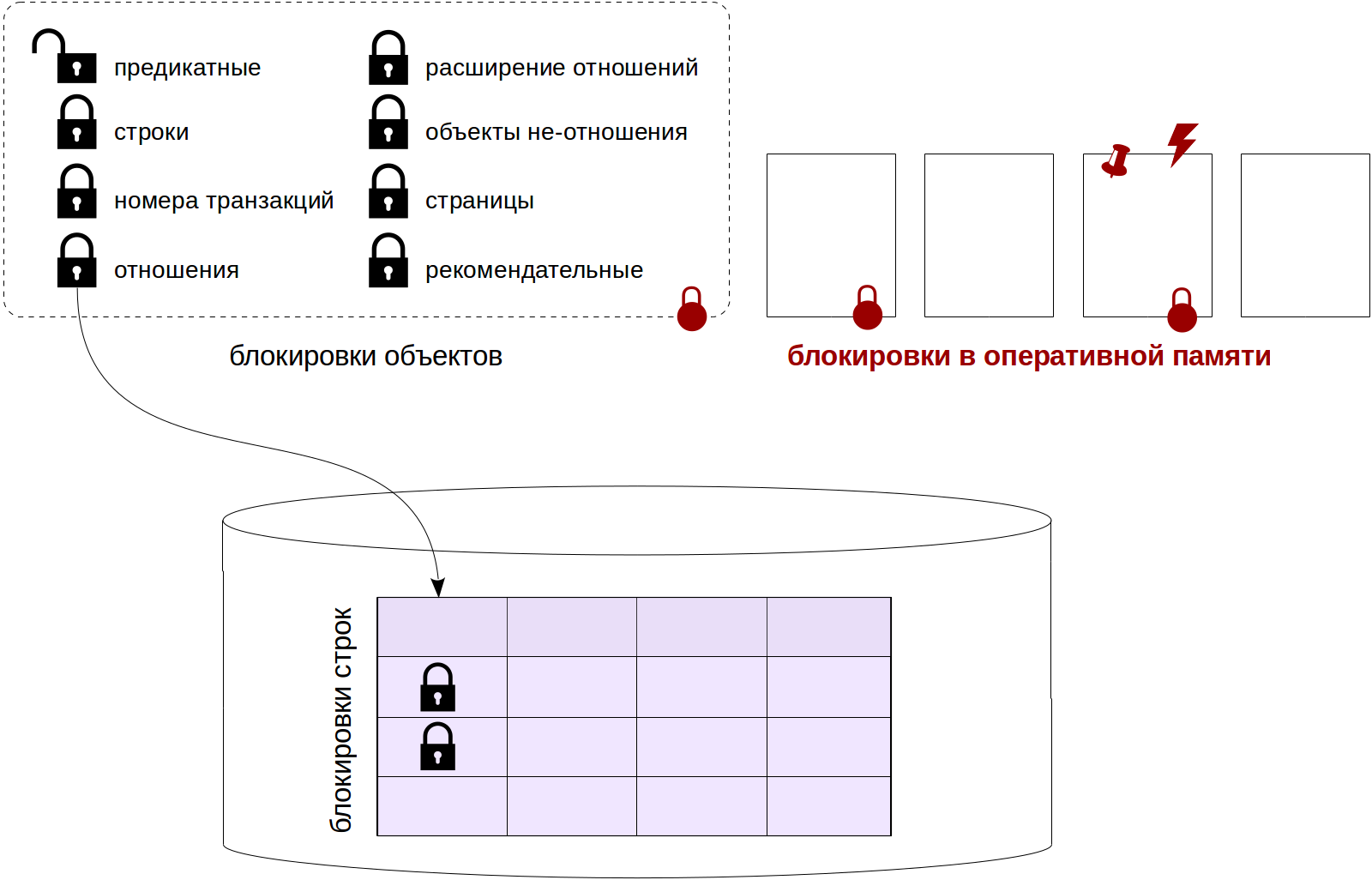
Deixe-me lembrá-lo de que já conversamos sobre
bloqueios de relacionamento , bloqueios em nível de linha ,
bloqueios de outros objetos (incluindo predicados) e sobre o relacionamento entre diferentes tipos de bloqueios.
Hoje encerro esta série com um artigo sobre
bloqueios de memória . Falaremos sobre spinlocks, bloqueios leves e bloqueio de buffer, bem como ferramentas de monitoramento e amostragem de expectativas.
Bloqueio de rotação
Diferentemente dos bloqueios comuns, “pesados”, os bloqueios mais leves e mais baratos (em termos de sobrecarga) são usados para proteger estruturas na RAM compartilhada.
Os mais simples deles são
bloqueios de rotação ou
spinlocks . Eles foram projetados para capturar por um período muito curto (várias instruções do processador) e proteger seções individuais da memória contra alterações simultâneas.
Os bloqueios de rotação são implementados com base em instruções atômicas do processador, como comparar e trocar. Eles suportam um único modo exclusivo. Se o bloqueio estiver ocupado, o processo de espera executará uma espera ativa - o comando se repete ("gira" no loop, daí o nome) até que seja executado com êxito. Isso faz sentido, pois os bloqueios de rotação são usados quando a probabilidade de conflito é estimada como muito baixa.
Os bloqueios de rotação não fornecem detecção de conflitos (os desenvolvedores do PostgreSQL estão monitorando isso) e não fornecem nenhuma ferramenta de monitoramento. Em geral, a única coisa que podemos fazer com os bloqueios de rotação é saber sobre sua existência.
Fechaduras leves
Em seguida, vêm as chamadas
fechaduras de luz (fechaduras leves, fechaduras).
Eles são capturados pelo curto período de tempo necessário para trabalhar com a estrutura de dados (por exemplo, uma tabela de hash ou uma lista de ponteiros). Como regra, uma trava leve não é mantida por muito tempo, mas, em alguns casos, uma trava leve protege as operações de E / S; portanto, em princípio, o tempo pode se tornar significativo.
Dois modos são suportados: exclusivo (para alteração de dados) e compartilhado (somente leitura). Como tal, não há fila de espera: se vários processos estiverem aguardando a liberação do bloqueio, um deles obterá acesso mais ou menos aleatoriamente. Em sistemas com um alto grau de paralelismo e carga pesada, isso pode levar a efeitos desagradáveis (ver, por exemplo,
discussão ).
Um mecanismo para verificar conflitos não é fornecido, isso permanece na consciência dos desenvolvedores do kernel. No entanto, os bloqueios de luz têm ferramentas de monitoramento; portanto, diferentemente dos bloqueios de rotação, eles podem ser "vistos" (um pouco mais tarde mostrarei como).
Buffer de clipe
Outro tipo de bloqueio que já discutimos no artigo sobre o
cache do
buffer é a
fixação do buffer .
Com um buffer fixo, você pode executar várias ações, incluindo alteração de dados, mas com a condição de que essas alterações não sejam visíveis para outros processos devido ao multi-versioning. Ou seja, por exemplo, você pode adicionar uma nova linha à página, mas não pode substituir a página no buffer por outra.
Se o processo é dificultado pela ligação, geralmente apenas ignora esse buffer e seleciona outro. Mas, em alguns casos, quando esse buffer específico é necessário, o processo fica em fila e adormece - o sistema o ativa quando a fixação é removida.
As expectativas de consolidação estão disponíveis para monitoramento.
Exemplo: cache de buffer
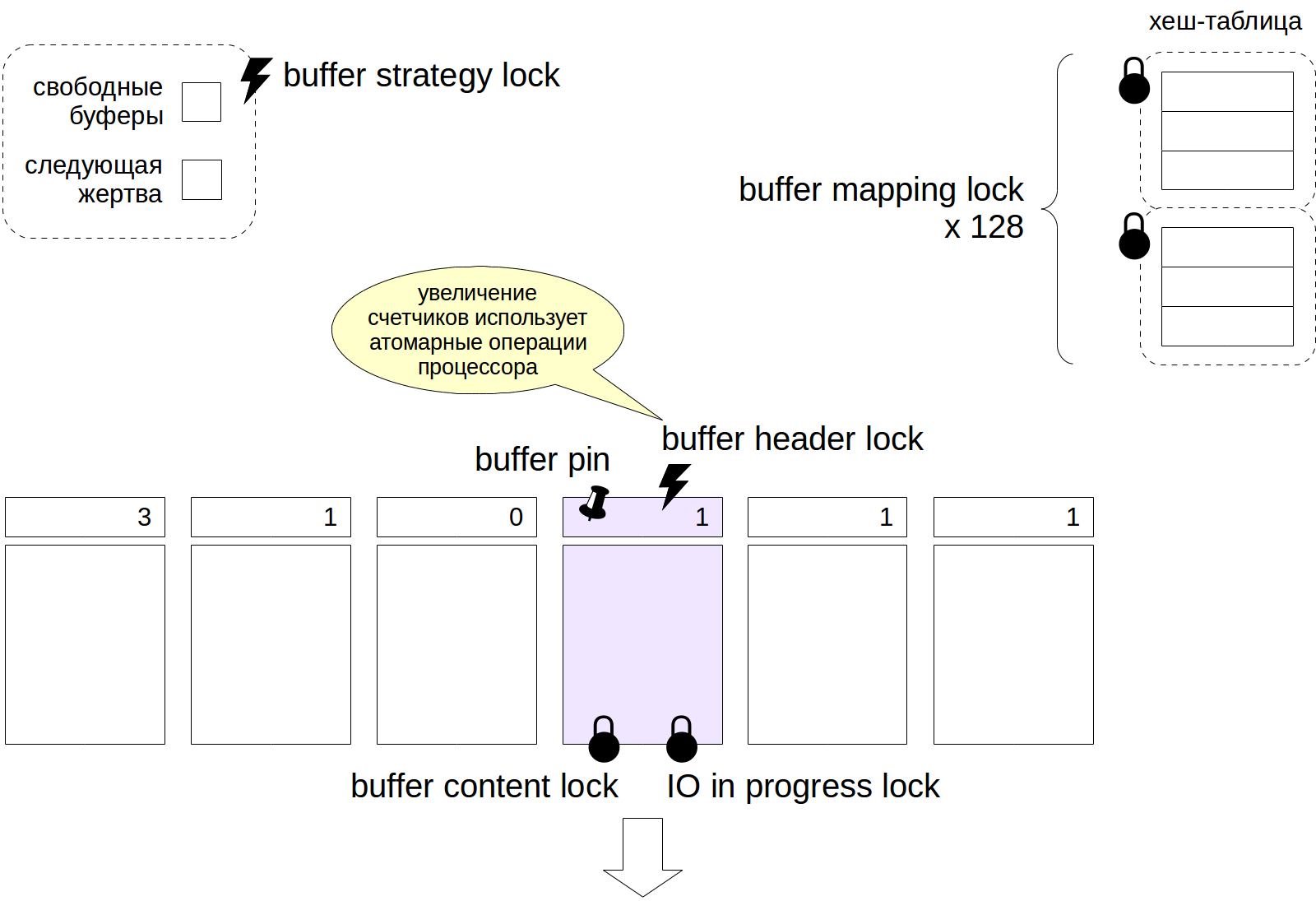
Agora, para obter algumas informações (incompletas!) Sobre como e onde os bloqueios são usados, considere um exemplo de cache de buffer.
Para acessar uma tabela de hash contendo referências a buffers, o processo deve capturar um bloqueio de mapeamento de buffer de luz no modo compartilhado e, se a tabela precisar ser alterada, então no modo excepcional. Para reduzir a granularidade, esse bloqueio é organizado como uma
parcela , consistindo em 128 bloqueios separados, cada um dos quais protege sua própria parte da tabela de hash.
O processo obtém acesso ao cabeçalho do buffer usando o bloqueio de rotação. Operações individuais (como incrementar o contador) também podem ser executadas sem bloqueios explícitos usando instruções atômicas do processador.
Para ler o conteúdo de um buffer, é necessário um bloqueio de conteúdo do buffer. Normalmente, ele é capturado apenas pelo tempo necessário para ler os ponteiros para a versão das linhas e, em seguida, a proteção fornecida pelo clipe de buffer é suficiente. Para modificar o conteúdo do buffer, esse bloqueio deve ser capturado no modo excepcional.
Ao ler um buffer do disco (ou gravar no disco), o bloqueio de E / S em andamento também é capturado, o que sinaliza outros processos que a página está lendo (ou gravando) - eles podem enfileirar-se se também precisarem fazer algo com esta página.
Os ponteiros para liberar buffers e para a próxima vítima são protegidos por um único bloqueio de rotação de estratégia de buffer.
Exemplo: Buffers de Log
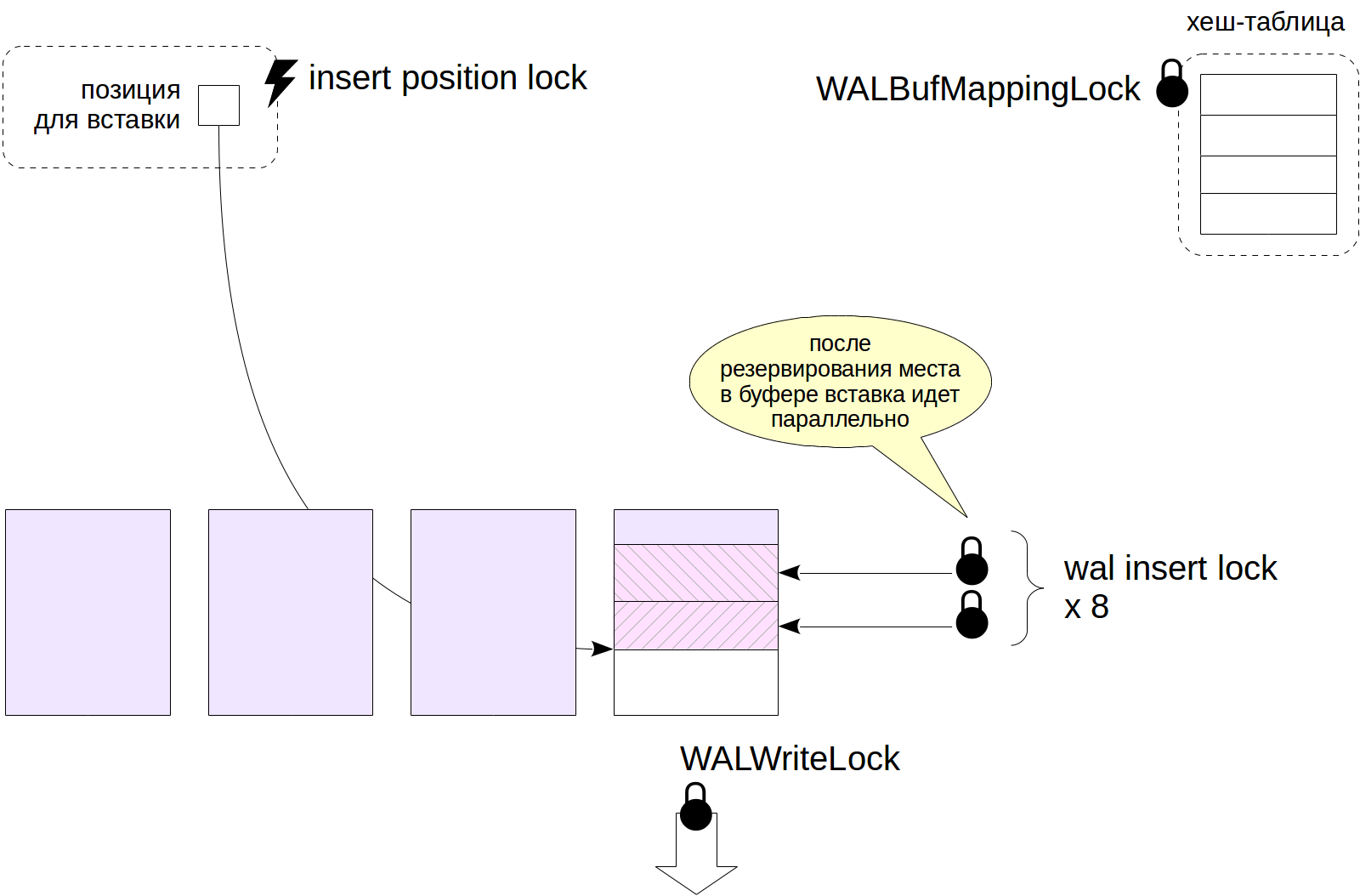
Outro exemplo: buffers de log.
Para o cache do diário, também é usada uma tabela de hash que contém o mapeamento de páginas para buffers. Diferentemente do cache do buffer, essa tabela de hash é protegida pelo único bloqueio leve do WALBufMappingLock, já que o tamanho do cache do diário é menor (geralmente 1/32 do cache do buffer) e o acesso aos buffers é mais simplificado.
A gravação de páginas no disco é protegida por um leve bloqueio WALWriteLock, para que apenas um processo possa executar esta operação por vez.
Para criar uma entrada no diário, o processo deve primeiro reservar um espaço na página WAL. Para fazer isso, ele captura a trava de posição da inserção da trava giratória. Depois que um local é reservado, o processo copia o conteúdo de seu registro para o local designado. A cópia pode ser executada por vários processos ao mesmo tempo, para os quais o registro é protegido por uma tranche de 8 bloqueios fáceis de inserção de bloqueio (o processo deve capturar
qualquer um deles).
A figura não mostra todos os bloqueios relacionados ao log de pré-registro, mas este e o exemplo anterior devem dar uma idéia sobre o uso de bloqueios na RAM.
Monitoramento de expectativas
A partir do PostgreSQL 9.6, as ferramentas de monitoramento de espera são incorporadas à exibição pg_stat_activity. Quando um processo (sistema ou serviço) não pode fazer seu trabalho e está esperando por algo, essa expectativa pode ser vista na exibição: a coluna wait_event_type indica o tipo de expectativa e a coluna wait_event indica o nome de uma expectativa específica.
Lembre-se de que uma exibição mostra apenas as expectativas que são tratadas adequadamente no código-fonte. Se a visão não mostra a expectativa, isso geralmente não significa com uma probabilidade de 100% que o processo realmente não espere nada.
Infelizmente, a única informação disponível sobre as expectativas é
a informação
atual . Nenhuma estatística é mantida. A única maneira de obter uma imagem das expectativas ao longo do tempo é
amostrando o estado da vista em um intervalo específico. Não há meios
internos para isso, mas você pode usar extensões, por exemplo,
pg_wait_sampling .
É necessário levar em consideração a natureza probabilística da amostragem. Para obter uma imagem mais ou menos confiável, o número de medições deve ser grande o suficiente. A amostragem em baixa frequência pode não fornecer uma imagem confiável e aumentar a frequência levará a um aumento na sobrecarga. Pelo mesmo motivo, a amostragem é inútil para analisar sessões de curta duração.
Todas as expectativas podem ser divididas em vários tipos.
As expectativas dos bloqueios considerados compõem uma grande categoria:
- aguardando bloqueios de objetos (valor de bloqueio na coluna wait_event_type);
- aguardando bloqueios de luz (LWLock);
- aguardando um buffer fixado (BufferPin).
Mas os processos podem esperar outros eventos:
- As expectativas de E / S (E / S) ocorrem quando um processo precisa gravar ou ler dados;
- o processo pode aguardar os dados necessários para o trabalho do cliente (cliente) ou de outro processo (IPC);
- extensões podem registrar suas expectativas específicas (extensão).
Há situações em que um processo simplesmente não faz um trabalho útil. Esta categoria inclui:
- aguardando processos em segundo plano em seu loop principal (Activity);
- aguardando um temporizador (Timeout).
Como regra, essas expectativas são "normais" e não falam de nenhum problema.
O tipo de expectativa é seguido pelo nome da expectativa específica. A tabela completa pode ser encontrada
na documentação .
Se nenhum nome de espera for especificado, o processo não estará no estado de espera. Esse tempo deve ser considerado
inexplicável , uma vez que, na verdade, não se sabe exatamente o que está acontecendo neste momento.
No entanto, é hora de olhar.
=> SELECT pid, backend_type, wait_event_type, wait_event FROM pg_stat_activity;
pid | backend_type | wait_event_type | wait_event -------+------------------------------+-----------------+--------------------- 28739 | logical replication launcher | Activity | LogicalLauncherMain 28736 | autovacuum launcher | Activity | AutoVacuumMain 28963 | client backend | | 28734 | background writer | Activity | BgWriterMain 28733 | checkpointer | Activity | CheckpointerMain 28735 | walwriter | Activity | WalWriterMain (6 rows)
Pode-se observar que todos os processos do serviço em segundo plano estão "brincando". Os valores vazios em wait_event_type e wait_event indicam que o processo não está esperando nada - no nosso caso, o processo de veiculação está ocupado executando a solicitação.
Amostragem
Para obter uma imagem mais ou menos completa das expectativas usando a amostragem, usamos a extensão
pg_wait_sampling . Ele deve ser compilado a partir do código fonte; Eu vou omitir esta parte. Em seguida, registramos a biblioteca no parâmetro
shared_preload_libraries e reiniciamos o servidor.
=> ALTER SYSTEM SET shared_preload_libraries = 'pg_wait_sampling';
student$ sudo pg_ctlcluster 11 main restart
Agora instale a extensão no banco de dados.
=> CREATE EXTENSION pg_wait_sampling;
A extensão permite visualizar o histórico de expectativas, armazenado em um buffer circular. Mas o mais interessante é ver o perfil das expectativas - as estatísticas acumuladas para todo o tempo de trabalho.
Aqui está o que veremos em alguns segundos:
=> SELECT * FROM pg_wait_sampling_profile;
pid | event_type | event | queryid | count -------+------------+---------------------+---------+------- 29074 | Activity | LogicalLauncherMain | 0 | 220 29070 | Activity | WalWriterMain | 0 | 220 29071 | Activity | AutoVacuumMain | 0 | 219 29069 | Activity | BgWriterMain | 0 | 220 29111 | Client | ClientRead | 0 | 3 29068 | Activity | CheckpointerMain | 0 | 220 (6 rows)
Como nada aconteceu desde o início do servidor, as principais expectativas são do tipo Atividade (processos de serviço aguardam até que o trabalho apareça) e Cliente (psql aguarda o usuário enviar uma solicitação).
Com as configurações padrão (parâmetro
pg_wait_sampling.profile_period ), o período de amostragem é de 10 milissegundos, ou seja, os valores são salvos 100 vezes por segundo. Portanto, para estimar a duração da espera em segundos, o valor da contagem deve ser dividido por 100.
Para entender a que pertencem as expectativas do processo, adicionamos a visualização pg_stat_activity à solicitação:
=> SELECT p.pid, a.backend_type, a.application_name AS app, p.event_type, p.event, p.count FROM pg_wait_sampling_profile p LEFT JOIN pg_stat_activity a ON p.pid = a.pid ORDER BY p.pid, p.count DESC;
pid | backend_type | app | event_type | event | count -------+------------------------------+------+------------+----------------------+------- 29068 | checkpointer | | Activity | CheckpointerMain | 222 29069 | background writer | | Activity | BgWriterMain | 222 29070 | walwriter | | Activity | WalWriterMain | 222 29071 | autovacuum launcher | | Activity | AutoVacuumMain | 221 29074 | logical replication launcher | | Activity | LogicalLauncherMain | 222 29111 | client backend | psql | Client | ClientRead | 4 29111 | client backend | psql | IPC | MessageQueueInternal | 1 (7 rows)
Vamos carregar com o pgbench e ver como a imagem muda.
student$ pgbench -i test
Redefinimos o perfil coletado para zero e executamos o teste por 30 segundos em um processo separado.
=> SELECT pg_wait_sampling_reset_profile();
student$ pgbench -T 30 test
A solicitação deve ser concluída antes que o processo pgbench seja concluído:
=> SELECT p.pid, a.backend_type, a.application_name AS app, p.event_type, p.event, p.count FROM pg_wait_sampling_profile p LEFT JOIN pg_stat_activity a ON p.pid = a.pid WHERE a.application_name = 'pgbench' ORDER BY p.pid, p.count DESC;
pid | backend_type | app | event_type | event | count -------+----------------+---------+------------+------------+------- 29148 | client backend | pgbench | IO | WALWrite | 8 29148 | client backend | pgbench | Client | ClientRead | 1 (2 rows)
Obviamente, as expectativas do processo pgbench serão ligeiramente diferentes, dependendo do sistema específico. No nosso caso, é muito provável que a espera de uma entrada de log (IO / WALWrite) seja apresentada, mas na maioria das vezes o processo não parou, mas fez algo presumivelmente útil.
Fechaduras leves
Você deve sempre lembrar que a ausência de qualquer expectativa na amostragem não significa que não havia expectativa. Se fosse mais curto que o período de amostragem (o centésimo de segundo em nosso exemplo), simplesmente não poderia cair na amostra.
Portanto, os bloqueios de luz não apareceram no perfil - mas aparecerão se você coletar dados por um longo tempo. Para garantir uma olhada nelas, você pode desacelerar artificialmente o sistema de arquivos, por exemplo, usar o projeto
slowfs criado no sistema de arquivos
FUSE .
É o que podemos ver no mesmo teste se qualquer operação de E / S demorar 1/10 de segundo.
=> SELECT pg_wait_sampling_reset_profile();
student$ pgbench -T 30 test
=> SELECT p.pid, a.backend_type, a.application_name AS app, p.event_type, p.event, p.count FROM pg_wait_sampling_profile p LEFT JOIN pg_stat_activity a ON p.pid = a.pid WHERE a.application_name = 'pgbench' ORDER BY p.pid, p.count DESC;
pid | backend_type | app | event_type | event | count -------+----------------+---------+------------+----------------+------- 29240 | client backend | pgbench | IO | WALWrite | 1445 29240 | client backend | pgbench | LWLock | WALWriteLock | 803 29240 | client backend | pgbench | IO | DataFileExtend | 20 (3 rows)
Agora, a principal expectativa do processo pgbench está relacionada à E / S, ou melhor, a uma entrada de log executada no modo síncrono com cada confirmação. Como (como mostrado no exemplo acima), a gravação de um log no disco é protegida pelo bloqueio de luz WALWriteLock, esse bloqueio também está presente no perfil - queríamos ver isso.
Buffer de clipe
Para ver a fixação do buffer, aproveitamos o fato de os cursores abertos prenderem o pino, para que a leitura da próxima linha seja mais rápida.
Iniciamos a transação, abrimos o cursor e selecionamos uma linha.
=> BEGIN; => DECLARE c CURSOR FOR SELECT * FROM pgbench_history; => FETCH c;
tid | bid | aid | delta | mtime | filler -----+-----+-------+-------+----------------------------+-------- 9 | 1 | 35092 | 477 | 2019-09-04 16:16:18.596564 | (1 row)
Verifique se o buffer está fixado (pinning_backends):
=> SELECT * FROM pg_buffercache WHERE relfilenode = pg_relation_filenode('pgbench_history') AND relforknumber = 0 \gx
-[ RECORD 1 ]----+------ bufferid | 190 relfilenode | 47050 reltablespace | 1663 reldatabase | 16386 relforknumber | 0 relblocknumber | 0 isdirty | t usagecount | 1 pinning_backends | 1 <-- 1
Agora vamos
limpar a mesa:
| => SELECT pg_backend_pid();
| pg_backend_pid | ---------------- | 29367 | (1 row)
| => VACUUM VERBOSE pgbench_history;
| INFO: vacuuming "public.pgbench_history" | INFO: "pgbench_history": found 0 removable, 0 nonremovable row versions in 1 out of 1 pages | DETAIL: 0 dead row versions cannot be removed yet, oldest xmin: 732651 | There were 0 unused item pointers.
| Skipped 1 page due to buffer pins, 0 frozen pages.
| 0 pages are entirely empty. | CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s. | VACUUM
Como podemos ver, a página foi pulada (1 página pulada devido aos pinos do buffer). De fato, a limpeza não pode lidar com isso, porque é proibido excluir fisicamente versões de linha de uma página em um buffer fixado. Mas a limpeza não irá esperar - a página será processada na próxima vez.
E agora faremos a
limpeza com congelamento :
| => VACUUM FREEZE VERBOSE pgbench_history;
Com um congelamento claramente solicitado, você não pode pular uma única página que não esteja marcada no mapa de congelamento - caso contrário, é impossível reduzir a idade máxima das transações descongeladas em pg_class.relfrozenxid. Portanto, a limpeza trava até o cursor fechar.
=> SELECT age(relfrozenxid) FROM pg_class WHERE oid = 'pgbench_history'::regclass;
age ----- 27 (1 row)
=> COMMIT;
| INFO: aggressively vacuuming "public.pgbench_history" | INFO: "pgbench_history": found 0 removable, 26 nonremovable row versions in 1 out of 1 pages | DETAIL: 0 dead row versions cannot be removed yet, oldest xmin: 732651 | There were 0 unused item pointers.
| Skipped 0 pages due to buffer pins, 0 frozen pages.
| 0 pages are entirely empty. | CPU: user: 0.00 s, system: 0.00 s, elapsed: 3.01 s. | VACUUM
=> SELECT age(relfrozenxid) FROM pg_class WHERE oid = 'pgbench_history'::regclass;
age ----- 0 (1 row)
Bem, vejamos o perfil de expectativas da segunda sessão psql na qual os comandos VACUUM foram executados:
=> SELECT p.pid, a.backend_type, a.application_name AS app, p.event_type, p.event, p.count FROM pg_wait_sampling_profile p LEFT JOIN pg_stat_activity a ON p.pid = a.pid WHERE p.pid = 29367 ORDER BY p.pid, p.count DESC;
pid | backend_type | app | event_type | event | count -------+----------------+------+------------+------------+------- 29367 | client backend | psql | BufferPin | BufferPin | 294 29367 | client backend | psql | Client | ClientRead | 10 (2 rows)
O tipo de espera BufferPin indica que a liberação estava aguardando a liberação do buffer.
Sobre isso, assumiremos que concluímos os bloqueios. Obrigado a todos por sua atenção e comentários!