Em um
artigo anterior, falamos sobre tentar usar o Watcher e apresentamos um relatório de teste. Periodicamente, conduzimos esses testes para equilibrar e outras funções críticas de uma grande nuvem corporativa ou de operador.
A alta complexidade do problema que está sendo resolvido pode exigir vários artigos para descrever nosso projeto. Hoje publicamos o segundo artigo da série sobre balanceamento de máquinas virtuais na nuvem.
Alguma terminologia
O VmWare introduziu o utilitário DRS (Distributed Resource Scheduler) para equilibrar a carga de seu ambiente de virtualização.
Enquanto
searchvmware.techtarget.com/definition/VMware-DRS escreve
“O VMware DRS (Distributed Resource Scheduler) é um utilitário que equilibra a carga de computação com os recursos disponíveis em um ambiente virtual. O utilitário faz parte de um pacote de virtualização chamado VMware Infrastructure.
Usando o VMware DRS, os usuários definem as regras para distribuir recursos físicos entre máquinas virtuais (VMs). O utilitário pode ser configurado para controle manual ou automático. Os pools de recursos da VMware podem ser facilmente adicionados, removidos ou reorganizados. Se desejado, os pools de recursos podem ser isolados entre diferentes unidades de negócios. Se a carga de trabalho de uma ou mais máquinas virtuais mudar drasticamente, o VMware DRS redistribui as máquinas virtuais entre servidores físicos. Se a carga de trabalho geral for reduzida, alguns servidores físicos poderão ficar temporariamente inoperantes e a carga de trabalho consolidada. ”Por que preciso de balanceamento?
Em nossa opinião, o DRS é um recurso indispensável da nuvem, embora isso não signifique que o DRS deva ser usado a qualquer hora, em qualquer lugar. Dependendo da finalidade e das necessidades da nuvem, pode haver requisitos diferentes para DRS e métodos de balanceamento. Talvez haja situações em que o balanceamento não seja necessário. Ou até prejudicial.
Para entender melhor onde e para quais clientes DRS são necessários, considere suas metas e objetivos. As nuvens podem ser divididas em públicas e privadas. Aqui estão as principais diferenças entre essas nuvens e as metas do cliente.
Tiramos as seguintes conclusões para nós mesmos:
Para nuvens privadas fornecidas para grandes clientes corporativos, o DRS pode ser aplicado sujeito a restrições:
- regras de segurança da informação e afinidade contábil para balanceamento;
- disponibilidade de uma quantidade suficiente de recursos em caso de acidente;
- os dados da máquina virtual residem em um sistema de armazenamento centralizado ou distribuído;
- diversidade temporal de procedimentos de administração, backup e balanceamento;
- balancear apenas dentro do agregado de hosts do cliente;
- equilibrando apenas com um forte desequilíbrio, a migração mais eficiente e segura de VMs (afinal, a migração pode falhar);
- equilibrar máquinas virtuais relativamente “silenciosas” (a migração de máquinas virtuais “barulhentas” pode levar muito tempo);
- balanceamento levando em consideração o "custo" - a carga no sistema de armazenamento e na rede (com arquiteturas personalizadas para grandes clientes);
- balanceamento levando em consideração o comportamento individual de cada VM;
- o equilíbrio é desejável após o horário (noite, fins de semana, feriados).
Para nuvens públicas que prestam serviços a pequenos clientes, o DRS pode ser usado com muito mais frequência, com recursos avançados:
- falta de restrições de segurança da informação e regras de afinidade;
- balanceamento dentro da nuvem;
- balanceamento a qualquer momento razoável;
- equilibrar qualquer VM;
- equilibrar máquinas virtuais “barulhentas” (para não interferir com o resto);
- os dados da máquina virtual geralmente estão localizados em unidades locais;
- contabilizando o desempenho médio da rede e do armazenamento (a arquitetura em nuvem é unificada);
- balanceamento de acordo com regras generalizadas e estatísticas disponíveis do comportamento do datacenter.
Complexidade do problema
A dificuldade do balanceamento é que o DRS deve trabalhar com muitos fatores incertos:
- comportamento do usuário de cada um dos sistemas de informações do cliente;
- algoritmos para a operação de servidores de sistemas de informação;
- Comportamento do servidor DBMS
- carga em recursos de computação, armazenamento, rede;
- interação do servidor entre si na luta por recursos da nuvem.
A carga de um grande número de servidores de aplicativos virtuais e bancos de dados nos recursos da nuvem ocorre com o tempo, as conseqüências podem ocorrer e se sobrepõem a efeitos imprevisíveis após períodos imprevisíveis. Mesmo para controlar processos relativamente simples (por exemplo, para controlar um motor, um sistema de aquecimento de água em casa), os sistemas de controle automático precisam usar algoritmos complexos
de feedback com
diferenciação proporcional e integral integral .

Nossa tarefa é muitas ordens de magnitude mais complicada e existe o risco de o sistema não conseguir equilibrar a carga com os valores estabelecidos em um tempo razoável, mesmo que influências externas dos usuários não ocorram.
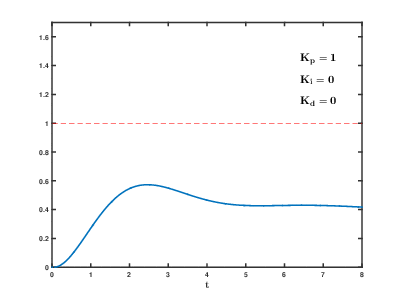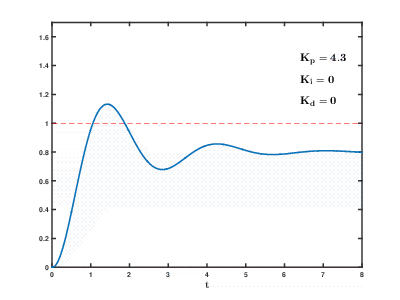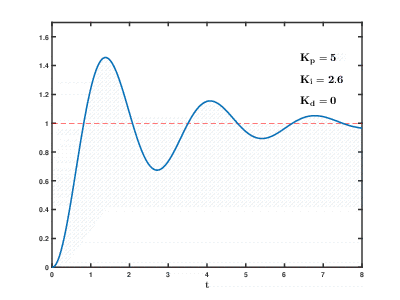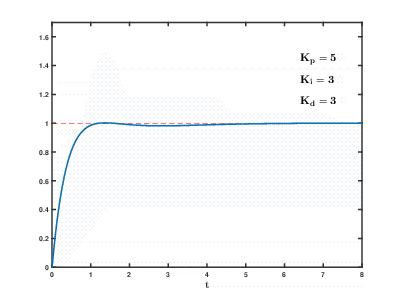
História de nossos desenvolvimentos
Para resolver esse problema, decidimos não começar do zero, mas aproveitar a experiência existente e começamos a interagir com especialistas com experiência nesse campo. Felizmente, nossa compreensão dos problemas coincidiu completamente.
Etapa 1
Usamos um sistema baseado na tecnologia de rede neural e tentamos otimizar nossos recursos com base em eles.
O interesse desse estágio era testar a nova tecnologia, e sua importância era aplicar uma abordagem não-padrão para resolver o problema, onde, sendo outras coisas iguais, as abordagens-padrão praticamente se esgotaram.
Iniciamos o sistema e realmente fomos equilibrados. A escala da nossa nuvem não nos permitiu obter resultados otimistas anunciados pelos desenvolvedores, mas ficou claro que o balanceamento estava funcionando.
Além disso, tínhamos limitações bastante sérias:
- Para treinar uma rede neural, as máquinas virtuais precisam executar sem alterações significativas por semanas ou meses.
- O algoritmo foi projetado para otimização com base na análise de dados "históricos" anteriores.
- Para treinar uma rede neural, é necessária uma quantidade suficientemente grande de dados e recursos de computação.
- A otimização e o balanceamento podem ser feitos relativamente raramente - uma vez a cada poucas horas, o que claramente não é suficiente.
Etapa 2
Como não estávamos satisfeitos com o estado das coisas, decidimos modificar o sistema e, para isso, responder à
pergunta principal - para quem o fazemos?
Primeiro para clientes corporativos. Portanto, precisamos de um sistema que funcione com eficiência, com as restrições corporativas que simplificam apenas a implementação.
A segunda pergunta é o que se entende pela palavra "operacional"? Como resultado de um breve debate, decidimos que era possível aumentar o tempo de resposta de 5 a 10 minutos para que saltos de curto prazo não introduzissem ressonância no sistema.
A terceira pergunta é qual o tamanho do número equilibrado de servidores a escolher?
Esta questão foi decidida por si só. Normalmente, os clientes não fazem agregados de servidor muito grandes, e isso é consistente com as recomendações do artigo para limitar agregados a 30 a 40 servidores.
Além disso, ao segmentar o pool de servidores, simplificamos a tarefa do algoritmo de balanceamento.
A quarta pergunta é o quanto uma rede neural nos convém com seu longo processo de aprendizado e seu raro equilíbrio. Decidimos abandoná-lo em favor de algoritmos operacionais mais simples para obter o resultado em segundos.
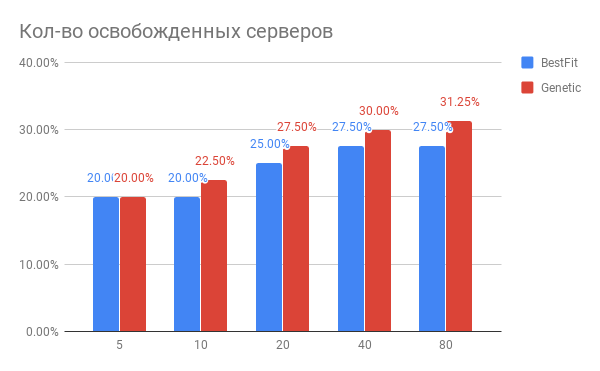
Uma descrição do sistema usando tais algoritmos e suas deficiências pode ser encontrada
aqui.Implementamos e lançamos esse sistema e recebemos resultados encorajadores - agora ele analisa regularmente a carga da nuvem e fornece recomendações sobre a movimentação de máquinas virtuais, que estão amplamente corretas. Mesmo agora, está claro que podemos obter uma liberação de recursos de 10 a 15% para novas máquinas virtuais com uma melhoria na qualidade das existentes.

Quando um desequilíbrio é detectado pela RAM ou CPU, o sistema fornece comandos para o planejador Tionics para executar a migração ao vivo das máquinas virtuais necessárias. Como pode ser visto no sistema de monitoramento, a máquina virtual mudou de um host (superior) para outro (inferior) e liberou memória no host superior (destacado em círculos amarelos), ocupando-o respectivamente no host inferior (destacado em círculos brancos).
Agora, estamos tentando avaliar com mais precisão a eficácia do algoritmo atual e tentando encontrar possíveis erros nele.
Etapa 3
Parece que você pode se acalmar com isso, aguardar eficácia comprovada e fechar o tópico.
Mas as seguintes oportunidades óbvias de otimização estão nos levando a conduzir uma nova fase.
- As estatísticas, por exemplo, aqui e aqui mostram que os sistemas de dois e quatro processadores em seu desempenho são significativamente inferiores aos sistemas de processador único. Isso significa que todos os usuários recebem retornos significativamente mais baixos de CPUs, RAMs, SSDs, LANs, FCs adquiridas em sistemas multiprocessadores em comparação com os de processador único.
- Os planejadores de recursos em si podem trabalhar com erros sérios. Aqui está um dos artigos sobre este tópico.
- As tecnologias oferecidas pela Intel e AMD para monitorar a RAM e o cache permitem que você estude o comportamento das máquinas virtuais e as coloque de maneira que vizinhos barulhentos não interfiram nas máquinas virtuais silenciosas.
- Expansão do conjunto de parâmetros (rede, armazenamento, prioridade da máquina virtual, custo da migração, disponibilidade para migração).
Total
O resultado do nosso trabalho na melhoria dos algoritmos de balanceamento foi uma conclusão inequívoca de que, devido aos algoritmos modernos, é possível obter otimização significativa dos recursos (25 a 30%) dos data centers e melhorar a qualidade do serviço ao cliente.
O algoritmo baseado em redes neurais é, obviamente, uma solução interessante que precisa de mais desenvolvimento e, devido às restrições existentes, não é adequado para resolver esses problemas em volumes característicos de nuvens privadas. Ao mesmo tempo, em nuvens públicas de tamanho significativo, o algoritmo mostrou bons resultados.
Falaremos mais sobre os recursos de processadores, agendadores e balanceamento de alto nível nos artigos a seguir.