Hoje, exploraremos o protocolo STP da Spanning Tree. Este tópico assusta muitas pessoas devido à sua aparente complexidade, porque elas não conseguem entender o que o protocolo STP faz. Espero que, no final deste tutorial em vídeo ou na próxima lição, você entenda como essa "árvore" funciona. Antes de iniciar a lição, quero mostrar o novo design da minha área de trabalho para esta semana.
Você também pode configurar sua área de trabalho de maneira semelhante se usar o link no canto superior direito deste vídeo. E não esqueça de "curtir" e compartilhar minhas vídeo aulas com os amigos.
Como na última vez, hoje discutiremos outro tópico de acordo com o cronograma do ICND2 apresentado no site da Cisco. Esta é a seção 1.3, “Configurando, verificando e problemas com os protocolos STP”, parágrafo 1.3a, “Modos STP (PVST + e RPVST +)” e 1.3b, “Selecionando um comutador de ponte raiz STP”.
Como esse é um tópico extenso, mudei a discussão da subseção 1.3b para a próxima lição, “Dia 37”, e adicionarei a seção 1.4. Portanto, hoje analisamos como é o STP, observamos os modos desse protocolo PVST + e RPVST + e, em seguida, observamos o identificador do comutador raiz do ID da ponte e o custo da rota para a porta raiz do custo de porta.

Para começar, precisamos entender qual é o loop de comutação que aparece no 2º nível do modelo OSI (no nível do quadro) e quais problemas estão associados a ele. Já discutimos o loop de tráfego em um dos episódios anteriores, e essa lição pode ser considerada uma introdução ao tópico de hoje. Deixe-me dar um exemplo: temos o comutador A e o comutador B conectados um ao outro por duas linhas de comunicação, o primeiro usuário se chama Joe e o segundo é Jim.

Se Joe envia uma mensagem para Jim, ele envia o quadro para o comutador A. O comutador A não conhece o endereço MAC de Jim; portanto, ele envia um quadro de Broadcast por todas as portas, exceto aquela pela qual Joe recebeu a mensagem. Quando o quadro Broadcast é recebido pelas portas do switch B, o pacote que chega em uma interface é enviado para Jim e o pacote que chega na segunda interface é encaminhado para a primeira porta e enviado de volta para o switch A.

Ao mesmo tempo, uma solicitação que chega na primeira interface é encaminhada para a segunda porta e também é enviada para o comutador A.
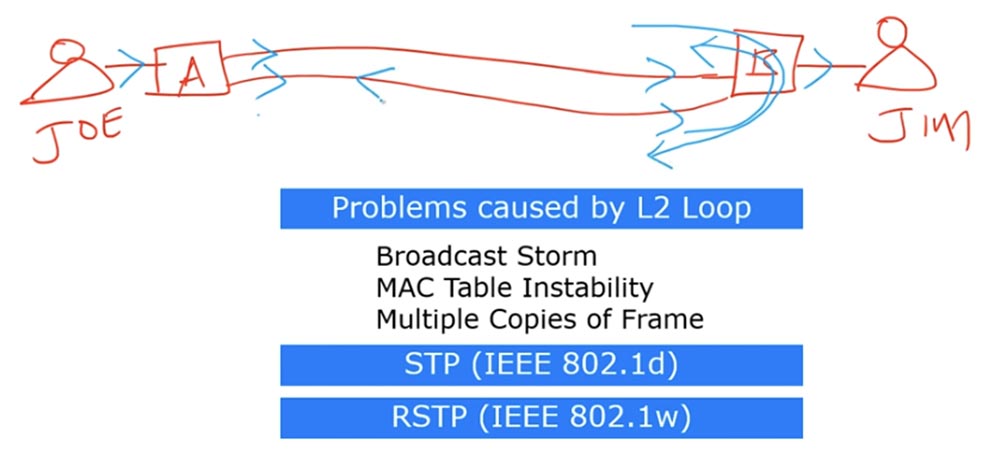
Depois de receber esses quadros de transmissão, o switch A os envia de volta: o quadro recebido na primeira interface é enviado na segunda e o recebido na segunda é enviado para a rede através da primeira interface. Esse processo se repete repetidamente, formando um loop de solicitações de transmissão. Se outro Broadcast entrar na rede, ele fará o loop da mesma maneira que o primeiro. O resultado é um fenômeno chamado Broadcast storm, ou broadcast storm. A rede inunda tantos quadros de transmissão que trava. Essa tempestade pode parar apenas quando um dos dispositivos é desconectado ou a conexão é interrompida. Se a linha permanecer operacional, logo após o início de uma tempestade, um dos comutadores deixará de funcionar devido ao estouro de memória. No segundo caso, um loop pode ocorrer devido ao encaminhamento de um quadro com um endereço MAC unicast. Esse problema é chamado de "Instabilidade da tabela de endereços MAC". Ocorre quando há mais de duas conexões entre comutadores. Vou desenhar um diagrama no qual os interruptores A, B e C estão conectados entre si e um loop também pode se formar entre eles.
O comutador A possui três interfaces: f0 / 1, f0 / 2 ef0 / 3. Suponha que o usuário tenha um computador com o endereço MAC AAA e envie um quadro de transmissão para o comutador A. O comutador aceita esse quadro pela interface f0 / 1. Há outro usuário na rede cujo computador possui um endereço MAC BBB. Assim, temos o endereço de origem AAA e o endereço de destino BBB.
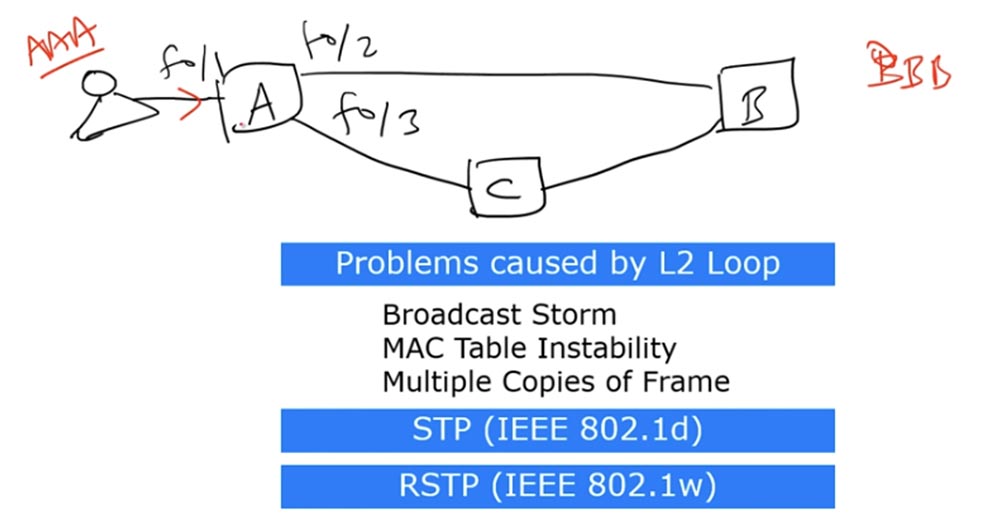
O switch A não sabe como chegar ao endereço MAC de destino do BBB, mas sabe que o endereço MAC de origem do AAA pode ser alcançado através da interface f0 / 1 e registra esse registro em sua tabela de endereços MAC. O switch A envia uma solicitação para o endereço de destino para as outras duas interfaces - f0 / 2 ef0 / 3.
Ao receber a solicitação AAA, o switch B vê que ele veio da fonte f0 / 2 e coloca em sua tabela de endereços MAC um registro de que o dispositivo AAA é acessível através da interface f0 / 2. Além disso, ele já tem uma entrada na qual a interface fB / 1 corresponde ao destino do BBB, então ele envia a solicitação ao destinatário.
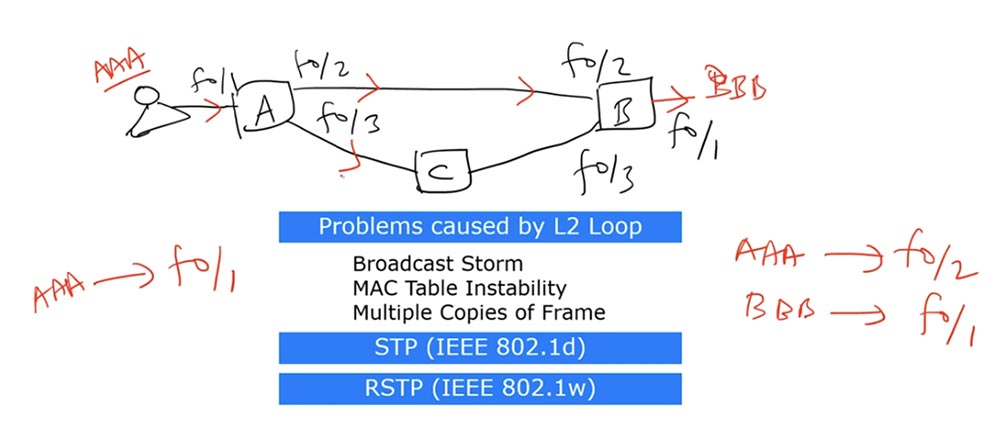
Como o switch A enviou um quadro de Broadcast, ele passou não apenas pela interface f0 / 2 para o switch B, mas também pela interface f0 / 3 para o switch C, que, por sua vez, o enviou à interface f0 / 3 do switch B.
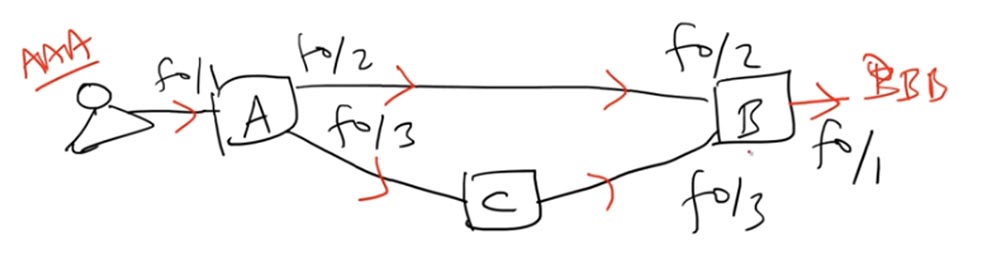
Depois de receber o quadro, o switch B pensa da seguinte maneira: “Eu sei que a fonte AAA estava anteriormente localizada na interface f0 / 2, mas agora o quadro veio até mim através da interface f0 / 3, então tenho que atualizar minha tabela de endereços MAC e substituir f0 / 2 em f0 / 3. "
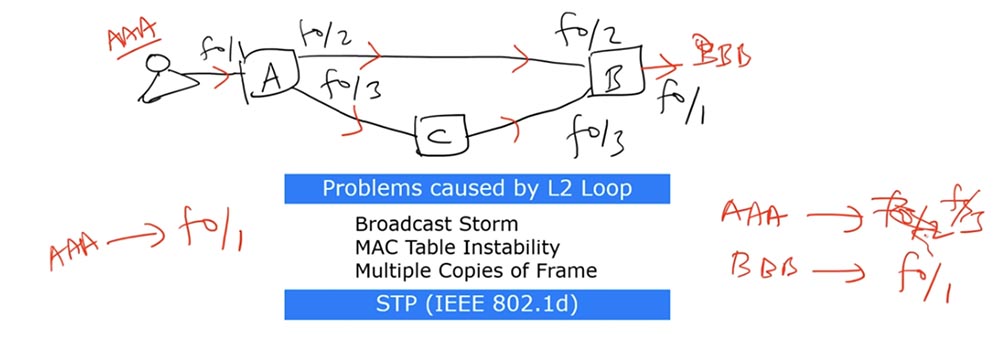
Então o quadro voltará ao comutador A e o “surpreenderá”: antes do comutador A pensava que a fonte AAA estava conectada pela interface f0 / 1, e agora acontece que a mensagem veio da interface f0 / 2. Na direção reversa do quadro através dos comutadores B e C, o comutador A receberá uma mensagem que o confundirá novamente - agora acontece que a fonte AAA está localizada na interface f0 / 3.
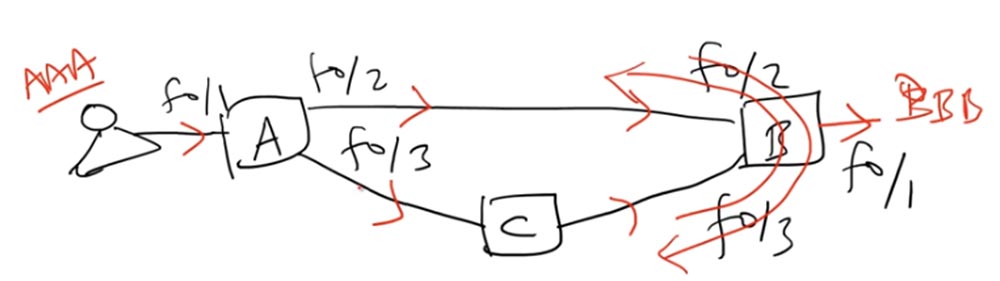
Assim, a tabela de endereços MAC desse comutador será atualizada constantemente entre essas três interfaces, ou seja, o problema acima mencionado da instabilidade da tabela de endereços MAC surgirá. Como no primeiro caso, um loop de quadro é formado aqui, levando a uma atualização da tabela a cada poucos segundos.
Há um terceiro problema de loop - várias cópias do quadro. O usuário AAA envia o quadro para o comutador A, depois o envia pela interface f0 / 2 para o comutador B, que o entrega ao destino BBB por meio da interface f0 / 1. Não há problemas.
Mas, ao mesmo tempo, o comutador A envia o mesmo quadro através de sua segunda interface f0 / 3 para o comutador C, que o encaminha para o comutador B. Ao receber o pacote ou o quadro do comutador C, o comutador B vê que ele é endereçado ao BBB e o envia ao destinatário. Assim, o usuário BBB recebe o mesmo pacote duas vezes. Aqui surge o problema - se essa é a distribuição dos dados executados pelo aplicativo, o mesmo quadro não deve chegar ao usuário duas vezes.
Esses são os três problemas que os loops de quadro podem causar. Todos eles são resolvidos de uma maneira, sobre a qual falamos anteriormente - usando o protocolo STP. Em um dos vídeos anteriores, não me lembro do número dele. Quando discutimos os modos de porta, esse protocolo já foi mencionado, o que serve para evitar loops de tráfego na rede.
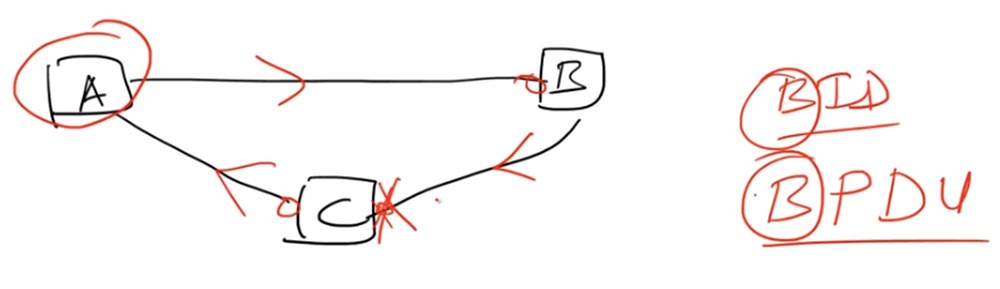
Portanto, um loop é formado quando três dispositivos são conectados um ao outro, formando um loop de rede fechado e pertencendo ao mesmo domínio de broadcast. Nesse caso, o algoritmo usado pelo protocolo STP designa um dos comutadores como o comutador raiz - Root Bridge. Vamos escolher a opção A como a opção raiz.

Cada porta conectada ao comutador raiz deve estar no estado de Encaminhamento, essas são as portas esquerdas dos comutadores C e B. Essas portas fornecem a transferência de pacotes ou quadros na direção do comutador raiz A. Na linha de conexão dos comutadores C e B, uma das portas deve ser no estado de bloqueio Blocking.
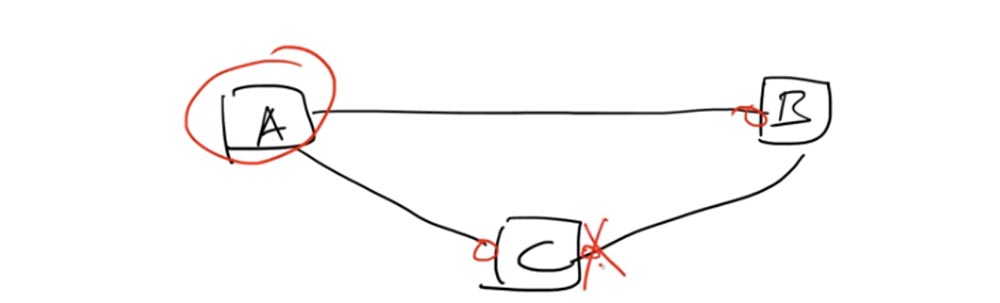
Isso significa que não está enviando tráfego. O comutador B pode continuar enviando tráfego para o comutador C, mas sua porta direita não manipula esse tráfego, embora continue fisicamente funcionando. Isso é feito usando o identificador de ponte ou o identificador de chave BID - ID da ponte.
Você deve se lembrar que o STP foi criado muito antes dos switches Ethernet aparecerem. Em seguida, em vez do termo switch, o termo bridge foi usado e muitos protocolos ainda usam a terminologia clássica dos padrões técnicos. Então agora o BID é o identificador do comutador.
As informações que o comutador raiz troca com outros comutadores são chamadas BPDU. Os dispositivos trocam mensagens BPDU a cada 2 segundos - desta vez é chamado de “hello timer”. A mensagem BPDU contém o BID do comutador raiz e o custo da rota para o comutador raiz, ou Custo do Caminho Raiz (essa é realmente a distância do comutador raiz). O custo do caminho em cada porta serve para calcular o caminho mais curto para o comutador raiz, mas não vamos nos aprofundar nesse conceito.
Logicamente, o esquema funciona assim: graças à porta direita bloqueada do comutador C, o tráfego indo na direção do comutador A - comutador B - comutador C não entra no comutador A, ou seja, não fecha no loop. C direciona o tráfego A, que o envia para B, o comutador B o direciona para C e, nesse ponto, o loop é interrompido.
Veja como o protocolo STP, que é o padrão IEEE 802.1d, funciona. Esse é um padrão muito antigo, cuja desvantagem é o tempo máximo para atualização de informações quando a comunicação é desconectada, igual a 50 segundos. Além do estado de bloqueio da porta de bloqueio, ele suporta mais 2 estados intermediários - Listening and Learning, após o qual alterna para o estado de transferência de encaminhamento.
A cada 2 segundos, os comutadores trocam uma mensagem de saudação - C a envia para B e A, A envia uma saudação para C e B e assim por diante. Se o dispositivo não receber essa mensagem, ele esperará por mais 10 vezes do temporizador hello, ou seja, 20 segundos. Depois disso, ele espera alguma ação, entrando no estado de escuta, que dura 15 segundos, depois entra no estado de aprendizado e permanece nele por mais 15 segundos. Assim, o período total de inatividade é de 50 s. Para redes modernas, esse é um período bastante longo.
Para melhorar essa situação, outro padrão foi introduzido - IEEE 802.1w, ou Rapid STP - o protocolo rápido STP, conhecido como RSTP. Ele é desprovido de estados intermediários e passa do estado de bloqueio para o estado de encaminhamento.
No STP, existem portas raiz Porta raiz - essas são as portas pelas quais a comunicação com o comutador raiz é realizada. No RSTP, é adicionado o conceito de portas alternativas que não estão relacionadas ao comutador raiz. No caso de uma desconexão entre a porta raiz do RP e o switch raiz, a porta ALT alternativa se transforma imediatamente na porta raiz do RP e a comunicação é realizada em uma rota diferente.
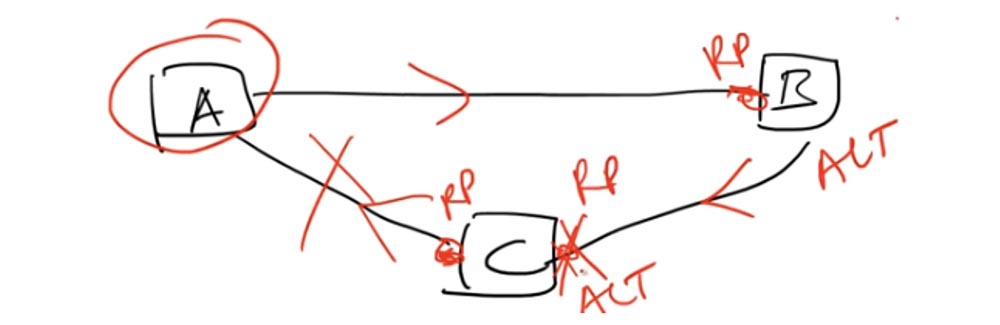
Com o curso mais difícil dos eventos, todo esse processo leva no máximo 10 segundos, e 10 segundos de inatividade são muito melhores que 50 segundos. Esta é a principal diferença entre STP e RSTP.
A Cisco agora usa o STP de várias maneiras, mas foi originalmente projetada para trabalhar no mesmo domínio de broadcast com uma VLAN nativa; portanto, o STP era visto como parte da VLAN1. Ao mesmo tempo, acreditava-se que todo o tráfego faz parte desse domínio de broadcast único. À medida que os dispositivos de rede evoluíram, a Cisco começou a usar o STP de outras maneiras, criando o PVSTP (Per-VLAN Spanning Tree), um protocolo proprietário projetado para funcionar com várias VLANs. Isso significava que cada VLAN teria seu próprio STP, isto é, seu próprio root root switch Root Bridge.

Da mesma maneira que a Cisco melhorou o STP criando o RSTP, desenvolveu a versão "acelerada" do PVSTP - RPVSTP. Ambos os protocolos foram encapsulados usando o protocolo ISL proprietário e não suportaram o padrão 802.1q, pois foram desenvolvidos antes de sua adoção. Para melhorar a interoperabilidade, a Cisco aprimorou esses protocolos adicionando suporte a 802.1q. Os novos protocolos que suportam ISL e 802.1q são chamados PVSTP + e RPVSTP +. Agora eles são padrões da indústria para redes Cisco.
O processo STP é caracterizado por uma métrica de custo de caminho em cada porta de custo de porta. Como base para esse indicador, foi utilizada a característica Velocidade da porta - a velocidade da porta em mb / s. Portanto, de acordo com o padrão IEEE 1998, a velocidade de 10 Mb / s correspondia ao custo da porta 100, a velocidade de 100 Mb / s - o custo de 19,1 Gb / s - o custo de 4 e 10 Gb / s - o custo de 2. Esse padrão não considerava a velocidade de 100 Gb / s e 1 Tb / s, portanto, em 2004, um novo IEEE foi desenvolvido, onde o indicador relativo do custo do porto varia de 2 a 20 milhões.

Quanto maior a velocidade, menor o custo; portanto, ao calcular rotas, são selecionadas as portas com menor custo. Se houver duas linhas - FastEthernet e GigabitEthernet, a última linha de comunicação terá um custo muito menor; portanto, ao escolher uma rota para o switch raiz, a porta GigabitEthern terá prioridade. O switch raiz em si tem custo de porta zero. No próximo vídeo, veremos o processo de escolha de uma rota, muito ficará claro para você. Por enquanto, lembre-se de qual é o princípio de preços.
O próximo tópico é o ID do remetente do ID do Bridge. No STP, ele contém 2 bytes de informações de prioridade do comutador e 6 bytes de endereço MAC.
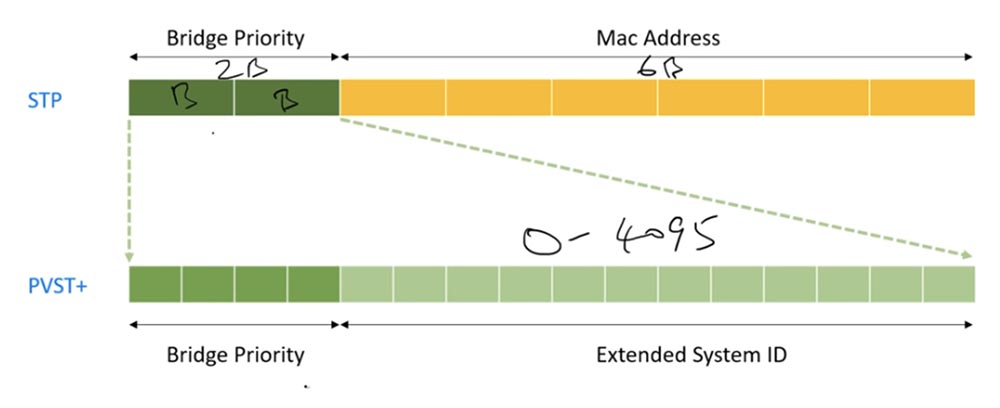
O PVSTP mais avançado consiste em 16 bits. Os primeiros 12 bits são chamados de Extended System ID ou identificador de sistema estendido. Ele contém o identificador da rede VLAN - o número da rede no intervalo de 0 a 4095 e o endereço MAC. Outros 4 bits são usados para indicar a prioridade da ponte ou switch. Se você se lembrar da nossa tabela binária mágica, verá que se todos os 4 bits forem 0, obteremos prioridade zero.
Se os bits estiverem na ordem 0001, isso significa que o número 4096 está abaixo de 1, ou seja, a prioridade será 4096. Dependendo das 16 combinações de bits, um desses números será usado como prioridade - de 0 a 61440 e cada subseqüente 4096 a mais que o anterior.
Por padrão, todos os comutadores Cisco têm prioridade 32768, mas você pode escolher qualquer um desses números como prioridade. Ao usar o ID do sistema estendido, um número de VLAN é adicionado a esse número, ou seja, se você tiver VLAN1, a prioridade do ID de ponte será 32768 + 1 = 32769.

Também temos um endereço MAC. Suponha que o ID da ponte de um dispositivo seja 32769: AAA: AAA: AAA e o outro seja 32769: BBB: BBB: BBB. Eles têm o mesmo valor de prioridade numérica, mas o dispositivo com o endereço MAC mais baixo terá uma vantagem, ou seja, AAA: AAA: AAA. Para entender melhor como o Bridge ID funciona, você pode revisar este vídeo novamente.
Não podemos alterar o endereço MAC do segundo dispositivo, mas podemos alterar o valor numérico de prioridade 32769. Se você deseja que este dispositivo tenha uma prioridade mais alta, pode alterar o valor de prioridade para 0 ou qualquer número menor que 32769. Se usarmos 0 e o número de rede VLAN1, obtemos o valor numérico da prioridade 1. Nesse caso, independentemente do valor do endereço MAC, este dispositivo terá uma prioridade mais alta que a primeira.
Se você deseja fazer o download deste vídeo em nosso site, pode usar o cupom com um desconto de 50%, válido até o final de 22 de novembro de 2017. Lembro que hoje examinamos um tópico muito importante, por isso recomendo que você assista a este tutorial em vídeo novamente.
Obrigado por ficar conosco. Você gosta dos nossos artigos? Deseja ver materiais mais interessantes? Ajude-nos fazendo um pedido ou recomendando a seus amigos, um
desconto de 30% para os usuários da Habr em um análogo exclusivo de servidores básicos que inventamos para você: Toda a verdade sobre o VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps de US $ 20 ou como dividir o servidor? (as opções estão disponíveis com RAID1 e RAID10, até 24 núcleos e até 40GB DDR4).
Dell R730xd 2 vezes mais barato? Somente temos
2 TVs Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV a partir de US $ 199 na Holanda! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - a partir de US $ 99! Leia sobre
Como criar um prédio de infraestrutura. classe usando servidores Dell R730xd E5-2650 v4 custando 9.000 euros por um centavo?