Em arquiteturas grandes ou de microsserviços, o serviço mais importante nem sempre é o mais produtivo e, às vezes, não se destina a carga alta. Estamos falando sobre o back-end. Funciona devagar - perde tempo no processamento de dados e aguarda uma resposta entre ele e o DBMS e não é escalável. Mesmo que o próprio aplicativo seja dimensionado com facilidade, esse gargalo não será dimensionado. Como resolver esse problema e garantir alto desempenho? Como fornecer uma resposta do sistema quando fontes importantes de informação estão silenciosas?

Se sua arquitetura estiver em total conformidade com o manifesto Reativo, os componentes do aplicativo serão escalados indefinidamente com o aumento da carga independentemente um do outro e suportarão a queda de qualquer nó - você sabe a resposta. Mas, se não,
Oleg Nizhnikov (
Odomontois ) dirá como o problema de escalabilidade foi resolvido em Tinkoff, criando seu indolor Fallback Cache no Scala sem reescrever o aplicativo.
Nota O artigo terá um mínimo de código Scala e um máximo de princípios e idéias gerais.Back-end instável ou lento
Ao interagir com o back-end, o aplicativo médio é rápido. Mas o back-end faz a maior parte do trabalho e mói a maioria dos dados internamente - leva mais tempo. Perde-se tempo extra aguardando uma resposta de back-end e DBMS. Mesmo que o próprio aplicativo seja dimensionado com facilidade, esse gargalo não será dimensionado. Como aliviar a carga no back-end e resolver o problema?
Cache incorporado
A primeira idéia é levar os dados para leitura, solicitações que recebem dados e configurar o cache no nível de cada nó da memória.
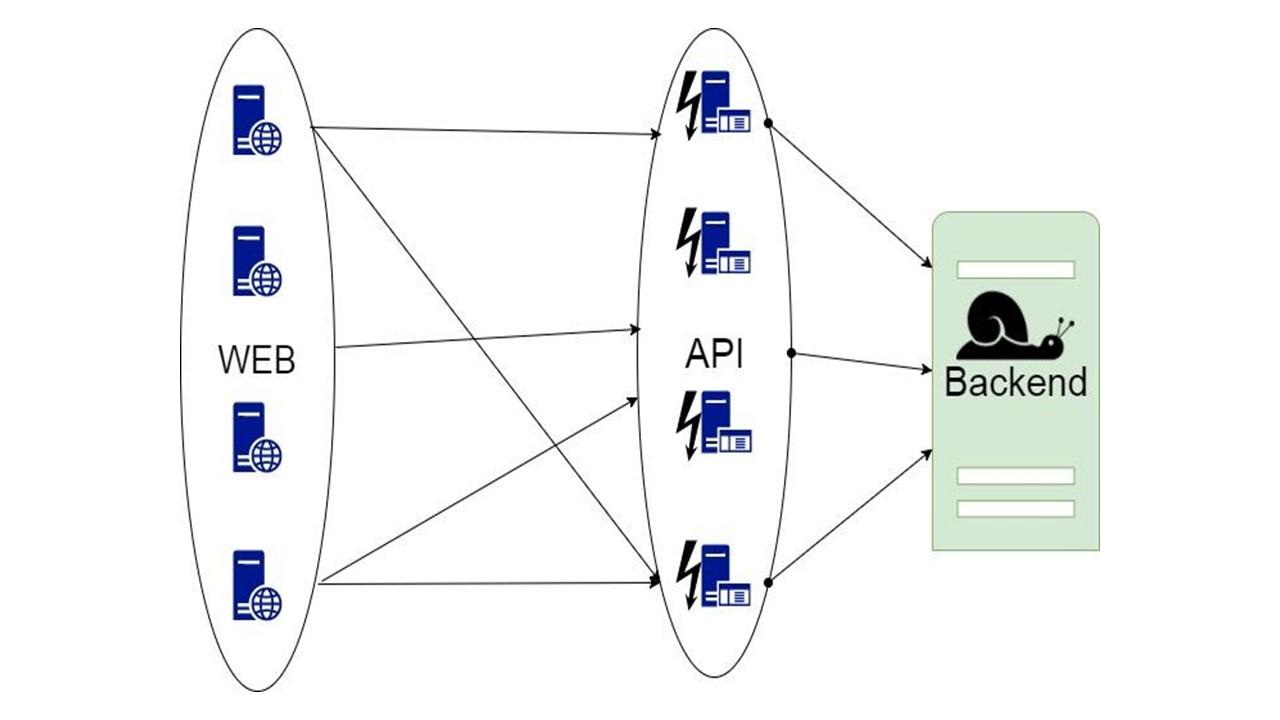
O cache permanece até que o nó reinicie e armazene apenas a última parte de dados. Se o aplicativo travar e novos usuários que não estiveram na última hora, dia ou semana entrarem, o aplicativo não poderá fazer nada a respeito.
Proxy
A segunda opção é um proxy, que assume parte das solicitações ou modifica o aplicativo.
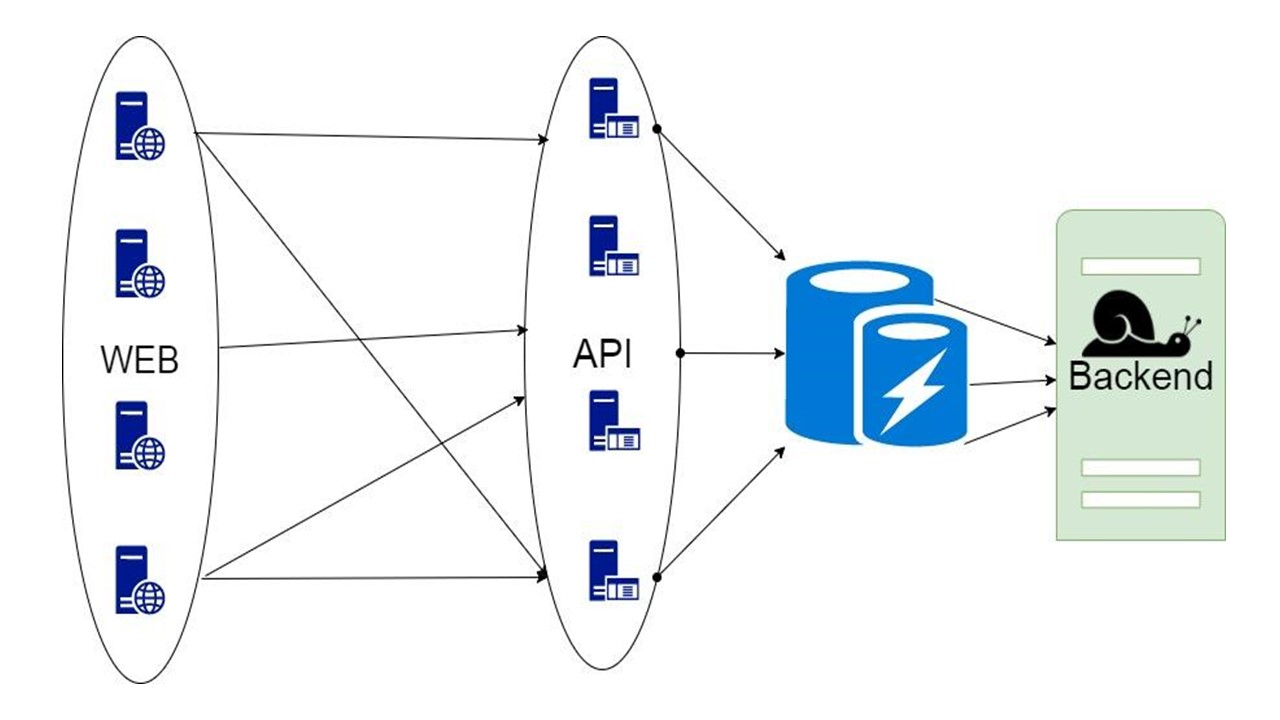
Mas no proxy, você não pode fazer todo o trabalho para o próprio aplicativo.
Banco de dados em cache
A terceira opção é complicada quando a parte dos dados retornados pelo back-end pode ser armazenada por um longo tempo. Quando eles são necessários, mostramos ao cliente, mesmo que eles não sejam mais relevantes. Isso é melhor que nada.
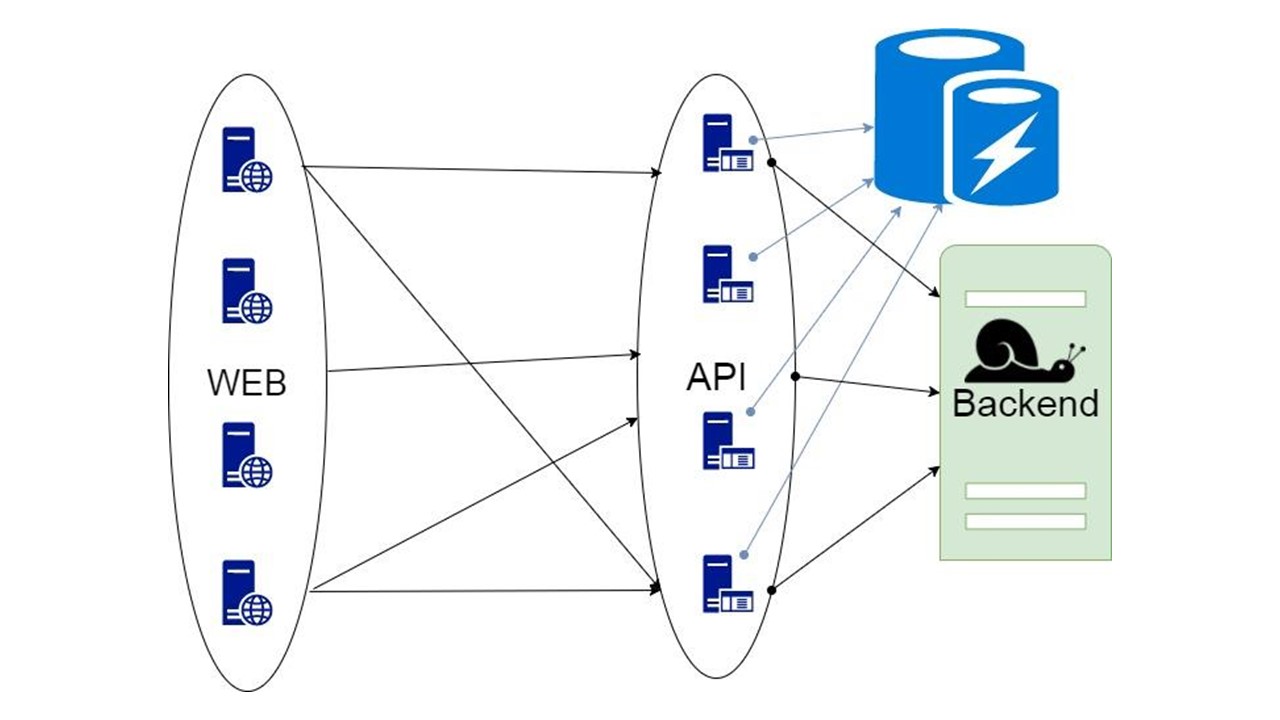
Esta decisão será discutida.
Cache de fallback
Esta é a nossa biblioteca. Ele é incorporado ao aplicativo e se comunica com o back-end. Com um refinamento mínimo, ele analisa a estrutura dos dados, gera formatos de serialização e, com a ajuda do algoritmo do disjuntor, aumenta a tolerância a falhas. A serialização eficaz pode ser implementada em qualquer idioma em que os tipos possam ser analisados com antecedência se forem definidos estritamente o suficiente.
Componentes
Nossa biblioteca se parece com isso.

A parte esquerda é dedicada à interação com este repositório, que inclui dois componentes importantes:
- o componente responsável pelo processo de inicialização - ações preliminares com o DBMS antes de usar o Cache de Fallback;
- módulo de geração de serialização automática.
O lado direito é a funcionalidade geral relacionada ao Fallback.
Como tudo isso funciona? Existem consultas no meio do aplicativo e tipos intermediários para armazenar o estado. Este formulário expressa os dados que recebemos do back-end para uma ou mais solicitações. Enviamos os parâmetros para o nosso método e obtemos os dados a partir daí. Esses dados precisam ser serializados de alguma forma para serem armazenados, portanto, agrupamos-os no código. Um módulo separado é responsável por isso. Utilizamos o padrão do disjuntor.
Requisitos de armazenamento
Vida útil longa - 30-500 dias . Algumas ações podem levar muito tempo e todo esse tempo é necessário para armazenar dados. Portanto, queremos um armazenamento que possa armazenar dados por um longo tempo. A memória não é adequada para isso.
Grande volume de dados - 100 GB-20 TB . Queremos armazenar dezenas de terabytes de dados no cache e ainda mais devido ao crescimento. Manter tudo isso na memória é ineficiente - a maioria dos dados não é solicitada constantemente. Eles ficam muito tempo esperando o usuário, que entra e pergunta. A memória não se enquadra nesses requisitos.
Alta disponibilidade de dados . Tudo pode acontecer com o serviço, mas queremos que o DBMS permaneça disponível o tempo todo.
Baixos custos de armazenamento . Enviamos dados adicionais para o cache. Como resultado, ocorre sobrecarga. Ao implementar nossa solução, queremos minimizá-la.
Suporte para consultas em intervalos . Nosso banco de dados deveria ter sido capaz de extrair um dado não apenas em sua totalidade, mas a intervalos: uma lista de ações, o histórico de um usuário por um determinado período. Portanto, um valor de chave puro não é adequado.
Pressupostos
Os requisitos restringem a lista de candidatos. Assumimos que implementamos o restante e fazemos as seguintes suposições, sabendo por que exatamente precisamos do Cache de Fallback.
A integridade dos dados entre duas solicitações GET diferentes não é necessária . Portanto, se eles exibirem dois estados diferentes que não são consistentes um com o outro, vamos tolerar isso.
A relevância e a invalidação de dados não são necessárias . No momento da solicitação, presume-se que tenhamos a versão mais recente que estamos mostrando.
Enviamos e recebemos dados do back-end.
A estrutura desses dados é conhecida antecipadamente .
Seleção de armazenamento
Como alternativas, consideramos três opções principais.
O primeiro é
Cassandra . Vantagens: alta disponibilidade, fácil escalabilidade e mecanismo de serialização integrado com a coleção UDT.
UDT ou
tipos definidos pelo usuário , significa algum tipo. Eles permitem que você empilhe com eficiência tipos estruturados. Os campos de tipo são conhecidos antecipadamente. Esses campos de serialização são marcados com tags separadas, como em Buffers de protocolo. Depois de ler essa estrutura, é possível entender quais campos existem com base em tags. Metadados suficientes para descobrir seu nome e tipo.
Outra vantagem do Cassandra é que, além da chave de partição, ela possui uma
chave de cluster adicional. Essa é uma chave especial, devido à qual os dados são ordenados em um nó. Isso permite implementar uma opção, como consultas com intervalo.
O Cassandra existe há um tempo relativamente longo, existem
muitas soluções de monitoramento e
um deles é a JVM . Essa não é a opção mais produtiva para plataformas nas quais você pode gravar um DBMS. A JVM tem problemas com coleta de lixo e sobrecarga.
A segunda opção é o
CouchBase . Vantagens: acessibilidade, escalabilidade e esquemas de dados.
Com o CouchBase, você precisa pensar menos sobre serialização. Isso é positivo e negativo - não precisamos controlar o esquema de dados. Existem índices globais que permitem executar consultas de intervalo globalmente em um cluster.
O CouchBase é um híbrido no qual o
Memcache é adicionado a um DBMS comum
- cache rápido . Ele permite armazenar em cache automaticamente todos os dados no nó - o mais quente, com disponibilidade muito alta. Graças ao seu cache, o CouchBase pode ser rápido se os mesmos dados forem solicitados com muita frequência.
Schemaless e
JSON também podem ser um
sinal de menos. Os dados podem ser armazenados por tanto tempo que o aplicativo tem tempo para mudar. Nesse caso, a estrutura de dados que o CouchBase vai armazenar e ler também será alterada. A versão anterior pode não ser compatível. Você só aprenderá sobre isso ao ler, e não ao desenvolver dados, quando estiverem em algum lugar da produção. Temos que pensar na migração adequada, e é exatamente isso que não queremos fazer.
A terceira opção é
Tarantool . É famoso por sua super velocidade. Ele possui um maravilhoso mecanismo LUA que permite escrever um monte de lógica que será executada diretamente no servidor no LuaJit.
Por outro lado, esse é um valor de chave modificado. Os dados são armazenados em tuplas. Precisamos pensar por nós mesmos na serialização correta, isso nem sempre é uma tarefa óbvia. O Tarantool também possui uma abordagem específica para
escalabilidade . O que há de errado com ele, discutiremos mais adiante.
Fragmento / replicação
Talvez nosso aplicativo precise de
Sharding / Replication . Três repositórios os implementam de maneira diferente.
Cassandra sugere uma estrutura que geralmente é chamada de "anel".
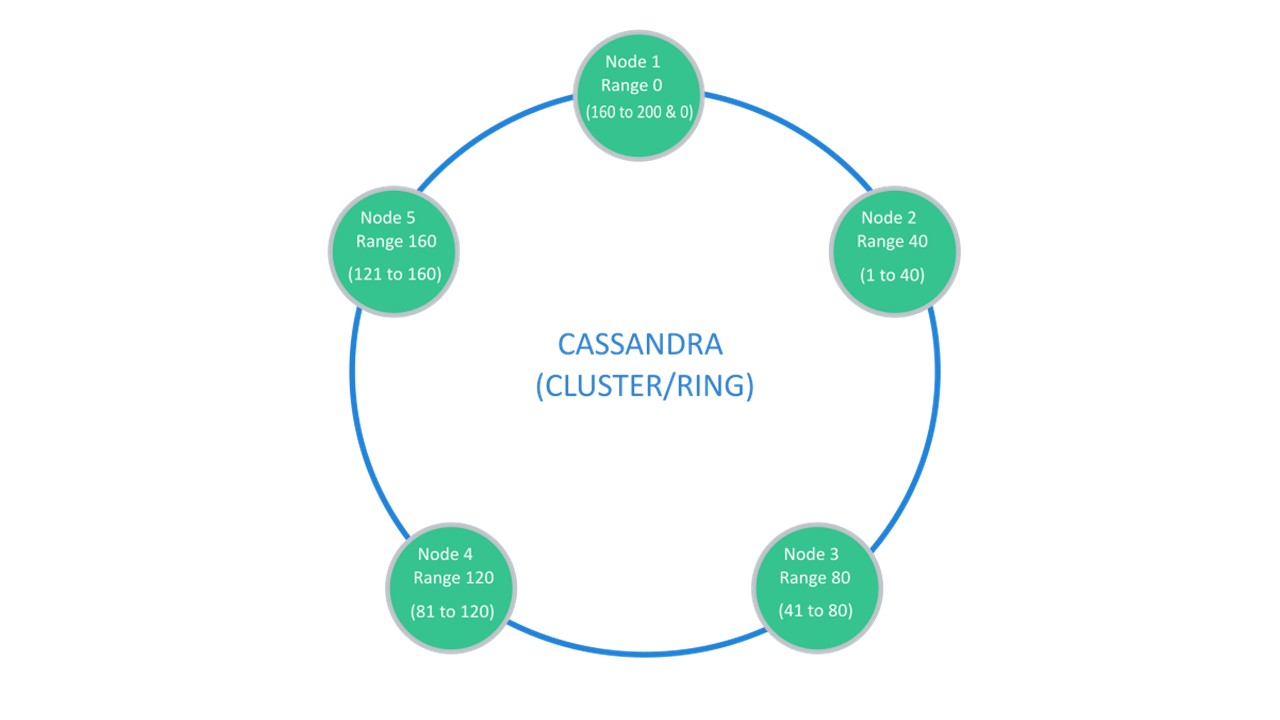
Muitos nós estão disponíveis. Cada um deles armazena seus dados e dados dos nós mais próximos como réplicas. Se um cair, os nós próximos a ele poderão servir parte de seus dados até que o dropout aumente.
Sharding \ Replication é responsável pela mesma estrutura. Para descompactar em 10 partes e no fator de replicação 3, 10 nós são suficientes. Cada um dos nós armazenará 2 réplicas dos vizinhos.
No CouchBase, a estrutura de interação entre nós é estruturada da mesma forma:
- existem dados marcados como ativos, pelos quais o próprio nó é responsável;
- Existem réplicas de nós vizinhos que o CouchBase armazena.
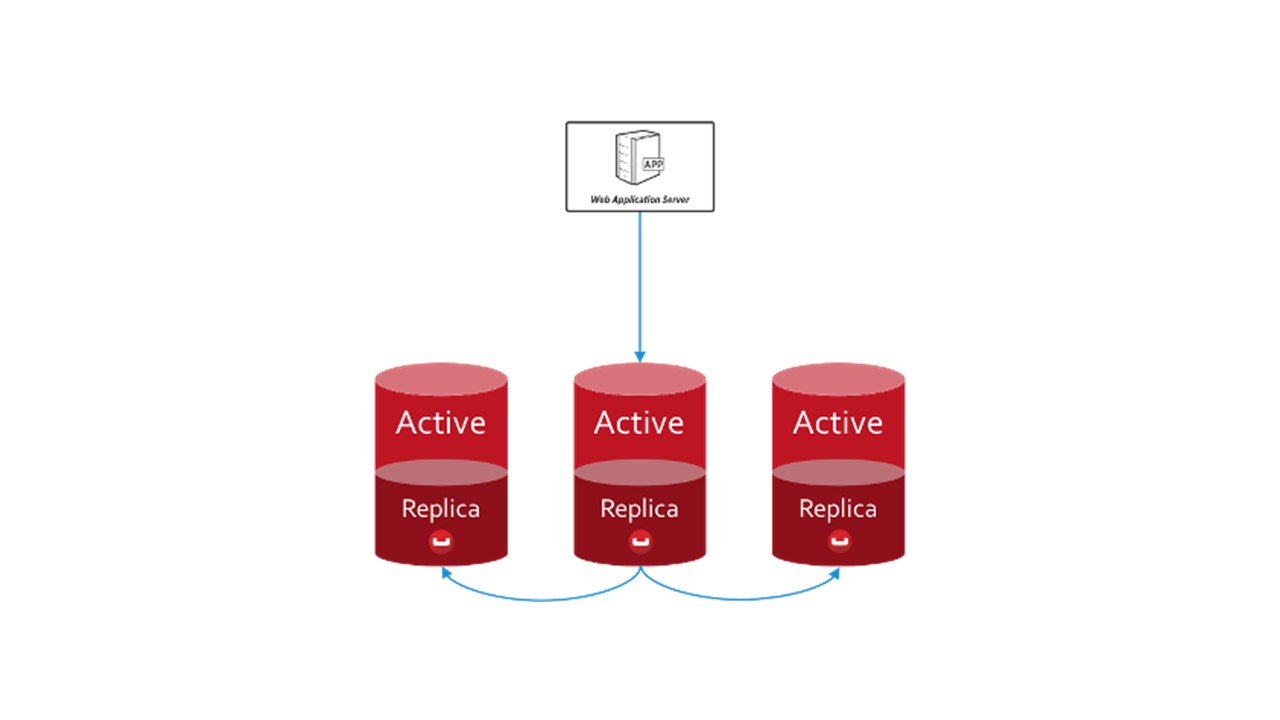
Se um nó cair, os vizinhos, compartilhados, assumirão a responsabilidade pela manutenção dessa parte das chaves.
No Tarantool, a arquitetura é semelhante ao MongoDB. Mas com uma nuance: existem grupos de sharding replicados entre si.
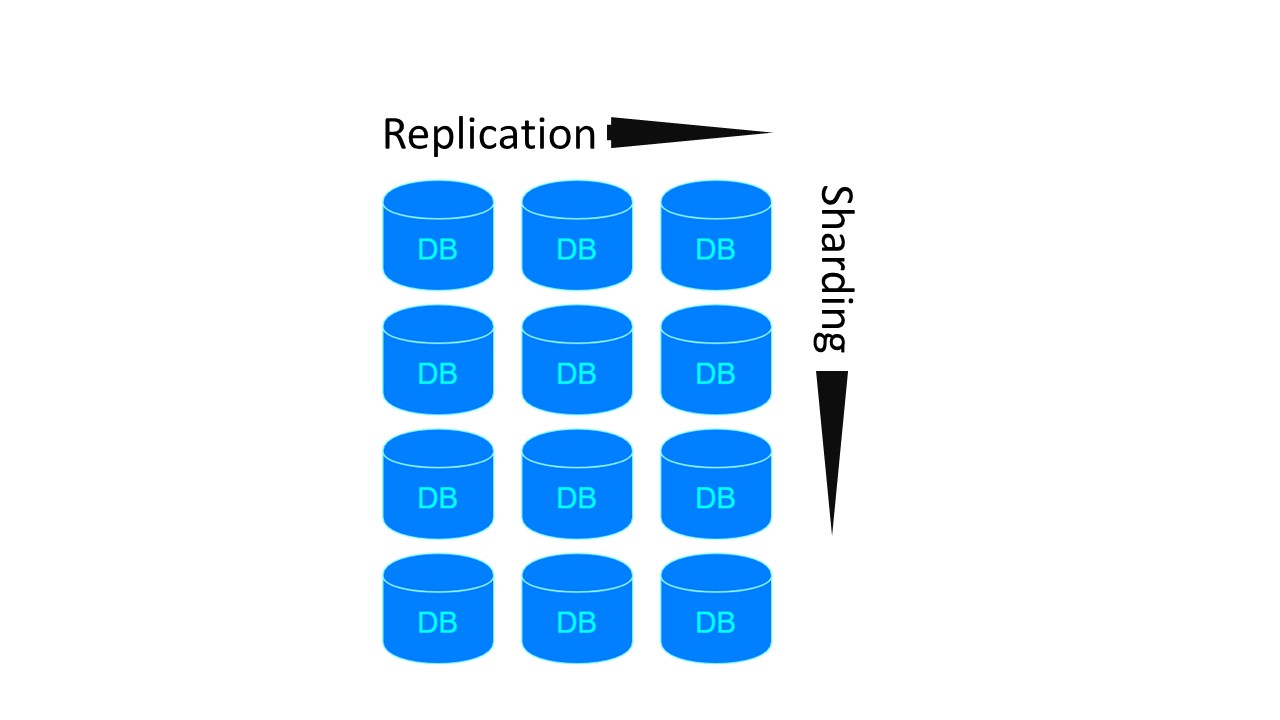
Para as duas arquiteturas anteriores, se queremos criar 4 shards e o fator de replicação 3, são necessários 4 nós. Para Tarantool - 12! Mas a desvantagem é compensada pela velocidade que o Tarantool garante.
Cassandra
Módulos opcionais para fragmentação em Tarantool apareceram apenas recentemente. Portanto, escolhemos o DBMS Cassandra como candidato principal. Lembre-se de que falamos sobre sua serialização específica.
Serialização automática
O protocolo SQL pressupõe que você seja bastante livre para definir um esquema de dados.
Você pode usar isso como uma vantagem. Por exemplo, serialize dados para que os nomes extensos de campos de nossas estruturas frondosas não sejam armazenados sempre em nossos valores. Nesse caso, teremos alguns metadados que descrevem o dispositivo de dados. As próprias UDTs também informam quais campos correspondem a rótulos e tags.
Portanto, a serialização gerada automaticamente ocorre aproximadamente da mesma maneira. Se tivermos um dos tipos básicos que podem corresponder ao tipo do banco de dados de um para um, faremos isso. Um conjunto de tipos Int, Long, String, Double também está em Cassandra.
Se um campo opcional for encontrado em alguma estrutura, não faremos nada extra. Indicamos para ele o tipo em que esse campo deve se transformar. A estrutura armazenará nulo. Se encontrarmos nulo na estrutura no nível de desserialização, assumimos que esse não é o valor.
Todos os tipos de coleção da coleção no Scala são convertidos em lista de tipos. Essas são coleções ordenadas que possuem um elemento correspondente ao índice.
Coleções de conjuntos não ordenados garantem que exista exatamente um elemento com cada valor. Cassandra também tem um tipo de conjunto especial para eles.
Provavelmente, teremos muito mapeamento (), especialmente com chaves de string. Cassandra tem um tipo de mapa especial para eles. Também é digitado e possui dois parâmetros de tipo. Para que possamos criar um tipo apropriado para qualquer chave
Existem tipos de dados que nos definimos em nosso aplicativo. Em muitos idiomas, eles são chamados de
tipos de dados algébricos . Eles são definidos pela definição de um produto nomeado de tipos, ou seja, uma estrutura. Atribuímos essa estrutura ao tipo definido pelo usuário. Cada campo da estrutura corresponderá a um campo na UDT.
O segundo tipo é a
soma algébrica de tipos . Nesse caso, o tipo corresponde a vários subtipos ou subespécies anteriormente conhecidas. Além disso, de certa maneira, atribuímos uma estrutura a ela.
Resumo Tipo de Dados traduzir para UDT
Temos uma estrutura e a exibimos um a um - para cada campo, definimos o campo na UDT criada no Cassandra:
case class Account ( id: Long, tags: List[String], user: User, finData: Option[FinData] ) create type account ( id bigint, tags: frozen<list<text>>, user frozen<user>, fin_data frozen<fin_data> )
Tipos primitivos se transformam em tipos primitivos. Um link para um tipo predefinido antes de congelar. Este é um invólucro especial no Cassandra, o que significa que você não pode ler este campo, peça por peça. O wrapper é "congelado" nesse estado. Só podemos ler ou salvar o usuário, ou a lista, como no caso de tags.
Se encontrarmos um campo opcional, descartamos essa característica. Tomamos apenas o tipo de dados correspondente ao tipo de campo que será. Se encontrarmos não aqui - a ausência de um valor -, escreveremos nulo no campo correspondente. Ao ler, também aceitaremos correspondência não nula.
Se encontrarmos um tipo que possui várias alternativas pré-conhecidas, também definiremos um novo tipo de dados no Cassandra. Para cada alternativa, um campo em nosso tipo de dados na UDT.
Como resultado, nessa estrutura, apenas um dos campos em um determinado momento não será nulo. Se você conheceu algum tipo de usuário e acabou sendo uma instância de um moderador em tempo de execução, o campo do moderador conterá algum valor, o restante será nulo. Para admin - admin, o resto - null.
Isso permite que você codifique a estrutura da seguinte forma: temos 4 campos opcionais, garantimos que apenas um será escrito a partir deles. Cassandra usa apenas uma tag para identificar a presença de um campo específico na estrutura. Graças a isso, obtemos uma estrutura de armazenamento sem sobrecarga.
De fato, para salvar o tipo de usuário, se for um moderador, será necessário o mesmo número de bytes necessários para armazenar o moderador. Mais um byte para mostrar qual alternativa específica está presente aqui.
Inicialização
A inicialização é um procedimento preliminar que deve ser concluído antes que possamos usar nosso fallback.
Como esse processo funciona?
- Em cada nó, geramos definições de tabelas, tipos e textos de consulta com base nos tipos que são apresentados.
- Leia o esquema atual do DBMS. No Cassandra, isso é fácil, basta conectar-se a ele. Quando conectado, em quase todos os drivers, o próprio objeto "sessão" bombeia os metadados do espaço principal aos quais está conectado. Então você pode ver o que eles têm.
- Analisamos os metadados, comparamos e verificamos que tudo o que queremos criar é permitido e que a migração incremental é possível.
- Se tudo estiver normal e a inicialização for possível, realizamos a migração.
- Estamos preparando pedidos.
sealed trait User case class Anonymous extends User case class Registered extends User case class Moderator extends User case class Admin extends User create type user ( anonymous frozen<anonymous>, registered frozen<registered>, moderator frozen<moderator>, admin frozen<admin> )
Isso acontece assim. Temos
tipos ,
tabelas e
consultas . Tipos dependem de outros tipos, aqueles de outros. As tabelas dependem desses tipos. As consultas já dependem das tabelas das quais eles lêem dados. A inicialização verificará todas essas dependências e criará no DBMS tudo o que ele pode criar, de acordo com certas regras.
Migração de tipo
Como determinar que um tipo pode ser migrado incrementalmente?
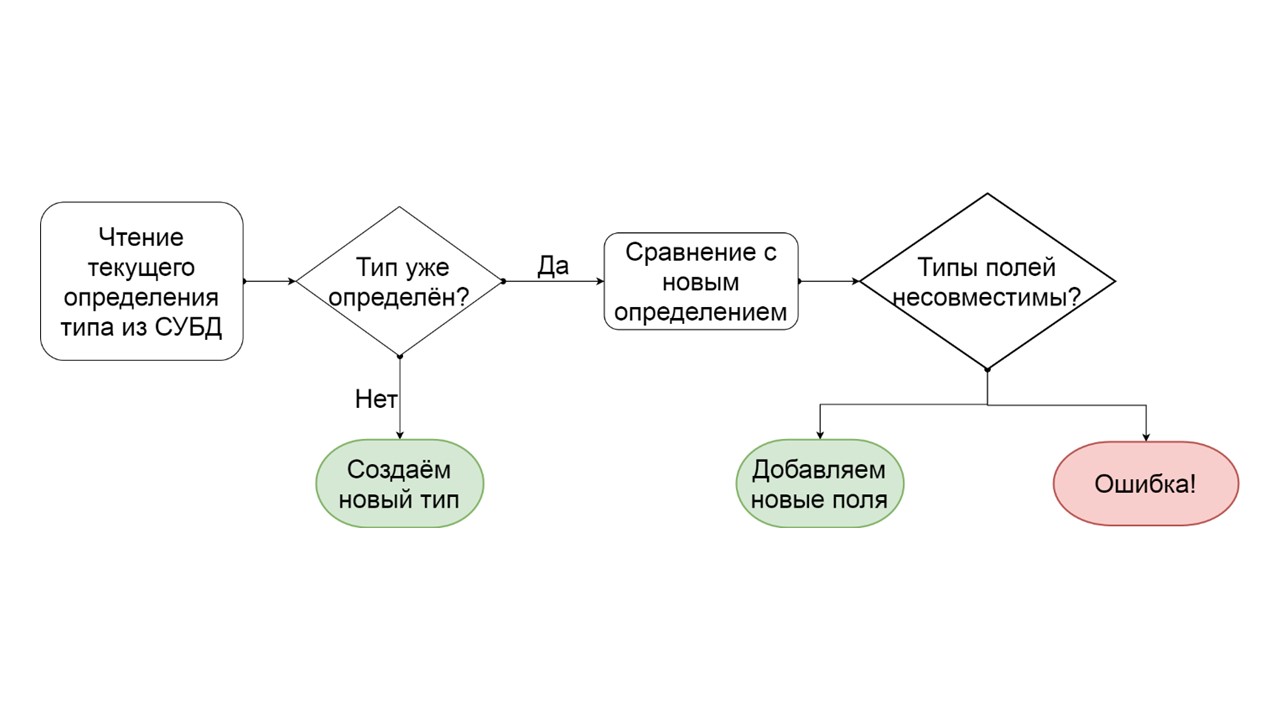
- Lemos como esse tipo é definido no DBMS.
- Se não existe esse tipo, ou seja, criamos um novo - nós o criamos.
- Se esse tipo já existe, estamos tentando comparar campo a campo a definição existente com a definição que queremos atribuir a esse tipo.
- Se queremos adicionar apenas alguns campos que não existem mais, o fazemos. Crie uma lista de operações ALTER TYPE mutantes e inicie-as.
- Se houver algum tipo de campo que seja de um tipo diferente - geraremos um erro. Por exemplo, havia lista - tornou-se mapa ou havia um link para um tipo definido pelo usuário, e estamos tentando torná-lo diferente.
O desenvolvedor pode ver esse erro antes mesmo de iniciar a funcionalidade na produção. Suponho que exatamente o mesmo esquema de dados esteja em seu ambiente de desenvolvimento. Ele vê que de alguma forma criou um esquema de dados não migrável e, para evitar esses erros, ele pode substituir a serialização gerada automaticamente, adicionar opções, renomear campos ou todos os tipos e tabelas como um todo.
Inicialização: Tipos
Imagine que existem vários tipos de definições:
case class Product (id: Long, name: ctring, price: BigDecimal) case class UserOffers (valiDate: LocalDate, offers: Seq[Products]) case class UserProducts (user User, products: Map[Date, Product]) case class UserInfo: UserOffers, products: UserProducts)
Case class - uma classe que contém um conjunto de campos. Este é um análogo da estrutura em Rust.
Geraremos aproximadamente essas definições de dados para cada um dos quatro tipos - o que queremos eventualmente pôr em marcha:
CREATE TYPE product (id bigint, name text, price decimal); CREATE TYPE user_offers (valid_date date, offers frozen<list<frozen<offer>>>); CREATE TYPE user_products (user frozen<user>, products frozen<map<date, frozen<product>>); CREATE TYPE user_jnfo (offers: frozen<user_offers>, products: frozen<user_products>);
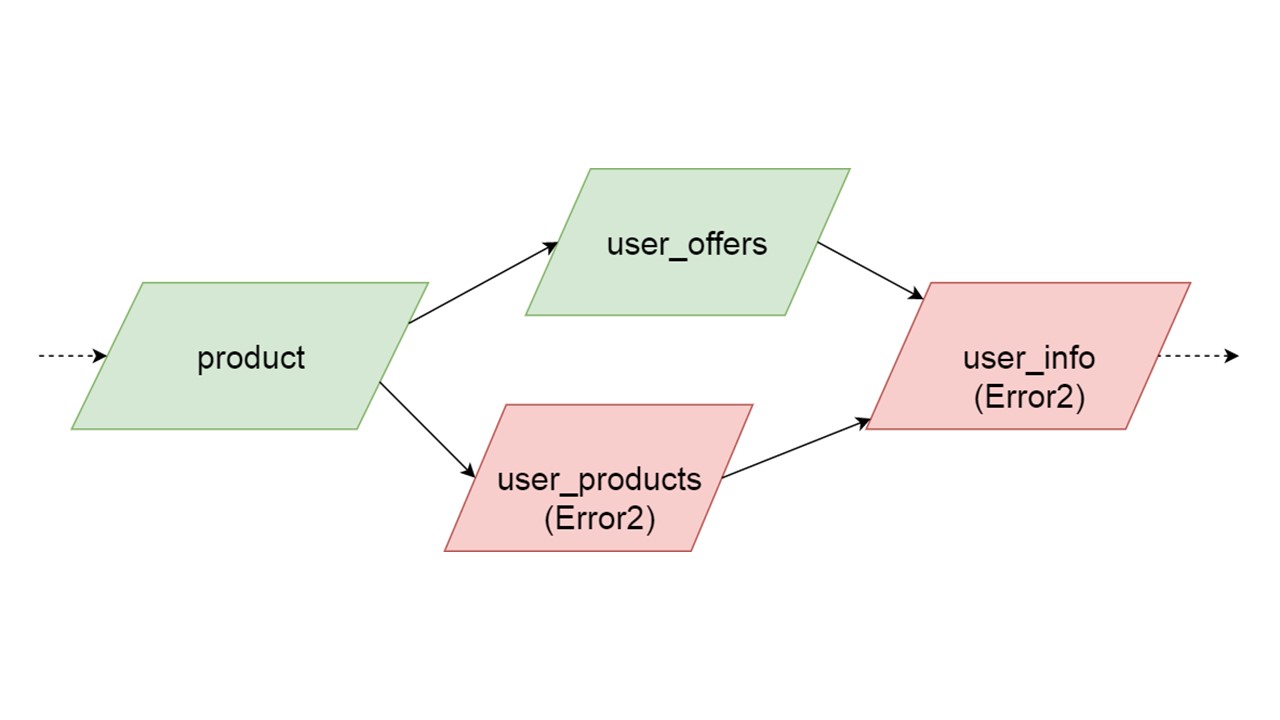
O tipo de user_offers depende do tipo de oferta, user_products depende do tipo de produto, user_info no segundo e terceiro tipos.

Temos uma dependência entre tipos e queremos inicializá-la corretamente. O diagrama mostra que inicializaremos user_offers e user_products em paralelo. Isso não significa que lançaremos duas operações paralelas. Não, iniciamos todas as instruções, todas as análises sequencialmente, para não criar acidentalmente o mesmo tipo em dois threads paralelos.
Mas há algum paralelismo no nível da correção de erros. Se ocorrer um erro de tipo, tudo o que depende dele puxará o erro original.
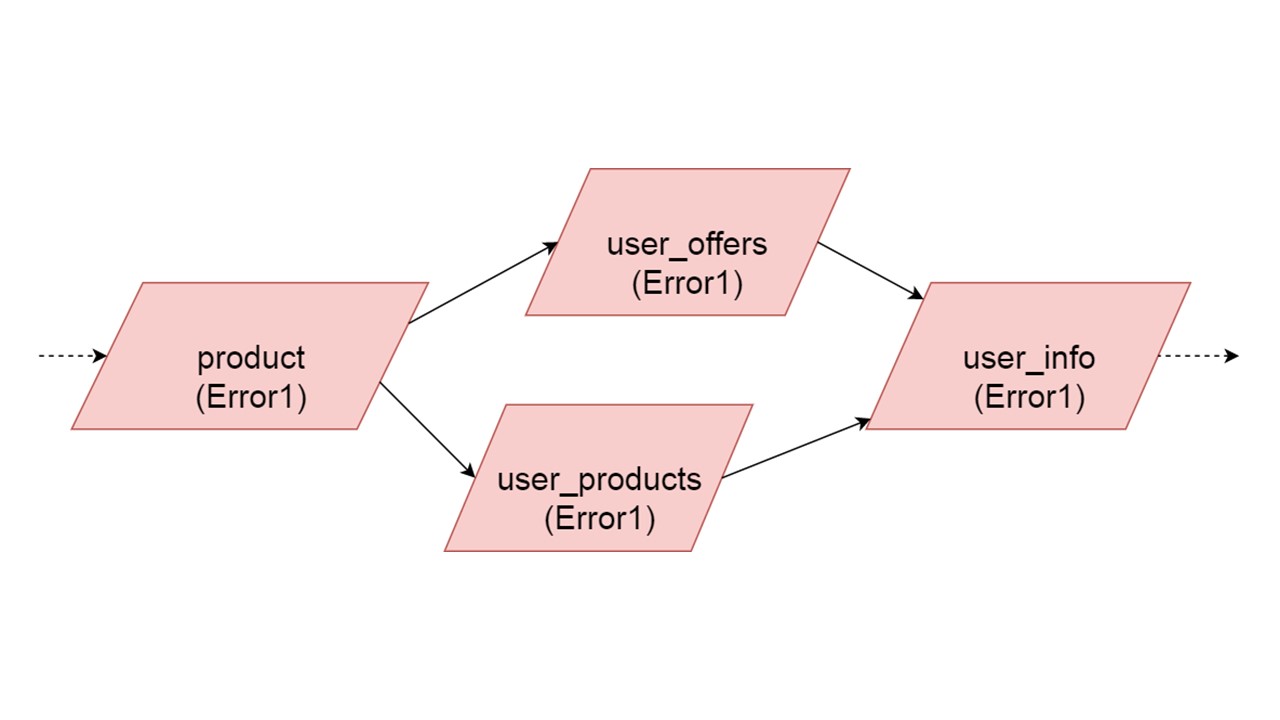
Se um erro for gerado por qualquer uma das ramificações paralelas, tudo o que depende dos dados normalmente migrados será gerado sem erro. Se houver mais definições de tabelas, instruções preparadas a partir delas, podemos inicializar com segurança essa parte do nosso Cache de Fallback. A comunicação será perdida apenas com alguma parte dos back-end ou com alguma funcionalidade. Os restantes são inicializados.
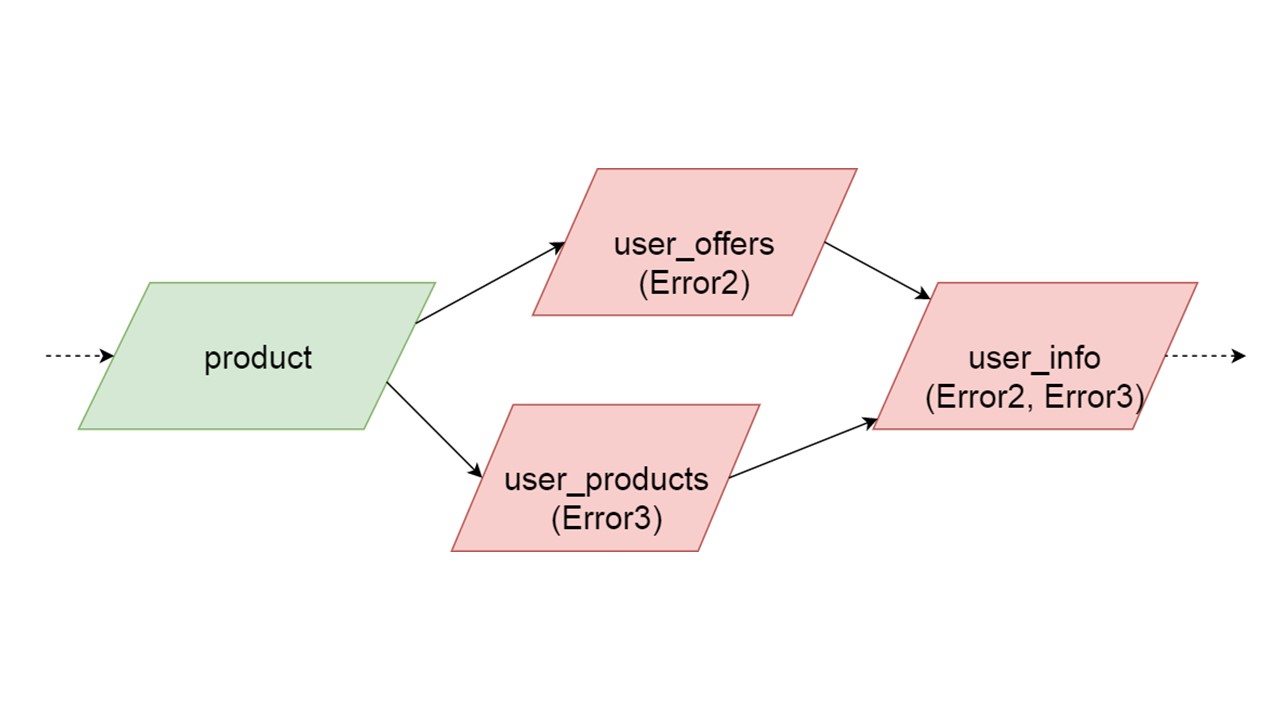
Pode acontecer que dois tipos inicializados simultaneamente gerem erros diferentes. Nesse caso, a funcionalidade que depende dos dois tipos produzirá um tipo de erro de soma. O desenvolvedor, inicializando seu Fallback no ambiente de desenvolvimento, receberá uma lista completa de dados com erros. Naturalmente, ele pode corrigi-lo aqui e obter o erro ainda mais. Mas não será tal que um ramo completamente independente feche os erros que poderíamos obter, independentemente desse ramo.
Inicialização: Tabelas
Em seguida, criamos as tabelas.
def getOffer (user: User, number: Long): Future[OfferData] create table get_offer( key frozen<tuple<frozen<user>, bigint>>PRIMARY KEY, value frozen<friend_data> )
Essa solicitação pode iniciar diretamente uma solicitação REST ou SOAP, criar operações adicionais internas ou até executar várias solicitações. Tudo depende do seu código - como você organizou o código. O fallback não analisa completamente o que acontece dentro do método no qual você pendura esse esboço.
O método deve ser assíncrono, porque o Fallback é o mesmo.
No Scala, isso é marcado com um tipo especial de Futuro. Isso significa que o resultado retornará um dia. Quando exatamente - é desconhecido: talvez imediatamente, ou talvez não.
Para o método, crie uma tabela. A chave na tabela é uma tupla de todos os tipos que correspondem aos parâmetros deste método. O valor não chave é o resultado, retornado de forma assíncrona. Para cada tabela, preparamos duas consultas paramétricas com antecedência: inserir dados e ler dados.
insert into get_offer(key, value) values (?key, ?value); select value from get_offer where key = ?key;
Tudo está pronto para interagir com o DBMS. Resta descobrir como vamos ler os dados do Fallback.
Disjuntor
Aqui, a responsabilidade passa para a zona do famoso padrão do disjuntor.
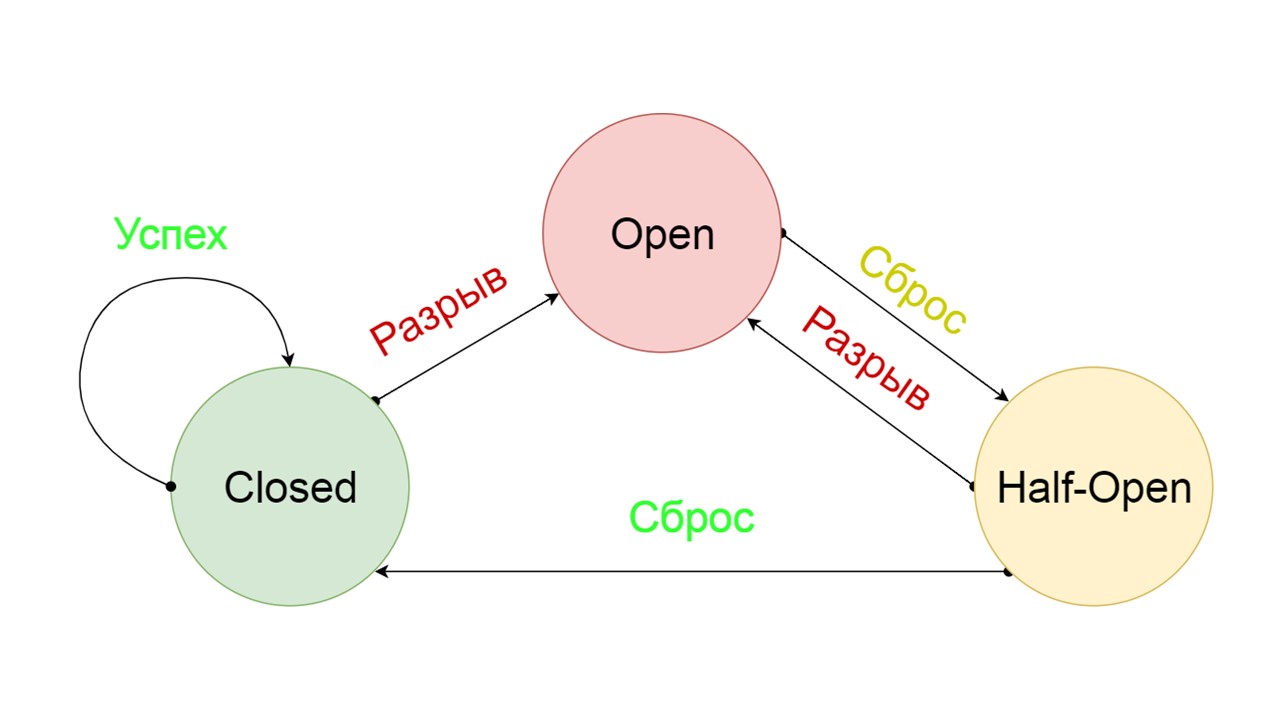
Um disjuntor típico inclui três estados.
Fechado - o estado fechado padrão que fecha nosso back-end. O princípio é que lemos os dados primeiro no back-end e, somente se não pudéssemos obtê-los, vamos para Fallback. Se conseguimos obter os dados, não procuramos no Fallback, mas salvamos os dados e nada acontece.
Se os problemas ocorrerem um após o outro, assumimos que o back-end está mentindo. Para não enviá-lo por spam com uma quantidade gigantesca de novas solicitações, mudamos para
Aberto - em um estado fragmentado . Nele, estamos tentando ler dados apenas do Fallback. Se não der certo, retornamos imediatamente um erro e nem tocamos no back-end principal.
Depois de um tempo, decidimos descobrir se o back-end acordou e tentamos redefinir o
estado Half-Open - um estado de curta duração . Seu tempo de vida é um pedido.
No estado de vida curta, optamos por fechar novamente ou abrir por um tempo ainda maior. Se no estado Semiaberto chegarmos com êxito ao Fallback e recebermos a próxima solicitação, iremos para o estado Fechado. Se não conseguimos, voltamos ao Open, mas por um longo tempo.
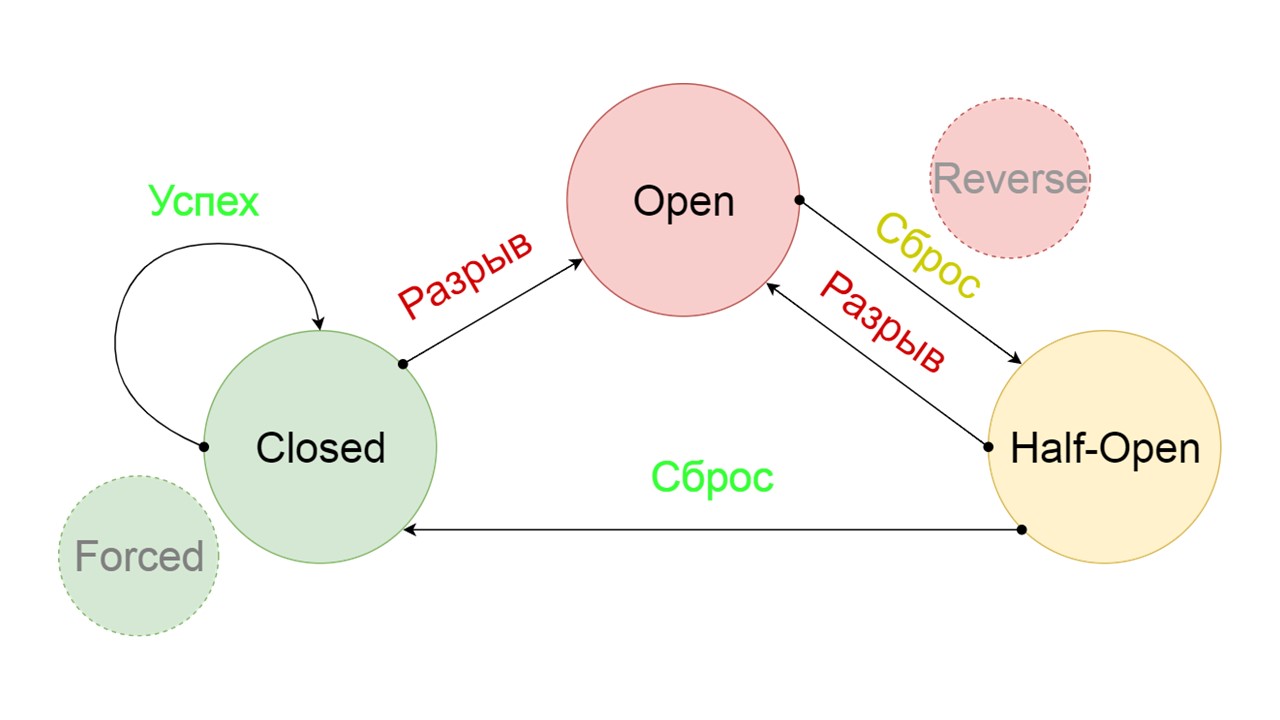
Adicionamos dois estados adicionais que claramente não estão relacionados ao circuito do disjuntor:
- Forçado - estado fechado à força;
- Invertida - prioridade para estado aberto e fechado invertido.
Vamos ver o que eles fazem.
O princípio de operação dos estados
Fechado O esquema é grande, mas basta entender o princípio geral. Mantemos o Fallback paralelo à forma como retornamos o resultado do back-end, se tudo correu bem lá e lemos no Fallback. Se estiver ruim em qualquer lugar, retornamos a prioridade do erro.
Dos dois erros, selecione o erro de back-end.
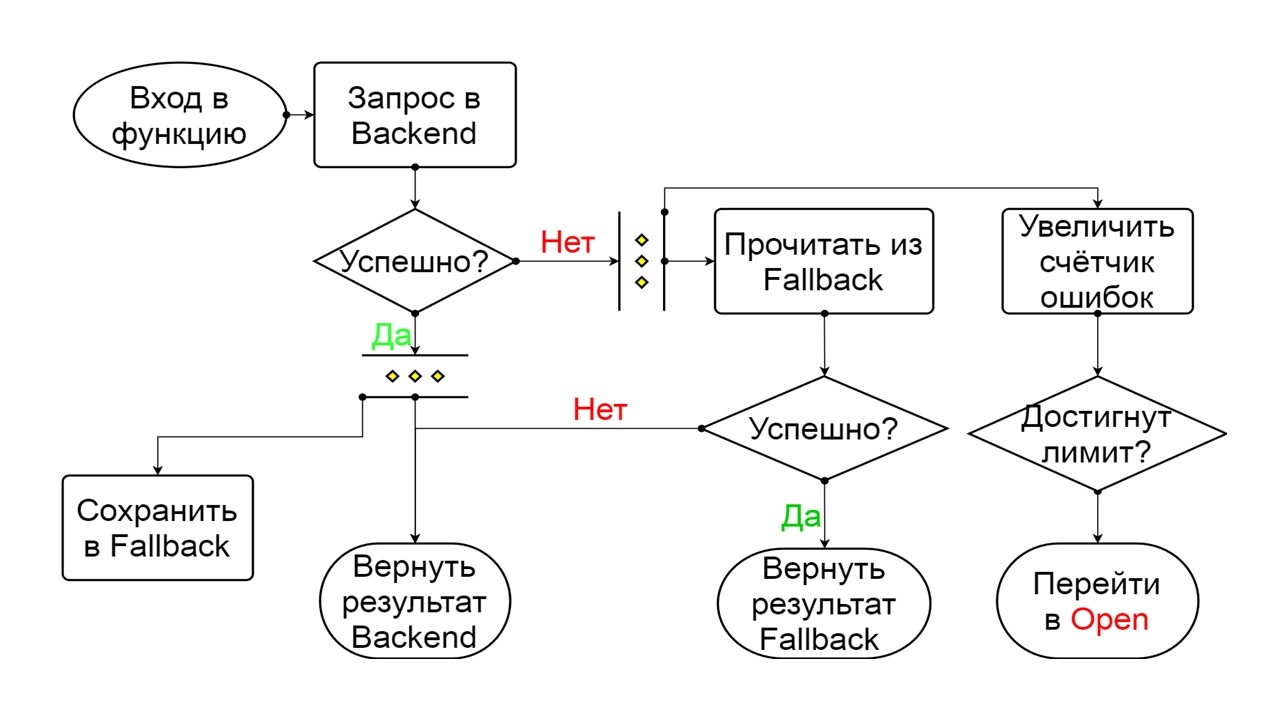
Se não houver erros, incrementamos o contador em paralelo com isso e entramos no estado aberto quando há muitas solicitações.
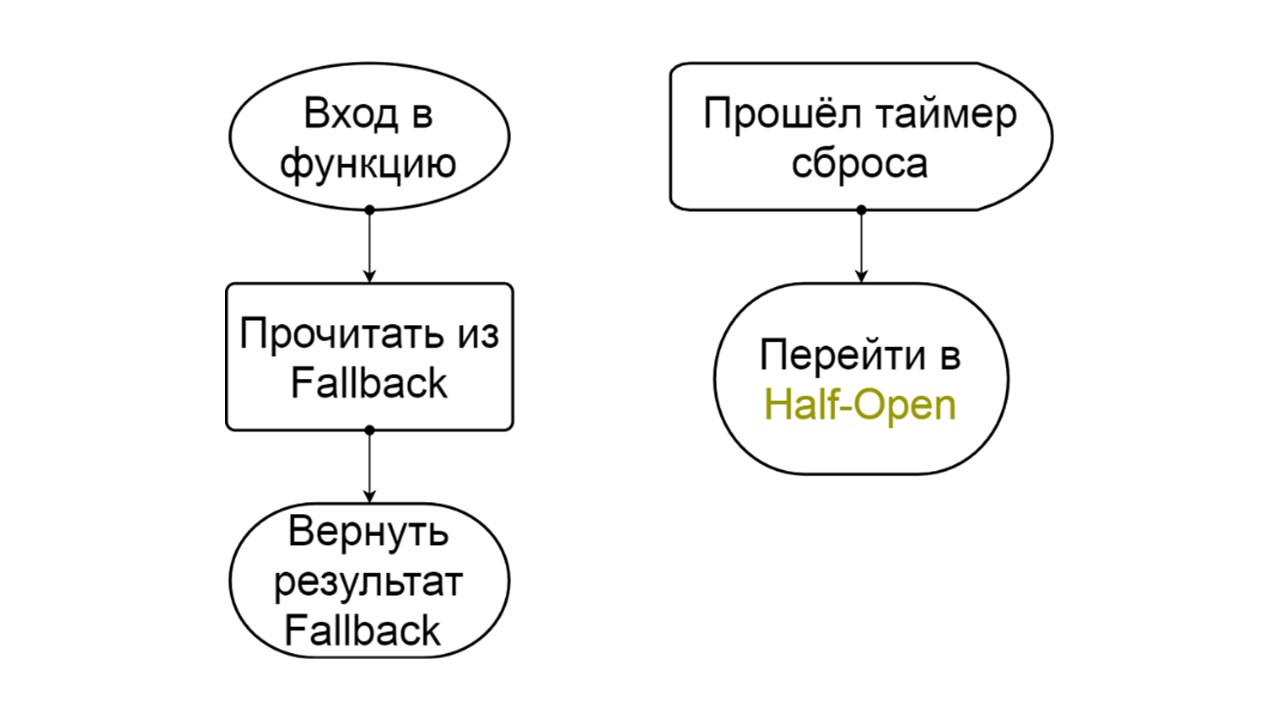 Aberto
Aberto O estado aberto do Open é mais simples - lemos constantemente o Fallback, não importa o que aconteça, e depois de um tempo tentamos mudar para o estado Half-Open.
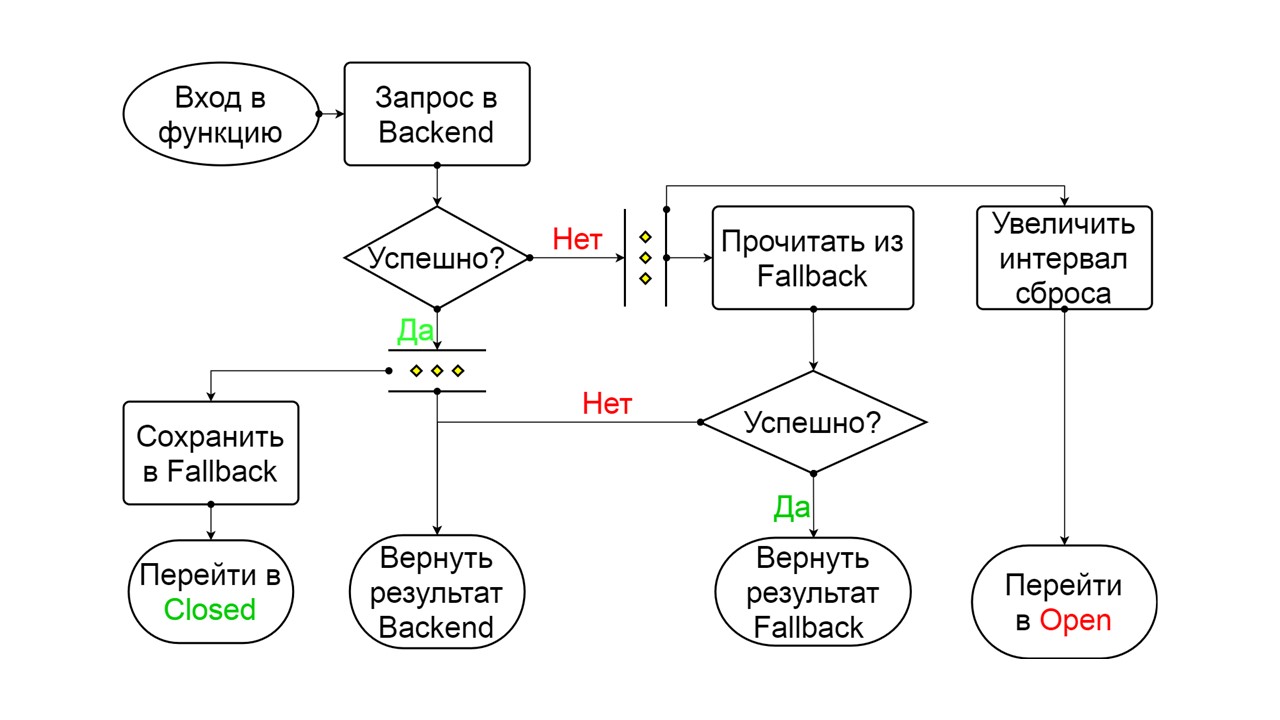
Semiaberto . O estado na estrutura é semelhante a Fechado. A diferença é que, no caso de uma resposta bem-sucedida, entramos em um estado fechado. Em caso de falha - retornamos ao aberto com um intervalo estendido.
 Forçado é um estado extra para aquecer o cache
Forçado é um estado extra para aquecer o cache . Quando o preenchemos com dados, ele nunca tenta ler no Fallback, mas apenas adiciona registros.
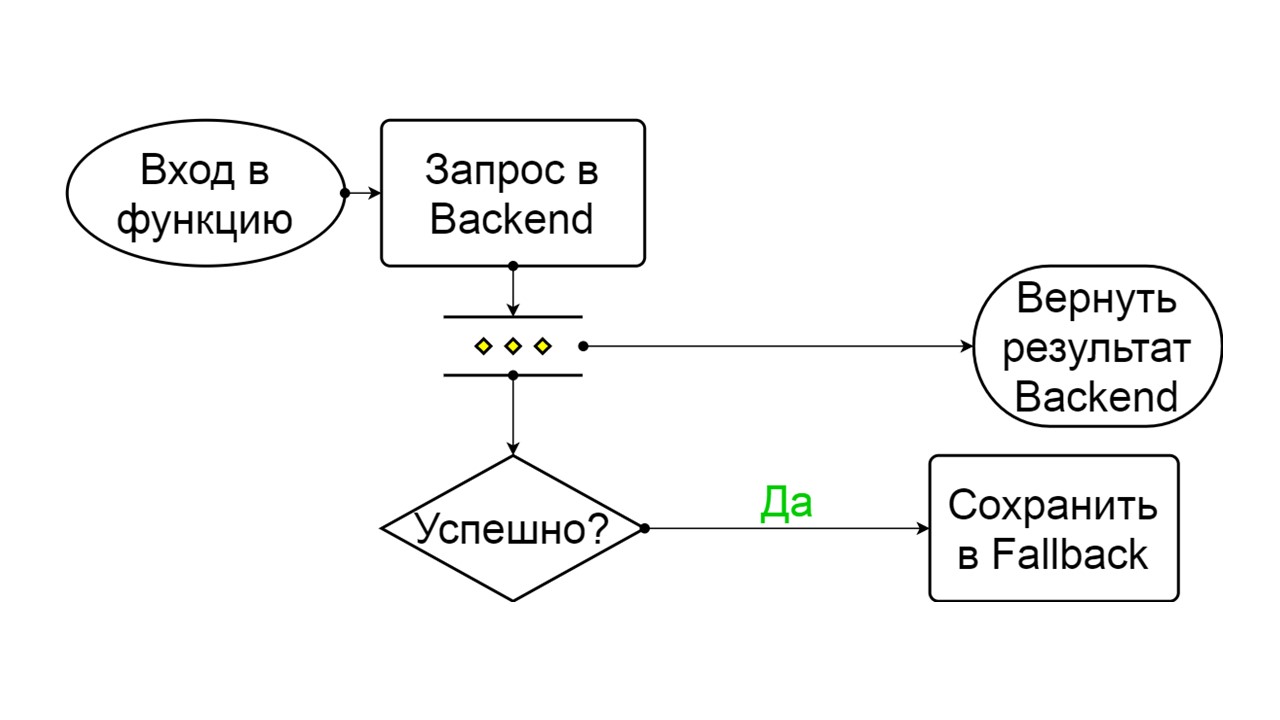 Invertido é um segundo estado rebuscado
Invertido é um segundo estado rebuscado . Funciona como um cache persistente. Ativamos o estado quando queremos remover permanentemente a carga do back-end, mesmo que os dados sejam irrelevantes. Primeiras pesquisas invertidas no Fallback e, se a pesquisa falhar, ela vai para o back-end e lida com isso.
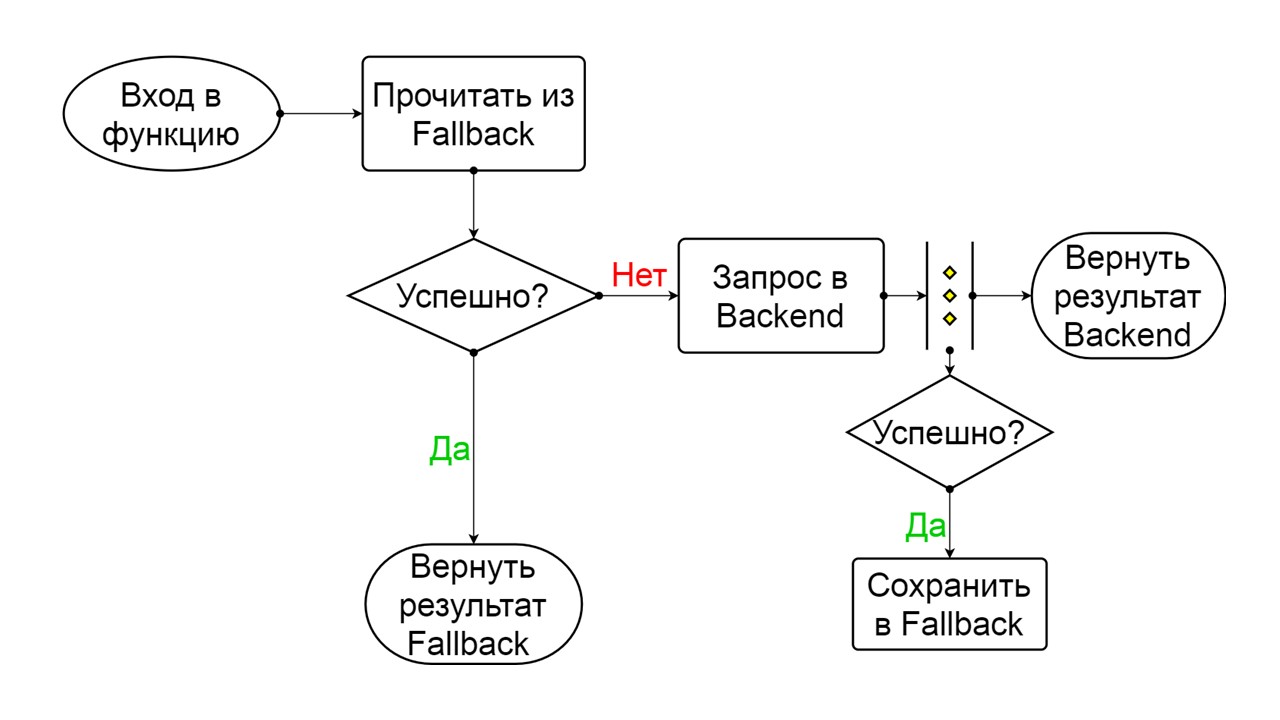
Os problemas
Com todo esse esquema, tivemos vários problemas. O mais sério é entender como as
declarações preparadas funcionam em Cassandra. Esse problema foi corrigido na versão 4.0, que ainda não foi lançada, por isso vou lhe dizer.
O Cassandra foi projetado para conectar milhões de clientes a ele ao mesmo tempo, e todos estão tentando preparar suas declarações preparadas. Naturalmente, Cassandra não prepara todas as declarações preparadas, caso contrário, ficará sem memória. Ele calcula o parâmetro MD5 com base nas opções de texto, espaço da chave e consulta. Se ela receber exatamente a mesma solicitação com exatamente o mesmo MD5, ela aceitará a solicitação já preparada. Ele já possui informações sobre metadados e como lidar com eles.
Mas há problemas de versão. Estamos lançando uma nova versão, ela rolou migrações com sucesso, adicionou campos em tipos e executou instruções preparadas. Eles retornam com a versão anterior do nosso estado e metadados - com tipos sem campos. No momento da leitura dos dados, estamos tentando escrever suas novas colunas necessárias e nos deparamos com o fato de que elas simplesmente não existem! Cassandra diz que esse geralmente é um tipo diferente que ela não conhece.
Lidamos com esse problema da seguinte maneira:
adicionamos um texto exclusivo a cada uma de nossas solicitações preparadas .
create table get_offer( key frozen<tuple<frozen<user>, bigint>> PRIMARY KEY, value frozen<friend_data>, query_tag text ) insert into get_offer (key, value, query_tag) values (?key, ?value, 'tag_123'); select value as tag_123 from get_offer where key = ?key;
Não teremos milhões de clientes conectados, mas apenas uma sessão para cada nó que possui várias conexões. Para cada declaração de preparação uma vez. Assumimos que não há problema se, para cada versão do aplicativo ou para cada início de um nó, um texto exclusivo for gerado, o que obviamente estará no texto de nossa solicitação.
Adicionamos um campo especial para enganá-lo. Ao inserir, escrevemos uma constante nesse campo. É exclusivo para cada versão de inicialização ou aplicativo - isso é configurado na biblioteca. Ao ler, usamos esse nome como alias para o valor que obtemos. A solicitação é exatamente a mesma, ainda estamos selecionando o valor, mas o texto é diferente. Cassandra não percebe que essa é a mesma solicitação, calcula outro MD5 e prepara a solicitação novamente com novos metadados.
O segundo problema é a
corrida de migração . Por exemplo, queremos fazer várias migrações paralelas. Vamos começar algumas anotações e, ao mesmo tempo, iniciarão os cálculos, executarão criar tabelas, criar tipos. Isso pode levar ao fato de que em cada nó ou em cada um dos encadeamentos paralelos tudo será bem-sucedido e duas tabelas parecerão criadas com êxito. Mas, por dentro, Cassandra fica confusa e receberemos intervalos para escrever e ler.
Você pode interromper o Cassandra se tentar paralelizar processos de vários encadeamentos ou de vários nós.
Se sabemos que devemos ter a migração de fallback,
migramos de um nó especial antes do lançamento . Somente então iniciaremos todos os nossos nós durante o lançamento. Então resolvemos esse problema.
O terceiro problema é a
falta de dados no cache de fallback . Pode ser que tenhamos "devolvido" o método, ele deve armazenar dados históricos de um ano atrás, mas, na realidade, o lançamos ontem.
O problema foi resolvido com o aquecimento . Usamos o estado Forçado e lançamos nós especiais que não se comunicam com usuários reais. Eles pegam todas as chaves possíveis que assumimos e aquecem o cache em um círculo. O aquecimento está indo tão rápido para não matar o backend que estamos lendo.
Dimensionamento de aplicativos, back-end, big data e front-end - Scala é adequado para tudo isso. 26 de novembro, estamos realizando uma conferência profissional para desenvolvedores Scala . Estilos, abordagens, dezenas de soluções para o mesmo problema, as nuances do uso de abordagens antigas e comprovadas, a prática da programação funcional, a teoria da cosmonáutica funcional radical - falaremos sobre tudo isso na conferência. Inscreva-se em um relatório se quiser compartilhar sua experiência Scala antes de 26 de setembro ou reserve seus ingressos .