Nos últimos anos,
a tradução por máquina neural (NMP), usando os modelos "transformadores", alcançou um sucesso extraordinário. Os FMIs baseados em redes neurais profundas geralmente são treinados do começo ao fim em casos paralelos muito volumosos de textos (pares de texto) apenas com base nos próprios dados, sem a necessidade de atribuir regras exatas de linguagem.
Apesar de todos os sucessos, os modelos NMP podem ser sensíveis a pequenas alterações nos dados de entrada, que podem se manifestar na forma de vários erros - tradução insuficiente, tradução excessiva e tradução incorreta. Por exemplo, na próxima proposta alemã, o "transformador" de modelo NMP de alta qualidade será traduzido corretamente.
“O Sprecher des Untersuchungsausschusses hat angekündigt, de Gericht zu ziehen, cai no gelo e é gelado Zeugen weiterhin weigern sollten, eine Aussage zu machen.”
(Tradução automática: “O porta-voz da Comissão de Inquérito anunciou que, se as testemunhas convocadas continuarem se recusando a depor, ele será levado ao tribunal.”)
Tradução: Um representante do Comitê de Investigação anunciou que, se as testemunhas convidadas continuarem se recusando a depor, ele será responsabilizado.
No entanto, quando você faz uma pequena alteração na frase recebida, substituindo a palavra geladenen pelo sinônimo vorgeladenen, a tradução muda drasticamente (e fica incorreta):
“O Sprecher des Untersuchungsausschusses hat angekündigt, de Gericht zu ziehen, cai sich die vorgeladenen Zeugen weiterhin weigern sollten, eine Aussage zu machen.”
(Tradução automática: “O comitê de investigação anunciou que ele será levado à justiça se as testemunhas convidadas continuarem se recusando a testemunhar.”).
Tradução: o comitê de investigação anunciou que seria levado à justiça se testemunhas convidadas continuassem a se recusar a testemunhar.
A falta de estabilidade dos modelos NMP não permite que sistemas comerciais sejam aplicados a tarefas nas quais um nível semelhante de instabilidade é inaceitável. Portanto, a disponibilidade de aprender modelos de tradução sustentável não é apenas desejável, mas muitas vezes necessária. Ao mesmo tempo, embora a estabilidade das redes neurais seja estudada ativamente por uma comunidade de pesquisadores em visão computacional, existem poucos materiais sobre modelos NMP de aprendizado estável.
Em nosso
artigo, “Tradução automática sustentável com dupla entrada do adversário”, propomos uma abordagem que usa os exemplos contraditórios gerados para melhorar a estabilidade dos modelos de tradução automática para pequenas alterações de entrada. Ensinamos um modelo NMP estável para superar exemplos competitivos gerados, levando em consideração o conhecimento sobre esse modelo e para distorcer suas previsões. Mostramos que essa abordagem melhora a eficiência do modelo NMP em testes padrão.
Treinamento de modelo com AdvGen
Um modelo NMP ideal deve gerar traduções semelhantes para entradas diferentes que apresentem pequenas diferenças. A idéia de nossa abordagem é interferir no modelo de tradução usando contribuições competitivas na esperança de aumentar sua estabilidade. Isso é feito usando o algoritmo "geração competitiva" (Adversarial Generation, AdvGen), que gera exemplos competitivos válidos que interferem no modelo e os alimenta no modelo para treinamento. Embora esse método seja inspirado na idéia de redes adversárias generativas (GSS), ele não usa uma rede discriminadora, mas simplesmente usa um exemplo competitivo no treinamento, diversificando e expandindo o conjunto de treinamentos.
O primeiro passo é ultrajar os dados com o AdvGen. Começamos usando um transformador para calcular a perda de uma transferência com base na oferta original recebida, na oferta de entrada de destino e na oferta de saída de destino. O AdvGen então seleciona aleatoriamente as palavras na frase original, agindo no pressuposto de sua distribuição uniforme. Cada palavra tem uma lista correspondente de palavras semelhantes, ou seja, candidatos de substituição. A partir dele, o AdvGen seleciona a palavra que provavelmente leva a erros na saída do transformador. Então essa sentença adversária gerada é devolvida ao transformador, iniciando o estágio de defesa.
 Primeiro, o modelo do transformador é aplicado à sentença recebida (canto inferior esquerdo) e, em seguida, a perda de conversão é calculada juntamente com a sentença de saída alvo (acima do topo) e a sentença de entrada alvo (no meio à direita, começando com "<sos>"). O AdvGen então aceita a sentença original, a distribuição de seleção de palavras, os candidatos a palavras e a perda de tradução como entrada e cria um exemplo de código-fonte contraditório.
Primeiro, o modelo do transformador é aplicado à sentença recebida (canto inferior esquerdo) e, em seguida, a perda de conversão é calculada juntamente com a sentença de saída alvo (acima do topo) e a sentença de entrada alvo (no meio à direita, começando com "<sos>"). O AdvGen então aceita a sentença original, a distribuição de seleção de palavras, os candidatos a palavras e a perda de tradução como entrada e cria um exemplo de código-fonte contraditório.No estágio de defesa, o código fonte do adversário é retornado ao transformador. A perda de conversão é contada novamente, mas desta vez usando a fonte de entrada controversa. Usando o mesmo método de antes, o AdvGen usa uma sentença de entrada direcionada, distribuição de seleção de palavras calculada a partir da matriz de atenção, candidatos à substituição de palavras e perda de tradução para criar um exemplo de código fonte contencioso.
 No estágio de defesa, o código fonte do adversário se torna a entrada do transformador e as perdas de conversão são calculadas. Usando o mesmo método de antes, o AdvGen cria um exemplo de código fonte controverso com base na entrada de destino.
No estágio de defesa, o código fonte do adversário se torna a entrada do transformador e as perdas de conversão são calculadas. Usando o mesmo método de antes, o AdvGen cria um exemplo de código fonte controverso com base na entrada de destino.Finalmente, a sentença contraditória é retornada ao transformador e a perda de estabilidade é calculada com base no exemplo da fonte adversária, no exemplo de entrada do alvo adversário e na sentença alvo. Se a intervenção no texto levou a perdas significativas, elas são minimizadas para que, quando os modelos encontrarem perturbações semelhantes, ela não repita o mesmo erro. Por outro lado, se o distúrbio leva a pequenas perdas, nada acontece, o que sugere que o modelo já é capaz de lidar com esses distúrbios.
Desempenho do modelo
Demonstramos a eficácia de nossa abordagem aplicando-a a testes de tradução padrão do chinês para o inglês e do inglês para o alemão. Obtemos uma melhoria significativa na tradução em 2,8 e 1,6 pontos BLEU, respectivamente, em comparação com o modelo concorrente do transformador, e alcançamos um novo recorde de qualidade de tradução.
 Comparação de modelos de transformadores em testes padrão
Comparação de modelos de transformadores em testes padrãoEm seguida, avaliamos o desempenho do nosso modelo em um conjunto de dados barulhento usando um procedimento semelhante ao descrito para o AdvGen. Tomamos dados de entrada puros, por exemplo, aqueles usados em testes padrão de tradutores e selecionamos aleatoriamente palavras que substituímos por palavras semelhantes. Concluímos que nosso modelo mostra estabilidade aprimorada em comparação com outros modelos recentes.
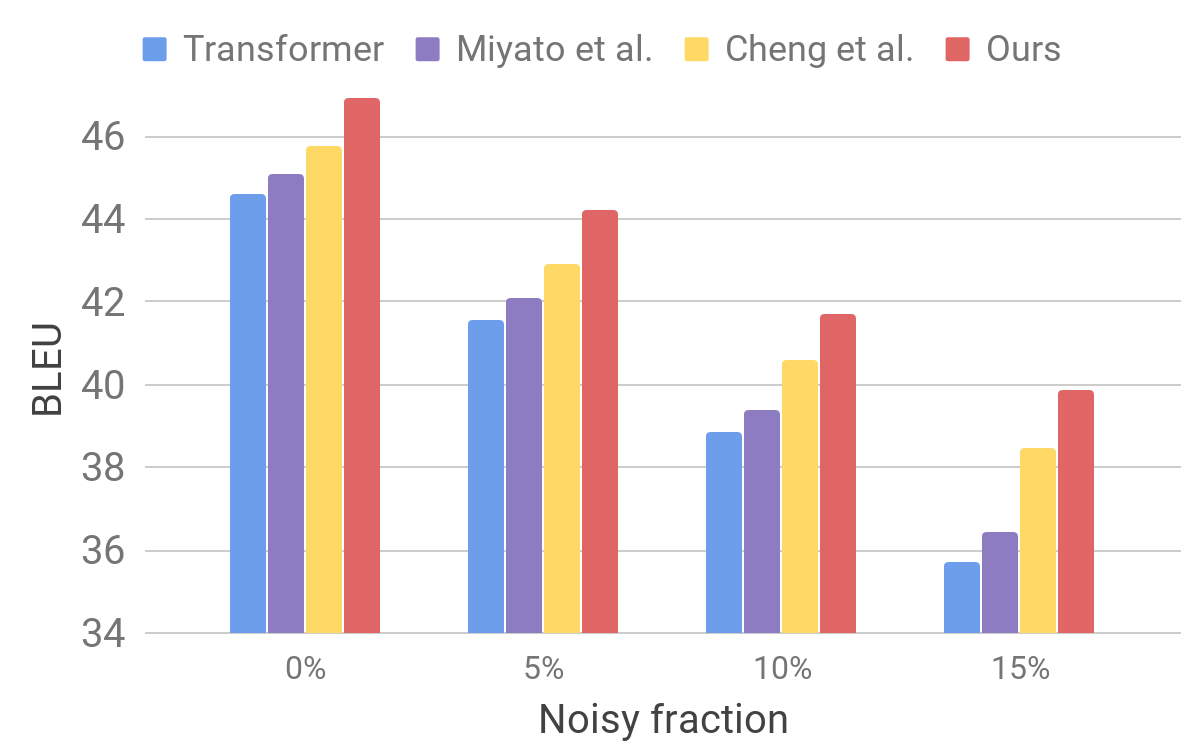 Comparação de transformadores e outros modelos em dados de entrada artificialmente ruidosos
Comparação de transformadores e outros modelos em dados de entrada artificialmente ruidososEsses resultados mostram que nossos métodos são capazes de superar pequenos distúrbios que surgem na frase recebida e melhorar a eficiência da generalização. Ele está à frente dos modelos de tradução concorrentes e alcança eficiência recorde de tradução em testes padrão. Esperamos que nosso modelo de tradutor se torne uma base estável para melhorar os resultados da solução de muitos dos seguintes problemas, especialmente aqueles que são sensíveis ou intolerantes a textos de entrada imperfeitos.