Olá pessoal, algumas informações "de baixo do capô" são a data da oficina de engenharia de Alfastrakhovaniya - o que excita nossas mentes técnicas.

O Apache Spark é uma ferramenta maravilhosa que permite processar rápida e facilmente grandes quantidades de dados em recursos de computação bastante modestos (refiro-me ao processamento de cluster).
Tradicionalmente, o notebook jupyter é usado no processamento de dados ad hoc. Em combinação com o Spark, isso nos permite manipular quadros de dados de longa duração (o Spark lida com a alocação de recursos, os quadros de dados vivem em algum lugar do cluster, sua vida útil é limitada pela vida útil do contexto do Spark).
Após a transferência do processamento de dados para o Apache Airflow, a vida útil dos quadros é bastante reduzida - o contexto do Spark "vive" na mesma instrução Airflow. Como contornar isso, por que contornar e o que Livy tem a ver com isso - leia abaixo.
Vejamos um exemplo muito, muito simples: suponha que precisamos desnormalizar dados em uma tabela grande e salvar o resultado em outra tabela para processamento adicional (um elemento típico do pipeline de processamento de dados).
Como faríamos isso:
- dados carregados no quadro de dados (seleção de uma tabela e diretórios grandes)
- olhou com "olhos" para o resultado (funcionou corretamente)
- dataframe salvo na tabela Hive (por exemplo)
Com base nos resultados da análise, podemos precisar inserir na segunda etapa algum processamento específico (substituição de dicionário ou outra coisa). Em termos de lógica, temos três etapas
- passo 1: baixar
- passo 2: processamento
- passo 3: salvar
No notebook jupyter, é assim que fazemos - podemos processar os dados baixados por um tempo arbitrariamente longo, dando controle aos recursos do Spark.
É lógico esperar que essa partição possa ser transferida para o Airflow. Ou seja, para ter um gráfico desse tipo

Infelizmente, isso não é possível ao usar a combinação Airflow + Spark: cada instrução Airflow é executada em seu próprio interpretador python; portanto, entre outras coisas, cada instrução deve de alguma forma "persistir" os resultados de suas atividades. Assim, nosso processamento é "compactado" em uma etapa - "desnormalizar dados".
Como a flexibilidade do notebook jupyter pode ser trazida de volta ao Airflow? É claro que o exemplo acima "não vale a pena" (talvez, pelo contrário, seja uma boa etapa de processamento compreensível). Mas ainda assim - como fazer com que as instruções do Airflow sejam executadas no mesmo contexto do Spark no espaço comum do quadro de dados?
Welcome Livy
Outro produto do ecossistema Hadoop vem em socorro - o Apache Livy.
Não tentarei descrever aqui que tipo de "besta" é. Se for muito breve e preto e branco - o Livy permite "injetar" o código python em um programa que o driver executa:
- primeiro criamos uma sessão animada
- depois disso, temos a capacidade de executar código python arbitrário nesta sessão (muito semelhante à ideologia jupyter / ipython)
E para tudo isso existe uma API REST.
Voltando à nossa tarefa simples: com Livy, podemos salvar a lógica original de nossa desnormalização
- na primeira etapa (a primeira declaração do nosso gráfico), carregaremos e executaremos o código de carregamento de dados no quadro de dados
- na segunda etapa (segunda instrução) - execute o código para o processamento adicional necessário desse quadro de dados
- na terceira etapa - o código para salvar o quadro de dados na tabela
O que, em termos de Airflow, pode ser assim:
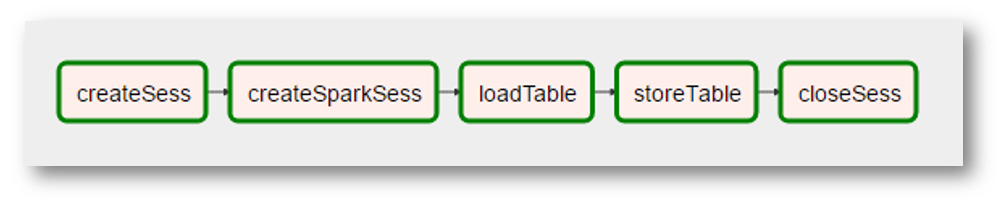
(como a imagem é uma captura de tela muito real, foram adicionadas "realidades" adicionais - a criação do contexto do Spark se tornou uma operação separada com um nome estranho, o "processamento" dos dados desapareceu porque não era necessário etc.)
Para resumir, obtemos
- declaração de fluxo de ar universal que executa código python em uma sessão Livy
- a capacidade de "organizar" o código python em gráficos bastante complexos (Airflow para isso)
- a capacidade de lidar com otimizações de nível superior, por exemplo, em que ordem precisamos executar nossas transformações para que o Spark possa manter os dados gerais na memória do cluster pelo maior tempo possível
Um pipeline típico para a preparação de dados para modelagem contém cerca de 25 consultas em 10 tabelas, é óbvio que algumas tabelas são usadas com mais frequência que outras (os "dados comuns") e há algo para otimizar.
O que vem a seguir
A capacidade técnica foi testada, pensamos mais - como traduzir tecnologicamente nossas transformações para esse paradigma. E como abordar a otimização mencionada acima. Ainda estamos no início desta parte de nossa jornada - quando há algo interessante, vamos compartilhá-lo definitivamente.