Sincronização de esquema de banco de dados
Depois de abrir o estúdio, vá para a aba “Database Sync” e crie uma nova conexão clicando no botão “New Connection”:
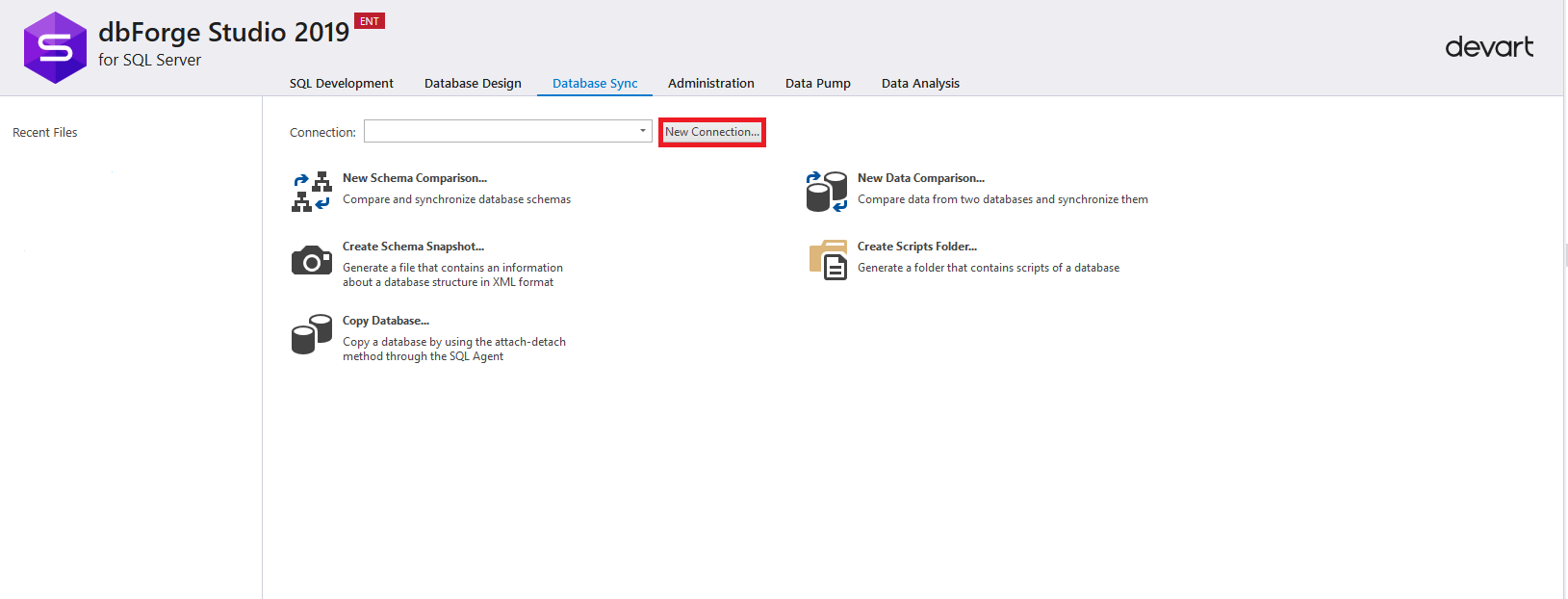
Na janela de configurações de conexão que é aberta, você deve inserir os dados necessários para se conectar à instância do MS SQL Server (servidor de origem). Observe que, além da autenticação do MS SQL Server, Windows, Active Directory, a autenticação por meio do MFA foi exibida. Após preencher todos os campos obrigatórios, clique no botão "Testar conexão" para testar a conexão:
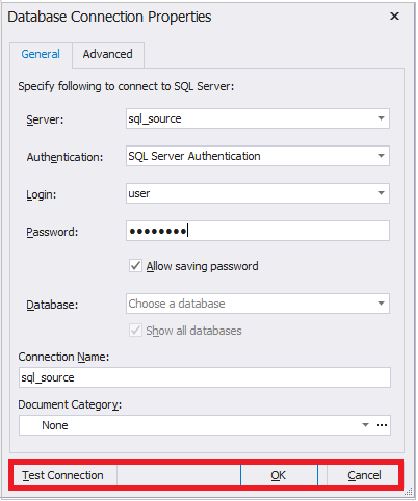
Depois que a conexão é estabelecida, a seguinte caixa de diálogo é exibida:
Em seguida, clique no botão “OK” na caixa de diálogo e o mesmo botão na janela de configurações da conexão.
Agora, uma nova conexão apareceu:

Da mesma forma, você precisa conectar todas as instâncias necessárias do MS SQL Server (neste exemplo, você precisa criar uma conexão para o servidor de destino).
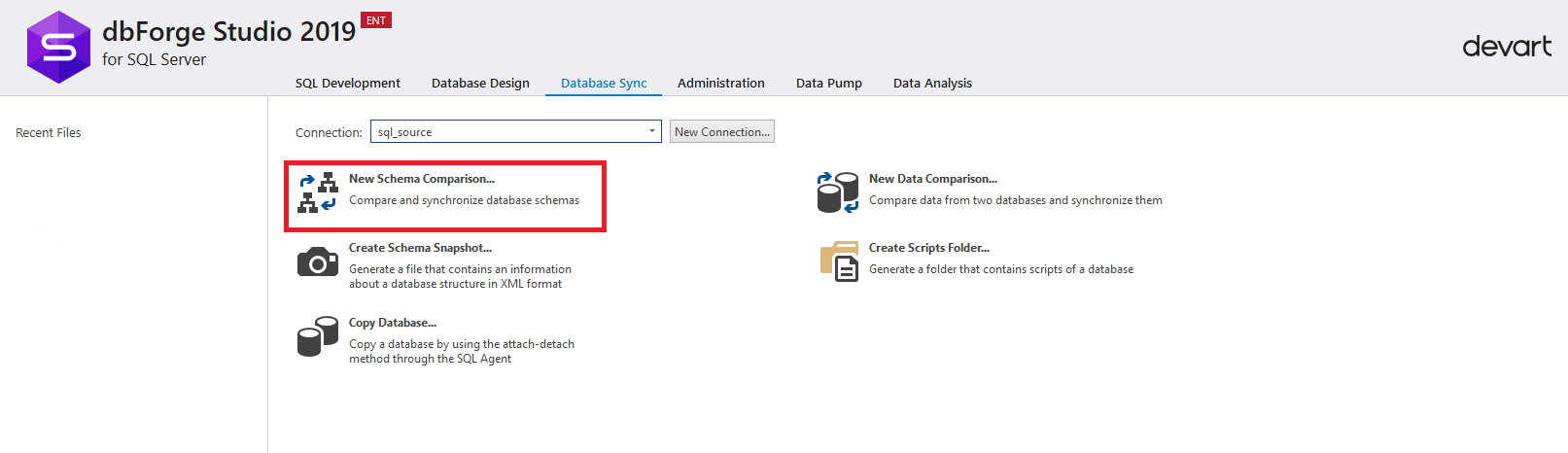
Depois disso, clique em "Nova comparação de esquema" para configurar o processo de comparação de esquemas de banco de dados no servidor de origem e o banco de dados no servidor de destino:
Uma janela de configurações para comparar circuitos será exibida.
Na guia "Origem e destino", à esquerda no painel Origem, você deve selecionar:
- tipo
- conexão
- banco de dados de origem
À direita no painel Destino, você precisa selecionar:
- tipo
- conexão
- banco de dados do receptor
Observe que no tipo você pode selecionar não apenas o banco de dados, mas também o diretório do script, instantâneo, controle de versão e backup. No nosso caso, selecionamos no tipo "banco de dados".
Após selecionar todas as configurações, você deve clicar no botão "Avançar" para continuar configurando a sincronização dos esquemas do banco de dados.
Se dois bancos de dados inicialmente idênticos forem comparados, você poderá começar imediatamente a comparar os esquemas clicando no botão "Comparar".
Se necessário, você pode acessar qualquer guia de configurações clicando no item correspondente na janela esquerda.
A qualquer momento, você pode salvar as configurações como um arquivo bat clicando no botão "Salvar linha de comando" no canto inferior esquerdo da janela.
Na maioria dos casos, ao rolar alterações entre bancos de dados inicialmente idênticos, basta clicar no botão "Comparar". Mas para estudar a funcionalidade, você deve clicar em "Avançar":
Na guia Opções, você pode definir várias configurações ou deixá-las por padrão:
Na guia "Mapeamento de esquema", você pode configurar o mapeamento de esquemas por nome:
Na guia "Mapeamento de tabela", você pode configurar o mapeamento de tabelas e colunas:

Na guia "Filtro de objetos", você pode especificar objetos para comparação.
Depois disso, se necessário, você pode retornar às etapas anteriores.
No final, você deve clicar no botão "Comparar" para iniciar o processo de comparação dos esquemas dos bancos de dados especificados:
A janela de configurações de comparação do esquema do banco de dados desaparecerá e uma janela aparecerá com um indicador do processo de comparação:

No final do processo, preste atenção na janela. Você pode alterar as configurações de comparação clicando no botão "Editar comparação" no canto superior esquerdo da janela. À direita desse botão, há um círculo com uma seta - este é o botão de atualização, que inicia o processo de comparação de esquemas novamente. Também estão localizados abaixo todos os servidores registrados anteriormente:
Através do menu principal em Arquivo, você pode salvar as configurações para comparar esquemas como um arquivo com a extensão scomp.
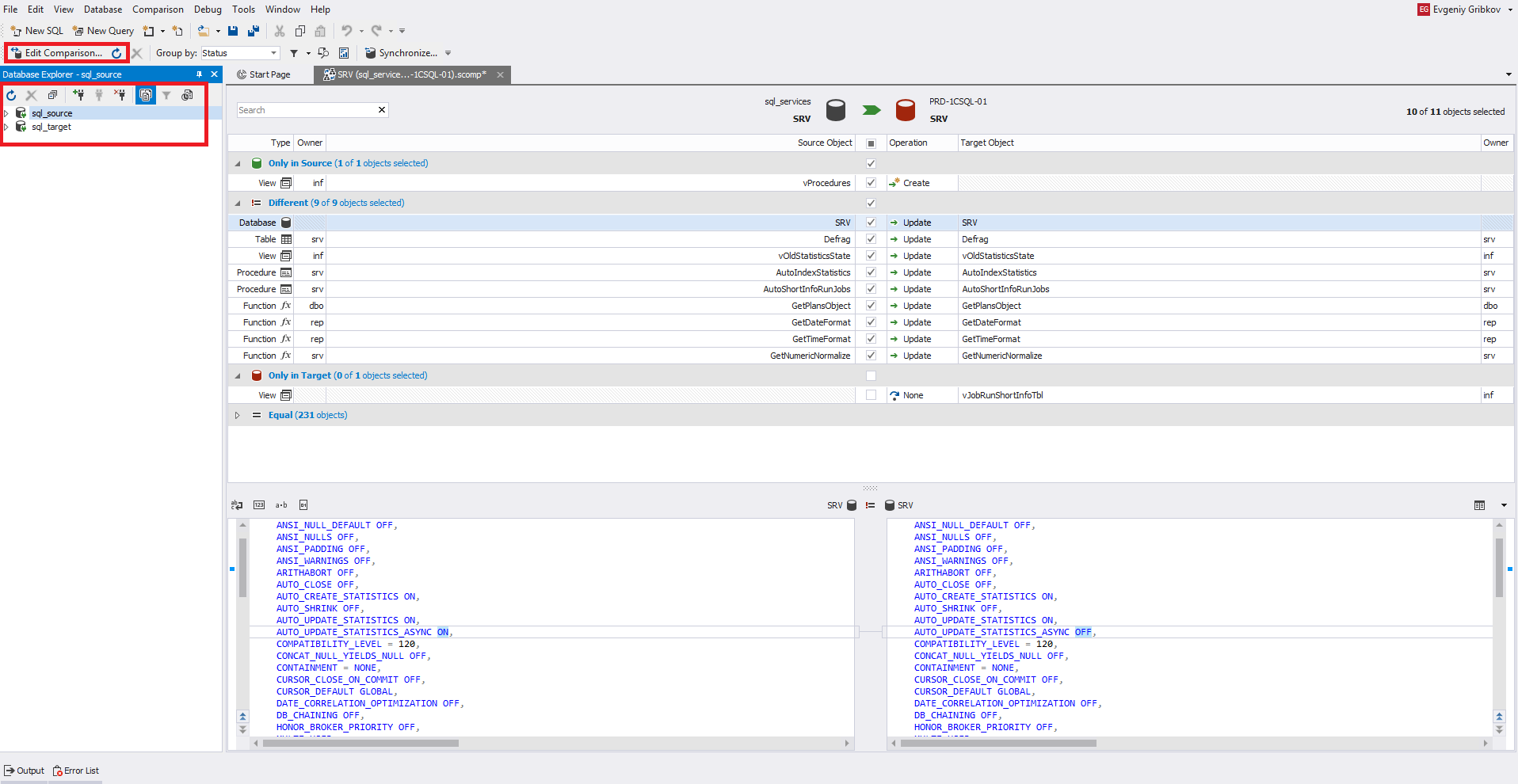
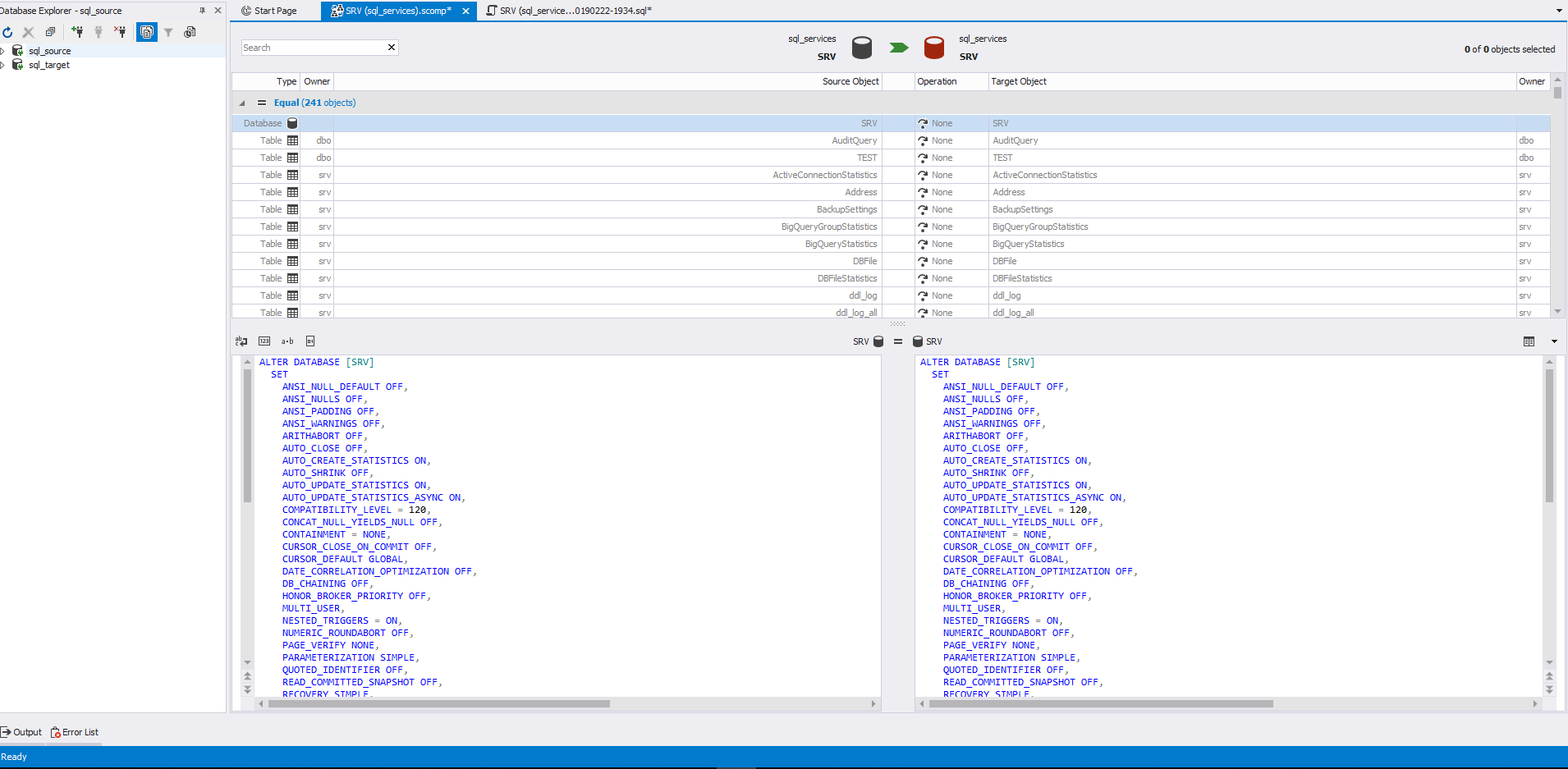
Agora vamos prestar atenção na parte central da janela. Aqui você precisa selecionar os objetos necessários para sincronização com as marcas de seleção. À esquerda estão os objetos de origem e, à direita, o receptor. Abaixo, da mesma maneira, está o código para definir objetos. Os objetos para comparação são divididos em 4 seções com uma contagem do número desses objetos em cada seção.
Aqui, uma tabela é selecionada para visualizar o código de definição, que está na fonte e no receptor. Portanto, este objeto está localizado na seção "Diferente":

Quando você seleciona esse objeto, seu código de definição à esquerda será movido para a direita ao sincronizar esquemas de banco de dados para o receptor.
Aqui, para visualizar o código de definição, é selecionada uma visualização que está apenas na fonte. Portanto, este objeto está localizado na seção "Somente na fonte" e não há um código de definição à direita:
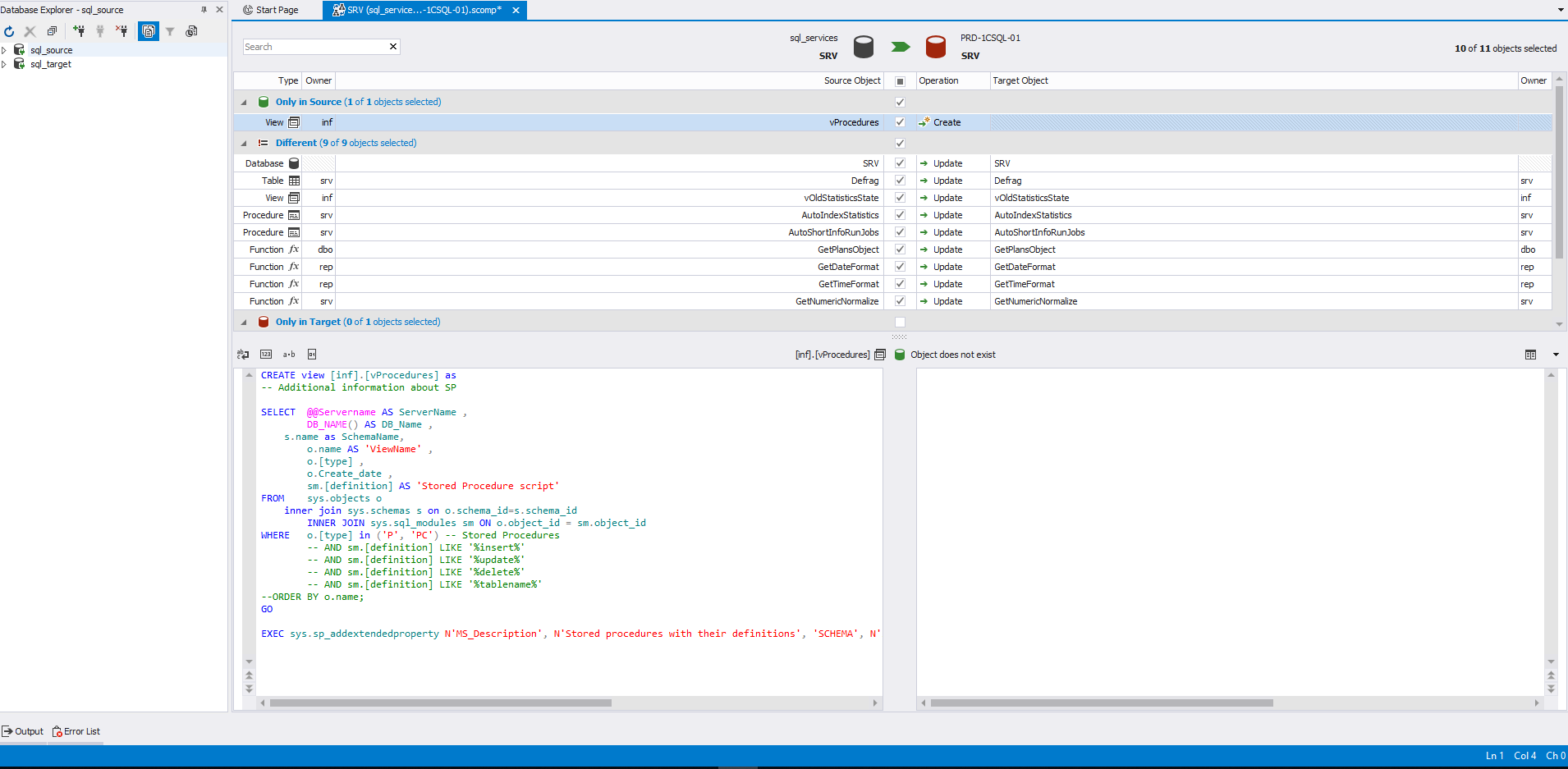
Ao escolher esse objeto, seu código de criação será gerado para o receptor.
Aqui, para visualizar o código de definição, é selecionada uma visualização que está apenas no receptor. Portanto, este objeto está localizado na seção "Somente no destino" e não há código de definição para ele à esquerda:
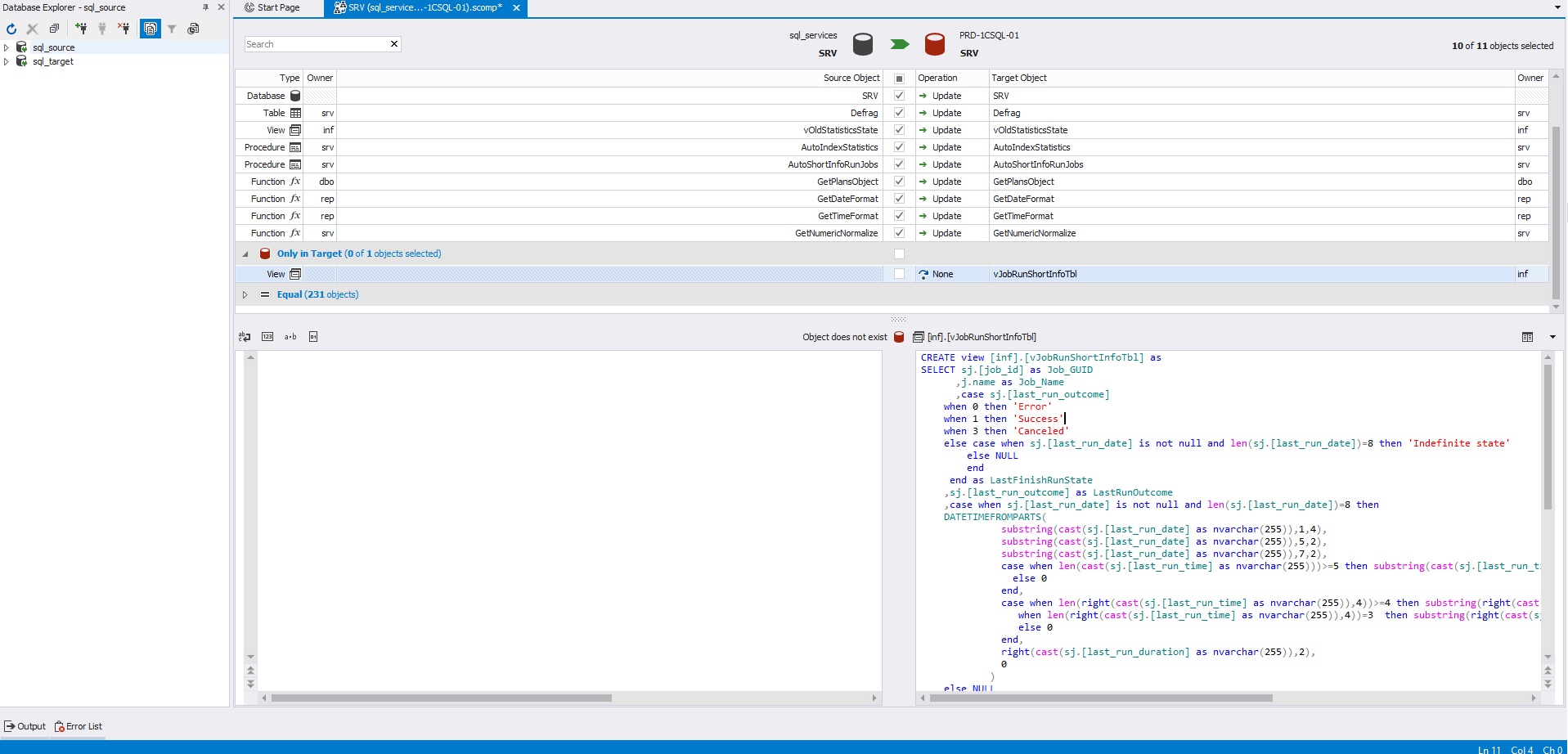
Ao escolher esse objeto, seu código de exclusão será gerado para o receptor.
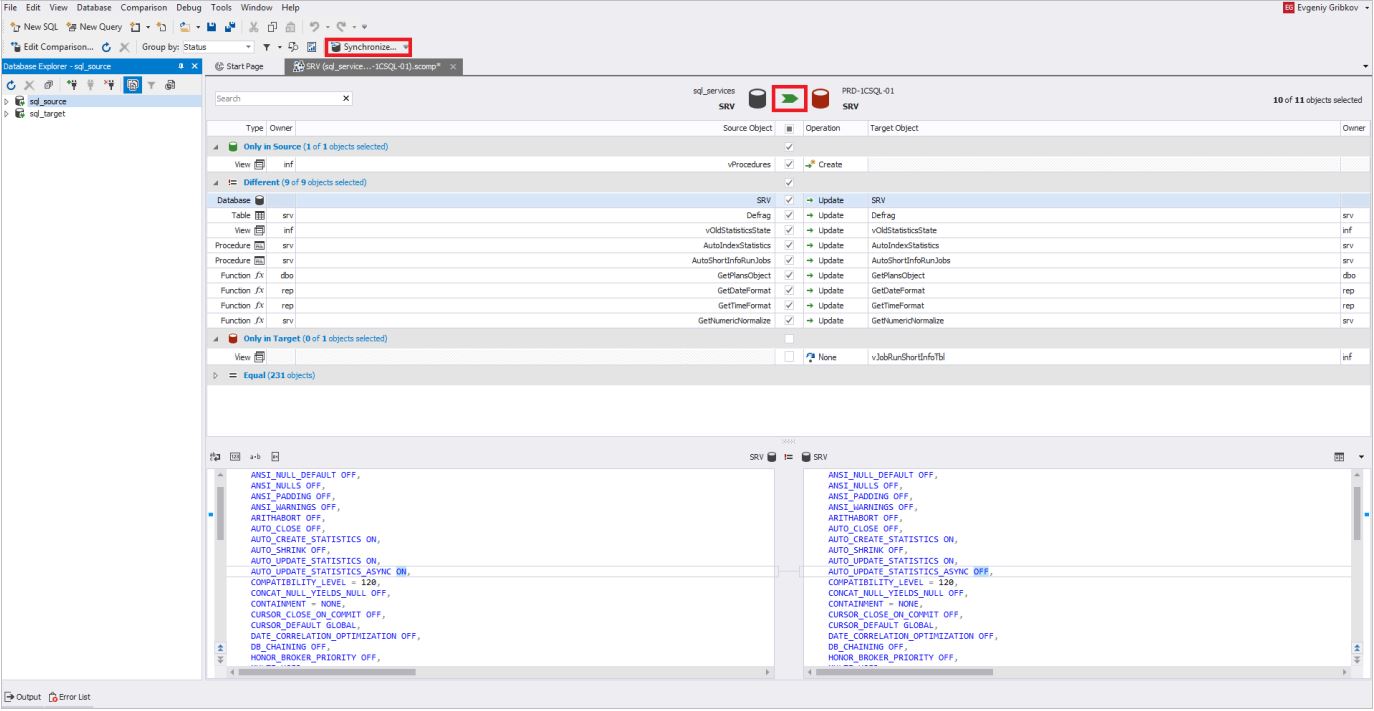
Em seguida, para iniciar o processo de sincronização dos esquemas do banco de dados, clique em um dos botões destacados em vermelho na figura:
Na guia "Saída", você deve especificar como o processo de sincronização ocorrerá. Geralmente, a geração do script é selecionada no estúdio ou em um arquivo. No nosso caso, escolheremos a primeira opção. É recomendável que você siga cuidadosamente a sequência de todas as guias para configurar o processo de sincronização:
Na guia "Opções", você pode definir várias configurações para sincronizar os esquemas do banco de dados.
Geralmente, todas as configurações do grupo de backup do banco de dados são removidas.
Por padrão, no grupo de configurações "Transações", "Usar uma única transação" e "Definir nível de isolamento da transação como SERIALIZABLE" estão definidos, o que evita situações nas quais apenas partes das alterações podem ser aplicadas - ou seja, as alterações serão aplicadas na íntegra ou de maneira nenhuma:
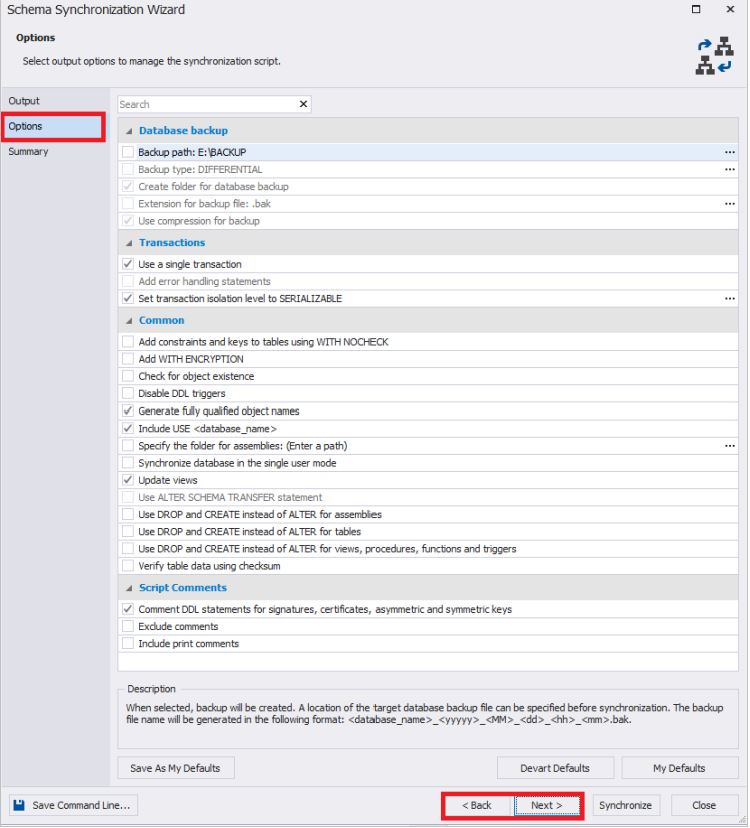
A guia Resumo exibe os resultados da seleção das configurações de sincronização. Se necessário, você pode retornar aos parágrafos anteriores.
Observe que as configurações para sincronizar esquemas de banco de dados também podem ser salvas em um arquivo bat clicando no botão "Salvar linha de comando" no canto inferior esquerdo da janela.
No final, você precisa clicar no botão "Sincronizar" para iniciar o processo de geração de um script para sincronizar os esquemas do banco de dados:
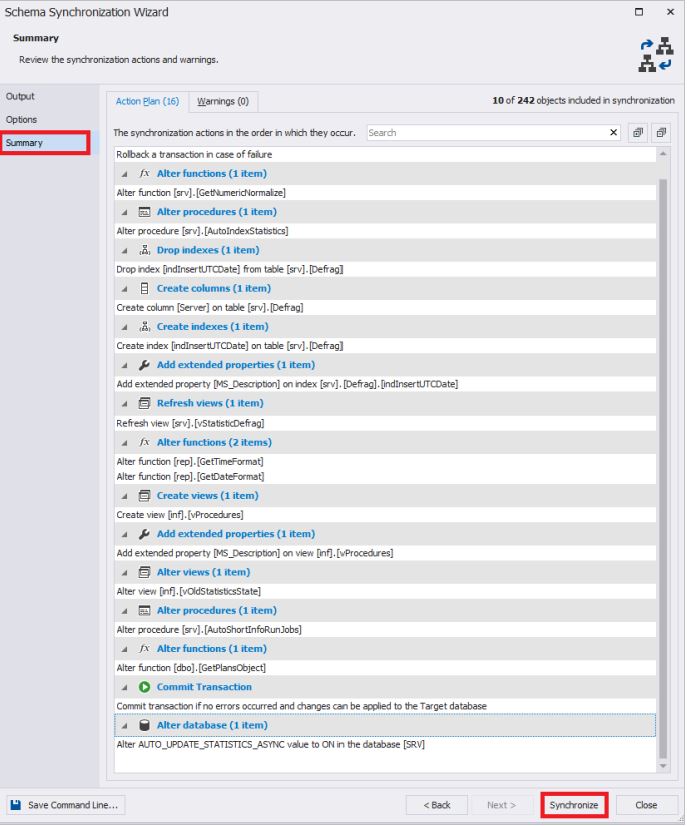
Após a conclusão, um script será gerado em uma nova janela:
Este script é o código para transferir alterações de esquema do banco de dados da origem para o receptor. Ele pode ser usado no servidor de destino ou salvo em um arquivo para uso posterior no servidor de destino. Como regra, em qualquer caso, esse script é salvo para aplicá-lo em vários servidores ao mesmo banco de dados após todas as verificações. Você pode fazer isso usando grupos de servidores registrados no SSMS enviando o script resultante imediatamente para todo o grupo de servidores desejado:
Após a sincronização, os objetos selecionados anteriormente devem desaparecer da janela de comparação de circuitos:
Sincronização de dados do banco de dados
Supõe-se que as conexões necessárias foram criadas conforme descrito acima em “Sincronização de Esquema do Banco de Dados”.
Depois disso, você precisa clicar em "Nova comparação de dados" para configurar o processo de comparação dos dados do banco de dados no servidor de origem e o banco de dados no servidor de destino:
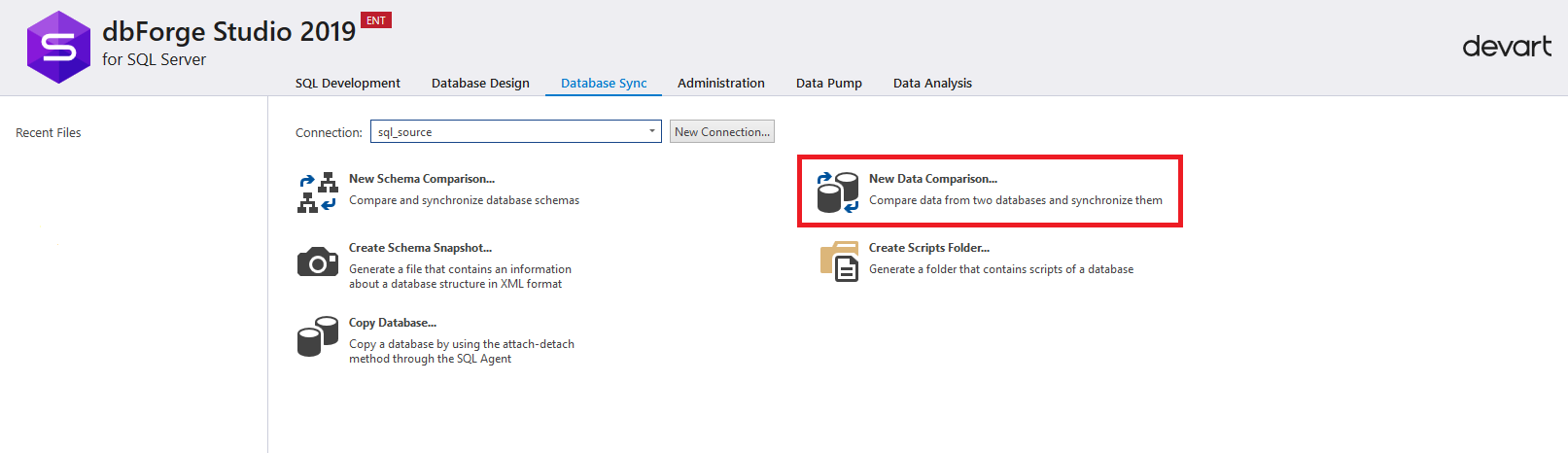
Uma janela de configurações para comparar dados será exibida.
Na guia "Origem e destino", à esquerda no painel Origem, você deve selecionar:
- tipo
- conexão
- banco de dados de origem
À direita no painel Destino, você precisa selecionar:
- tipo
- conexão
- banco de dados do receptor
Observe que no tipo você pode selecionar não apenas o banco de dados, mas também o diretório e o backup do script. No nosso caso, selecionamos no tipo "banco de dados".
Após selecionar todas as configurações, clique em “Avançar” para continuar configurando a sincronização dos dados do banco de dados.
Ao contrário da comparação de circuitos, ao comparar dados, é recomendável que você execute todas as etapas de configuração em sequência.
Se necessário, você pode acessar qualquer guia de configurações clicando no elemento da janela correspondente à esquerda.
A qualquer momento, você pode salvar as configurações como um arquivo bat clicando no botão "Salvar linha de comando" no canto inferior esquerdo da janela.
Depois de definir a guia "Origem e destino", clique em "Avançar":
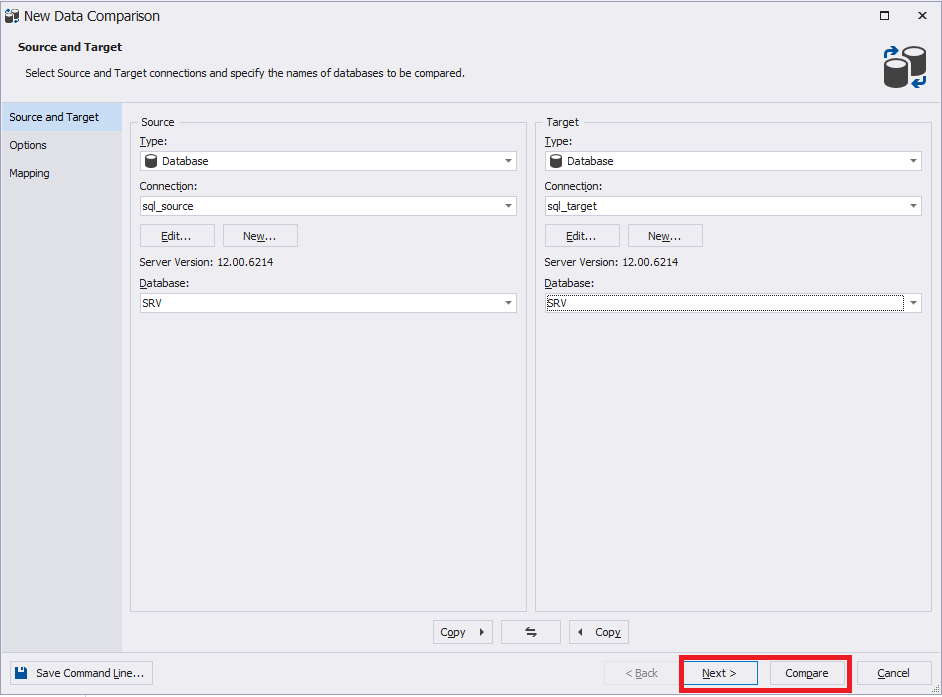
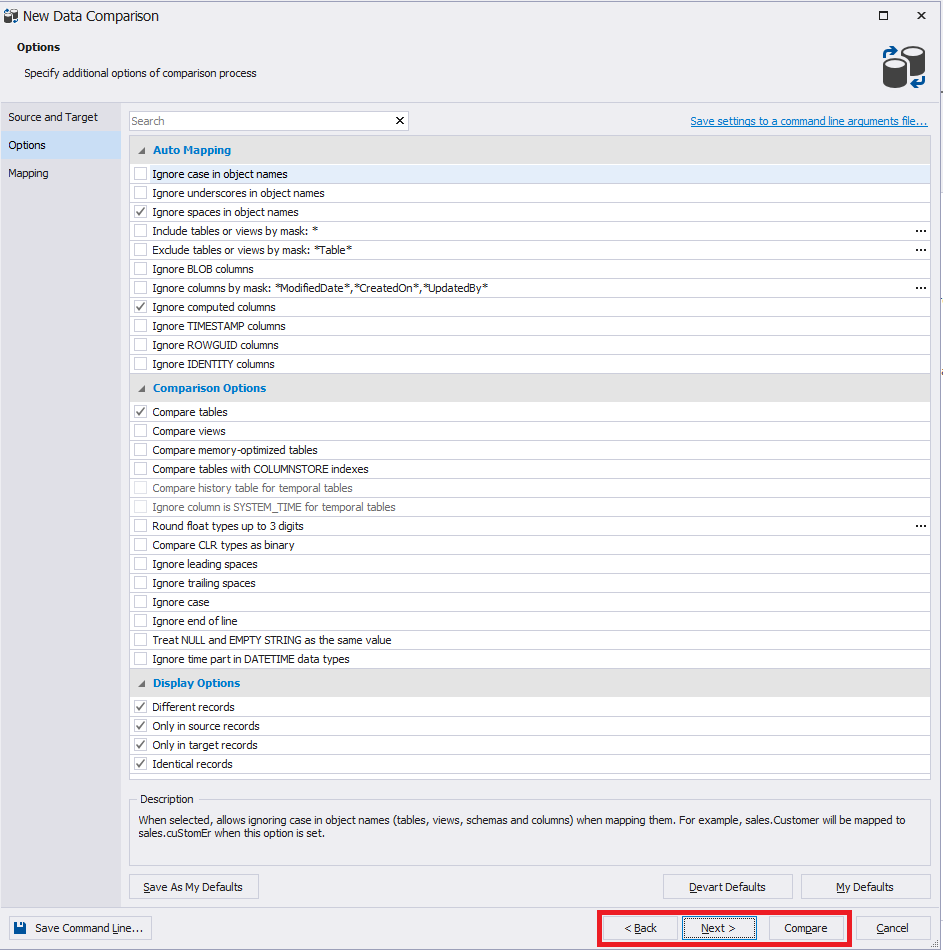
Na guia Opções, você pode definir várias configurações ou deixá-las por padrão:
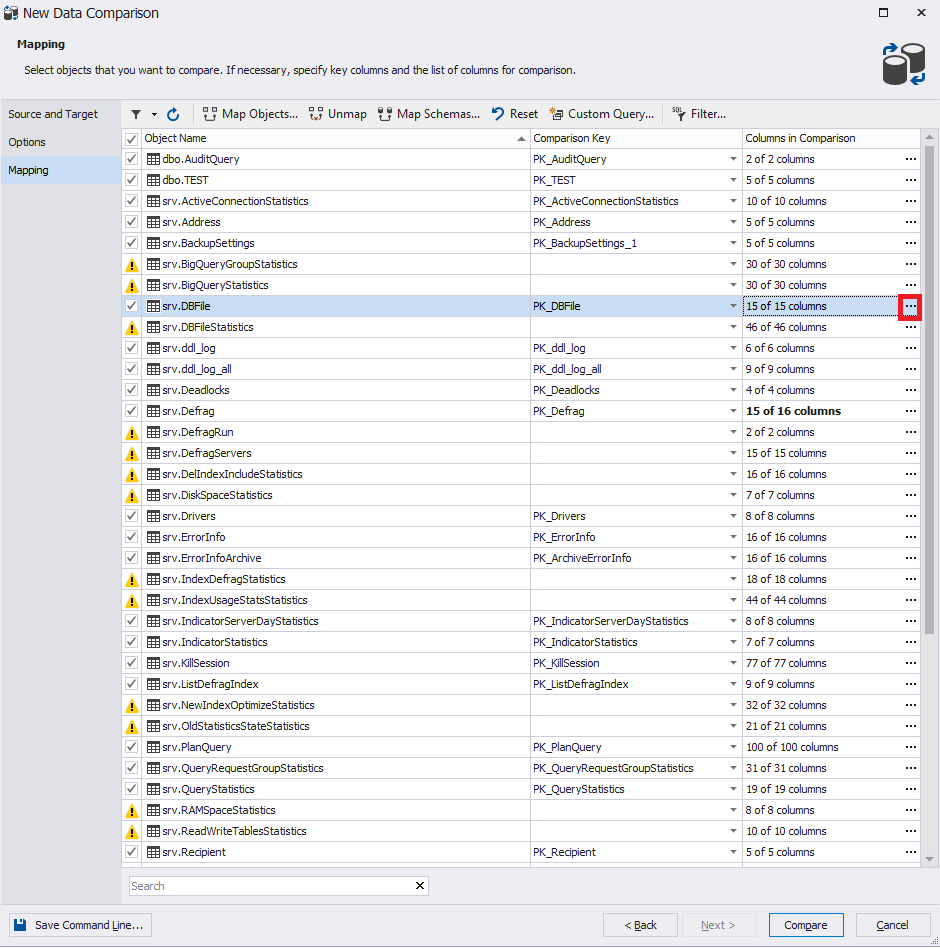
A guia "Mapeamento" fornece uma lista de tabelas para sincronização de dados. Os pontos de exclamação indicam aquelas tabelas nas quais não há chave primária. Para essas tabelas, a correspondência deve ser feita manualmente. Para fazer isso, selecione a linha desejada (tabela) e clique com o botão direito do mouse nas reticências:
A janela correspondente aparecerá:

Depois disso, se necessário, você pode retornar às etapas anteriores.
No final, clique em "Comparar" para iniciar o processo de comparação dos dados dos bancos de dados especificados:
A janela de configurações para comparar os dados do banco de dados desaparecerá e uma janela aparecerá com um indicador do andamento da comparação:
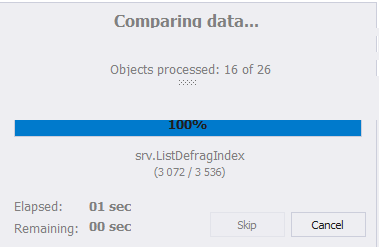
No final do processo, preste atenção na janela. Você pode alterar as configurações de comparação clicando em "Editar comparação" no canto superior esquerdo da janela. À direita desse botão, há um círculo com uma seta - este é um botão de atualização que inicia o processo de comparação de dados novamente. Também estão localizados abaixo todos os servidores registrados anteriormente:

Através do menu principal em Arquivo, você pode salvar as configurações para comparar circuitos como um arquivo com a extensão dcomp.
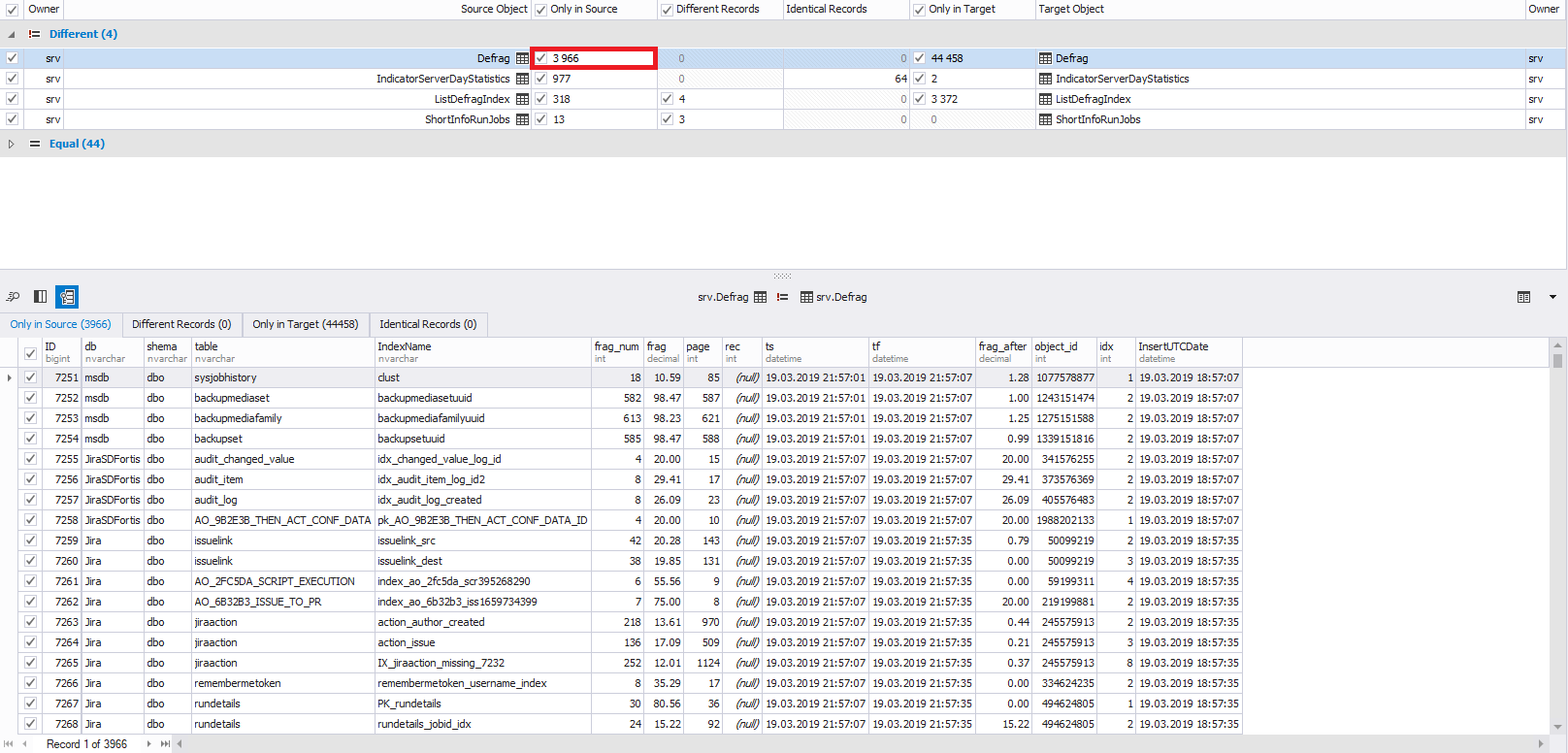
Agora vamos prestar atenção na parte central da janela. Aqui você precisa selecionar os objetos necessários para sincronização com as marcas de seleção. À esquerda estão os objetos de origem e à direita - o receptor:

As seguintes informações são exibidas abaixo:
- para linhas inseridas - dados de linhas inseridas:
- para strings mutáveis - comparação de strings:

- para linhas excluídas - dados de linhas excluídas:
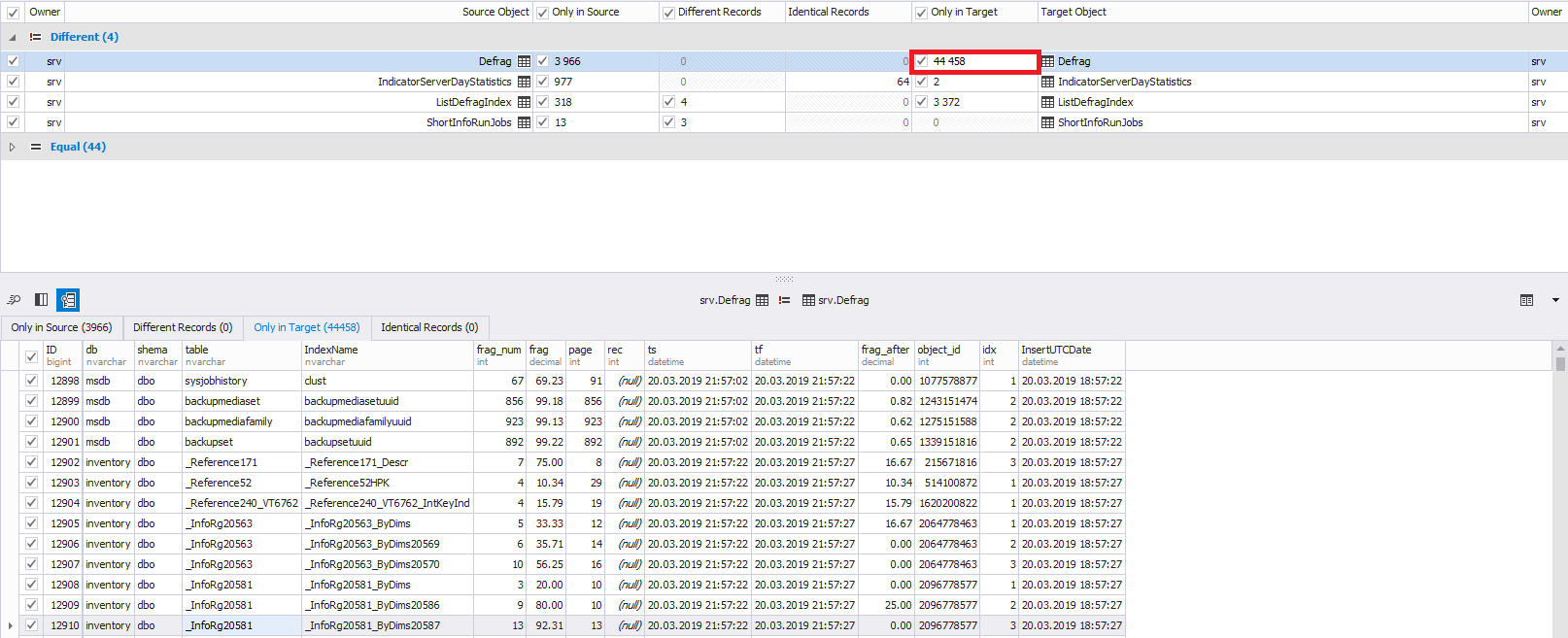
No canto inferior esquerdo, se necessário, você pode selecionar não todas as linhas para alterações, mas as que você precisa. Por padrão, todas as linhas são selecionadas:
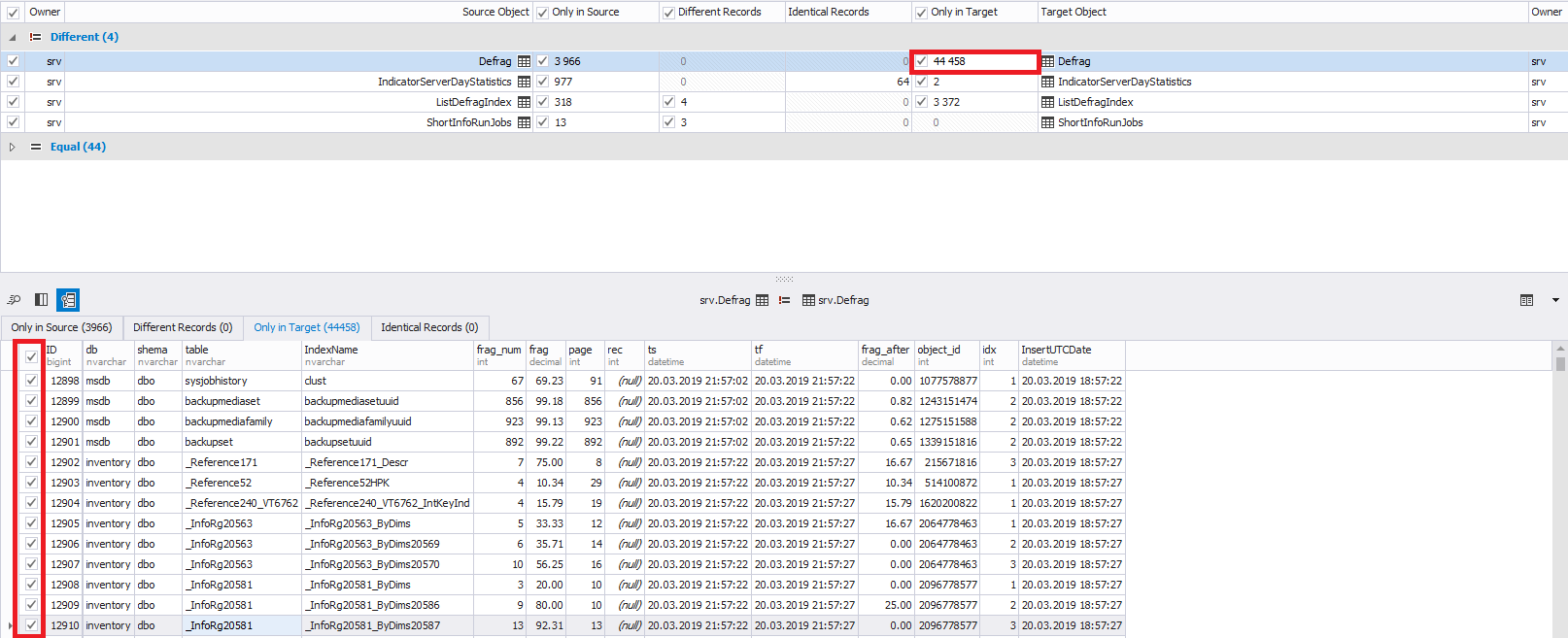
Você também pode alternar entre as linhas adicionadas, alteradas e excluídas usando as guias acima da própria tabela de dados:
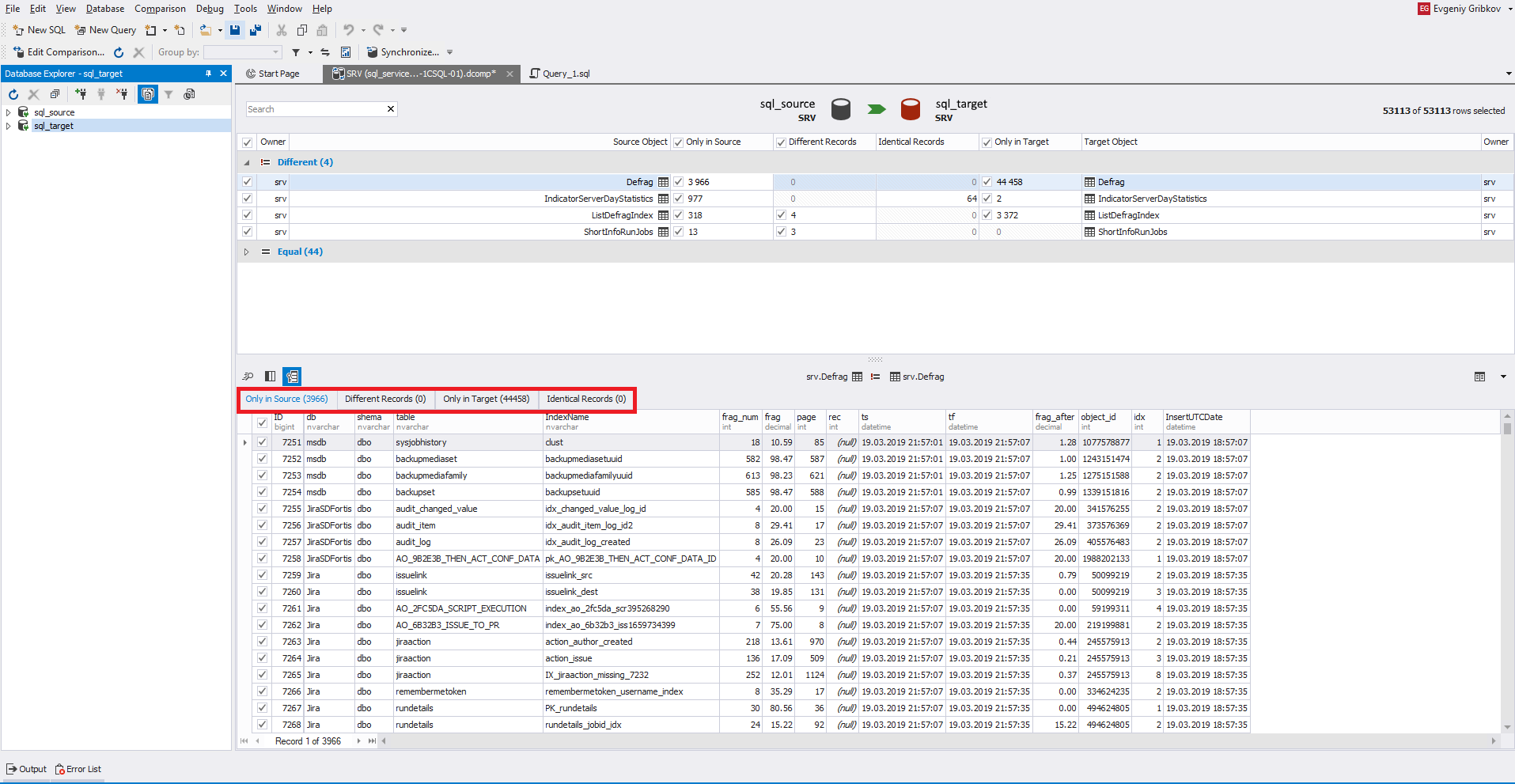
Para controlar a visibilidade das colunas (campos) desejados, existe a funcionalidade necessária:
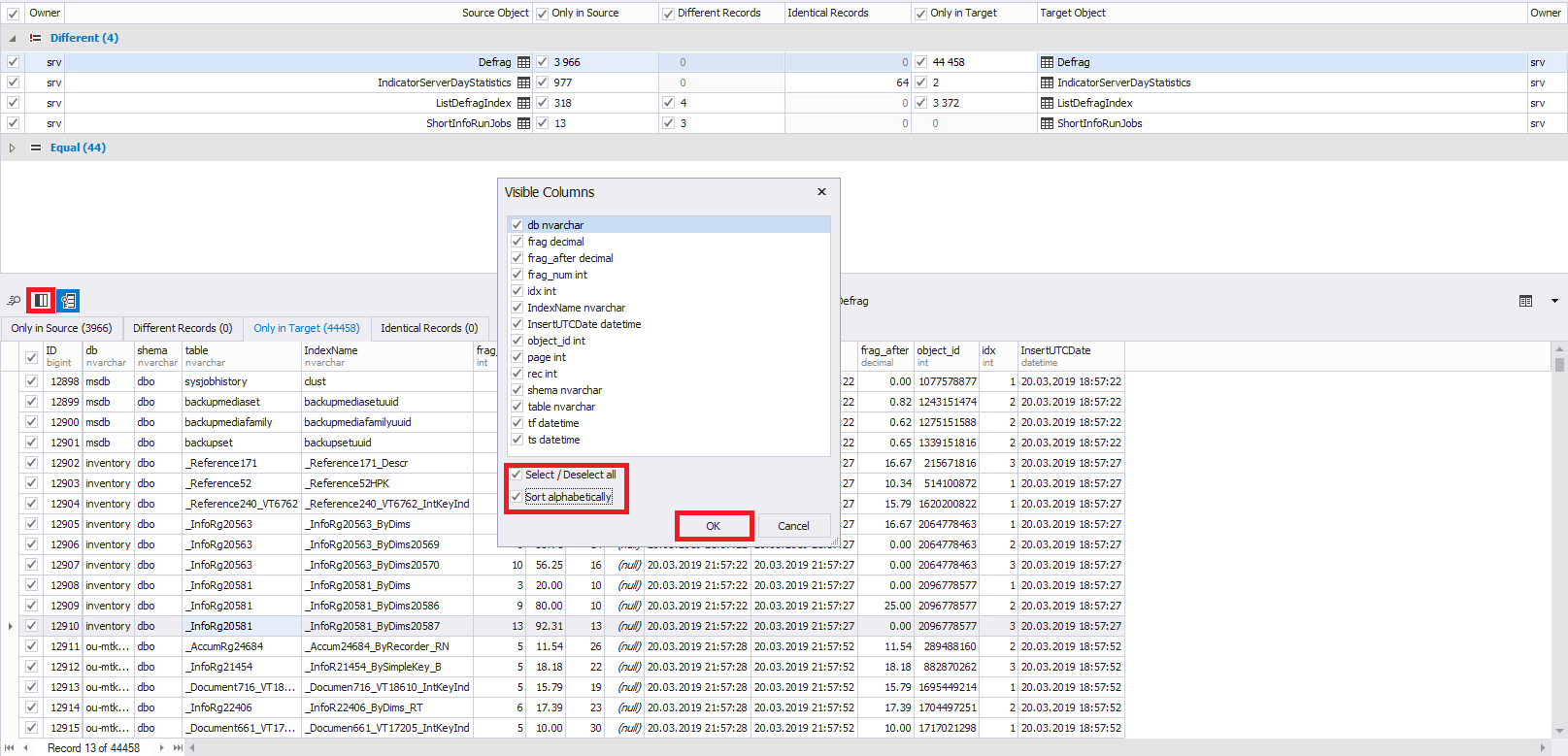
Por padrão, todas as colunas estão selecionadas.
Em seguida, para iniciar o processo de sincronização de dados do banco de dados, clique em um dos botões destacados em vermelho na imagem:

Na guia "Saída", você deve especificar como o processo de sincronização ocorrerá. Geralmente, a geração do script é selecionada no estúdio ou em um arquivo. No nosso caso, escolheremos a primeira opção. É recomendável que você siga cuidadosamente a sequência de todas as guias para configurar o processo de sincronização:
Na guia "Opções", você pode definir várias configurações para sincronização.
Geralmente, todas as configurações do grupo de backup do banco de dados são removidas.
Por padrão, no grupo de configurações "Transações", "Usar uma única transação" e "Definir nível de isolamento da transação como SERIALIZABLE" estão definidos, o que evita situações nas quais apenas partes das alterações podem ser aplicadas - ou seja, as alterações serão aplicadas na íntegra ou de maneira nenhuma:
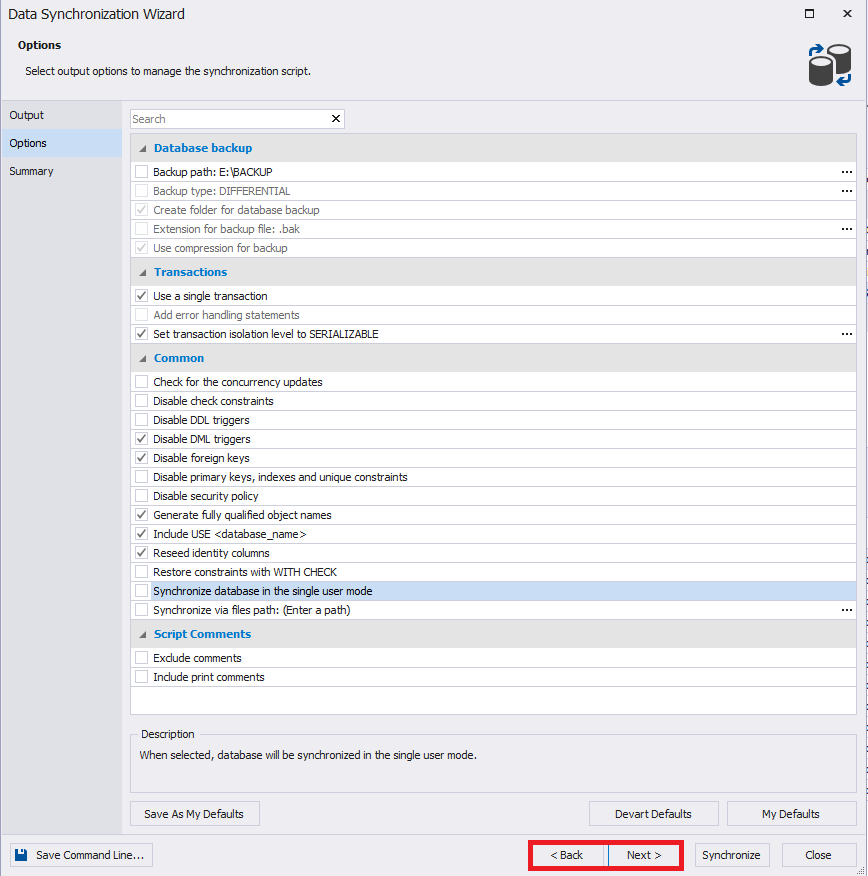
A guia Resumo exibe os resultados da seleção das configurações de sincronização. Se necessário, você pode retornar aos parágrafos anteriores.
Observe que as configurações para sincronizar esquemas de banco de dados também podem ser salvas em um arquivo bat clicando em "Salvar linha de comando" no canto inferior esquerdo da janela.
No final, você precisa clicar em "Sincronizar" para iniciar o processo de geração de um script de sincronização:
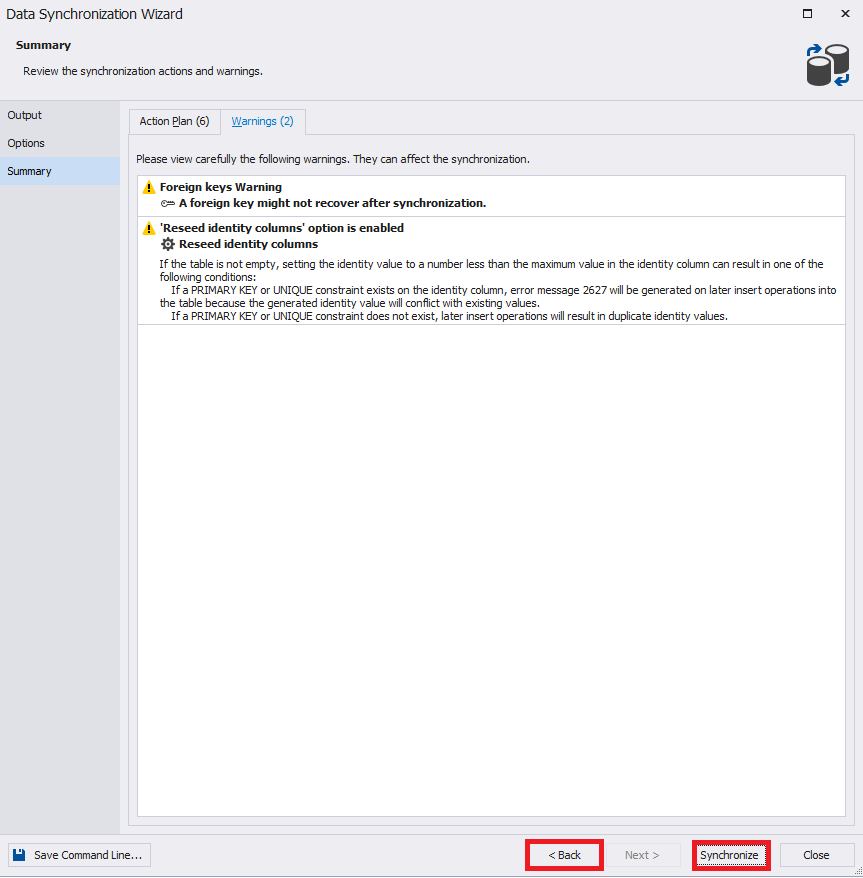
Após a conclusão, um script será gerado em uma nova janela:
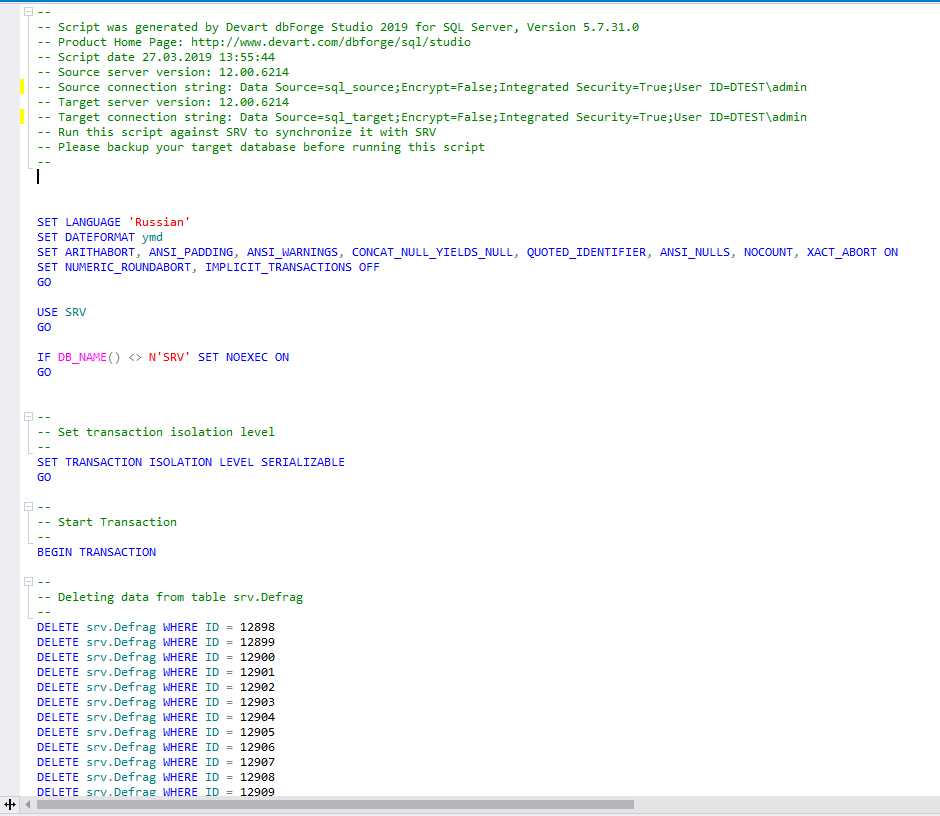
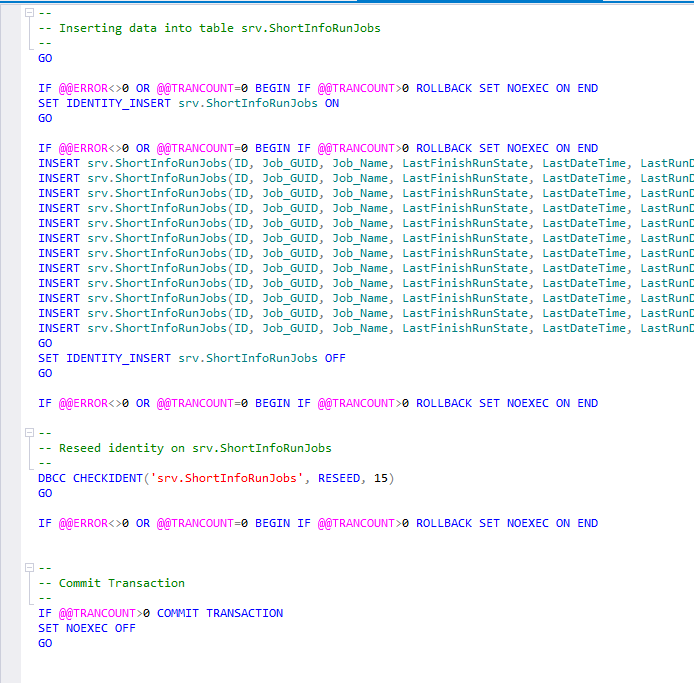
Este script é o código para transferir alterações de dados da fonte para o receptor. Pode ser aplicado no servidor receptor ou salvo em um arquivo para uso posterior no servidor receptor.
Após a sincronização, os objetos selecionados anteriormente devem desaparecer da janela de comparação de dados.
Visão geral do DbForge Compare Bundle para SQL Server
Além do dbForge Studio para SQL Server, você pode usar a ferramenta dbForge Compare Bungle para SQL Server do Devart, integrada ao SQL Server Management Studio (SSMS), para comparar dados e esquemas de banco de dados. Considere um exemplo de uso desta ferramenta no SSMS:
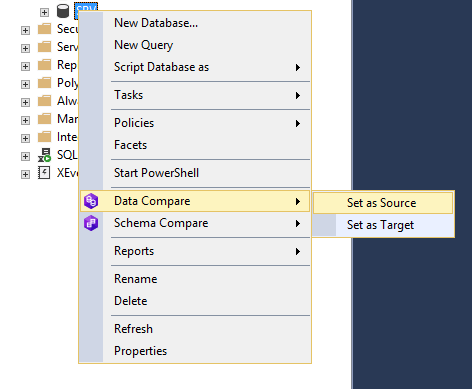
Aqui você precisa clicar com o botão direito do mouse no banco de dados desejado e selecionar a ação desejada: comparação de dados ou comparação de esquema. Depois disso, instale o banco de dados selecionado como uma fonte ou como um receptor. Da mesma forma, selecione o segundo banco de dados como receptor ou como fonte.
Após definir a fonte e o receptor, para iniciar a configuração da sincronização de dados ou do esquema do banco de dados, clique na seta verde no meio da tela:
Depois disso, a janela familiar para definir a sincronização de dados ou os esquemas do banco de dados será exibida, dependendo do que foi selecionado anteriormente.