Em busca de um DataSet interessante e simples, me deparei com esse homem bonito .
Sobre esta beleza
Ele contém dados sobre o crescimento e o peso de 10.000 homens e mulheres . Sem descrição. Nada "supérfluo". Somente altura, peso e marca do piso. Eu gostei dessa simplicidade misteriosa.
Bem, vamos começar!
O que foi interessante para mim?
- Qual é a faixa de peso e altura para a maioria dos homens e mulheres?
- Que tipo de homem "médio" e mulher "média" são eles?
- O modelo simples de aprendizado de máquina KNN desses dados pode prever peso por altura ?
Vamos lá!

Primeiro olhar
Primeiro, carregue os módulos necessários
Quando as bibliotecas se levantaram exatamente - era hora de carregar o próprio DataSet e examinar os 10 primeiros elementos. Isso é necessário para que nosso intestino fique calmo, para que carregemos tudo corretamente.
A propósito, não se assuste com o fato de altura e peso diferirem do que estamos acostumados. Isso ocorre por um sistema de medição diferente: polegadas e libras , em vez de centímetros e quilogramas .
data = pd.read_csv('weight-height.csv') data.head(10)
Bom! Vemos que as dez primeiras entradas são "homens". Vemos sua altura e peso . Dados carregados bem.
Agora você pode ver o número de linhas no conjunto.
data.shape >> (10000, 3)
Dez mil linhas / registros. E cada um tem três parâmetros . O que você precisa!
É hora de consertar o sistema de medição. Agora, aqui estão centímetros e quilogramas.
data['Height'] *= 2.54 data['Weight'] /= 2.205
Agora tornou-se mais familiar. E o primeiro registro nos fala sobre um homem com uma altura de ~ 190cm e um peso de ~ 110kg. Grande homem. Vamos chamá-lo de Bob.
Mas como entender: é muito ou pouco comparado ao resto? É possível que estejamos todos mais ou menos feijões? Isso é um pouco mais tarde.
Agora vamos descobrir quão simétricos são os dois gêneros nesse conjunto de dados?
data['Gender'].value_counts() >> Male 5000 Female 5000 Name: Gender, dtype: int64
Idealmente igualmente dividido. E isso é bom, porque se houvesse: 9999 homens e uma mulher, não faria sentido fingir que este DataSet revela ambos os sexos igualmente bem. No nosso caso, está tudo bem!
Divida e aprenda!
Agora, a intuição sugere que será correto separar os dois sexos e explorar separadamente. De fato, na vida vemos frequentemente que homens e mulheres têm mais ou menos altura e peso diferentes
Vamos dar uma olhada nas pequenas estatísticas descritivas que o módulo pandas nos oferece.
Homens :
data_male.describe()
Mulheres :
data_female.describe()
Um pequeno programa educacional com as informações acimaEm linguagem simples:
Estatísticas descritivas são um conjunto de números / características para uma descrição. Talvez seja o tipo de estatística mais fácil de entender.
Imagine que você está descrevendo os parâmetros de uma bola. Pode ser:
- grande / pequeno
- liso / áspero
- azul / vermelho
- saltando / e não realmente.
Com uma forte simplificação, podemos dizer que a estatística descritiva está envolvida nisso . Mas ele faz isso não com bolas, mas com dados.
E aqui estão os parâmetros da tabela acima:
- count - O número de instâncias.
- média - A média ou soma de todos os valores divididos por seu número.
- std - O desvio padrão ou raiz da variação. Mostra a dispersão dos valores em relação à média.
- min - O valor mínimo ou mínimo.
- 25% - Primeiro quartil. Mostra um valor abaixo do qual 25% dos registros estão.
- 50% - segundo quartil ou mediana. Mostra um valor acima e abaixo do qual o mesmo número de entradas.
- 75% - Terceiro Quartil. Por anologia, com o primeiro quartil, mas abaixo de 75% dos registros.
- max - O valor máximo ou máximo.
O valor médio é muito sensível às emissões! Se quatro pessoas recebem um salário de 10.000 ₽, e o quinto - 460.000 ₽. Essa média será - 100 000 ₽. E a mediana permanecerá a mesma - 10 000 ₽.
Isso não significa que a média seja um indicador ruim. Ele precisa ser tratado com mais cuidado.
A propósito, também há um problema com a mediana.
Se o número de medições for ímpar. Essa mediana é o valor no meio, se você colocar os dados "por crescimento".
E se for uniforme, a mediana é a média entre as duas "mais centrais".
Se o conjunto de dados contiver apenas números inteiros e a mediana for fracionária, não se surpreenda. Muito provavelmente, o número de medições é par.
Um exemplo :
O filho trouxe marcas da escola. Ele recebeu cinco lições: 1, 5, 3, 2, 4
Cinco classificações → valor ímpar
Crescimento: 1, 2, 3, 4, 5
Pegue a central - 3
Escore mediano - 3
No dia seguinte, o filho trouxe da escola novas notas: 4, 2, 3, 5
Quatro classificações → valor ímpar
Construímos por crescimento: 2, 3, 4, 5
Pegue as peças centrais: 3, 4
Nós encontramos a média deles: 3,5
Mediana - 3,5
Conclusão: Filho bem feito :)
Vemos que nos homens a média e a mediana são 175cm e 85kg. E nas mulheres : 162cm e 62kg. Isso nos diz que não há emissões fortes. Ou são simétricos nos dois lados da mediana. O que é muito raro.
Mas ambos os sexos apresentam pequenos desvios da média em relação à mediana. Mas eles são insignificantes e são visíveis apenas aos centésimos. Vamos seguir em frente!
Histograma
Este é um gráfico que plota os valores do mínimo ao máximo em ordem de crescimento e mostra o número de instâncias individuais.
fig, axes = plt.subplots(2,2, figsize=(20,10)) plt.subplots_adjust(wspace=0, hspace=0) axes[0,0].hist(data_male['Height'], label='Male Height', bins=100, color='red') axes[0,1].hist(data_male['Weight'], label='Male Weight', bins=100, color='red', alpha=0.4) axes[1,0].hist(data_female['Height'], label='Female Height', bins=100, color='blue') axes[1,1].hist(data_female['Weight'], label='Female Weight', bins=100, color='blue', alpha=0.4) axes[0,0].legend(loc=2, fontsize=20) axes[0,1].legend(loc=2, fontsize=20) axes[1,0].legend(loc=2, fontsize=20) axes[1,1].legend(loc=2, fontsize=20) plt.savefig('plt_histogram.png') plt.show()

Os dados são distribuídos em forma de sino. Muito semelhante à distribuição normal .
Além de testes estatísticos para distribuição normal, há um teste visual. Se a distribuição por tipo e lógica parecer normal - podemos assumir com algumas suposições que estamos lidando com ela.
Pode-se fazer um teste estatístico de normalidade e determinar o valor de p, mas Eu não posso isso está além do escopo do artigo.
Aprendendo a trabalhar com canetas
Os pandas podem contar muito para nós. Mas você precisa contar pelo menos uma vez algumas estatísticas. Agora vou mostrar como calcular o desvio padrão .
Vamos fazê-lo no exemplo dos homens e na característica - crescimento.
Média
Formula
M= frac1N soma limitesNi=1ni
onde
- M - valor médio
- N é o número de instâncias
- ni - instância única
Código:
mean = data_male['Height'].mean() print('mean:\t{:.2f}'.format(mean)) >> mean: 175.33
Altura média - 175cm
Desvio ao quadrado
di=(ni−M)2
onde
- di - desvio único
- ni - instância única
- M - média
Código:
data_male['Height_d'] = (data_male['Height'] - mean) ** 2 data_male['Height_d'].head(10) >> 0 149.927893 1 0.385495 2 166.739089 3 47.193692 4 4.721246 5 20.288347 6 0.375539 7 2.964214 8 25.997623 9 200.149603 Name: Height_d, dtype: float64
Dispersão
Formula
D= frac1N soma limitesNi=1di
onde
- D é o valor da dispersão
- di - desvio único
- N é o número de instâncias
Código:
disp = data_male['Height_d'].mean() print('disp:\t{:.2f}'.format(disp)) >> disp: 52.89
Dispersão - 53
Desvio padrão
Formula
std= sqrtD
onde
- std - valor do desvio padrão
- D é o valor da dispersão
Código:
std = disp ** 0.5 print('std:\t{:.2f}'.format(std)) >> std: 7.27
Desvio Padrão - 7
Intervalos de confiança
Agora vamos descobrir em quais faixas de crescimento e peso 68%, 95% e 99.7% de homens e mulheres estão .
Isso não é tão difícil - você precisa adicionar e subtrair o desvio padrão da média. É assim:
- 68% - mais ou menos um desvio padrão
- 95% - mais ou menos dois desvios padrão
- 99,7% - mais ou menos três desvios padrão
Escrevemos uma função auxiliar que considerará isso:
def get_stats(series, title='noname'):
Bem, aplique-o aos dados:
Homens Crescimento
get_stats(data_male['Height'], title='Male Height') >> = MALE HEIGHT = = Mean: 175 = Std: 7 = = = = = 68% is from 168 to 183 = 95% is from 161 to 190 = 99.7% is from 154 to 197
Homens Peso
get_stats(data_male['Height'], title='Male Height') >> = MALE WEIGHT = = Mean: 85 = Std: 9 = = = = = 68% is from 76 to 94 = 95% is from 67 to 103 = 99.7% is from 58 to 112
Mulheres Crescimento
get_stats(data_male['Height'], title='Male Height') >> = FEMALE HEIGHT = = Mean: 162 = Std: 7 = = = = = 68% is from 155 to 169 = 95% is from 148 to 176 = 99.7% is from 141 to 182
Mulheres Peso
get_stats(data_male['Height'], title='Male Height') >> = FEMALE WEIGHT = = Mean: 62 = Std: 9 = = = = = 68% is from 53 to 70 = 95% is from 44 to 79 = 99.7% is from 36 to 87
Daí as conclusões:
- A maioria dos homens: 154cm - 197cm e 58kg - 112kg.
- A maioria das mulheres: 141cm - 182cm e 36kg - 87kg.
Agora, resta apenas aplicar o aprendizado de máquina a esse conjunto e tentar prever o peso por altura.
Vizinhos mais próximos
O algoritmo "Para os vizinhos mais próximos" é simples. Existe para tarefas de classificação - para distinguir um gato de um cachorro - e para tarefas de regressão - para adivinhar o peso por altura. É disso que precisamos!
Para regressão, ele usa o seguinte algoritmo:
- Lembra todos os pontos de dados
- Quando um novo ponto aparece, ele procura por K seus vizinhos mais próximos (o número K é definido pelo usuário)
- Média do resultado
- Dá uma resposta
Primeiro, você precisa dividir o conjunto de dados nas partes de treinamento e teste e testar o algoritmo
Experimentando homens
X_train, X_test, y_train, y_test = train_test_split(data_male['Height'], data_male['Weight'])
Dividido, é hora de tentar.
Não vamos longe e paramos em três vizinhos. Mas a pergunta é: esse modelo pode adivinhar meu peso?
knr3.predict([[180]])[0, 0] >> 88.67596236265881
88kg está muito perto. Neste segundo, meu peso é 89,8 kg
Gráfico de previsão para homens
O momento de construir minha parte favorita da ciência são os gráficos.
array_male = []

Modelo e gráfico de previsão para mulheres
X_train, X_test, y_train, y_test = train_test_split(data_female['Height'], data_female['Weight']) knr3 = KNeighborsRegressor(n_neighbors=3) knr3.fit(X_train.values.reshape(-1,1), y_train.values.reshape(-1,1)) knr3.score(X_train.values.reshape(-1,1), y_train.values.reshape(-1,1)) >> 0.8135681584074799
array_female = []

E é claro que é interessante a aparência desses gráficos:
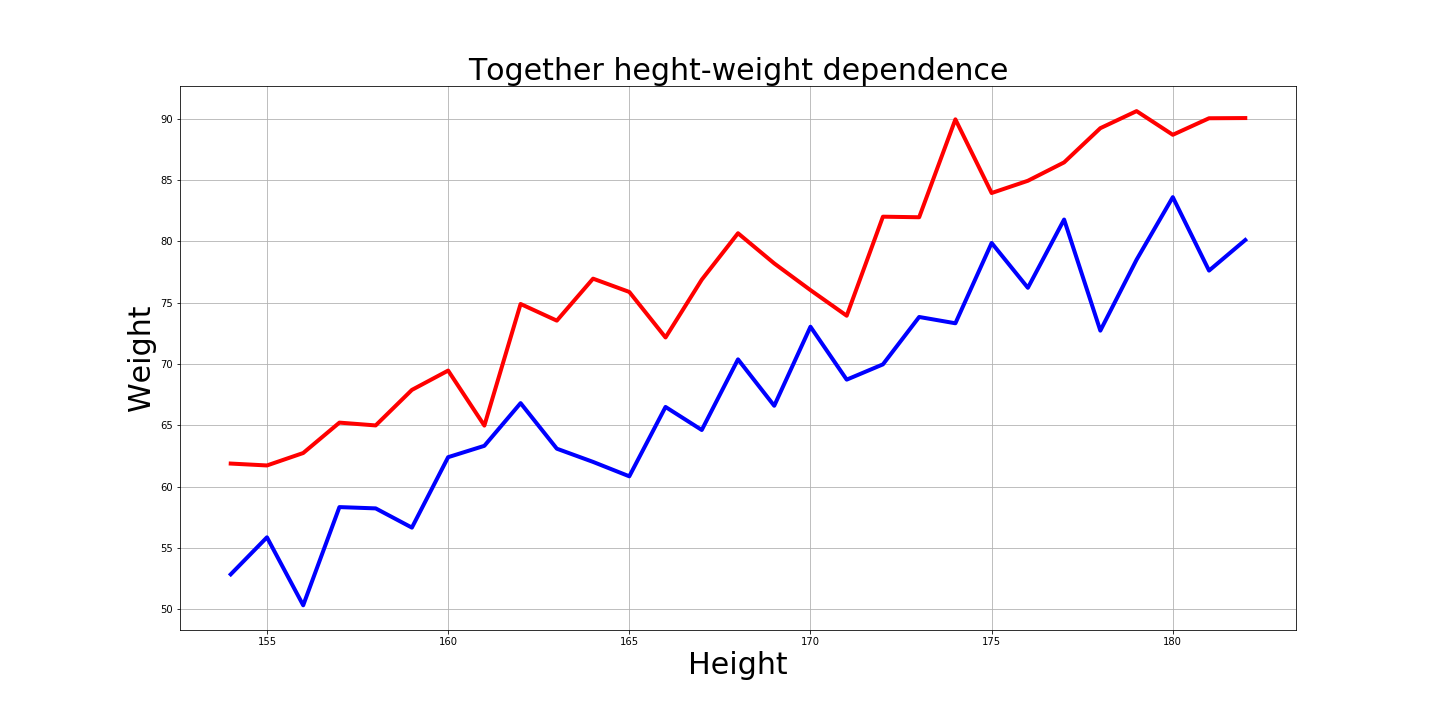
Respostas às perguntas
- Qual é a faixa de peso e altura para a maioria dos homens e mulheres?
99,7% dos homens: de 154cm a 197cm e de 58kg a 112kg.
E 99,7% das mulheres: de 141cm a 182cm e de 36kg a 87kg.
- Que tipo de homem "médio" e de mulher "média" são eles?
O homem médio mede 175 cm e 85 kg.
E a mulher média tem 162 cm e 62 kg.
- O modelo simples de aprendizado de máquina KNN desses dados prevê peso por altura?
Sim, o modelo previa 88 kg e eu tenho 89,8 kg.
Tudo o que fiz, coletei aqui
Contras do artigo
- Não há descrição do DataSet. Provavelmente, a idade e outros fatores nas pessoas eram diferentes. Portanto, não se pode aceitá-lo com fé, mas por uma questão de experimento - por favor.
- No bom sentido - foi necessário fazer um teste de normalidade da distribuição
Epílogo
Como se você atingisse o intervalo de 99,7%