Eu costumava ter medo de fazer cache. Eu realmente não queria escalar e descobrir o que era, imediatamente imaginei algumas coisas de luto-empresa no compartimento do motor que apenas o vencedor da olimpíada de matemática poderia descobrir. Descobriu-se que não é assim. O armazenamento em cache acabou sendo muito simples, compreensível e incrivelmente fácil de implementar em qualquer projeto.
Neste post, tentarei explicar sobre o armazenamento em cache da maneira mais simples possível. Você aprenderá como implementar o cache em 1 minuto, como armazenar em cache por chave, definir a vida útil do cache e muitas outras coisas que você precisa saber se você foi instruído a armazenar em cache algo em seu projeto de trabalho e não deseja confundir rosto.
Por que digo "confiado"? Como o cache, por regra, faz sentido aplicar em projetos grandes e altamente carregados, com dezenas de milhares de solicitações por minuto. Nesses projetos, para não sobrecarregar o banco de dados, eles geralmente armazenam em cache as chamadas do repositório. Especialmente se for sabido que os dados de algum sistema mestre são atualizados com uma certa frequência. Nós mesmos não escrevemos tais projetos, trabalhamos neles. Se o projeto é pequeno e não ameaça sobrecargas, é claro que é melhor não armazenar em cache nada - sempre os dados novos são sempre melhores que os atualizados periodicamente.
Normalmente, nos postos de treinamento, o palestrante primeiro rasteja por baixo do capô, começa a se aprofundar nas entranhas da tecnologia, o que incomoda muito o leitor, e só então, quando folheia uma boa metade do artigo e não entende nada, diz como funciona. Tudo será diferente conosco. Primeiro, fazemos com que funcione e, de preferência, com o mínimo de esforço, e só então, se você estiver interessado, pode olhar sob o capô do cache, dentro da própria lixeira e ajustar o cache. Mas mesmo se você não o fizer (e isso começa no ponto 6), seu cache funcionará assim.
Criaremos um projeto no qual analisaremos todos os aspectos do cache que prometi. No final, como sempre, haverá um link para o próprio projeto.
0. Criando um projeto
Criaremos um projeto muito simples no qual podemos extrair a entidade do banco de dados. Adicionei Lombok, Spring Cache, Spring Data JPA e H2 ao projeto. Embora apenas o Spring Cache possa ser dispensado.
plugins { id 'org.springframework.boot' version '2.1.7.RELEASE' id 'io.spring.dependency-management' version '1.0.8.RELEASE' id 'java' } group = 'ru.xpendence' version = '0.0.1-SNAPSHOT' sourceCompatibility = '1.8' configurations { compileOnly { extendsFrom annotationProcessor } } repositories { mavenCentral() } dependencies { implementation 'org.springframework.boot:spring-boot-starter-cache' implementation 'org.springframework.boot:spring-boot-starter-data-jpa' compileOnly 'org.projectlombok:lombok' runtimeOnly 'com.h2database:h2' annotationProcessor 'org.projectlombok:lombok' testImplementation 'org.springframework.boot:spring-boot-starter-test' }
Teremos apenas uma entidade, vamos chamá-la de usuário.
@Entity @Table(name = "users") @Data @NoArgsConstructor @ToString public class User implements Serializable { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; @Column(name = "name") private String name; @Column(name = "email") private String email; public User(String name, String email) { this.name = name; this.email = email; } }
Adicione o repositório e o serviço:
public interface UserRepository extends JpaRepository<User, Long> { } @Slf4j @Service public class UserServiceImpl implements UserService { private final UserRepository repository; public UserServiceImpl(UserRepository repository) { this.repository = repository; } @Override public User create(User user) { return repository.save(user); } @Override public User get(Long id) { log.info("getting user by id: {}", id); return repository.findById(id) .orElseThrow(() -> new EntityNotFoundException("User not found by id " + id)); } }
Quando inserimos o método de serviço get (), escrevemos sobre isso no log.
Conecte-se ao projeto Spring Cache.
@SpringBootApplication @EnableCaching
O projeto está pronto.
1. Armazenando em cache o resultado do retorno
O que o Spring Cache faz? O Spring Cache simplesmente armazena em cache o resultado de retorno para parâmetros de entrada específicos. Vamos conferir. Colocaremos a anotação @Cacheable sobre o método de serviço get () para armazenar em cache os dados retornados. Atribuímos a esta anotação o nome "usuários" (analisaremos melhor por que isso é feito separadamente).
@Override @Cacheable("users") public User get(Long id) { log.info("getting user by id: {}", id); return repository.findById(id) .orElseThrow(() -> new EntityNotFoundException("User not found by id " + id)); }
Para verificar como isso funciona, escreveremos um teste simples.
@RunWith(SpringRunner.class) @SpringBootTest public abstract class AbstractTest { }
@Slf4j public class UserServiceTest extends AbstractTest { @Autowired private UserService service; @Test public void get() { User user1 = service.create(new User("Vasya", "vasya@mail.ru")); User user2 = service.create(new User("Kolya", "kolya@mail.ru")); getAndPrint(user1.getId()); getAndPrint(user2.getId()); getAndPrint(user1.getId()); getAndPrint(user2.getId()); } private void getAndPrint(Long id) { log.info("user found: {}", service.get(id)); } }
Uma pequena digressão, por que geralmente escrevo AbstractTest e herdo todos os testes dele.Se a classe tiver sua própria anotação @SpringBootTest, o contexto será gerado novamente para essa classe sempre. Como o contexto pode aumentar por 5 segundos, ou talvez 40 segundos, isso, em qualquer caso, inibe bastante o processo de teste. Ao mesmo tempo, geralmente não há diferença de contexto e, quando você executa cada grupo de testes na mesma classe, não há necessidade de reiniciar o contexto. Se colocarmos apenas uma anotação, digamos, sobre uma classe abstrata, como no nosso caso, isso nos permitirá levantar o contexto apenas uma vez.
Portanto, prefiro reduzir o número de contextos levantados durante o teste / montagem, se possível.
O que nosso teste faz? Ele cria dois usuários e os retira do banco de dados duas vezes. Como lembramos, colocamos a anotação @Cacheable, que armazenará em cache os valores retornados. Depois de receber o objeto do método get (), produzimos o objeto no log. Além disso, registramos informações sobre cada visita do aplicativo ao método get ().
Execute o teste. É isso que recebemos no console.
getting user by id: 1 user found: User(id=1, name=Vasya, email=vasya@mail.ru) getting user by id: 2 user found: User(id=2, name=Kolya, email=kolya@mail.ru) user found: User(id=1, name=Vasya, email=vasya@mail.ru) user found: User(id=2, name=Kolya, email=kolya@mail.ru)
Como vemos, nas duas primeiras vezes fomos ao método get () e, na verdade, obtivemos o usuário do banco de dados. Em todos os outros casos, não houve uma chamada real para o método, o aplicativo pegou os dados em cache por chave (neste caso, esse é o ID).
2. Declaração de Chave de Cache
Há situações em que vários parâmetros chegam ao método em cache. Nesse caso, pode ser necessário determinar o parâmetro pelo qual o cache ocorrerá. Nós adicionamos um exemplo a um método que salvará uma entidade montada por parâmetros no banco de dados, mas se uma entidade com o mesmo nome já existir, não a salvaremos. Para fazer isso, definiremos o parâmetro name como a chave para o cache. Ficará assim:
@Override @Cacheable(value = "users", key = "#name") public User create(String name, String email) { log.info("creating user with parameters: {}, {}", name, email); return repository.save(new User(name, email)); }
Vamos escrever o teste correspondente:
@Test public void create() { createAndPrint("Ivan", "ivan@mail.ru"); createAndPrint("Ivan", "ivan1122@mail.ru"); createAndPrint("Sergey", "ivan@mail.ru"); log.info("all entries are below:"); service.getAll().forEach(u -> log.info("{}", u.toString())); } private void createAndPrint(String name, String email) { log.info("created user: {}", service.create(name, email)); }
Vamos tentar criar três usuários, para dois dos quais o nome será o mesmo
createAndPrint("Ivan", "ivan@mail.ru"); createAndPrint("Ivan", "ivan1122@mail.ru");
e para dois dos quais o email corresponderá
createAndPrint("Ivan", "ivan@mail.ru"); createAndPrint("Sergey", "ivan@mail.ru");
No método de criação, registramos todos os fatos de que o método é chamado e também registramos todas as entidades que esse método nos retornou. O resultado será assim:
creating user with parameters: Ivan, ivan@mail.ru created user: User(id=1, name=Ivan, email=ivan@mail.ru) created user: User(id=1, name=Ivan, email=ivan@mail.ru) creating user with parameters: Sergey, ivan@mail.ru created user: User(id=2, name=Sergey, email=ivan@mail.ru) all entries are below: User(id=1, name=Ivan, email=ivan@mail.ru) User(id=2, name=Sergey, email=ivan@mail.ru)
Vimos que, de fato, o aplicativo chamou o método três vezes e entrou nele apenas duas vezes. Uma vez que uma chave correspondia a um método, ela simplesmente retornava um valor em cache.
3. Armazenamento em cache forçado. @CachePut
Há situações em que queremos armazenar em cache o valor de retorno para alguma entidade, mas, ao mesmo tempo, precisamos atualizar o cache. Para essas necessidades, a anotação @CachePut existe. Ele passa o aplicativo para o método, enquanto atualiza o cache para o valor de retorno, mesmo se já estiver em cache.
Adicione alguns métodos nos quais salvaremos o usuário. Marcaremos um deles com a anotação usual @Cacheable, o segundo com @CachePut.
@Override @Cacheable(value = "users", key = "#user.name") public User createOrReturnCached(User user) { log.info("creating user: {}", user); return repository.save(user); } @Override @CachePut(value = "users", key = "#user.name") public User createAndRefreshCache(User user) { log.info("creating user: {}", user); return repository.save(user); }
O primeiro método simplesmente retornará os valores em cache, o segundo forçará a atualização do cache. O armazenamento em cache será realizado usando a chave # user.name. Vamos escrever o teste correspondente.
@Test public void createAndRefresh() { User user1 = service.createOrReturnCached(new User("Vasya", "vasya@mail.ru")); log.info("created user1: {}", user1); User user2 = service.createOrReturnCached(new User("Vasya", "misha@mail.ru")); log.info("created user2: {}", user2); User user3 = service.createAndRefreshCache(new User("Vasya", "kolya@mail.ru")); log.info("created user3: {}", user3); User user4 = service.createOrReturnCached(new User("Vasya", "petya@mail.ru")); log.info("created user4: {}", user4); }
De acordo com a lógica já descrita, na primeira vez que um usuário com o nome "Vasya" é salvo por meio do método createOrReturnCached (), receberemos uma entidade em cache e o aplicativo não entrará no próprio método. Se chamarmos o método createAndRefreshCache (), a entidade em cache da chave denominada "Vasya" será substituída no cache. Vamos executar o teste e ver o que será exibido no console.
creating user: User(id=null, name=Vasya, email=vasya@mail.ru) created user1: User(id=1, name=Vasya, email=vasya@mail.ru) created user2: User(id=1, name=Vasya, email=vasya@mail.ru) creating user: User(id=null, name=Vasya, email=kolya@mail.ru) created user3: User(id=2, name=Vasya, email=kolya@mail.ru) created user4: User(id=2, name=Vasya, email=kolya@mail.ru)
Vemos que o usuário1 foi gravado com sucesso no banco de dados e no cache. Quando tentamos gravar o usuário com o mesmo nome novamente, obtemos o resultado em cache da primeira chamada (usuário2, para o qual o ID é igual ao usuário1, o que nos diz que o usuário não foi gravado e isso é apenas um cache). Em seguida, escrevemos o terceiro usuário através do segundo método, que, mesmo com o resultado em cache, ainda chamou o método e gravou um novo resultado no cache. Este é o usuário3. Como podemos ver, ele já tem um novo ID. Depois disso, chamamos o primeiro método, que pega o novo cache adicionado pelo usuário3.
4. Remoção do cache. @CacheEvict
Às vezes, torna-se necessário atualizar alguns dados no cache. Por exemplo, uma entidade já foi excluída do banco de dados, mas ainda pode ser acessada pelo cache. Para manter a consistência dos dados, precisamos pelo menos não armazenar dados excluídos no cache.
Adicione mais alguns métodos ao serviço.
@Override public void delete(Long id) { log.info("deleting user by id: {}", id); repository.deleteById(id); } @Override @CacheEvict("users") public void deleteAndEvict(Long id) { log.info("deleting user by id: {}", id); repository.deleteById(id); }
O primeiro simplesmente exclui o usuário, o segundo também o exclui, mas o marcaremos com a anotação @CacheEvict. Adicione um teste que criará dois usuários, após o qual um será excluído através de um método simples e o segundo através de um método anotado. Depois disso, levaremos esses usuários através do método get ().
@Test public void delete() { User user1 = service.create(new User("Vasya", "vasya@mail.ru")); log.info("{}", service.get(user1.getId())); User user2 = service.create(new User("Vasya", "vasya@mail.ru")); log.info("{}", service.get(user2.getId())); service.delete(user1.getId()); service.deleteAndEvict(user2.getId()); log.info("{}", service.get(user1.getId())); log.info("{}", service.get(user2.getId())); }
É lógico que, como nosso usuário já está armazenado em cache, a remoção não nos impede de obtê-lo, pois está armazenado em cache. Vamos ver os logs.
getting user by id: 1 User(id=1, name=Vasya, email=vasya@mail.ru) getting user by id: 2 User(id=2, name=Vasya, email=vasya@mail.ru) deleting user by id: 1 deleting user by id: 2 User(id=1, name=Vasya, email=vasya@mail.ru) getting user by id: 2 javax.persistence.EntityNotFoundException: User not found by id 2
Vemos que o aplicativo foi com segurança as duas vezes para o método get () e o Spring armazenou em cache essas entidades. Em seguida, os excluímos através de diferentes métodos. Excluímos o primeiro da maneira usual, e o valor em cache permaneceu; portanto, quando tentamos colocar o usuário no id 1, obtivemos sucesso. Quando tentamos obter o usuário 2, o método retornou uma EntityNotFoundException - não havia esse usuário no cache.
5. Configurações de agrupamento. @Caching
Às vezes, um único método requer várias configurações de cache. A anotação @Caching é usada para esses propósitos. Pode ser algo como isto:
@Caching( cacheable = { @Cacheable("users"), @Cacheable("contacts") }, put = { @CachePut("tables"), @CachePut("chairs"), @CachePut(value = "meals", key = "#user.email") }, evict = { @CacheEvict(value = "services", key = "#user.name") } ) void cacheExample(User user) { }
Essa é a única maneira de agrupar anotações. Se você tentar acumular algo como
@CacheEvict("users") @CacheEvict("meals") @CacheEvict("contacts") @CacheEvict("tables") void cacheExample(User user) { }
a IDEA dirá que esse não é o caso.
6. Configuração flexível. Gerenciador de cache
Finalmente, descobrimos o cache e ele deixou de ser algo incompreensível e assustador para nós. Agora vamos dar uma olhada por baixo e ver como podemos configurar o cache em geral.
Para essas tarefas, existe um CacheManager. Existe onde quer que o Spring Cache esteja. Quando adicionamos a anotação @EnableCache, esse gerenciador de cache será criado automaticamente pelo Spring. Podemos verificar isso se envolvermos automaticamente o ApplicationContext e o abrirmos no ponto de interrupção. Entre outras posições, haverá um bean cacheManager.
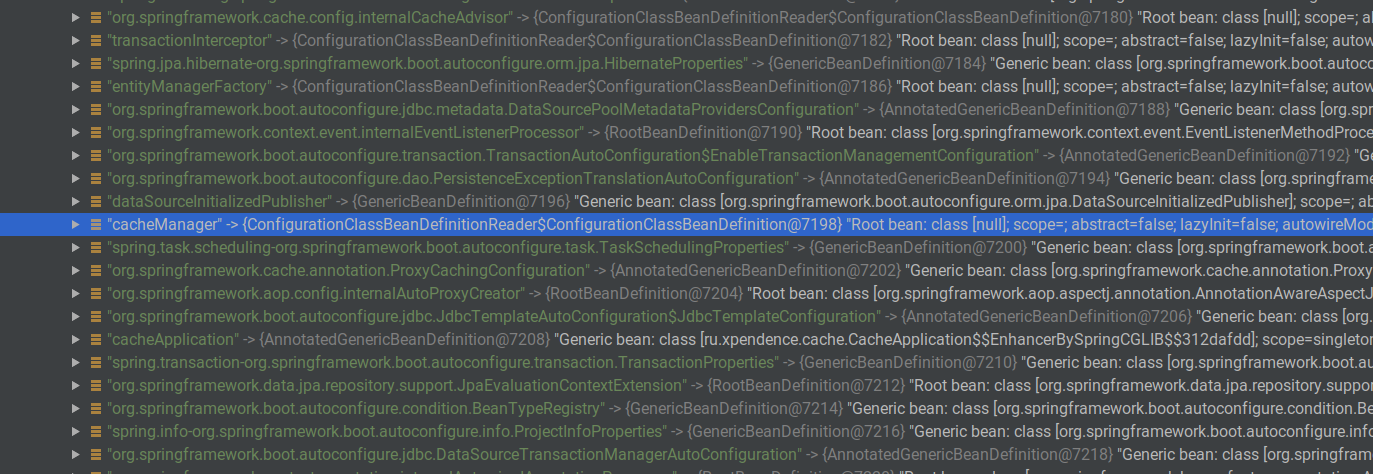
Parei o aplicativo no estágio em que dois usuários já haviam sido criados e colocados no cache. Se chamarmos o bean que precisamos por meio de Evaluate Expression, veremos que realmente existe um bean, ele possui um ConcurentMapCache com a chave "users" e o valor ConcurrentHashMap, que já contém usuários em cache.

Por sua vez, podemos criar nosso gerenciador de cache, com Habr e programadores, e ajustá-lo ao nosso gosto.
@Bean("habrCacheManager") public CacheManager cacheManager() { return null; }
Resta apenas escolher qual gerenciador de cache usaremos, porque existem muitos deles. Não vou listar todos os gerenciadores de cache, basta saber que existem:
- O SimpleCacheManager é o gerenciador de cache mais simples, conveniente para aprendizado e teste.
- ConcurrentMapCacheManager - Inicializa lentamente as instâncias retornadas para cada solicitação. Também é recomendado para testar e aprender a trabalhar com o cache, bem como para algumas ações simples como a nossa. Para um trabalho sério com o cache, a implementação abaixo é recomendada.
- JCacheCacheManager , EhCacheCacheManager , CaffeineCacheManager são "parceiros parceiros" sérios gerenciadores de cache que são personalizáveis de forma flexível e executam tarefas de uma ampla gama de ações.
Como parte da minha humilde publicação, não descreverei os gerenciadores de cache dos três últimos. Em vez disso, examinaremos vários aspectos da configuração de um gerenciador de cache usando o ConcurrentMapCacheManager como exemplo.
Então, vamos recriar nosso gerenciador de cache.
@Bean("habrCacheManager") public CacheManager cacheManager() { return new ConcurrentMapCacheManager(); }
Nosso gerenciador de cache está pronto.
7. Configuração de cache. Tempo de vida, tamanho máximo e assim por diante.
Para fazer isso, precisamos de uma biblioteca Google Guava bastante popular. Eu peguei o último.
compile group: 'com.google.guava', name: 'guava', version: '28.1-jre'
Ao criar o gerenciador de cache, redefinimos o método createConcurrentMapCache, no qual chamaremos CacheBuilder a partir do Guava. No processo, seremos solicitados a configurar o gerenciador de cache, inicializando os seguintes métodos:
- maximumSize - o tamanho máximo dos valores que o cache pode conter. Usando esse parâmetro, é possível encontrar uma tentativa de encontrar um compromisso entre a carga no banco de dados e a RAM da JVM.
- refreshAfterWrite - tempo após gravar o valor no cache, após o qual ele será atualizado automaticamente.
- expireAfterAccess - a vida útil do valor após a última chamada.
- expireAfterWrite - vida útil do valor após a gravação no cache. Este é o parâmetro que definiremos.
e outros
Definimos no gerente a vida útil do registro. Para não esperar muito, defina 1 segundo.
@Bean("habrCacheManager") public CacheManager cacheManager() { return new ConcurrentMapCacheManager() { @Override protected Cache createConcurrentMapCache(String name) { return new ConcurrentMapCache( name, CacheBuilder.newBuilder() .expireAfterWrite(1, TimeUnit.SECONDS) .build().asMap(), false); } }; }
Escrevemos um teste correspondente a este caso.
@Test public void checkSettings() throws InterruptedException { User user1 = service.createOrReturnCached(new User("Vasya", "vasya@mail.ru")); log.info("{}", service.get(user1.getId())); User user2 = service.createOrReturnCached(new User("Vasya", "vasya@mail.ru")); log.info("{}", service.get(user2.getId())); Thread.sleep(1000L); User user3 = service.createOrReturnCached(new User("Vasya", "vasya@mail.ru")); log.info("{}", service.get(user3.getId())); }
Salvamos vários valores no banco de dados e, se os dados forem armazenados em cache, não salvaremos nada. Primeiro, salvamos dois valores e esperamos 1 segundo até o cache ficar inoperante, após o qual salvamos outro valor.
creating user: User(id=null, name=Vasya, email=vasya@mail.ru) getting user by id: 1 User(id=1, name=Vasya, email=vasya@mail.ru) User(id=1, name=Vasya, email=vasya@mail.ru) creating user: User(id=null, name=Vasya, email=vasya@mail.ru) getting user by id: 2 User(id=2, name=Vasya, email=vasya@mail.ru)
Os logs mostram que primeiro criamos um usuário e depois tentamos outro, mas como os dados foram armazenados em cache, obtivemos os dados do cache (nos dois casos, ao salvar e ao obter no banco de dados). Em seguida, o cache ficou com defeito, como um registro informa sobre a economia e o recebimento reais do usuário.
8. Resumir
Cedo ou tarde, o desenvolvedor enfrenta a necessidade de implementar o cache no projeto. Espero que este artigo o ajude a entender o assunto e a examinar os problemas de cache com mais ousadia.
Github do projeto aqui:
https://github.com/promoscow/cache