de alguma coisa e cale a boca. A raposa não alcançará a exaustão até que a fome atinja uvas inacessíveis. Ela fará várias tentativas, decide que ele é amargo e vai embora. E este não é um processo de aprendizado, mas um comportamento predefinido pela biologia. Além disso, diferentes espécies têm diferentes. Alguns predadores correm imediatamente para presas, enquanto outros ficam emboscados por um longo tempo. E eles aprenderam isso não por tentativa e erro, mas essa é sua biologia, dada por instintos. Da mesma forma, muitos animais usaram programas de prevenção de predadores desde os primeiros minutos de vida, embora ainda não pudessem aprendê-los fisicamente.
Teoricamente, métodos modernos de treinamento de redes neurais são capazes de criar uma semelhança com um cérebro pré-treinado, zerando conexões desnecessárias (de fato, cortando-as) e deixando apenas as necessárias. Mas isso requer um grande número de exemplos, não se sabe como treiná-los e, o que é mais importante - no momento não há boas maneiras de consertar essa estrutura "inicial" do cérebro. O treinamento subsequente altera esses pesos e tudo dá errado.
Pesquisadores do Google também fizeram essa pergunta. É possível criar uma estrutura cerebral inicial semelhante à biológica, isto é, já bem otimizada para resolver o problema e depois apenas treiná-lo novamente? Teoricamente, isso reduzirá drasticamente o espaço de soluções e permitirá que você treine rapidamente redes neurais.
Infelizmente, os algoritmos de otimização da estrutura de rede existentes, como o Neural Architecture Search (NAS), operam em blocos inteiros. Depois de adicionar ou remover qual, a rede neural deve ser treinada novamente do zero. Este é um processo que consome muitos recursos e não resolve completamente o problema.
Portanto, os pesquisadores propuseram uma versão simplificada, denominada "Redes Neurais Agnósticas por Peso" (WANN). A idéia é substituir todos os pesos de uma rede neural por um peso "comum". E no processo de aprendizado, não é selecionar pesos entre os neurônios, como nas redes neurais comuns, mas selecionar a estrutura da própria rede (o número e a localização dos neurônios), que com os mesmos pesos mostra os melhores resultados. E depois disso, otimize-o para que a rede funcione bem com todos os valores possíveis desse peso total (comum para todas as conexões entre neurônios!).
Como resultado, isso fornece a estrutura de uma rede neural, que não depende de pesos específicos, mas funciona bem com todos. Porque funciona devido à estrutura geral da rede. Isso é semelhante ao cérebro de um animal que ainda não foi inicializado com escalas específicas no nascimento, mas que já contém instintos incorporados devido à sua estrutura geral. E o subsequente ajuste fino das escalas durante o treinamento ao longo da vida torna essa rede neural ainda melhor.
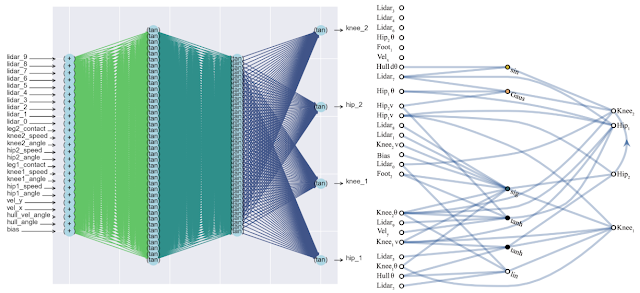
Um efeito colateral positivo dessa abordagem é uma diminuição significativa no número de neurônios na rede (uma vez que permanecem apenas as conexões mais importantes), o que aumenta sua velocidade. Abaixo está uma comparação da complexidade de uma rede neural clássica totalmente conectada (esquerda) e de uma nova rede correspondente (direita).
Para procurar por essa arquitetura, os pesquisadores usaram o algoritmo de busca de topologia (NEAT). Primeiro, um conjunto de redes neurais simples é criado e, em seguida, é executada uma das três ações: um novo neurônio é adicionado à conexão existente entre dois neurônios, uma nova conexão com os aleatórios é adicionada a outro neurônio ou a função de ativação no neurônio muda (veja as figuras abaixo). E então, ao contrário do NAS clássico, onde são pesquisados pesos ótimos entre os neurônios, aqui todos os pesos são inicializados com um único número. E a otimização é realizada para encontrar a estrutura de rede que funciona melhor em uma ampla gama de valores desse peso total. Assim, é obtida uma rede que não depende do peso específico entre os neurônios, mas funciona bem em toda a faixa (mas todos os pesos ainda são iniciados por um número e não são diferentes dos das redes normais). Além disso, como objetivo adicional de otimização, eles tentam minimizar o número de neurônios na rede.
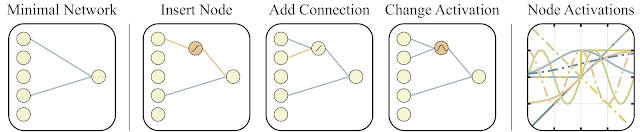
Abaixo está um esboço geral do algoritmo.
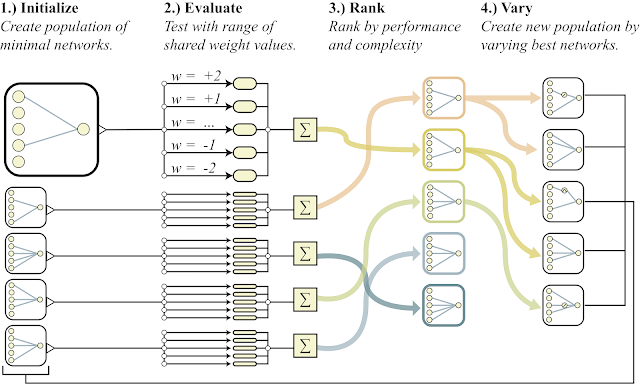
- cria uma população de redes neurais simples
- cada rede inicializa todos os seus pesos com um número e para uma ampla variedade de números: w = -2 ... + 2
- as redes resultantes são classificadas pela qualidade da solução do problema e pelo número de neurônios (abaixo)
- na parte dos melhores representantes, um neurônio é adicionado, uma conexão ou a função de ativação em um neurônio muda
- estas redes modificadas são usadas como iniciais no ponto 1)
Tudo isso é bom, mas centenas, senão milhares de idéias diferentes foram propostas para redes neurais. Isso funciona na prática? Sim sim. Abaixo está um exemplo do resultado da pesquisa dessa arquitetura de rede para o problema clássico do carrinho pendular. Como pode ser visto na figura, a rede neural funciona bem com todas as variantes do peso total (melhor com +1,0, mas também tenta levantar o pêndulo de -1,5). E depois de otimizar esse peso único, ele começa a funcionar perfeitamente perfeitamente (opção Pesos ajustados na figura).
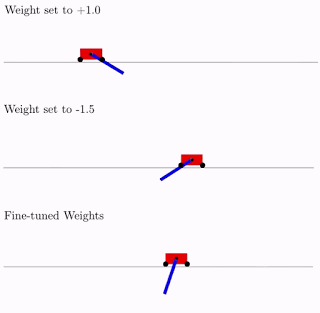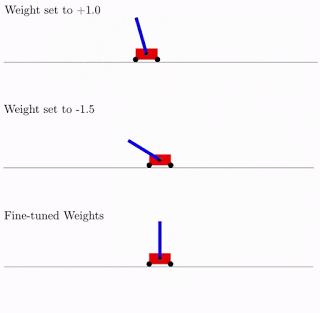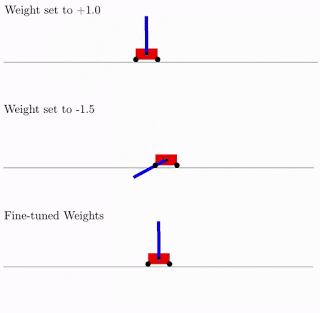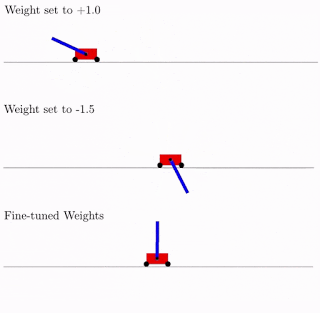
Normalmente, você pode treinar novamente esse peso total único, já que a seleção da arquitetura é feita em um número discreto limitado de parâmetros (no exemplo acima -2, -1,1,2). E você pode obter um parâmetro ideal mais preciso, digamos, 1,5. E você pode usar o melhor peso total como ponto de partida para a reciclagem de todos os pesos, como no treinamento clássico de redes neurais.
Isso é semelhante a como os animais são treinados. Tendo instintos próximos do ideal no nascimento, e usando essa estrutura cerebral dada pelos genes como inicial, durante o curso de sua vida, os animais treinam seu cérebro em condições externas específicas. Mais detalhes em um artigo recente na revista Nature .
Abaixo está um exemplo de uma rede encontrada pela WANN para uma tarefa de controle de máquina baseada em pixel. Observe que este é um passeio nos "instintos desencapados", com o mesmo peso total em todas as articulações, sem o ajuste fino clássico de todos os pesos. Ao mesmo tempo, a rede neural é extremamente simples em estrutura.
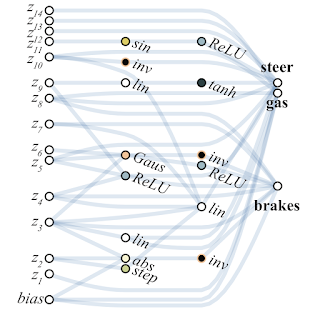

Os pesquisadores sugerem a criação de conjuntos de redes da WANN como outro caso de uso para a WANN. Assim, a rede neural usual inicializada aleatoriamente no MNIST mostra uma precisão de cerca de 10%. Uma rede neural única selecionada da WANN gera cerca de 80%, mas um conjunto da WANN com pesos totais diferentes já mostra> 90%.
Como resultado, o método proposto pelos pesquisadores do Google para procurar a arquitetura inicial de uma rede neural ideal não apenas imita a aprendizagem animal (nascimento com instintos ótimos internos e reciclagem na vida), mas também evita a simulação de toda a vida animal com o aprendizado completo de toda a rede nos algoritmos evolutivos clássicos, criando Redes simples e rápidas de uma só vez. O que é suficiente apenas para treinar um pouco para obter uma rede neural totalmente ideal.
Referências
- Entrada de blog do Google AI
- Um artigo interativo no qual você pode alterar o peso total e monitorar o resultado
- Artigo da Nature sobre a importância dos instintos incorporados no nascimento