Oi Equipe de análise ad-hoc de Big Data conectada do X5 Retail Group.
Neste artigo, falaremos sobre nossa metodologia de teste A / B e os desafios que enfrentamos diariamente.
O Big Data X5 emprega cerca de 200 pessoas, incluindo 70 a data dos cientistas e a data dos analistas. Nossa parte principal está envolvida em produtos específicos - demanda, sortimento, campanhas de promoção etc. Além deles, há nossa equipe de análise Ad-hoc separada.
Nós somos:
- ajudamos as unidades de negócios com solicitações de análise de dados que não se encaixam nos produtos existentes;
- ajudamos as equipes de produtos se precisarem de mãos extras;
- Estamos envolvidos nos testes A / B - e essa é a principal função da equipe.
A situação em que trabalhamos é muito diferente dos testes A / B típicos. Normalmente, a técnica está associada a métricas online e online: como as alterações afetam a conversão, retenção, CTR, etc. A maioria das experiências está relacionada a alterações na interface: reorganizou o banner, repintou o botão, substituiu o texto etc.
Os negócios X5 são diferentes - são ao vivo 15.000 lojas offline de vários formatos, distribuídos por todo o país. Esse recurso impõe certas limitações. Em primeiro lugar, o conjunto de métricas que podem ser testadas varia muito e, em segundo lugar, a restrição de experimentos é imposta. A tarefa de alterar o design de uma fachada de uma loja online não é comparável em termos de mão-de-obra à tarefa de alterar a ordem dos departamentos nas lojas offline.
A empresa possui uma equipe envolvida em um programa de fidelidade e seus pilotos estão mais próximos da idéia clássica dos testes A / B. As perguntas que surgem são muito atípicas para os testes A / B "comuns". Por exemplo:
- Como o desempenho financeiro da loja mudará se eu alterar a ordem dos departamentos de Linguiça e Bolos?
- Como o modelo de rotatividade de clientes afetará o resultado financeiro?
- Como a configuração de postamates afetará o desempenho da loja?
Os clientes acreditam que uma certa mudança afetará positivamente um dos indicadores (falaremos sobre eles mais tarde). Nosso trabalho é ajudá-los a validar suas hipóteses com base em dados.
Métricas
Quais indicadores estamos testando?
RTO ,
verificação média e
tráfego são as palavras mais usadas em nossa ala de espaço aberto.
- RTO (rotatividade de varejo) - a quantidade de dinheiro ganho pela loja.
Uma das principais métricas para os negócios e a mais difícil de testar.
O volume de negócios diário da loja é medido em milhões de rublos. Por conseguinte, a propagação do indicador é medida em pelo menos milhares de rublos. A fórmula complexa e longa para determinar o tamanho da amostra diz que, quanto maior a variação, mais dados são necessários para quaisquer conclusões significativas. Para captar o efeito mesmo no décimo por cento com uma dispersão tão grande da TDF, os pilotos nas lojas precisam passar seis meses.
Imagine a reação do conselho, se em uma reunião com eles disser que o piloto precisa passar seis meses ou até um ano em todas as lojas? =)
Temos duas abordagens padrão.
A primeira abordagem: não estamos considerando o RTO de toda a loja, mas algum tipo de categoria de produto. Por exemplo, como resultado do rearranjo de duas seções na loja (“Bolos” e “Enchidos”), é esperado um aumento na TDF em ambas as categorias. O RTO de uma categoria é muito menor que o RTO de toda a loja, portanto, a dispersão é menor. Nesse caso, esperamos que o piloto nessas categorias seja isolado das demais categorias.
Segunda abordagem: amostramos o tempo. A unidade de observação não é a TDF da loja para todo o piloto, mas a TDF por semana ou dia. Assim, aumentamos o número de observações, mantendo a variação dos dados brutos.
- Cheque médio ou RTO / número de cheques - a quantidade média de dinheiro em um cheque.
Parte das mudanças visa fazer as pessoas comprarem mais, por isso testamos o RTO / número de cheques, ou o cheque médio, se fizermos analogias com as métricas usuais.
A dificuldade em testar essa métrica está relacionada às especificidades do varejo. Por exemplo, com o lançamento piloto da promoção “3 pelo preço de 2”, uma pessoa que planejava comprar um produto compraria três, e o valor do cheque aumentará. Mas e se ele mais tarde se tornar menos provável de ir à loja e o piloto não ter tanto sucesso?
- Tráfego - o número de verificações na loja por um determinado período de tempo.
Para evitar conclusões errôneas ao testar hipóteses que afetam a verificação média, analisamos simultaneamente as alterações de tráfego. Não podemos rastrear diretamente quantas pessoas foram à loja, pois nem todos os visitantes são clientes do programa de fidelidade; portanto, para os testes A / B, cada verificação é uma "visita única" ao cliente. Por analogia com a PTO, consideramos o tráfego em vários intervalos de tempo: tráfego por dia, tráfego por hora.
A inter-relação da verificação e do tráfego médios é muito importante: o piloto poderia aumentar a verificação média, mas reduzir o tráfego e, por fim, levar não a um aumento na TDF, mas a sua diminuição? O piloto poderia ajudar a aumentar o tráfego sem alterar a fatura média?
- Margem - a diferença entre o preço de um produto e seu custo
Existem pilotos nos quais alteramos os preços dos produtos - para alguns, o preço aumentou, para outros, pelo contrário. Como não afetamos os custos de produção, alterando os preços, alteramos a margem das mercadorias. Esse piloto pode levar ao aumento do tráfego e ao aumento da verificação média. Mas isso significa que o piloto é bem-sucedido e vale a pena alterar os preços em todas as lojas da rede? Não, poderia muito bem acontecer que as pessoas começassem a comprar mercadorias com uma margem negativa ou pequena com mais frequência e abandonassem as mercadorias com uma margem alta. Portanto, nem sempre um aumento no RTO é seguido por um aumento na margem total; portanto, vale a pena testar esses indicadores separadamente.
Bem, digamos que decidimos sobre as métricas de destino. As seguintes perguntas:
- Que efeito de tamanho o cliente planeja receber?
- Que efeito pode realmente ser detectado no experimento?
- Quanto tempo leva o experimento?
- Quais grupos?
Resumo da experiência
Os testes A / B realizados em usuários on-line têm uma vantagem significativa - eles têm uma capacidade generalizada alta. Em outras palavras, as conclusões obtidas durante o experimento podem ser dimensionadas para todos os usuários. A capacidade de generalização é garantida pela configuração do experimento: os grupos de controle e teste são formados aleatoriamente, quase exatamente os dois grupos da mesma distribuição, você pode capturar muito tráfego nos dois grupos - haveria um orçamento.
No caso do varejo offline, nenhuma dessas configurações funciona. Em primeiro lugar, há um limite no número de lojas. Em segundo lugar, as lojas são muito diferentes umas das outras. A loja Perekrestok na área residencial e a Perekrestok perto do centro de negócios são, de fato, objetos muito diferentes de diferentes distribuições.

No gráfico, vemos que as lojas do grupo de teste são diferentes das lojas de toda a rede. Esta é uma situação bastante típica: nas cadeias de lojas de Pyaterochka estão localizadas não apenas nas cidades, mas também em pequenos assentamentos. Os grandes pilotos costumam ser realizados nas cidades. Seja qual for o efeito que capturamos, escalá-lo em toda a rede está errado.
O efeito total
Є do piloto avaliamos pela fórmula:

a é a área de interseção das distribuições do grupo piloto e de todas as lojas da rede.
Observe que isso não é uma conseqüência das leis estatísticas, mas nossa suposição sobre como é lógico considerar o efeito cumulativo.
A opção ideal é recrutar uma amostra representativa para o grupo de teste, ou seja, aquelas lojas que realmente refletem todo o estado da rede. Mas a representatividade leva à heterogeneidade da amostra, porque lojas com baixa ou alta TDF serão amostradas.
Tamanhos de grupos, duração do piloto e efeito detectável mínimo
E agora a coisa mais importante - o tamanho do efeito e a duração do piloto. Como regra, somos confrontados com uma das três situações:
- o cliente tem um limite de tempo para o piloto e o número de lojas com as quais você pode trabalhar;
- o cliente sabe qual o tamanho do efeito que ele espera receber e pede para indicar o número de lojas que o piloto precisa (e depois as próprias lojas);
- o cliente está aberto para nossas ofertas.
Não se pode dizer que qualquer um dos cenários seja mais simples, porque, de qualquer forma, estamos preparando uma tabela do erro de efeito.
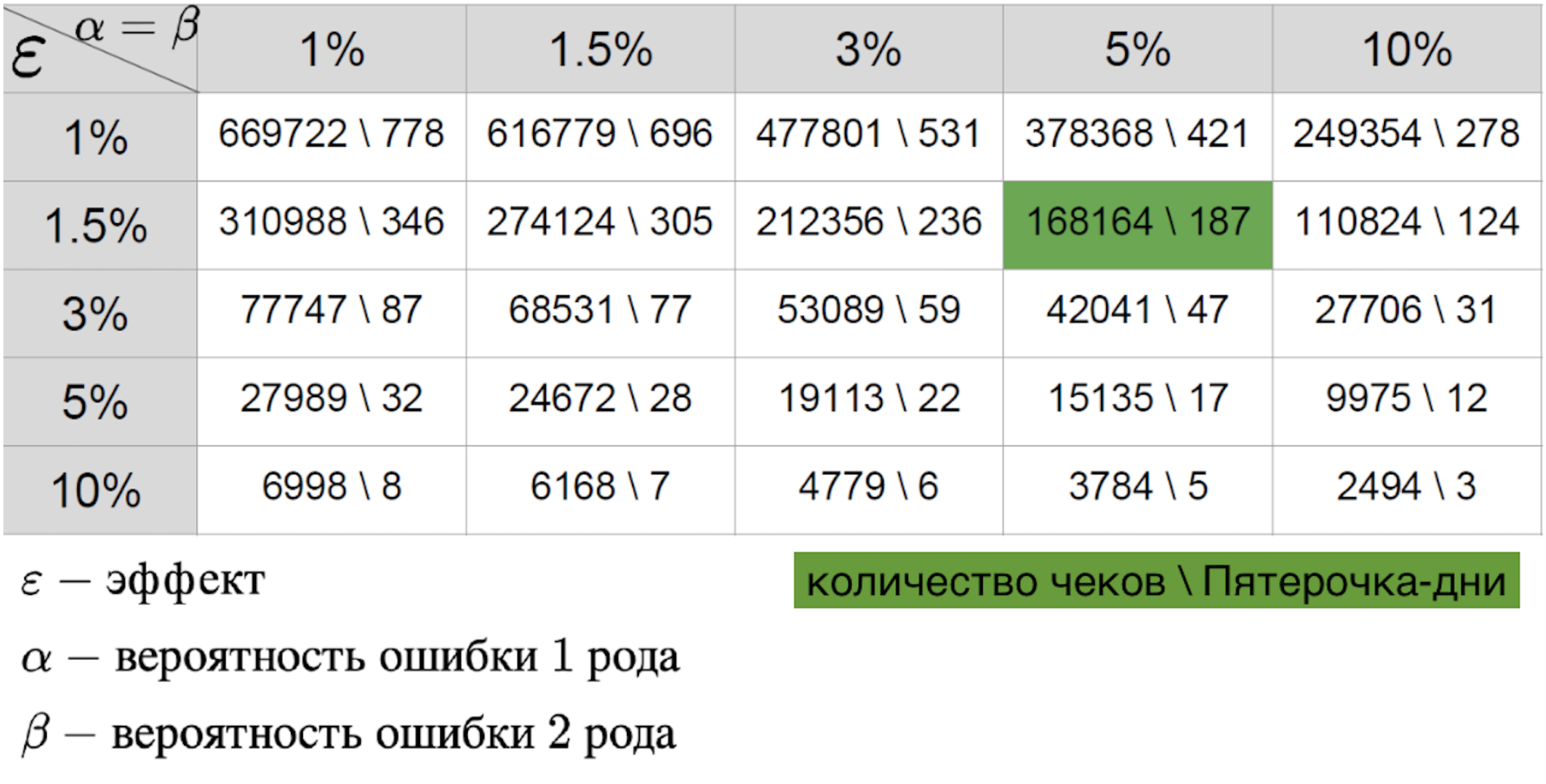
Importante para ela:
- um erro do primeiro tipo - a probabilidade de ver o efeito quando não existe;
- um erro do segundo tipo - a probabilidade de pular o efeito quando é;
- o tamanho do efeito esperado para um piloto bem-sucedido.
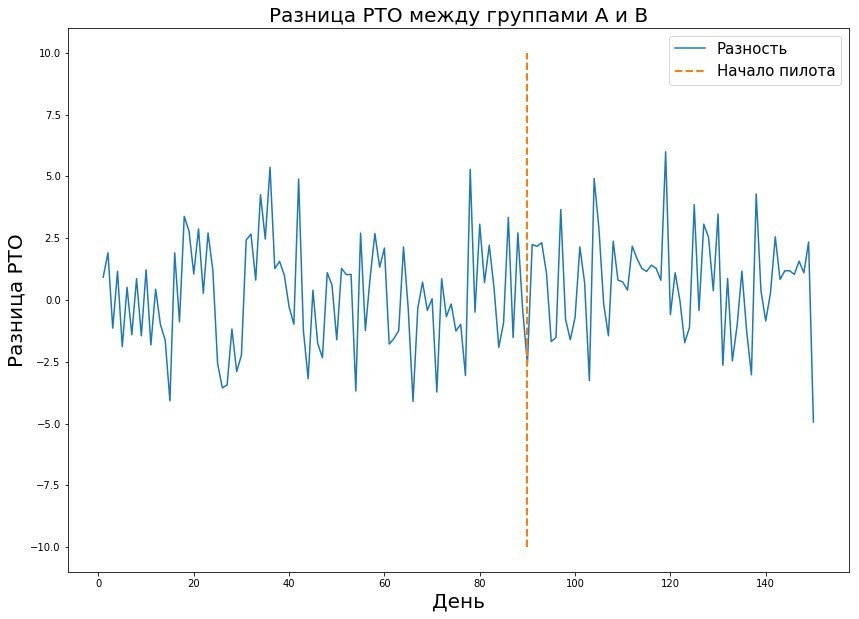
A combinação desses três parâmetros permite calcular a duração necessária do piloto. O valor na tabela é o tamanho da amostra - nesse caso, o número de recebimentos ou a métrica média na loja por dia, necessários para conduzir o piloto. Se falamos sobre o mundo real, geralmente a probabilidade de erros do primeiro e do segundo tipo é de 5 a 10%. Como pode ser visto na tabela, com esses erros corrigidos, precisamos de 421 Pyaterochka-day para capturar o efeito de um por cento. Parece que o número é muito bom - afinal, 421 dias em Pyaterochka é piloto em 40 lojas por 10 dias. No entanto, existe um "mas" - existem muito poucos pilotos que realmente esperam um efeito de um por cento. Normalmente estamos falando de décimos de um por cento. Dado que a RTO é medida em bilhões, um décimo de por cento do efeito de um piloto bem-sucedido pode gerar um grande aumento na receita. Por isso, quero medir até o menor efeito. Porém, quanto menor o tamanho do efeito, maior o erro do segundo tipo. Isso é compreensível: o pequeno efeito é semelhante ao ruído aleatório e raramente será considerado um desvio real da norma. Isso é claramente visto no gráfico abaixo, onde queremos capturar um pequeno efeito nos dados com grande variação.

Teste A / A
Antes do início do piloto, você precisa decidir sobre o grupo de teste e controle. O cliente pode ou não ter um grupo piloto. Estamos prontos para ajudá-lo nos dois casos, solicitando restrições - por exemplo, as lojas devem ser estritamente de três regiões específicas.
Suponha que tenhamos escolhido de alguma forma um grupo de teste e controle. Como ter certeza de que os grupos selecionados são bons e você pode realmente realizar testes A / B neles? Parece que tudo parece harmonioso: pontuamos o número necessário de observações, de acordo com a fórmula, podemos pegar o efeito de 0,7%, encontramos lojas semelhantes. O que agora não nos convém?
Infelizmente, muitos fatos sérios:
- elementos da amostra não são da mesma distribuição - nossa amostra é uma mistura de observações de lojas diferentes e cada loja tem sua própria distribuição.
- os elementos da amostra não são independentes - na amostra há muitas observações de uma loja, respectivamente, há uma conexão entre elas;
- a igualdade de meios não é garantida na ausência de um piloto - ou seja, não temos certeza de que, se não houvesse um piloto, as estatísticas da loja não seriam diferentes.
Todos esses problemas não são levados em consideração no cálculo da fórmula para selecionar o número de observações, dependendo de erros e efeitos. Para entender a extensão do impacto dos problemas acima, realizamos testes A / A. De fato, é uma simulação de todo o piloto nas lojas, no momento em que não há piloto nas lojas. Esse período é chamado de pré-piloto.

Durante o período pré-piloto, repetimos três etapas várias vezes:
- seleção de grupos semelhantes;
- teste de igualdade em dois grupos;
- adicionando efeito ao grupo de teste e testando os meios para igualdade.

Correspondência de grupos semelhantes
Como não inventamos uma bicicleta, procuramos grupos semelhantes com o bom e velho método dos vizinhos mais próximos. A estratégia de gerar recursos para a loja é uma arte separada. Encontramos três métodos de trabalho:
- Cada loja é descrita por um vetor de recurso de acordo com a métrica que estamos testando. Por exemplo, ao examinar a verificação média, descrevemos as verificações médias diárias por 8 semanas - recebemos 56 sinais para a loja. Então tomamos a distância euclidiana entre os sinais de um par de lojas.
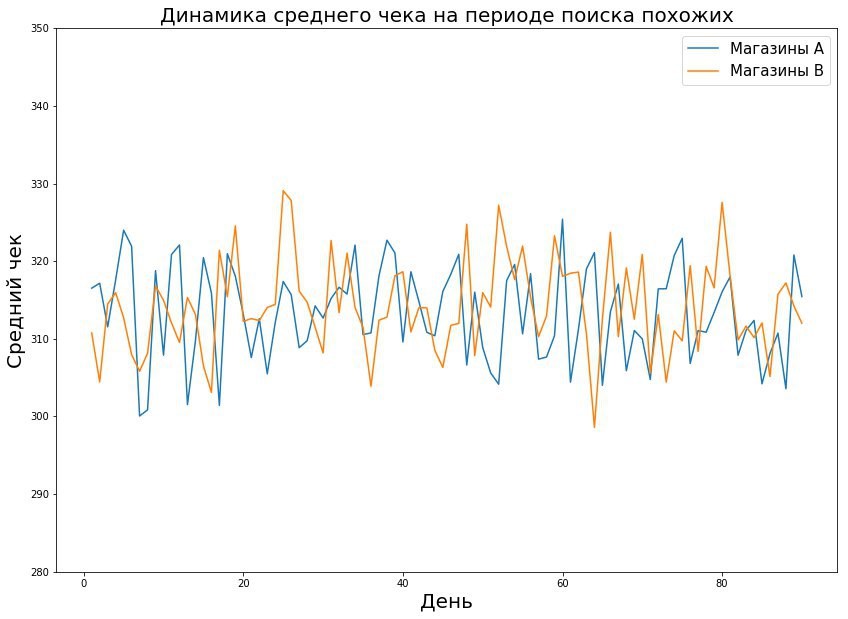
- Encontre lojas semelhantes em dinâmica. As lojas podem diferir em valores absolutos das métricas, mas coincidem em tendências - e com certas manipulações matemáticas, essas lojas podem ser consideradas iguais.
- Preveja o desempenho da loja no período do piloto (no futuro) e selecione similares com base neles - mas aqui precisamos de um oráculo que possa prever o desempenho do piloto com bastante precisão.
Aderimos a uma hipótese muito simples: se as lojas fossem semelhantes antes do piloto, se não houvesse uma mudança de piloto, elas teriam permanecido semelhantes.
Você pode notar que, mesmo nesses três métodos de trabalho, há muitos aspectos que podem ser variados: o número de dias / semanas em que um recurso é considerado, um método para avaliar a dinâmica de um indicador etc.
Não existe pílula universal; em cada experimento, passamos por diferentes opções com base em nosso objetivo. Mas é muito simples: encontre um método para selecionar os vizinhos mais próximos que dê erros razoáveis do primeiro e do segundo tipo. De onde eles vêm, contamos mais.
Teste de igualdade de médias ou erro do primeiro tipo de método
Lembre-se de que, neste ponto, nós:
- determinado com o cliente o tamanho do efeito e a duração do piloto
- explicou a essência dos erros do primeiro e do segundo tipo
- construiu um método para selecionar grupos semelhantes
O objetivo desse estágio é garantir que o método que selecionamos na Seção 3 encontre grupos que antes do piloto iniciar o indicador (RTO, verificação média, tráfego) nessas lojas não sejam estatisticamente diferentes.
No ciclo, selecionamos os grupos selecionados repetidamente para igualdade por algum tipo de teste estatístico e autoinicialização. Se a proporção de erros (ou seja, os grupos não forem iguais) for maior que o limite, o método será rejeitado e um novo será selecionado. Então, até atingirmos o limite desejado de erro.
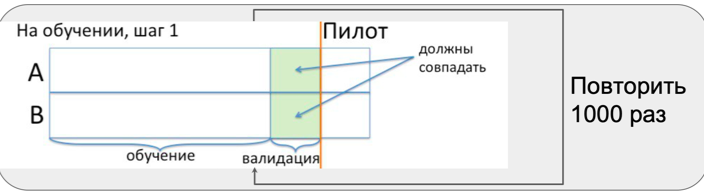
É importante descobrir com que frequência captamos o efeito quando ele não está presente, ou seja, se nosso método de seleção responde a diferenças aleatórias entre lojas ou não.
Adicionando um efeito ou um erro do segundo tipo de método
Uma pergunta razoável, mas não estamos nos treinando de tal maneira que também perceberemos os efeitos reais como ruído e os ignoraremos? Em outras palavras, somos capazes de detectar um efeito quando é?
Depois de garantir na última etapa que os grupos coincidem, adicionamos um efeito artificial a um dos grupos, ou seja, Garantimos que o piloto tenha sucesso e que o efeito deva ser.
Desta vez, o objetivo é descobrir com que frequência a hipótese de igualdade é rejeitada, ou seja, o teste foi capaz de distinguir entre dois grupos. O erro neste caso é assumir que os grupos são iguais. Chamamos esse erro de um segundo tipo.
Novamente no ciclo, testamos a igualdade no grupo de controle e no grupo de teste "barulhento". Se cometermos erros raramente, acreditamos que o método de seleção de grupos passou na validação. Ele pode ser usado para selecionar grupos no período piloto e ter certeza de que, se o piloto der um efeito, seremos capazes de detectá-lo.

Sobre heterogeneidade
Já mencionamos que a heterogeneidade dos dados é um dos piores inimigos que estamos lutando. As heterogeneidades surgem de várias causas principais:
- heterogeneidade de compras - cada loja tem seu próprio valor métrico médio (nas lojas RTO de Moscou e o tráfego é muito maior do que nas lojas das aldeias)
- heterogeneidade por dia da semana - distribuição diferente do tráfego e verificação média diferente em diferentes dias da semana: o tráfego na terça-feira não se parece com o tráfego na sexta-feira
- heterogeneidade no clima - as pessoas vão às compras de maneira diferente em diferentes condições climáticas
- heterogeneidade na época do ano - o tráfego nos meses de inverno difere do tráfego no verão - isso deve ser levado em consideração se o piloto durar várias semanas.
A falta de homogeneidade aumenta a variância, que, como mencionado acima, na avaliação das lojas de tomada de força já tem um significado enorme. O tamanho do efeito capturado é diretamente dependente da variação. Por exemplo, reduzir a dispersão por um fator de quatro permite detectar um meio efeito.
No caso mais simples, estamos lutando com a heterogeneidade da linearização.
Suponha que tenhamos um piloto em duas lojas por três dias (sim, isso contradiz todas as fórmulas prescritas sobre o tamanho do efeito, mas este é um exemplo). As
RTOs médias nas lojas são respectivamente 200 mil e 500 mil, enquanto a variação nos dois grupos é de 10.000 e, de acordo com todas as observações - 35.000
Após o piloto, as médias estão nos grupos 300 e 600 e as variações são 10.000 e 22.500, respectivamente, e o grupo inteiro é 40.000.

Uma ação simples e elegante é linearizar os dados, ou seja, subtrair de cada período o valor da média do anterior.

Na saída, a amostra: 100, 0, 200, -50, 100, 250. A dispersão no período piloto foi reduzida em 3 vezes para 13000.
Isso significa que podemos ver um efeito muito mais sutil do que com os valores absolutos originais.
Esta não é a única maneira de lidar com a heterogeneidade. Falaremos sobre outros no próximo artigo.
Abordagem geral ao teste A / B
A preparação para grandes pilotos e sua avaliação passam por nossa equipe e são exaustivamente testados.
Nosso protocolo:
- receber informações do cliente sobre a métrica e o efeito esperado;
- determinar o tamanho dos grupos e a duração do piloto;
- desenvolver um algoritmo para a distribuição de lojas por grupos;
- realizar um teste A / A entre grupos e validar esse algoritmo;
- aguarde o piloto terminar e calcular o efeito.
Nenhuma dessas etapas passa sem dificuldades, cada uma delas possui características. Como lidamos com alguns deles, descrevemos neste artigo. No próximo, falaremos sobre ....
A equipe
No final, gostaria de mencionar todos os atores:
- Valery Babushkin
- Alexander Sakhnov
- Denis Ivanov
- Sergey Demchenko
- Nikolay Nazarov
- Sergey Kabanov
- Yuri Galimullin
- Helen Tevanyan
- Vladislav Ladenkov
- Sergey Zakharov
- Vasily Stories
- Alexander Belyaev
- Kismat Magomedov
- Egor Krashennikov
- Egor Karnaukh
- Svyatoslav Oreshin
- Yuri Trubitsyn