
Em 2017, vencemos a competição pelo desenvolvimento do núcleo de transações dos negócios de investimento do Alfa Bank e começamos a trabalhar (no HighLoad ++ 2018
, Vladimir Drynkin, chefe do núcleo transacional dos negócios de investimentos do Alfa Bank, apresentou um relatório sobre o núcleo dos negócios de investimentos). Este sistema era para agregar dados de transação de várias fontes em vários formatos, trazer os dados para um formulário unificado, salvá-los e fornecer acesso a eles.
No processo de desenvolvimento, o sistema evoluiu e tornou-se funcional e, em algum momento, percebemos que estávamos cristalizando algo muito mais do que apenas um software aplicativo projetado para resolver uma gama estritamente definida de tarefas: obtivemos um
sistema para criar aplicativos distribuídos com armazenamento persistente . Nossa experiência formou a base de um novo produto -
Tarantool Data Grid (TDG).
Quero falar sobre a arquitetura TDG e as soluções que encontramos durante o processo de desenvolvimento, apresentar as funcionalidades básicas e mostrar como nosso produto pode se tornar a base para a construção de soluções completas.
Arquitetonicamente, dividimos o sistema em
papéis separados, sendo cada um deles responsável por resolver uma certa variedade de tarefas. Uma instância em execução de um aplicativo implementa um ou mais tipos de funções. Um cluster pode ter várias funções do mesmo tipo:
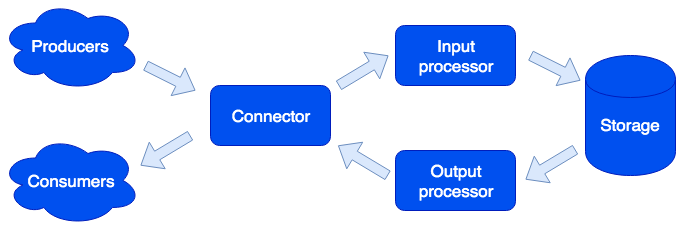
Conector
Connector é responsável pela comunicação com o mundo exterior; sua tarefa é aceitar a solicitação, analisá-la e, se for bem-sucedida, envie os dados para processamento ao processador de entrada. Apoiamos os formatos HTTP, SOAP, Kafka, FIX. A arquitetura permite que você simplesmente inclua suporte para novos formatos; o suporte do IBM MQ está disponível em breve. Se a análise da solicitação falhar, o conector retornará um erro; caso contrário, ele responderá que a solicitação foi processada com êxito, mesmo se um erro ocorreu durante o processamento adicional. Isso é feito de propósito, para trabalhar com sistemas que não sabem como repetir solicitações - ou vice-versa, fazê-lo de forma muito agressiva. Para não perder dados, a fila de reparo é usada: o objeto entra primeiro nele e somente após o processamento bem-sucedido ser excluído dele. O administrador pode receber notificações sobre os objetos restantes na fila de reparo e, após eliminar um erro de software ou falha de hardware, tente novamente.
Processador de entrada
O processador de entrada classifica os dados recebidos por característica e chama manipuladores adequados. Manipuladores são códigos Lua que são executados na sandbox, portanto, não podem afetar o funcionamento do sistema. Nesse estágio, os dados podem ser reduzidos para o formulário necessário e, se necessário, executar um número arbitrário de tarefas que podem implementar a lógica necessária. Por exemplo, no produto MDM (Master Data Management) criado no Tarantool Data Grid, ao adicionar um novo usuário, executamos uma tarefa separada para não retardar o processamento da solicitação. A sandbox suporta solicitações de leitura, alteração e adição de dados; permite executar algumas funções em todas as funções, como armazenamento e agregar o resultado (mapear / reduzir).
Os manipuladores podem ser descritos em arquivos:
sum.lua local x, y = unpack(...) return x + y
E então, declarado na configuração:
functions: sum: { __file: sum.lua }
Por que Lua? Lua é uma linguagem muito simples. Com base em nossa experiência, algumas horas depois de conhecê-lo, as pessoas começam a escrever um código que resolve seu problema. E estes não são apenas desenvolvedores profissionais, mas, por exemplo, analistas. Além disso, graças ao compilador jit, Lua é muito rápido.
Armazenamento
O armazenamento armazena dados persistentes. Antes de salvar, os dados são validados para conformidade com o esquema de dados. Para descrever o esquema, usamos o formato estendido do
Apache Avro . Um exemplo:
{ "name": "User", "type": "record", "logicalType": "Aggregate", "fields": [ { "name": "id", "type": "string"}, {"name": "first_name", "type": "string"}, {"name": "last_name", "type": "string"} ], "indexes": ["id"] }
Com base nessa descrição, o DDL (Data Definition Language) para Tarantula DBMS e o esquema
GraphQL para acesso a dados são gerados automaticamente.
A replicação de dados assíncrona é suportada (planeja adicionar síncrona).
Processador de saída
Às vezes, é necessário notificar os consumidores externos sobre a chegada de novos dados, para isso existe o papel do processador de saída. Após salvar os dados, eles podem ser transferidos para o manipulador apropriado (por exemplo, para trazê-los para o formato exigido pelo consumidor) - e depois transferidos para o conector para envio. A fila de reparo também é usada aqui: se ninguém aceitou o objeto, o administrador pode tentar novamente mais tarde.
Dimensionamento
As funções do conector, processador de entrada e processador de saída são sem estado, o que nos permite dimensionar o sistema horizontalmente, simplesmente adicionando novas instâncias do aplicativo com a função incluída do tipo desejado. Para o dimensionamento horizontal do armazenamento, é utilizada uma
abordagem para organização de cluster usando buckets virtuais. Após adicionar um novo servidor, parte do bucket de servidores antigos em segundo plano é movida para o novo servidor; isso acontece de maneira transparente com os usuários e não afeta a operação de todo o sistema.
Propriedades de dados
Os objetos podem ser muito grandes e conter outros objetos. Garantimos a atomicidade de adicionar e atualizar dados, salvando o objeto com todas as dependências em um depósito virtual. Isso elimina a "mancha" do objeto em vários servidores físicos.
O controle de versão é suportado: cada atualização do objeto cria uma nova versão, e sempre podemos fazer uma fatia do tempo e ver como o mundo estava na época. Para dados que não precisam de um longo histórico, podemos limitar o número de versões ou até armazenar apenas uma - a última - ou seja, desabilitar a versão para um determinado tipo. Você também pode limitar o histórico por tempo: por exemplo, exclua todos os objetos de um determinado tipo com mais de 1 ano. O arquivamento também é suportado: podemos descarregar objetos mais antigos que o tempo especificado, liberando espaço no cluster.
As tarefas
Das funções interessantes, vale a pena notar a capacidade de executar tarefas em um agendamento, a pedido do usuário ou programaticamente a partir da sandbox:

Aqui vemos outro papel - corredor. Essa função não possui estado e, se necessário, instâncias de aplicativos adicionais com essa função podem ser adicionadas ao cluster. A responsabilidade do corredor é concluir as tarefas. Como afirmado, a criação de novas tarefas a partir da sandbox é possível; eles são enfileirados no armazenamento e depois executados no corredor. Esse tipo de tarefa é chamado de trabalho. Também temos um tipo de tarefa chamada Tarefa - são tarefas definidas pelo usuário que estão agendadas para execução (usando a sintaxe cron) ou sob demanda. Para executar e rastrear essas tarefas, temos um conveniente gerenciador de tarefas. Para que essa funcionalidade esteja disponível, você deve habilitar a função do planejador; esse papel tem um estado; portanto, não é escalável, o que, no entanto, não é necessário; no entanto, ela, como todas as outras funções, pode ter uma réplica que começa a funcionar se o mestre se recusar repentinamente.
Logger
Outra função é chamada logger. Ele coleta logs de todos os membros do cluster e fornece uma interface para carregar e visualizá-los através de uma interface da web.
Serviços
Vale ressaltar que o sistema facilita a criação de serviços. No arquivo de configuração, você pode especificar quais solicitações devem ser enviadas ao manipulador escrito pelo usuário em execução na sandbox. Nesse manipulador, você pode, por exemplo, executar algum tipo de consulta analítica e retornar o resultado.
O serviço é descrito no arquivo de configuração:
services: sum: doc: "adds two numbers" function: sum return_type: int args: x: int y: int
A API GraphQL é gerada automaticamente e o serviço fica disponível para a chamada:
query { sum(x: 1, y: 2) }
Isso chamará o manipulador de
sum , que retornará o resultado:
3
Perfis e métricas de consulta
Para entender o sistema e a criação de perfil de consulta, implementamos o suporte ao protocolo OpenTracing. O sistema pode, sob demanda, enviar informações para ferramentas que suportam esse protocolo, por exemplo, Zipkin, o que permitirá entender como a solicitação foi executada:
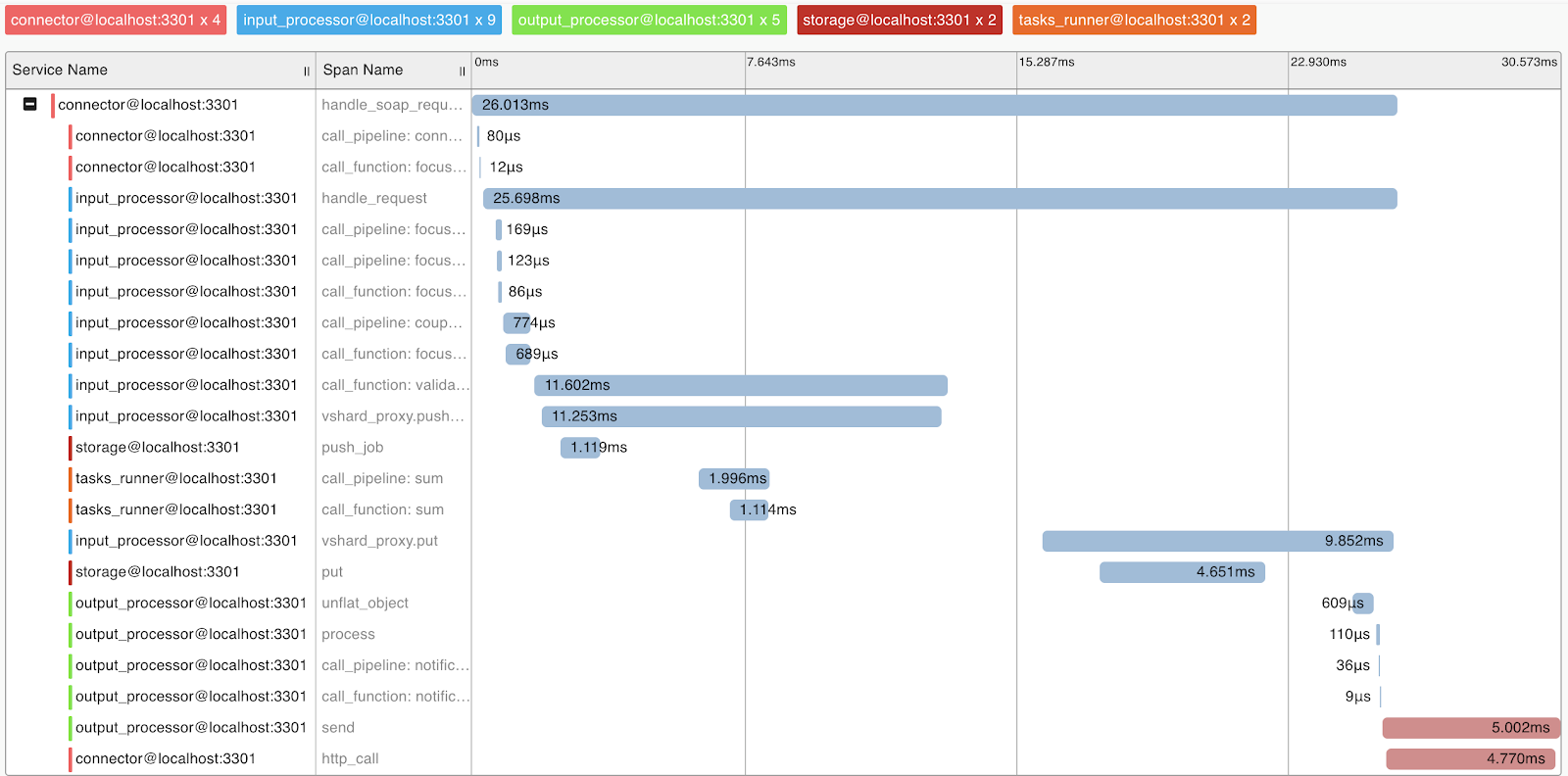
Naturalmente, o sistema fornece métricas internas que podem ser coletadas usando o Prometheus e visualizadas usando o Grafana.
Implantar
O Tarantool Data Grid pode ser implantado a partir de pacotes ou arquivo RPM, usando o utilitário da entrega ou Ansible, também há suporte para o Kubernetes (
Operador Tarantool Kubernetes ).
Um aplicativo que implementa a lógica de negócios (configuração, processadores) é carregado no cluster Tarantool Data Grid como um arquivo morto por meio da interface do usuário ou usando um script por meio da API fornecida por nós.
Exemplos de aplicação
Quais aplicativos posso criar com o Tarantool Data Grid? De fato, a maioria das tarefas de negócios está de alguma forma relacionada ao processamento do fluxo de dados, armazenamento e acesso a ele. Portanto, se você tiver grandes fluxos de dados que precisam ser armazenados com segurança e ter acesso a eles, nosso produto poderá economizar muito tempo no desenvolvimento e se concentrar na lógica de negócios.
Por exemplo, queremos coletar informações sobre o mercado imobiliário para, posteriormente, por exemplo, obter informações sobre as melhores ofertas. Nesse caso, distinguimos as seguintes tarefas:
- Robôs que coletam informações de fontes abertas - essas serão nossas fontes de dados. Você pode resolver esse problema usando soluções prontas ou escrevendo código em qualquer idioma.
- Em seguida, a Tarantool Data Grid aceitará e salvará os dados. Se o formato dos dados de diferentes fontes for diferente, você poderá escrever o código na linguagem Lua, o que levará à conversão em um único formato. No estágio de pré-processamento, você também pode, por exemplo, filtrar ofertas recorrentes ou atualizar adicionalmente informações sobre agentes que operam no mercado no banco de dados.
- Agora você já tem uma solução escalável no cluster, que pode ser preenchida com dados e fazer amostras de dados. Em seguida, você pode implementar novas funcionalidades, por exemplo, escrever um serviço que consultará os dados e emitirá a oferta mais rentável em um dia - isso exigirá algumas linhas no arquivo de configuração e um pouco de código Lua.
O que vem a seguir?
Nossa prioridade é aumentar a conveniência do desenvolvimento com o
Tarantool Data Grid . Por exemplo, este é um IDE com suporte para criação de perfil e depuração de manipuladores em área restrita.
Também prestamos muita atenção aos problemas de segurança. No momento, estamos passando pela certificação FSTEC Russia para confirmar o alto nível de segurança e atender aos requisitos de certificação de produtos de software usados em sistemas de informações de dados pessoais e sistemas de informações estaduais.