
Sou líder de equipe e minha tarefa é garantir o trabalho produtivo da equipe. Isso não é fácil, pois não existe uma receita pronta para o sucesso. Obviamente, existem metodologias reconhecidas:
Agile ,
Lean ,
Mapeamento do Fluxo de Valor . Eles fornecem diretrizes e valores comuns, o que já é bom, mas essas são apenas diretrizes. E com soluções específicas, seja gentil, faça você mesmo. É por isso que você e o líder da equipe.
No artigo, mostrarei como a equipe e eu nos formamos gradualmente e agora refinamos regularmente a abordagem para um trabalho eficaz. O ponto principal é que as ferramentas selecionadas são realmente aceitas por toda a equipe e se enraizaram no trabalho. Isso dá esperança de que a abordagem seja útil.
Um pouco de contexto
Na True Engineering, estamos envolvidos no desenvolvimento da empresa. Nós criamos um produto enorme, com vários anos, do qual muitas equipes participam. Especificamente, nossa equipe é composta por sete pessoas: quatro desenvolvedores, um líder de equipe (escreve muito código), um controle de qualidade e uma equipe de PM. O produto em que a equipe está trabalhando tem dois anos. A condição técnica - pelos esforços de toda a equipe - é quase exemplar.
Desconforto como ferramenta de diagnóstico
Para encontrar e reconhecer problemas na equipe, usamos uma ferramenta bastante simples - o desconforto dos participantes.
Naturalmente, não se trata de uma situação em que uma pessoa tem ar condicionado e outra quente. Estou falando de falhas no fluxo normal de trabalho.
Por exemplo, o lançamento foi torto, embora cada um tenha feito bem seu trabalho individualmente. Ou a estabilização está em andamento há duas semanas e a equipe está arrasada, embora nós próprios fizemos estimativas e ninguém nos incomodou a fazer o bem. Ou o negócio não conseguiu o que esperava.
Como agir em uma situação semelhante:
- Pare o pânico e perceba por que estamos desconfortáveis agora.
- Vá para o final da causa raiz. Por exemplo, usando a técnica Five Why ou apenas senso comum.
- Decida como tratar o problema. As diretrizes para a escolha da solução certa serão discutidas no final do artigo. Aqui, observo um ponto fundamental: usamos o desconforto para diagnosticar problemas, mas isso não significa que a diretriz para a escolha de soluções seja obter conforto. Lembre-se de que o principal motivo de sua existência em equipe é o valor comercial. Ninguém precisa de uma equipe feliz que não traga resultados.
- Depois de um tempo, conduza uma retrospectiva. Se a decisão não ajudou, voltamos ao parágrafo 1 com um novo entendimento. Se ajudar, automatizamos ou adicionamos à lista de princípios para futuros iniciantes. Não é mais necessário controle, os próprios participantes adotarão a abordagem para o trabalho, se for realmente bom.
O algoritmo descrito é simples, mas os detalhes não são suficientes. A seguir, descreverei os princípios que deduzimos usando essa abordagem. Para que o artigo não se transforme em um livro de memórias, descreverei apenas o resultado obtido, e não toda a história, desde a conscientização da dor até sua eliminação.
Os princípios sobre os quais construímos o processo
1. Criamos e diminuímos constantemente os ciclos de feedback
Toda interação humana com o mundo exterior é construída com base no feedback, sem que seja impossível verificar a correção da ação executada. Imagine como seria nossa vida se não sentíssemos dor saltando de uma altura de quatro metros ou pegando um bule de chá quente.
No desenvolvimento, a conclusão do código pode servir como um exemplo de um loop de feedback curto e bom - ele nos informa sobre a exatidão da ação no momento da entrada do código.
Agora, um exemplo da ausência de um loop de feedback: conhecemos o problema com os usuários, mas não podemos reproduzi-lo, não temos logs, não há como lançar rapidamente a correção e nem sabemos qual versão está atualmente no prod. Você não desejará o inimigo.
Cada ação no processo de desenvolvimento pode e deve fornecer feedback: criar, eliminar, passar por autotestes, testes realizados, uma sessão de teste com a empresa, implantação bem-sucedida, produto de monitoramento - todas essas são maneiras de detectar erros e ajustar suas ações posteriores.
Também é importante notar que o custo do erro aumenta à medida que você avança. Se lançamos um bug de produção que estraga os dados, a tarefa não é apenas corrigi-los, mas também restaurar os dados (se possível). O custo da eliminação tardia de tal erro é muito alto, sem mencionar as consequências para os negócios.
Portanto, a presença de um grande número de loops de feedback rápidos e informativos é vital.
Abaixo estão os loops que apoiamos conscientemente e encurtamos, se possível. Eu acho que a maioria de vocês sabe. Mas você realmente os tem e trabalha?
- A capacidade de executar e executar um projeto localmente.
- Projetado para falhar rapidamente .
- Compilação de IC rápida e informativa.
- Revisão constante de código e trabalho com código por meio de solicitações pull.
- Disponibilidade de autotestes. Os testes são mensagens de erro rápidas, estáveis e informativas.
- Implantação automática, porque o manual será executado com menos frequência.
- Versões frequentes em vez de acumular e liberar uma versão uma semana após a conclusão das tarefas.
- Logs informativos, monitoramento, ferramentas de diagnóstico. Acesso a eles de toda a equipe.
- A capacidade de filtrar e visualização gráfica de logs.
- Monitoramento contínuo dos indicadores técnicos e funcionais do sistema como parte do trabalho diário.
- Estudo empírico do sistema - Google Analytics, análise dos dados acumulados no sistema.
- Armazenando o histórico de alterações de dados em vez do estado final, se aplicável.
- Trabalho conjunto e apertado dos negócios de Dev, Ops, QA, em vez de "jogar fora o muro" dos resultados do estágio anterior.
- Realização de retrospectivas regulares, tanto dentro da equipe quanto com os negócios.
- Feedback regular da empresa. Ainda melhor é o feedback do usuário final.
- A capacidade de observar o trabalho dos usuários "nos campos".
- A capacidade de observar o usuário que vê seu sistema pela primeira vez.
Em geral, o feedback em si deve ser atraente. Como, por exemplo, uma compilação quebrada.
O que é digno de nota, às vezes uma mudança muito pequena é suficiente para uma melhoria radical.
Por exemplo, você grava logs no
ELK . Eles são estruturados, analisados, publicamente disponíveis - está tudo bem. Mas com que frequência o desenvolvedor aparece durante a depuração? Provavelmente não.
Se as mensagens de nível de aviso e superiores forem exibidas diretamente no IDE, é possível observar, por exemplo, o tempo de execução da consulta. Mesmo que não esteja relacionado à tarefa atual. Há uma chance de perceber o problema mais cedo, e o custo para corrigi-lo será menor.
2. Qualquer atividade deixa artefatos públicos
Os artefatos devem ser exatamente públicos. E útil.
Graças a esse princípio, minimizamos o
fator de barramento , fornecemos uma compreensão unificada da situação, trabalhamos (e fakapim) conscientemente, tirando conclusões constantemente.
Algumas práticas são óbvias e geralmente aceitas: mensagens informativas de confirmações, conexão de confirmações com tarefas, descrição de Como Testar, Definição de Concluído.
Existem pontos menos óbvios:
- Você não pode "estragar tudo", a falha deve ser realizada. Se a análise revelar requisitos mal pensados, o refinamento deliberado se tornará um artefato para todos. Se o problema estiver na arquitetura do sistema, o artefato será o dever técnico descrito com um termo claro para entrar em trabalho.
- A quantidade de conhecimento no correio, mensageiros instantâneos, chefes deve ser mínima. Todos os refinamentos são refletidos na base de conhecimento ou no rastreador de tarefas. Portanto, quando o testador aceita a tarefa, os requisitos variáveis para ele não serão novidade. Quando uma empresa aceita um resultado, todos entendem o que devem receber. Esse estado transforma o trabalho em um fluxo contínuo. Forneça (descubra os detalhes, atualize a base de conhecimento e a descrição das tarefas) - a tarefa de cada participante no processo.
- Os resultados do teste não são apenas “verifiquei, está tudo bem”, mas uma lista disponível publicamente dos casos de teste aprovados, que foram compilados e discutidos antes do teste, e não durante ou depois. A lista pode ser estudada e complementada por cada participante no processo.
3. Respeitamos o direito do outro ao trabalho concentrado
A importância do trabalho
no fluxo e as
conseqüências da interrupção , acredito, já são bem conhecidas. Portanto, não vou me debruçar sobre o problema em detalhes, mas voltarei imediatamente para nossas práticas.
- Fones de ouvido são apenas encorajados.
- A comunicação de trabalho é assíncrona. Não distraia seu colega com uma pequena pergunta, pergunte a ele no rastreador de tarefas (consulte a seção sobre artefatos disponíveis ao público).
- Às vezes acontecem coisas que interrompem o modo normal de operação: um acidente no prod, requisitos incompreensíveis para uma tarefa já levada ao trabalho. Um sinal pode ser uma discussão barulhenta no escritório, na qual três ou mais pessoas participam. Se essa situação não for resolvida em alguns minutos, nomearei uma pessoa para esclarecer os detalhes. O restante retornará à operação normal até que o responsável forneça informações para análises adicionais.
4. Evitamos multitarefa
Porque a
multitarefa não funciona . Ela apenas se esgota, chama a atenção e adia o recebimento do resultado.
Quais práticas ajudam:
- Limite de trabalhos em andamento .
- Focar no fluxo de valor, não em recursos. Por exemplo, o primeiro desenvolvedor pode executar a tarefa em um dia e o segundo em três. Mas o primeiro será lançado apenas após uma semana. Então, o segundo leva a tarefa a funcionar. Vamos gastar mais tempo na implementação, mas entregaremos o resultado mais rapidamente (três dias em vez de uma semana e um dia) e passaremos para a próxima tarefa. Ao mesmo tempo, não estamos tentando "empurrar o que não pode ser empurrado" para o primeiro desenvolvedor e não nos distraímos com o trabalho que está "travando" em sua expectativa.
- Se várias pessoas estiverem envolvidas em uma tarefa e o trabalho estiver 90% concluído, o objetivo número um da equipe é fazer tudo para terminar os últimos 10%. Somente depois disso seguimos em frente.
5. Tomamos decisões arquitetônicas o mais tarde possível
Este não é o nosso know-how, mas
um dos princípios básicos da manufatura enxuta .
A decisão tomada e implementada limita a possibilidade de novas alterações. E se a decisão for tomada em condições de informações incompletas (e esse é quase sempre o caso), as chances de tomar a decisão errada são significativamente maiores.
Se a falha na tomada de decisão não bloquear o trabalho e não levar a um aumento exponencial da dívida técnica, ela deverá ser adiada, deixando o sistema pronto para qualquer decisão no futuro, quando tivermos mais informações.
Essa é a base do desenvolvimento - não construímos arquiteturas “grandes” antes do início do projeto. Em vez disso, tornamos o processo de refatoração seguro (consulte a seção sobre loops de feedback) e o transformamos em uma parte natural do processo.
Da mesma forma, não estamos tentando adivinhar os requisitos futuros para o sistema ou criar uma solução universal. A capacidade de refatorar com segurança é mais universal, pois possibilita fazer alterações no futuro.
6. O código está operacional a qualquer momento.
Obviamente, esse estado é inatingível no absoluto, o sistema irá quebrar periodicamente após fazer alterações. Mas isso não significa que essa característica não deva ser procurada.
Quando um colapso é uma situação anormal, e não uma norma da vida, é fácil encontrar suas causas. Geralmente, esse é o último commit. Portanto, a pessoa responsável é compreensível, as etapas a serem eliminadas são compreensíveis, fica claro quando retornamos a um estado estável.
A confiança resultante na operação do sistema oferece uma valiosa oportunidade de liberação a qualquer momento.
O segundo valor é que estamos mais confiantes em fazer promessas de disponibilidade. Se dividirmos o trabalho em duas fases: “desenvolvimento” e “estabilização”, será difícil dar uma promessa concreta, pois “estabilização” é um trabalho com problemas que ainda não conhecemos. Portanto, não podemos avaliá-los com precisão.
Se a estabilização é indissociável do desenvolvimento e existem todas as ferramentas necessárias para isso, então a situação é mais previsível.
Como mantemos o desempenho contínuo:
- Óbvio: revisão de código, autoteste, sinalizadores de recursos.
- Quaisquer alterações são implantadas imediatamente no ambiente de teste. Se estiver quebrado, você não poderá corrigi-lo mais tarde - o controle de qualidade está bloqueado.
- Testando em um fluxo contínuo imediatamente após a conclusão das tarefas, enquanto o desenvolvedor se lembra da tarefa e do código e faz correções rapidamente.
- Nós não fazemos o trabalho em partes. Se duas pessoas forem necessárias para a implementação, elas trabalharão em pares, em uma ramificação, carregue o código na ramificação principal quando estiver completamente pronto e coberto em testes.
- Automação de entrega e artefatos de entrega fixa que não precisam ser "finalizados" manualmente.
- Cada membro da equipe conhece ferramentas de diagnóstico, sabe como trabalhar com eles e sabe fazer lançamentos.
7. Somos uma equipe, não um grupo de desenvolvimento.
O que significa "equipe":
- Todo o código é revisado por pelo menos uma pessoa. Se um problema sério for descoberto, eles são incentivados a se sentar juntos e fazer a programação em pares. Compartilhar um livro, um artigo, uma explicação detalhada em vez de transmitir opiniões pessoais não tem preço.
- Em vez de desenvolvermos peças com subsequente integração dolorosa do resultado, trabalhamos em pares quando necessário.
- Não transformamos o revisor em uma ferramenta para verificar erros de digitação, trazemos solicitações limpas e pequenas para a revisão.
- Não lançamos tarefas “através da cerca”, mas entregamos cuidadosamente o trabalho de controle de qualidade, verificando você mesmo o caminho feliz. Ajudamos o controle de qualidade a entender o que e como testar, ajudamos na passagem de cenários de fronteira (por exemplo, quebras artificiais do sistema).
- O controle de qualidade, por sua vez, estuda a estrutura interna do sistema, sabe como coletar todos os detalhes necessários (logs, status dos dados) e obtém um bug extremamente informativo.
8. Cortamos caudas
Para maximizar a eficiência e a concentração do trabalho atual, eliminamos as "dívidas" associadas ao trabalho já realizado:
- As tarefas são trazidas para as vendas o mais rápido possível. Somente depois disso nós os consideramos concluídos.
- Estamos constantemente eliminando as dívidas técnicas, para que elas não atinjam o alto custo da correção (uma semana) e não bloqueiem o trabalho, arruinando os planos de entrega da funcionalidade do negócio.
- Não iniciamos tarefas que faremos "algum dia", mas excluímos tarefas de longa duração. Uma empresa certamente virá para uma tarefa quando (se) chegar a hora de fazê-la realmente. E, no caso, no rastreador de tarefas, você pode restaurar a tarefa excluída. Mas essa função nunca foi útil para nós.
- Ramos de longa duração, código comentado, To-do-shki - tudo isso é um código morto, cujo lugar está na cesta.
- Os testes instáveis são imediatamente corrigidos ou excluídos e substituídos pelos inferiores.
- Nós rastreamos tarefas "rastejantes".
O último ponto vale uma explicação separada.
Quero dizer tarefas "rastejantes" com custos de mão-de-obra inicialmente pequenos, mas permanecendo em andamento por vários dias ou semanas.
Por que isso pode ser:
- A tarefa foi inicialmente mal projetada, já exigia muitos aprimoramentos, os esclarecimentos são contraditórios ou incompletos. Então, paramos de perder tempo, paramos de trabalhar na tarefa e retornamos à declaração.
- A tarefa está em um estado de espera por um resultado de alguém. Por exemplo, um serviço de outra equipe ou refinamento de uma empresa. Mantemos essas tarefas em um lápis e não as deixamos sozinhas.
É difícil cumprir com este ponto. Primeiro de tudo, "fluência" deve ser realizado. Então você precisa tomar uma decisão decidida e voltar aos detalhes. Isso é difícil para o desenvolvedor, pois o tempo já foi gasto. E, é claro, essa decisão encontrará a resistência do negócio. Mas a prática mostra que isso reduz as chances de produzir um resultado que nem a equipe, nem a empresa, nem os usuários fiquem satisfeitos.
O gráfico do tempo do ciclo ajuda na busca de tais tarefas. Ele mostra o tempo desde o momento de levar para o trabalho até a conclusão. Se a tarefa está "fora da multidão", então este é um candidato a um exame mais atento.
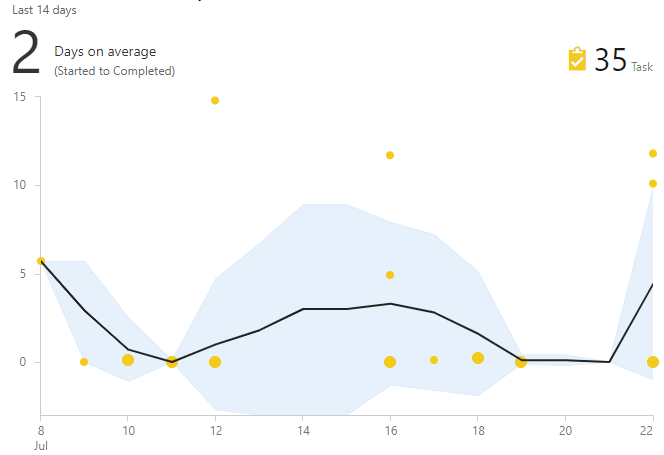
Como escolher soluções úteis
Infelizmente, não tenho uma receita pronta para uso. A eficácia da equipe é uma tarefa heurística, o que significa que não possui soluções garantidas.
Mas ainda há alguma lista de verificação. Aqui está:
- Escrevi sobre isso no início do artigo e repito aqui: o fato de usarmos desconforto para diagnosticar problemas não significa que buscamos conforto ao tomar decisões. Lembre-se do objetivo principal - aumentar o valor para os negócios.
- Ao analisar problemas, lembre-se de que todos os participantes têm boas intenções . Se o seu pensamento é baseado em uma crença paranóica de que alguém está lhe prejudicando intencionalmente, é muito difícil tomar uma boa decisão.
- Não tente quebrar tudo e reconstruir. Mova-se em pequenas etapas, fazendo alterações gradualmente. Aguarde até que as alterações feitas tragam resultados e só então introduza novas.
- Se não houver uma solução clara, faça pequenos passos, avaliando constantemente o resultado e tentando várias opções. Um loop de feedback claro e reflexão constante são uma ferramenta de desenvolvimento inesgotável para você e a equipe.
- Forje o ferro enquanto está quente. Não adie a análise até retrospectiva - a equipe já esquecerá o que estava acontecendo. É melhor chegar a uma retrospectiva com um problema já reconhecido e soluções prontas que ainda precisam ser pesadas com a equipe e escolher a melhor.
- A decisão deve ser tomada por toda a equipe. Nenhum plantio de cima funcionará, e as tentativas de controle são apenas uma ilusão.
- Não inculque nas pessoas tarefas atípicas para suas atividades diárias. Você encontrará milhares de explicações plausíveis sobre por que a promessa não foi feita, mas você não obterá o resultado.
- O efeito da decisão deve ser tangível. Você raramente conseguirá formular uma decisão sobre as características do SMART , mas deve existir alguma maneira consciente de avaliar o resultado. Pelo menos com base em "agora isso acontece com menos frequência".
- Tente gravar regularmente o que dói mais agora. Se depois de meio ano você reler as gravações com um sorriso, pensando "havia uma lata", estará no caminho certo.
Conclusão
Em conclusão, vamos discutir os pontos fracos da abordagem.
Antes de tudo, essa abordagem trabalha para buscar otimizações locais; não é possível criar uma estratégia de desenvolvimento para o produto e para toda a empresa com ele. Obviamente, a consciência dos problemas é melhor do que inconscientemente cagar e queimar no trabalho, mas este é apenas o primeiro passo.
Eu também pergunto a você, não tome uma lista pronta de princípios, leve a ferramenta com a qual foi criada. Aqui está o porquê:
Nossa lista não está completa. Ele contém apenas o que já implementamos em nosso trabalho diário.
A equipe não enraíza princípios, cuja importância ela não percebeu, através da dor de sua ausência. Em vez de idéias de trabalho, você terá um bicho-papão que todo mundo carregará pelo escritório por algum tempo e depois colocará poeira em um canto.
Nossa lista é específica. Por exemplo, se a dívida técnica do projeto for ignorada por cinco anos e for comparável à dívida pública dos EUA, será muito difícil obter o benefício do princípio do extermínio constante da dívida técnica. É justo admitir: uma dívida desse tamanho nunca será paga. E concentre-se em soluções que realmente ajudam a melhorar a situação.
Como você melhora o processo? E que princípios você já adotou em seu trabalho?