
Nos dias em que o Kubernetes ainda estava na v1.0.0, existiam plug-ins de volume. Eles eram necessários para se conectar aos sistemas Kubernetes para armazenar dados de contêiner persistentes (permanentes). Seu número era pequeno e entre os primeiros havia fornecedores de armazenamento como GCE PD, Ceph, AWS EBS e outros.
Os plug-ins foram entregues juntamente com o Kubernetes, para o qual eles receberam seu nome - na árvore. No entanto, muitos dos conjuntos existentes desses plug-ins não eram suficientes. Os artesãos adicionaram plugins simples ao núcleo do Kubernetes usando patches, depois dos quais eles construíram seu próprio Kubernetes e o colocaram em seus servidores. Mas com o tempo, os desenvolvedores do Kubernetes perceberam que o
peixe não podia ser resolvido. As pessoas precisam de uma
vara de pescar . E no lançamento do Kubernetes v1.2.0, ele apareceu ...
Plug-in Flexvolume: vara de pesca mínima
Os desenvolvedores do Kubernetes criaram o plug-in FlexVolume, que era uma ligação lógica de variáveis e métodos para trabalhar com drivers Flexvolume de terceiros.
Vamos parar e dar uma olhada no que é o driver FlexVolume. Esse é um determinado
arquivo executável (
arquivo binário, script Python, script Bash etc.) que, quando executado, recebe argumentos de linha de comando e retorna uma mensagem com campos conhecidos anteriormente no formato JSON. Por convenção, o primeiro argumento da linha de comando é sempre o método, e o restante dos argumentos são seus parâmetros.
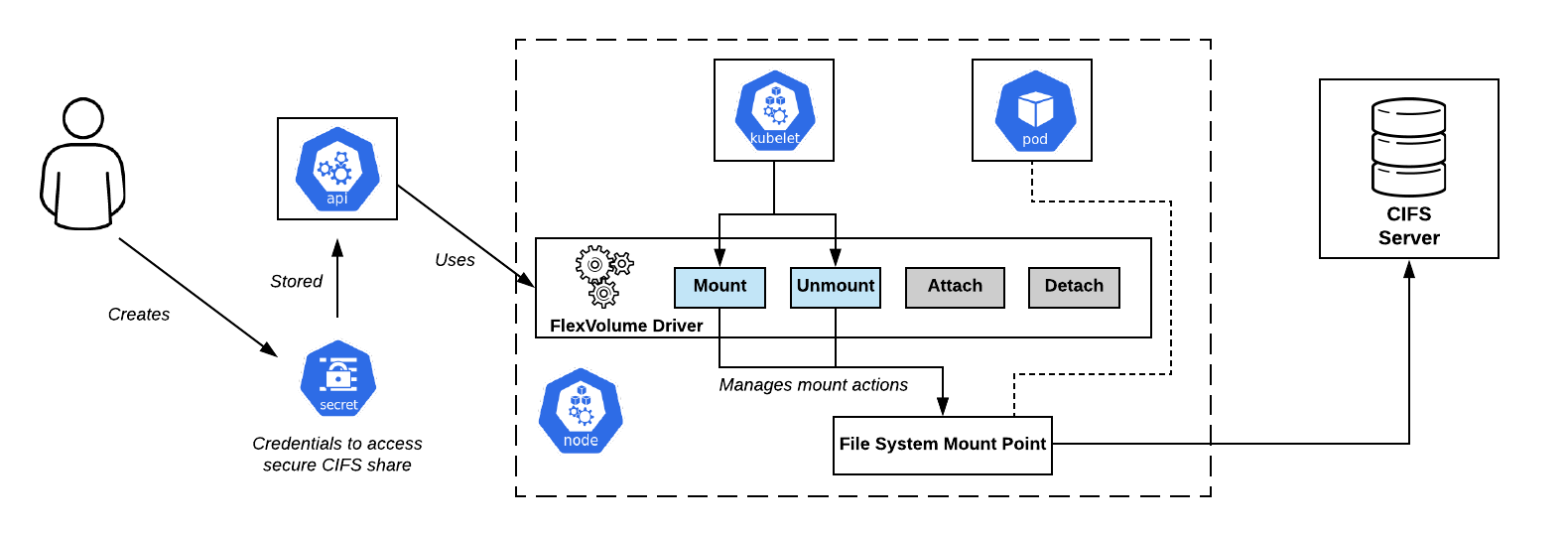 CIFS Compartilha o esquema de conexão no OpenShift. Driver Flexvolume - Bem no centroO conjunto mínimo de métodos se
CIFS Compartilha o esquema de conexão no OpenShift. Driver Flexvolume - Bem no centroO conjunto mínimo de métodos se parece com isso:
flexvolume_driver mount # pod' # : { "status": "Success"/"Failure"/"Not supported", "message": " ", } flexvolume_driver unmount # pod' # : { "status": "Success"/"Failure"/"Not supported", "message": " ", } flexvolume_driver init # # : { "status": "Success"/"Failure"/"Not supported", "message": " ", // , attach/deatach "capabilities":{"attach": True/False} }
O uso dos métodos
attach e
detach determinará o cenário segundo o qual no futuro o kubelet atuará quando o driver for chamado. Também existem
expandfs especiais
expandvolume e
expandfs que são responsáveis por redimensionar dinamicamente um volume.
Como um exemplo das alterações que o método
expandvolume e, com ele, a capacidade de redimensionar o volume em tempo real, você pode conferir
nossa solicitação de recebimento no operador da torre Rook.
Aqui está um exemplo de implementação do driver Flexvolume para trabalhar com o NFS:
usage() { err "Invalid usage. Usage: " err "\t$0 init" err "\t$0 mount <mount dir> <json params>" err "\t$0 unmount <mount dir>" exit 1 } err() { echo -ne $* 1>&2 } log() { echo -ne $* >&1 } ismounted() { MOUNT=`findmnt -n ${MNTPATH} 2>/dev/null | cut -d' ' -f1` if [ "${MOUNT}" == "${MNTPATH}" ]; then echo "1" else echo "0" fi } domount() { MNTPATH=$1 NFS_SERVER=$(echo $2 | jq -r '.server') SHARE=$(echo $2 | jq -r '.share') if [ $(ismounted) -eq 1 ] ; then log '{"status": "Success"}' exit 0 fi mkdir -p ${MNTPATH} &> /dev/null mount -t nfs ${NFS_SERVER}:/${SHARE} ${MNTPATH} &> /dev/null if [ $? -ne 0 ]; then err "{ \"status\": \"Failure\", \"message\": \"Failed to mount ${NFS_SERVER}:${SHARE} at ${MNTPATH}\"}" exit 1 fi log '{"status": "Success"}' exit 0 } unmount() { MNTPATH=$1 if [ $(ismounted) -eq 0 ] ; then log '{"status": "Success"}' exit 0 fi umount ${MNTPATH} &> /dev/null if [ $? -ne 0 ]; then err "{ \"status\": \"Failed\", \"message\": \"Failed to unmount volume at ${MNTPATH}\"}" exit 1 fi log '{"status": "Success"}' exit 0 } op=$1 if [ "$op" = "init" ]; then log '{"status": "Success", "capabilities": {"attach": false}}' exit 0 fi if [ $# -lt 2 ]; then usage fi shift case "$op" in mount) domount $* ;; unmount) unmount $* ;; *) log '{"status": "Not supported"}' exit 0 esac exit 1
Portanto, depois de preparar o arquivo executável real, você precisa
dispor o driver no cluster Kubernetes . O driver deve estar localizado em cada nó do cluster de acordo com um caminho predefinido. Por padrão, foi selecionado:
/usr/libexec/kubernetes/kubelet-plugins/volume/exec/__~_/... mas usando diferentes distribuições Kubernetes (OpenShift, Rancher ...), o caminho pode ser diferente.
Problemas de flexvolume: como lançar uma vara de pescar?
Colocar o driver Flexvolume nos nós do cluster acabou sendo uma tarefa não trivial. Depois de executar a operação manualmente, é fácil encontrar uma situação em que novos nós aparecem no cluster: devido à adição de um novo nó, escalonamento horizontal automático ou, pior, substituindo o nó devido a um mau funcionamento. Nesse caso, é
impossível trabalhar com o armazenamento nesses nós até você adicionar manualmente o driver Flexvolume a eles da mesma maneira.
A solução para esse problema foi uma das primitivas do Kubernetes -
DaemonSet . Quando um novo nó aparece no cluster, ele obtém automaticamente um pod do nosso DaemonSet, ao qual um volume local é anexado ao longo do caminho para encontrar drivers Flexvolume. Após a criação bem-sucedida, o pod copia os arquivos necessários para o driver trabalhar no disco.
Aqui está um exemplo de um DaemonSet para o layout do plug-in Flexvolume:
apiVersion: extensions/v1beta1 kind: DaemonSet metadata: name: flex-set spec: template: metadata: name: flex-deploy labels: app: flex-deploy spec: containers: - image: <deployment_image> name: flex-deploy securityContext: privileged: true volumeMounts: - mountPath: /flexmnt name: flexvolume-mount volumes: - name: flexvolume-mount hostPath: path: <host_driver_directory>
... e um exemplo de script Bash para o layout de um driver Flexvolume:
É importante não esquecer que a operação de cópia
não é
atômica . É muito provável que o kubelet comece a usar o driver antes que o processo de preparação seja concluído, o que causará um erro no sistema. A abordagem correta seria primeiro copiar os arquivos do driver com um nome diferente e depois usar a operação de renomeação atômica.
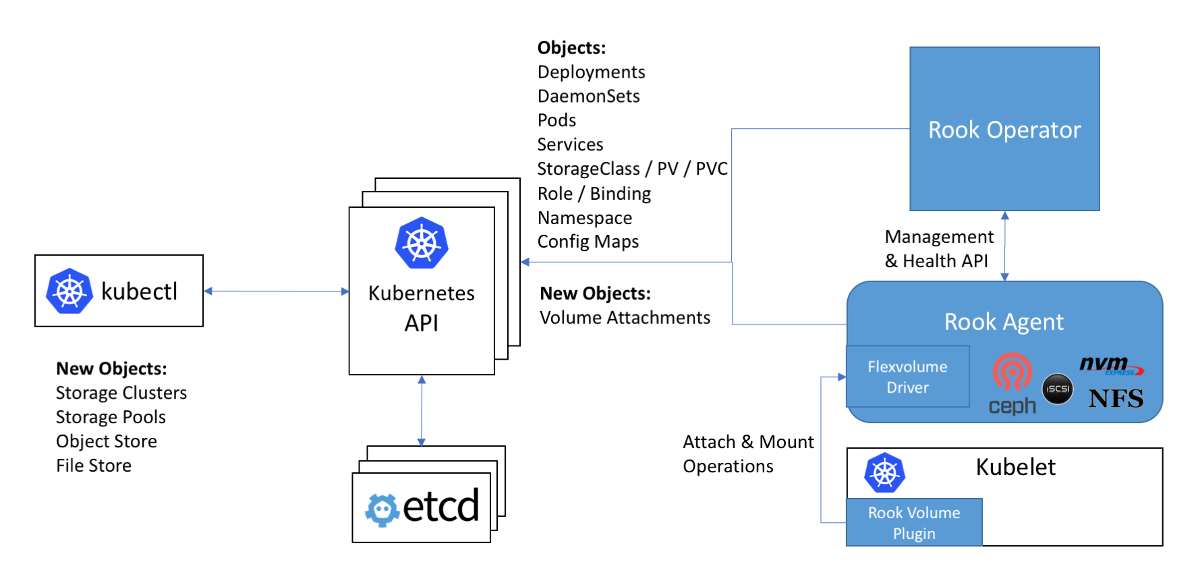 Esquema de trabalho com Ceph na instrução Rook: o driver Flexvolume no diagrama está dentro do agente Rook
Esquema de trabalho com Ceph na instrução Rook: o driver Flexvolume no diagrama está dentro do agente RookO próximo problema ao usar drivers Flexvolume é que, para a maioria dos armazenamentos
, o software necessário para isso deve ser instalado no nó do cluster (por exemplo, o pacote ceph-common para Ceph). Inicialmente, o plug-in Flexvolume não foi projetado para implementar sistemas tão complexos.
Uma solução original para esse problema pode ser vista na implementação do driver Flexvolume do operador Rook:
O driver em si foi projetado como um cliente RPC. O soquete IPC para comunicação está no mesmo diretório que o próprio driver. Lembramos que, para copiar arquivos de driver, seria bom usar o DaemonSet, que conecta um diretório ao driver como um volume. Após copiar os arquivos necessários do driver da torre, esse pod não morre, mas se conecta ao soquete IPC através do volume conectado como um servidor RPC completo. O pacote ceph-common já está instalado dentro do contêiner de pod. O soquete IPC garante que o kubelet se comunique com o pod específico localizado no mesmo nó. Tudo engenhoso é simples! ..
Adeus, nossos carinhosos ... plugins in-tree!
Os desenvolvedores do Kubernetes descobriram que o número de plugins de armazenamento dentro do kernel é de vinte. E a mudança em cada um deles, de alguma forma, passa pelo ciclo completo de lançamento do Kubernetes.
Acontece que, para usar a nova versão do plug-in para armazenamento,
é necessário atualizar o cluster inteiro . Além disso, você pode se surpreender com o fato de a nova versão do Kubernetes se tornar repentinamente incompatível com o kernel Linux usado ... E, portanto, você enxuga as lágrimas e range os dentes e coordena com as autoridades e usuários o tempo para atualizar o kernel Linux e o cluster Kubernetes. Com possível tempo de inatividade na prestação de serviços.
A situação é mais do que cômica, não é? Ficou claro para toda a comunidade que a abordagem não funcionou. Com uma decisão decidida, os desenvolvedores do Kubernetes anunciam que novos plugins de armazenamento não serão mais aceitos no kernel. Para todo o resto, como já sabemos, na implementação do plugin Flexvolume, várias deficiências foram reveladas ...
De uma vez por todas, o último plugin adicionado para volumes em Kubernetes, CSI, foi chamado para fechar o problema com data warehouses persistentes. Sua versão alfa, mais comumente chamada de Plugins de volume CSI fora da árvore, foi anunciada no
Kubernetes 1.9 .
Interface de armazenamento de contêiner, ou CSI 3000 girando!
Antes de tudo, gostaria de observar que o CSI não é apenas um plug-in de volume, mas um
padrão real
para criar componentes personalizados para trabalhar com data warehouses . Supunha-se que os sistemas de orquestração de contêineres, como Kubernetes e Mesos, deveriam “aprender” como trabalhar com componentes implementados de acordo com este padrão. E agora o Kubernetes já aprendeu.
Qual é o dispositivo do plug-in CSI no Kubernetes? O plug-in CSI funciona com drivers especiais (
drivers CSI ) criados por desenvolvedores de terceiros. O driver CSI no Kubernetes deve consistir em pelo menos dois componentes (pods):
- Controlador - gerencia o armazenamento persistente externo. É implementado como um servidor gRPC para o qual a primitiva
StatefulSet é usada. - Nó - é responsável pela montagem de armazenamentos persistentes nos nós do cluster. Também é implementado como um servidor gRPC, mas a primitiva
DaemonSet é usada para ele.
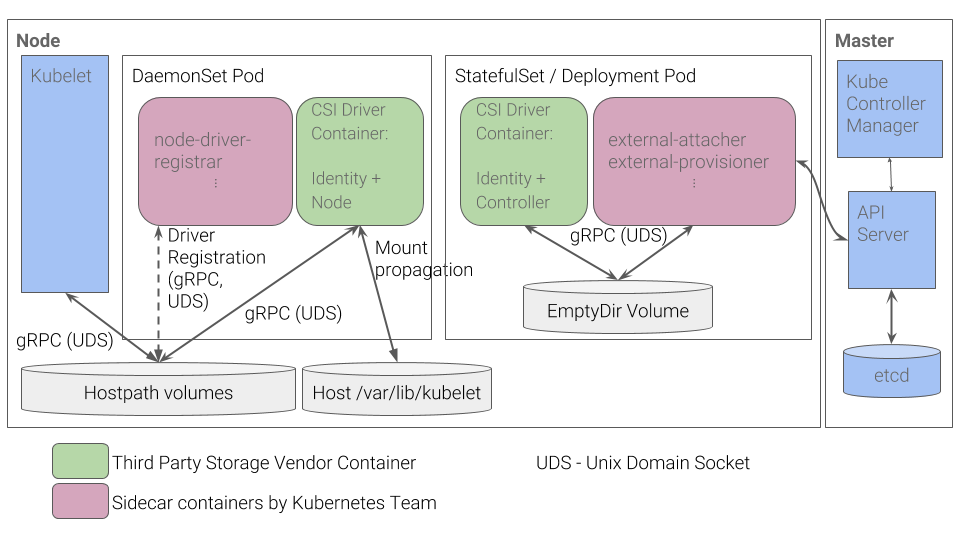 Fluxo de trabalho do plug-in CSI do Kubernetes
Fluxo de trabalho do plug-in CSI do KubernetesVocê pode aprender sobre alguns outros detalhes do CSI, por exemplo, no artigo “
Entendendo o CSI ”, uma
tradução que publicamos um ano atrás.
As vantagens de tal implementação
- Para coisas básicas - por exemplo, para registrar um driver para um nó - os desenvolvedores do Kubernetes implementaram um conjunto de contêineres. Você não precisa mais criar uma resposta JSON com recursos, como foi feito para o plug-in Flexvolume.
- Em vez de "deslizar" os nós dos arquivos executáveis, agora organizamos os pods no cluster. Isso é o que esperávamos originalmente do Kubernetes: todos os processos ocorrem dentro de contêineres implantados usando as primitivas do Kubernetes.
- Para implementar drivers complexos, você não precisa mais desenvolver um servidor RPC e um cliente RPC. O cliente para nós foi implementado pelos desenvolvedores do Kubernetes.
- Passar argumentos para trabalhar com o protocolo gRPC é muito mais conveniente, flexível e mais confiável do que passá-los por argumentos de linha de comando. Para entender como adicionar suporte para métricas de uso de volume ao CSI, adicionando um método gRPC padronizado, verifique nossa solicitação de recebimento do driver vsphere-csi.
- A comunicação ocorre através dos soquetes do IPC para não confundir se o pod do kubelet enviou ou não uma solicitação.
Esta lista lembra qualquer coisa? As vantagens do CSI são a
solução para os mesmos problemas que não foram levados em consideração ao desenvolver o plug-in Flexvolume.
Conclusões
O CSI como padrão para implementar plug-ins personalizados para interagir com data warehouses foi muito calorosamente aceito pela comunidade. Além disso, devido às suas vantagens e versatilidade, os drivers CSI são criados mesmo para repositórios como Ceph ou AWS EBS, plug-ins para trabalhar com os quais foram adicionados na primeira versão do Kubernetes.
No início de 2019, os plug-ins em árvore
foram preteridos . Está planejado continuar suportando o plug-in Flexvolume, mas não haverá desenvolvimento de novas funcionalidades para ele.
Nós próprios já temos experiência com o ceph-csi, vsphere-csi e estamos prontos para adicionar a esta lista! Até agora, o CSI lida com as tarefas atribuídas a ele com um estrondo, e lá esperamos e vemos.
Não esqueça que tudo o que é novo é um pensamento bem repensado!
PS
Leia também em nosso blog: