Embora as redes neurais tenham começado a ser usadas para síntese de fala há pouco tempo ( por exemplo ), elas já conseguiram superar as abordagens clássicas e a cada ano experimentam tarefas cada vez mais novas.
Por exemplo, alguns meses atrás, houve uma implementação de síntese de fala com clonagem de voz em tempo real . Vamos tentar descobrir em que consiste e realizar nosso modelo de fonema multilíngue (russo-inglês).
Prédio
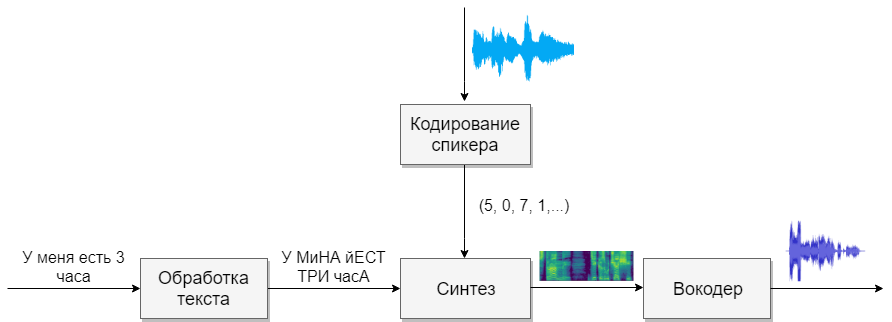
Nosso modelo consistirá em quatro redes neurais. O primeiro converterá o texto em fonemas (g2p), o segundo converterá o discurso que queremos clonar em um vetor de sinais (números). O terceiro sintetizará os espectrogramas Mel com base nas saídas dos dois primeiros. E finalmente, o quarto receberá som de espectrogramas.
Conjuntos de dados
Este modelo precisa de muito discurso. Abaixo estão as bases que ajudarão com isso.
Processamento de texto
A primeira tarefa será o processamento de texto. Imagine o texto na forma em que ele será dublado. Representaremos números em palavras e abriremos abreviações. Leia mais no artigo sobre síntese . Essa é uma tarefa difícil, portanto, suponha que já processamos o texto (ele foi processado nos bancos de dados acima).
A próxima pergunta a ser feita é se deve usar grafema ou gravação de fonema. Para uma voz monofônica e monolíngue, um modelo de letra também é adequado. Se você deseja trabalhar com um modelo multilíngue para várias vozes, recomendamos que você use a transcrição (Google também ).
G2p
Para o idioma russo, existe uma implementação chamada russian_g2p . Ele é construído sobre as regras do idioma russo e lida bem com a tarefa, mas tem desvantagens. Nem todas as palavras enfatizam e também não são adequadas para um modelo multilíngue. Portanto, pegue o dicionário criado para ela, adicione o dicionário para o idioma inglês e alimente a rede neural (por exemplo, 1 , 2 )
Antes de treinar a rede, vale a pena considerar que sons de diferentes idiomas soam semelhantes e você pode selecionar um caractere para eles e para o qual é impossível. Quanto mais sons houver, mais difícil será o aprendizado do modelo e, se houver muito poucos, o modelo terá sotaque. Lembre-se de enfatizar caracteres individuais com vogais estressadas. Para o idioma inglês, o estresse secundário desempenha um papel pequeno, e eu não o distinguiria.
Codificação do Alto-falante
A rede é semelhante à tarefa de identificar um usuário por voz. Na saída, usuários diferentes recebem vetores diferentes com números. Sugiro usar a implementação do próprio CorentinJ, que se baseia no artigo . O modelo é um LSTM de três camadas com 768 nós, seguido por uma camada totalmente conectada de 256 neurônios, fornecendo um vetor de 256 números.
A experiência mostrou que uma rede treinada em inglês fala bem com o russo. Isso simplifica muito a vida, pois o treinamento requer muitos dados. Eu recomendo pegar um modelo já treinado e reciclar o inglês da VoxCeleb e LibriSpeech, além de todo o discurso em russo que você encontrar. O codificador não precisa de uma anotação de texto de fragmentos de fala.
Treinamento
- Execute
python encoder_preprocess.py <datasets_root> para processar os dados - Execute "visdom" em um terminal separado.
- Execute
python encoder_train.py my_run <datasets_root> para treinar o codificador
Síntese
Vamos para a síntese. Os modelos que conheço não captam som diretamente do texto, porque é difícil (muitos dados). Primeiro, o texto produz som na forma espectral e somente então a quarta rede se traduz em uma voz familiar. Portanto, primeiro entendemos como a forma espectral está associada à voz. É mais fácil descobrir o problema inverso de como obter um espectrograma do som.
O som é dividido em segmentos de 25 ms em incrementos de 10 ms (o padrão na maioria dos modelos). Então, usando a transformada de Fourier para cada peça, o espectro é calculado (oscilações harmônicas, cuja soma dá o sinal original) e apresentado na forma de um gráfico, em que a faixa vertical é o espectro de um segmento (em frequência) e na horizontal - uma sequência de segmentos (no tempo). Este gráfico é chamado de espectrograma. Se a frequência for codificada de forma não linear (as frequências mais baixas são melhores que as superiores), a escala vertical será alterada (necessária para reduzir os dados), então esse gráfico é chamado de espectrograma Mel. É assim que a audição humana funciona: ouvimos um ligeiro desvio nas frequências mais baixas do que nas altas, portanto a qualidade do som não será afetada.
Existem várias implementações de síntese de espectrogramas boas, como Tacotron 2 e Deepvoice 3 . Cada um desses modelos possui suas próprias implementações, por exemplo 1 , 2 , 3 , 4 . Usaremos (como CorentinJ) o modelo Tacotron da Rayhane-mamah.
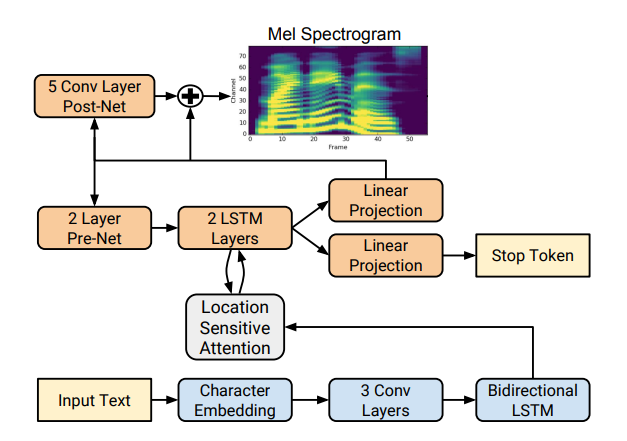
O Tacotron é baseado na rede seq2seq com um mecanismo de atenção. Leia os detalhes no artigo .
Treinamento
Não se esqueça de editar utils / symbols.py se você sintetizar não apenas a fala em inglês, hparams.p, mas também preprocess.py.
A síntese requer muito som limpo e bem marcado de diferentes alto-falantes. Aqui uma língua estrangeira não vai ajudar.
- Execute
python synthesizer_preprocess_audio.py <datasets_root> para criar som e espectrogramas processados - Execute
python synthesizer_preprocess_embeds.py <datasets_root> para codificar o som (obtenha os sinais de uma voz) - Execute
python synthesizer_train.py my_run <datasets_root> para treinar o sintetizador
Vocoder
Agora resta apenas converter os espectrogramas em som. Para isso, a última rede é o vocoder. Surge a questão: se os espectrogramas são obtidos a partir do som usando a transformada de Fourier, é possível obter o som novamente usando a transformação inversa? A resposta é sim e não. As oscilações harmônicas que compõem o sinal original contêm amplitude e fase, e nossos espectrogramas contêm informações apenas sobre amplitude (para reduzir parâmetros e trabalhar com espectrogramas); portanto, se fizermos a transformação inversa de Fourier, obteremos um som ruim.
Para resolver esse problema, eles inventaram um algoritmo rápido de Griffin-Lim. Ele faz a transformação inversa de Fourier do espectrograma, obtendo um som "ruim". Então ele faz uma conversão direta desse som e recebe um espectro que já contém um pouco de informação sobre a fase, e a amplitude não muda no processo. Em seguida, a transformação inversa é realizada novamente e um som mais limpo é obtido. Infelizmente, a qualidade da fala gerada por esse algoritmo deixa muito a desejar.
Foi substituído por vocoders neurais como WaveNet , WaveRNN , WaveGlow e outros. CorentinJ usou o modelo WaveRNN por fatchord

Para pré-processamento de dados, duas abordagens são usadas. Obtenha espectrogramas pelo som (usando a transformação de Fourier) ou pelo texto (usando o modelo de síntese). O Google recomenda uma segunda abordagem.
Treinamento
- Execute
python vocoder_preprocess.py <datasets_root> para sintetizar espectrogramas - Execute
python vocoder_train.py <datasets_root> para vocoder
Total
Temos um modelo de síntese de fala multilíngue que pode clonar uma voz.
Executar caixa de ferramentas: python demo_toolbox.py -d <datasets_root>
Exemplos podem ser ouvidos aqui
Dicas e conclusões
- Precisa de muitos dados (> 1000 votos,> 1000 horas)
- A velocidade de operação é comparável com o tempo real apenas na síntese de pelo menos 4 frases
- Para o codificador, use o modelo pré-treinado para o idioma inglês, um pouco de reciclagem. Ela está indo bem
- Um sintetizador treinado em dados "limpos" funciona melhor, mas clona pior do que aquele que treinou em um volume maior, mas com dados sujos
- O modelo funciona bem apenas nos dados em que estudei
Você pode sintetizar sua voz on-line usando colab , ou ver minha implementação no github e baixar meus pesos .