Decidi compartilhá-lo, mas eu não esqueceria como ferramentas estatísticas simples podem ser usadas para analisar dados. Uma pesquisa anônima foi usada como exemplo em relação a salários, tempo de serviço e posições de programadores ucranianos em 2014 e 2019. (1)
Etapas de análise
- Pré-processamento de dados e análise preliminar ( qualquer pessoa interessada no código aqui )
- Uma representação gráfica dos dados. Função densidade de distribuição.
- Formulamos a hipótese nula (H0) (2)
- Escolha uma métrica para análise
- Usamos o método de inicialização para formar uma nova matriz de dados.
- Calculamos o valor p (3) para confirmar ou refutar a hipótese
Pré-processamento de dados
Após algumas manipulações (o
código está aqui ), apresentamos os dados da seguinte forma:
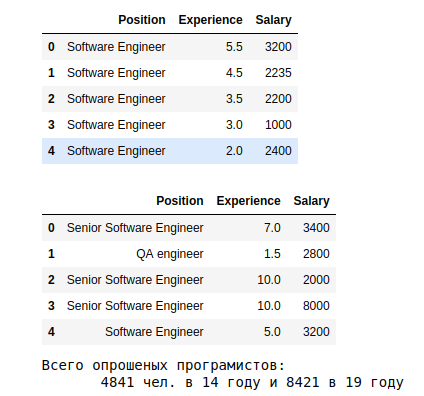
Um pouco mais de agrupamentos por um ano (deixe o dia 19):

As primeiras estimativas são as seguintes.
a. Os resultados mostram que, em média, em 19, aqueles que trabalham há mais de 10 anos recebem mais de 3,5 mil. A dependência da experiência -> zp
c. Média s.p. em 19, dependendo da especialização, eles mostram um spread de 10 vezes - de 5k para o System Architect a 575 para Junior QA.
s A última placa mostra a distribuição por profissão. A maioria dos dados sobre engenheiro de software, sem qualificação.
Chamamos atenção para as características do 19º ano: Algo está errado com o 9º ano de experiência e não há classificação de acordo com os níveis de junior, middle e senior. Você pode entender melhor as razões para o outlier do nono ano. Mas para esta análise, nós a tomamos como é.
Mas com as categorias - vale a pena resolver. em 19, o engenheiro de software 2739 pessoas (35% do total) sem indicar o nível de qualificação. Vamos calcular a média e os desvios para quem indicou.
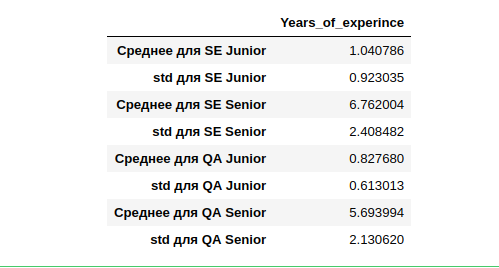
Acontece que a experiência média de trabalho (quem a indicou) para o SE Junior é de um ano, com um desvio bastante amplo de um ano. O SE Senior tem mais experiência com um desvio de 2,4 anos igualmente grande.
Se tentarmos calcular o Médio e usar a experiência média daqueles que o indicaram, para categorizar quem não o indicou, talvez não agrupemos corretamente a amostra inteira. Cometeremos erros especialmente em outras especialidades (não SE e QA), ou seja, poucos dados. Além disso, existem poucos deles para comparação com o 14º ano.
O que mais posso usar?
Vamos considerar apenas o nível salarial como um indicador confiável do nível de habilidade! (Eu acho que haverá divergências).
Primeiro, construímos a aparência da distribuição de salários para o 19º ano.
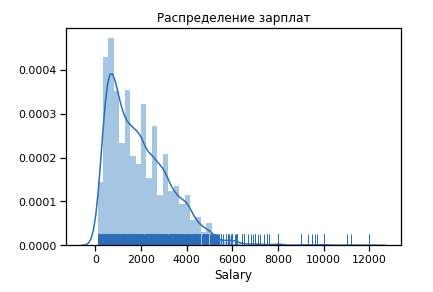
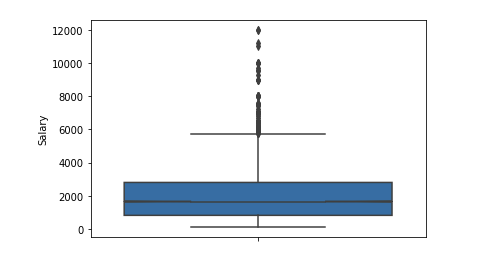
Outliers número significativo após 6 $ k. Deixamos o intervalo de limitações [400 - 4000]. Qualquer programador deve ter mais de 400 :)
df_new = data_19_1[(data_19_1['Salary'] > 400) & (data_19_1['Salary'] < 4000)] sns.distplot(df_new['Salary'], rug=True, norm_hist=True)
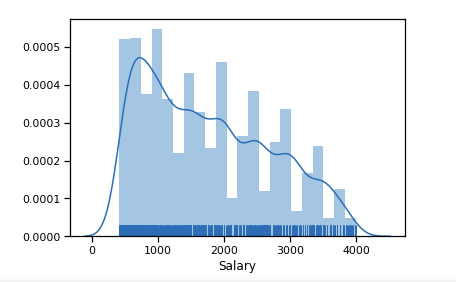
Já um pouco mais perto da distribuição normal.
Compomos por 19 anos, níveis de habilidade dependendo da RFP. A faixa de US $ 3600 nos dá um bom divisor em 3 categorias - US $ 1200
df_new.reset_index() df_new.loc['level'] = 0 df_new.loc[df_new.Salary <= 1200, 'level'] = 'Junior' df_new.loc[(df_new.Salary > 1200) & (df_new.Salary <= 2400), 'level'] = 'Middle' df_new.loc[df_new.Salary > 2401, 'level'] = 'Senior'
Draw - densidade da categoria por 19 anos.
sns.set(style="whitegrid") fig, ax = plt.subplots() fig.set_size_inches(11.7, 8.27) plt.title(' 19 ') sns.barplot(x='level', y='Salary', hue='Experience', hue_order=[1,3,5,7,10], palette='Blues', \ data=df_new, ci='sd')

Ao adicionar a quantidade especificada de experiência (canto esquerdo), você pode ver diferentes nuances. Por exemplo, em média, Junior chega a 1k e sua experiência de trabalho é de 5 anos. A maior dispersão no sn em Senior (uma linha curta preta no topo de cada coluna) e muitos outros detalhes interessantes.
É aqui que os dois primeiros estágios terminam, procedemos ao teste de hipóteses usando o bootstraping.
Formulamos a hipótese nula (H0)
Nos primeiros estágios, descobrimos que a experiência profissional especificada não significa com muita precisão o nível de qualificação. Em seguida, formamos a hipótese nula (aquela que precisa ser refutada)
Existem muitas opções (por exemplo):
- A dependência salarial da antiguidade no ano 14 é igual à do 19.
- Os salários dos juniores não mudam desde 14 anos.
No entanto, como a experiência indicada é um indicador ruim e o cálculo para determinadas categorias pode ser confuso, adotamos uma opção simples e mais substantiva: o
nível médio de sn em 14, o mesmo que em 19, é nossa hipótese nula H0 (2).
Ou seja, assumimos que os salários de 5 anos não mudaram.
NÃO a fidelidade da hipótese, apesar de toda a sua obviedade, podemos verificar com precisão calculando o valor-P da hipótese nula.
O salário médio no ano 14 é de US $ 1797, onde o intervalo de confiança é de 95% [300,0 4000,0]
O salário médio em 19 é $ 1949, onde o intervalo de confiança é de 95% [300.0 5000.0]
A diferença nos salários médios nos anos 14 e 19: US $ 152
Métrica para análise
É lógico escolher os valores médios como nossa métrica. Outras opções são possíveis, por exemplo, a mediana, que geralmente é feita no caso de um número significativo de discrepantes. No entanto, a média como estimativa é fácil de entender e também fornece uma boa ideia.
Escrevendo uma função de inicialização.
Nós calculamos nossas estatísticas.
Valor p = 0,0
Valores de p de até 0,05 são considerados insignificantes e, no nosso caso, são iguais a 0. O que significa que a hipótese nula é
refutada - o salário médio nos anos 14 e 19 é diferente e esse não é um resultado acidental ou um número significativo de discrepantes.
Geramos 10 mil dessas matrizes, em média, não puderam obter um total de mais desses destacamentos do que os próprios dados.
Embora tenhamos dedicado muita atenção nos dois primeiros estágios, formulamos a hipótese correta e escolhemos a métrica correta. Em tarefas mais complexas, com um grande número de variáveis, sem essas etapas preliminares, a análise pode levar a uma interpretação incorreta. Não os pule.
Como resultado de nosso estudo do nível de salários de 14 e 19 anos, chegamos às seguintes conclusões:
- Com base nos dados da pesquisa, a experiência especificada não é um critério inteiramente adequado para determinar o nível de salários e qualificações.
- A divisão no nível de habilidade provavelmente será baseada no nível de salários.
- Os salários dos programadores aumentaram de 14 para 19 (uma média de 8,5%) e isso não é um resultado acidental.
Obrigado pela atenção. Ficarei feliz em fazer comentários e críticas.
Fontes
- https://jobs.dou.ua/salaries/ (resultados da pesquisa)
- https://en.wikipedia.org/wiki/Null_hypothesis
- https://en.wikipedia.org/wiki/P-value