Algum tempo atrás,
anunciamos um lançamento público e abrimos sob a licença MIT o código fonte do
LuaVela - uma implementação do Lua 5.1, baseada no LuaJIT 2.0. Começamos a trabalhar em 2015 e, no início de 2017, ele era usado em mais de 95% dos projetos da empresa. Agora eu quero olhar para trás no caminho percorrido. Que circunstâncias nos levaram a desenvolver nossa própria implementação de uma linguagem de programação? Que problemas encontramos e como os resolvemos? Qual a diferença entre LuaVela e outros garfos LuaJIT?
Antecedentes
Esta seção é baseada em nosso
relatório sobre o HighLoad ++. Começamos a usar Lua ativamente para escrever a lógica de negócios de nossos produtos em 2008. No início, era baunilha Lua, e desde 2009 - LuaJIT. O protocolo RTB possui uma estrutura rígida para processar a solicitação, portanto, mudar para uma implementação mais rápida da linguagem era uma solução lógica e, a partir de algum ponto, necessária.
Com o tempo, percebemos que havia certas limitações na arquitetura LuaJIT. O mais importante para nós foi que o LuaJIT 2.0 utiliza estritamente ponteiros de 32 bits. Isso nos levou a uma situação em que a execução no Linux de 64 bits limitava o tamanho do espaço de endereço virtual da memória do processo a um gigabyte (nas versões posteriores do kernel do Linux, esse limite era aumentado para dois gigabytes):
void *ptr = mmap((void *)MMAP_REGION_START, size, MMAP_PROT, MAP_32BIT | MMAP_FLAGS, -1, 0);
Essa limitação se tornou um grande problema - em 2015, 1-2 gigabytes de memória deixaram de ser suficientes para muitos projetos carregar os dados com os quais a lógica trabalhava. Vale ressaltar que cada instância da máquina virtual Lua é de thread único e não sabe como compartilhar dados com outras instâncias - isso significa que, na prática, cada máquina virtual pode reivindicar um tamanho de memória que não exceda 2 GB / n, onde n é o número de threads de trabalho do nosso servidor aplicações.
Passamos por várias soluções para o problema: reduzimos o número de threads em nosso servidor de aplicativos, tentamos organizar o acesso aos dados através do LuaJIT FFI, testamos a transição para o LuaJIT 2.1. Infelizmente, todas essas opções eram economicamente desvantajosas ou não foram bem dimensionadas a longo prazo. A única coisa que nos restava era arriscar e pegar o LuaJIT. Nesse momento, tomamos decisões que determinaram amplamente o destino do projeto.
Primeiro, decidimos imediatamente não fazer alterações na sintaxe e na semântica da linguagem, com o objetivo de eliminar as restrições arquiteturais do LuaJIT, o que acabou sendo um problema para a empresa. Obviamente, à medida que o projeto se desenvolveu, começamos a adicionar extensões (discutiremos isso abaixo) - mas isolamos todas as novas APIs da biblioteca de idiomas padrão.
Além disso, abandonamos a plataforma cruzada em favor do suporte apenas ao Linux x86-64, nossa única plataforma de produção. Infelizmente, não tínhamos recursos suficientes para testar adequadamente a quantidade gigantesca de mudanças que faríamos na plataforma.
Uma rápida olhada sob o capô da plataforma
Vamos ver de onde vem a restrição no tamanho dos ponteiros. Para começar, o
número do tipo em Lua 5.1 é (com algumas ressalvas menores) o tipo C double, que por sua vez corresponde ao tipo de precisão dupla definido pelo padrão IEEE 754. Na codificação desse tipo de 64 bits, o intervalo de valores é destacado para apresentação. NaN. Em particular, como qualquer valor no intervalo [0xFFF8000000000000; 0xFFFFFFFFFFFFFFFF].
Assim, podemos agrupar em um único valor de 64 bits um número de precisão dupla "real" ou alguma entidade que, do ponto de vista do tipo double, será interpretada como NaN e, do ponto de vista da nossa plataforma, será algo mais significativo - por exemplo, pelo tipo de objeto (alto 32 bits) e um ponteiro para seu conteúdo (baixo 32 bits):
union TValue { double n; struct object { void *payload; uint32_t type; } o; };
Essa técnica às vezes é chamada de marcação NaN (ou box NaN), e TValue basicamente descreve como LuaJIT representa valores variáveis em Lua. O TValue também possui uma terceira hipóstase usada para armazenar um ponteiro para uma função e informações para rebobinar a pilha Lua, ou seja, na análise final, a estrutura de dados fica assim:
union TValue { double n; struct object { void *payload; uint32_t type; } o; struct frame { void *func; uintptr_t link; } f; };
O campo frame.link na definição acima é do tipo uintptr_t, porque em alguns casos ele armazena um ponteiro e, em outros, é um número inteiro. O resultado é uma representação muito compacta da pilha da máquina virtual - na verdade, é uma matriz de valores de TV, e cada elemento da matriz é interpretado situacionalmente como um número, depois como um ponteiro digitado para um objeto ou como dados sobre o quadro da Lua-stack.
Vejamos um exemplo. Imagine que começamos com LuaJIT esse código Lua e definimos um ponto de interrupção dentro da função print:
local function foo(x) print("Hello, " .. x) end local function bar(a, b) local n = math.pi foo(b) end bar({}, "Lua")
A pilha Lua neste momento terá a seguinte aparência:

E tudo ficaria bem, mas essa técnica começa a falhar assim que tentamos iniciar no x86-64. Se rodarmos no modo de compatibilidade para aplicativos de 32 bits, ficaremos contra a restrição mmap já mencionada acima. E ponteiros de 64 bits não funcionarão imediatamente. O que fazer Para corrigir o problema, tive que:
- Estenda o valor de TV de 64 para 128 bits: dessa forma, obtemos um vazio "honesto" * em uma plataforma de 64 bits.
- Corrija o código da máquina virtual de acordo.
- Faça alterações no compilador JIT.
O volume total de mudanças acabou sendo muito significativo e nos alienou bastante do LuaJIT original. Vale ressaltar que a extensão TValue não é a única maneira de resolver o problema. No LuaJIT 2.1, seguimos o outro caminho, implementando o modo LJ_GC64. Peter Cawley, que fez uma enorme contribuição para o desenvolvimento desse modo de operação, leu sobre isso em uma reunião em Londres. Bem, no caso de LuaVela, a pilha para o mesmo exemplo é assim:
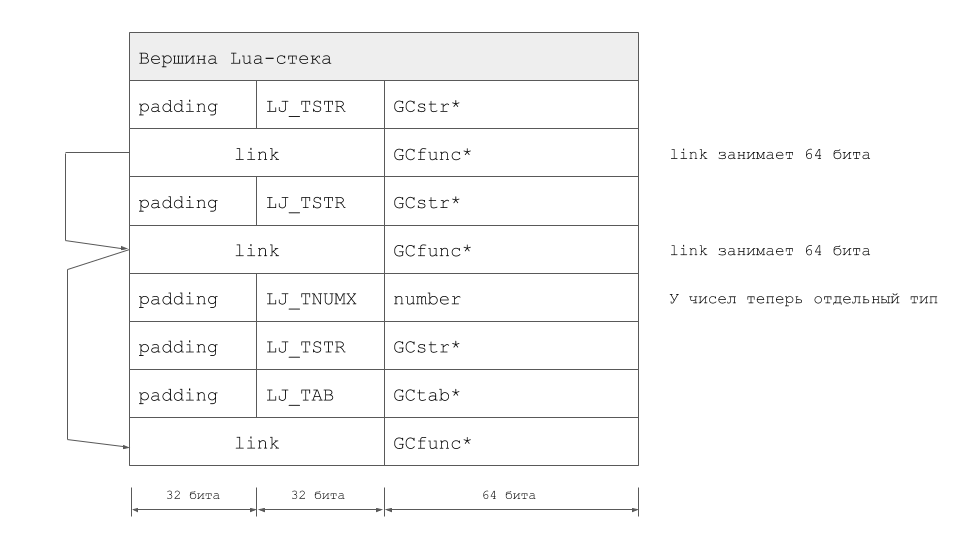
Primeiros sucessos e estabilização do projeto
Após meses de desenvolvimento ativo, é hora de experimentar o LuaVela em batalha. Como experimental, escolhemos os projetos mais problemáticos em termos de consumo de memória: a quantidade de dados com os quais eles tinham que trabalhar obviamente excedia 1 gigabyte; portanto, eles foram forçados a usar várias soluções alternativas. Os primeiros resultados foram animadores: LuaVela foi estável e apresentou melhor desempenho em comparação com a configuração LuaJIT usada nesses mesmos projetos.
Ao mesmo tempo, surgiu a questão dos testes. Felizmente, não tivemos que começar do zero, pois desde o primeiro dia de desenvolvimento, além de disponibilizar servidores, dispomos de:
- Testes funcionais e de integração de um servidor de aplicativos que executa a lógica de negócios de todos os projetos da empresa.
- Testes de projetos individuais.
Como a prática demonstrou, esses recursos foram suficientes para depurar e levar o projeto a um estado estável mínimo (eles fizeram um assembly de desenvolvimento - implementado na preparação - ele funciona e não falha). Por outro lado, esses testes em outros projetos eram completamente inadequados a longo prazo: um projeto com um nível de complexidade tão grande quanto a implementação de uma linguagem de programação não pode ter seus próprios testes. Além disso, a falta de testes diretamente no projeto complicou tecnicamente a busca e a correção de erros.
Em um mundo ideal, queríamos testar não apenas nossa implementação, mas também ter um conjunto de testes que nos permitissem validá-la de acordo com a
semântica da linguagem . Infelizmente, alguma decepção nos aguardava neste assunto. Apesar de a comunidade Lua voluntariamente criar bifurcações das implementações existentes, até recentemente, faltava um conjunto semelhante de testes de validação. A situação mudou para melhor quando, no final de 2018, François Perrad
anunciou o projeto lua-Harness.
No final, encerramos o problema de teste integrando os conjuntos de testes mais completos e representativos no ecossistema Lua em nosso repositório:
- Testes escritos pelos criadores da linguagem para a implementação do Lua 5.1.
- Testes fornecidos pela comunidade pelo autor do LuaJIT, Mike Pall.
- arnês lua
- Um subconjunto dos testes do projeto MAD que está sendo desenvolvido pelo CERN.
- Dois conjuntos de testes que criamos no IPONWEB e continuam sendo repostos até agora: um para teste funcional da plataforma, o outro usando a estrutura cmocka para testar a API C e tudo o que falta no nível de código Lua.
A introdução de cada lote de testes nos permitiu detectar e corrigir de 2 a 3 erros críticos - portanto, é óbvio que nossos esforços foram recompensados. Embora o tópico de teste dos tempos de execução da linguagem e dos compiladores (estáticos e dinâmicos) seja realmente ilimitado, acreditamos que estabelecemos uma base bastante sólida para o desenvolvimento estável do projeto. Falamos sobre os problemas de testar nossa própria implementação do Lua (incluindo tópicos como trabalhar com bancos de teste e depuração post-mortem) duas vezes, no
Lua em Moscou 2017 e no
HighLoad ++ 2018 - todos os interessados em detalhes podem assistir a um vídeo desses relatórios. Bem, veja o diretório de
testes em nosso repositório, é claro.
Novos recursos
Portanto, tínhamos à disposição uma implementação estável do Lua 5.1 para Linux x86-64, desenvolvida pelas forças de uma pequena equipe que gradualmente “dominou” o legado LuaJIT e acumulou conhecimentos. Em tais condições, o desejo de expandir a plataforma e adicionar recursos que não estão na Lua de baunilha nem no LuaJIT, mas que nos ajudariam a resolver outros problemas prementes, tornou-se bastante natural.
Uma descrição detalhada de todas as extensões é fornecida na
documentação no formato RST (use cmake. && make docs para criar uma cópia local no formato HTML). Uma descrição completa das extensões da API Lua pode ser encontrada
neste link , e a API C
neste . Infelizmente, em um artigo de revisão, é impossível falar sobre tudo, então aqui está uma lista das funções mais significativas:
- DataState - a capacidade de organizar o acesso compartilhado a um objeto de várias instâncias independentes das máquinas virtuais Lua.
- A capacidade de definir um tempo limite para a corotina e interromper a execução daqueles que são executados por mais tempo.
- Um conjunto de otimizações do compilador JIT projetadas para combater o aumento exponencial no número de rastreamentos ao copiar dados entre objetos - falamos sobre isso no HighLoad ++ 2017, mas há alguns meses tivemos novas idéias de trabalho que ainda não foram documentadas.
- Novo Kit de Ferramentas: Sampling Profiler. descompacte o analisador de saída de depuração do compilador, etc.
Cada um desses recursos merece um artigo separado - escreva nos comentários sobre os quais você gostaria de ler mais.
Aqui, quero falar um pouco mais sobre como reduzimos a carga no coletor de lixo.
A vedação permite tornar um objeto inacessível ao coletor de lixo. Em nosso projeto típico, a maioria dos dados (até 80%) dentro da máquina virtual Lua já são regras de negócios, que são uma tabela Lua complexa. O tempo de vida desta tabela (minutos) é muito maior que o tempo de vida das solicitações processadas (dezenas de milissegundos) e os dados nela não são alterados durante o processamento da consulta. Em tal situação, não faz sentido forçar o coletor de lixo a repetir essa enorme estrutura de dados repetidamente. Para fazer isso, "selamos" recursivamente o objeto e reordenamos os dados de forma que o coletor de lixo nunca alcance o objeto "selado" ou seu conteúdo. Na baunilha Lua 5.4, esse problema será
resolvido com o suporte de gerações de objetos na coleta de lixo geracional.
É importante ter em mente que objetos "selados" não devem ser graváveis. A não observância desse invariável leva ao aparecimento de ponteiros pendentes: por exemplo, um objeto "selado" se refere a um objeto regular e um coletor de lixo, pulando um objeto "selado" ao atravessar uma pilha, ignora um regular - com a diferença de que um objeto "selado" não pode ser liberado, e o habitual pode. Tendo implementado o suporte para esse invariante, obtemos essencialmente suporte de
imunidade gratuito
para objetos, cuja ausência é frequentemente lamentada em Lua. Enfatizo que objetos imutáveis e "selados" não são a mesma coisa. A segunda propriedade implica a primeira, mas não vice-versa.
Também observo que no Lua 5.1 a imunidade pode ser implementada usando metatables - a solução está funcionando, mas não é a mais rentável em termos de desempenho. Mais informações sobre "vedação", imunidade e como as usamos na vida cotidiana podem ser encontradas
neste relatório.
Conclusões
No momento, estamos satisfeitos com a estabilidade e o conjunto de oportunidades para nossa implementação. E, apesar das limitações iniciais, nossa implementação é significativamente inferior à baunilha Lua e LuaJIT em termos de portabilidade, resolve muitos de nossos problemas - esperamos que essas soluções sejam úteis para outra pessoa.
Além disso, mesmo que o LuaVela não seja adequado à produção, convidamos você a usá-lo como um ponto de entrada para entender como o LuaJIT ou seu fork funciona. Além de resolver problemas e expandir a funcionalidade, ao longo dos anos refatoramos uma parte significativa da base de código e escrevemos
artigos de treinamento sobre a estrutura interna do projeto - muitos deles são aplicáveis não apenas ao LuaVela, mas também ao LuaJIT.
Obrigado por sua atenção, estamos aguardando solicitações de recebimento!