Certa vez, explorando as profundezas da Internet, deparei-me com um vídeo em que uma pessoa treina uma cobra usando um algoritmo genético. E eu queria o mesmo. Mas apenas pegar o mesmo e escrever em python não seria interessante. E decidi usar uma abordagem mais moderna para o treinamento de sistemas de agentes, ou seja, Q-network. Mas vamos começar do começo.
Treinamento de reforço
No aprendizado de máquina, o RL (Reinforcement Learning) é bem diferente de outras áreas. A diferença é que o algoritmo clássico de ML aprende com dados prontos, enquanto o RL, por assim dizer, cria esses dados para si. A idéia da RL é que, além do próprio algoritmo, chamado agente, existe um ambiente no qual esse agente é colocado. Em cada estágio, o agente deve executar alguma ação (ação), e o ambiente responde com uma recompensa (recompensa) e seu estado (estado), com base no qual o agente executa a ação.
Dqn
Deve haver uma explicação de como o algoritmo funciona, mas deixarei um link para onde as pessoas inteligentes o explicam.
Implementação de cobra
Depois que descobrimos o c rl, precisamos criar um ambiente no qual colocaremos o agente. Felizmente, não há necessidade de reinventar a roda, pois uma empresa como a open-ai já escreveu a biblioteca da academia, com a qual você pode escrever seu próprio ambiente. Na biblioteca, eles já estão em grande número. Desde simples jogos de atari até modelos 3D complexos. Mas entre tudo isso não há cobra. Portanto, procedemos à sua criação.
Não descreverei todos os momentos da criação de um ambiente na academia, mas mostrarei apenas a classe principal, na qual é necessário implementar várias funções.
import gym class Env(gym.Env): def __init__(self): pass def step(self, action): """ . , """ def reset(self): """ """ def render(self, mode='human'): """ """
Mas, para implementar essas funções, precisamos criar um sistema de recompensas e de que forma forneceremos informações sobre o meio ambiente.
Condição
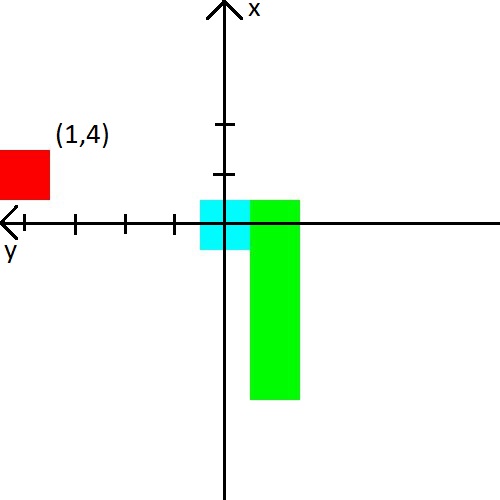
No vídeo, um homem deu à cobra a distância para a parede, cobra e maçã em 8 direções. Esses são 24 números. Decidi reduzir a quantidade de dados, mas os complique um pouco. Primeiro, combinarei a distância das paredes com a distância da cobra. Simplificando, diremos a ela a distância do objeto mais próximo que pode matar em uma colisão. Em segundo lugar, haverá apenas três direções e elas dependerão da direção do movimento da cobra. Por exemplo, ao iniciar, a cobra olha para cima, então vamos dizer a distância para as paredes superior, esquerda e direita. Mas quando a cabeça da cobra virar para a direita, já informaremos a distância para as paredes direita, superior e inferior. Por uma questão de simplicidade, darei uma imagem.

Eu também decidi brincar com a maçã. Apresentaremos informações sobre ele na forma de (x, y) coordenadas no sistema de coordenadas, que se origina na cabeça da cobra. O sistema de coordenadas também mudará sua orientação atrás da cabeça da cobra. Depois da foto, acho que definitivamente deveria ficar claro.
Recompensa
Se você pode criar algum tipo de recurso com o estado e esperar que a rede neural descubra isso, então com o prêmio tudo fica mais complicado. Depende dela se o agente aprenderá e se ele aprenderá o que queremos.
Darei imediatamente o sistema de recompensa com o qual consegui um treinamento estável.
- A cada passo, a recompensa é -0,25.
- Na morte -10.
- Após a morte, até 15 etapas -100.
- Ao comer um quadrado de maçã ( número de maçãs comidas ) * 3.5.
E também dê exemplos do que leva a um sistema de recompensa ruim.
- Se você não der uma recompensa pequena o suficiente pela morte nos primeiros passos, a cobra preferirá matar contra a parede. É mais fácil do que procurar maçãs :)
- Se você der uma recompensa positiva pelas etapas, a cobra começará a girar sem parar. Porque, na opinião dela, será mais lucrativo do que procurar maçãs.
- E muitos outros casos em que a cobra simplesmente não aprende.
Bem, um exemplo do que a cobra aprendeu em 2000 episódios Sumário
O principal interesse em escrever a cobra era ver como a cobra aprende sabendo tão pouco sobre seu ambiente. E ela estudou bem, já que a taxa média de maçãs comidas chegou a 23, o que, me parece, não é muito ruim. Portanto, o experimento pode ser considerado bem-sucedido.
Código fonte