Hoje começaremos a estudar o roteamento OSPF. Este tópico, bem como a consideração do protocolo EIGRP, é o mais importante em todo o curso do CCNA. Como você pode ver, a Seção 2.4 é chamada de “Configurando, Verificando e Problemas com uma Zona Única e Multizone OSPFv2 para IPv4 (Exceto para Autenticação, Filtragem, Soma Manual de Rotas, Redistribuição, Área Sem Saída, Rede Virtual e LSA)”.

O tópico OSPF é bastante extenso, portanto, serão necessários 2, possivelmente 3 tutoriais em vídeo. A lição de hoje será dedicada ao lado teórico da questão. Vou lhe dizer o que é esse protocolo em termos gerais e como ele funciona. No próximo vídeo, mudaremos para o modo de configuração OSPF usando o Packet Tracer.
Portanto, nesta lição, examinaremos três coisas: o que é OSPF, como ele funciona e o que são zonas OSPF. Na lição anterior, dissemos que o OSPF é um protocolo de roteamento do tipo Link State que examina os canais de comunicação entre os roteadores e toma decisões com base na velocidade desses canais. Um canal longo com uma velocidade mais alta, ou seja, com uma largura de banda maior, será uma prioridade em comparação com um canal curto com uma largura de banda menor.
O protocolo RIP, sendo um vetor de distância, escolherá um caminho em um salto, mesmo se esse canal tiver uma velocidade baixa, e o OSPF escolherá uma rota longa com várias esperanças se a velocidade total nessa rota for maior que a velocidade do tráfego em uma rota curta.

Mais tarde, veremos o algoritmo de tomada de decisão, pois agora você deve se lembrar de que o OSPF é o protocolo de estado do link Link State. Esse padrão aberto foi criado em 1988, para que todo fabricante de equipamentos de rede e qualquer provedor de rede pudessem usá-lo. Portanto, o OSPF é muito mais popular que o EIGRP.
O OSPF versão 2 suporta apenas IPv4 e, um ano depois, em 1989, os desenvolvedores anunciaram o lançamento da versão 3, que suporta IPv6. No entanto, a terceira versão totalmente funcional do OSPF para IPv6 apareceu apenas em 2008. Por que você escolheu o OSPF? Na última lição, aprendemos que esse protocolo de gateway interno realiza convergência de rota muito mais rápido que o RIP. Este é um protocolo sem classe.
Se você se lembrar, o RIP é um protocolo de classe, ou seja, ele não envia informações sobre a máscara de sub-rede e, se encontrar um endereço IP da classe A / 24, não o aceitará. Por exemplo, se você apresentar um endereço IP no formato 10.1.1.0/24, ele o perceberá como uma rede 10.0.0.0, porque ele não entende quando uma rede é dividida em sub-redes usando mais de uma máscara de sub-rede.
OSPF é um protocolo seguro. Por exemplo, se dois roteadores trocarem informações OSPF, você poderá configurar a autenticação para poder compartilhar informações com um roteador vizinho somente depois de inserir a senha. Como dissemos, esse é um padrão aberto, e é por isso que o OSPF é usado por muitos fabricantes de equipamentos de rede.
Em um sentido global, o OSPF é o mecanismo de troca de anúncios do estado do link, LSA, estado publicitário. As mensagens LSA são geradas pelo roteador e contêm muitas informações: um identificador exclusivo para a identificação do roteador, dados em redes conhecidas pelo roteador, dados sobre seus custos e assim por diante. O roteador precisa de todas essas informações para tomar uma decisão sobre o roteamento.

O roteador R3 envia suas informações de LSA ao roteador R5, e o roteador R5 compartilha suas informações de LSA com o R3. Esses LSAs são uma estrutura de dados que forma um banco de dados Link State Data Base, ou LSDB, de estados de link. O roteador coleta todos os LSAs recebidos e os coloca em seu LSDB. Depois que os dois roteadores criam seus próprios bancos de dados, eles trocam mensagens Hello, que são usadas para descobrir vizinhos e iniciam o procedimento de comparação de seus LSDBs.
O roteador R3 envia uma mensagem DBD, ou "descrição do banco de dados", para R5, e R5 envia seu DBD para R3. Essas mensagens contêm os índices LSA encontrados nas bases de cada roteador. Depois de receber um DBD, o R3 envia uma solicitação de status da rede LSR para o R5, que diz: “Eu já tenho as mensagens 3.4 e 9, então envie-me apenas 5 e 7”.
O R5 faz exatamente o mesmo, dizendo ao terceiro roteador: "Eu tenho informações 3,4 e 9, então me envie 1 e 2". Ao receber solicitações de LSR, os roteadores enviam de volta os pacotes de atualização de status da rede LSU, ou seja, em resposta ao LSR, o terceiro roteador recebe a LSU do roteador R5. Depois que os roteadores atualizam seus bancos de dados, todos eles, mesmo se você tiver 100 roteadores, terão o mesmo LSDB. Assim que os bancos de dados LSDB forem criados nos roteadores, cada um deles conhecerá toda a rede como um todo. O protocolo OSPF usa o algoritmo Shortest Path First para criar uma tabela de roteamento; portanto, a condição mais importante para o seu correto funcionamento é a sincronização do LSDB de todos os dispositivos na rede.

O diagrama acima contém 9 roteadores, cada um dos quais troca mensagens LSR, LSU e assim por diante com os vizinhos. Todos eles são conectados entre si, como p2p, ou interfaces ponto a ponto que suportam o protocolo OSPF e interagem entre si para criar o mesmo LSDB.

Assim que os bancos de dados são sincronizados, cada roteador, usando o algoritmo de caminho mais curto, forma sua própria tabela de roteamento. Roteadores diferentes terão tabelas diferentes. Ou seja, todos os roteadores usam o mesmo LSDB, mas criam tabelas de roteamento com base em suas próprias considerações sobre as rotas mais curtas. Para usar esse algoritmo, o OSPF precisa de atualizações regulares no banco de dados LSDB.
Portanto, para seu próprio funcionamento, o OSPF deve primeiro fornecer três condições: encontre vizinhos, crie e atualize o LSDB e crie uma tabela de roteamento. Para cumprir a primeira condição, o administrador da rede pode precisar configurar manualmente a ID do roteador, horários ou máscara curinga. No próximo vídeo, consideraremos como configurar o dispositivo para funcionar com OSPF, até agora você deve saber que este protocolo usa uma máscara reversa e, se não corresponder, se suas sub-redes não corresponderem ou se a autenticação não corresponder, a vizinhança dos roteadores não será formada. Portanto, ao solucionar problemas do OSPF, você deve descobrir por que essa vizinhança não se forma, ou seja, verifique se os parâmetros acima correspondem.
Como administrador de rede, você não está envolvido no processo de criação de um LSDB. Os bancos de dados são atualizados automaticamente após a criação de uma vizinhança de roteadores e a criação de tabelas de roteamento. Tudo isso é feito pelo próprio dispositivo, configurado para funcionar com o protocolo OSPF.
Vejamos um exemplo. Temos dois roteadores, para os quais atribuímos identificadores RID 1.1.1.1 e 2.2.2.2 por simplicidade. Assim que os conectarmos, o canal de link entrará imediatamente no estado ativo, porque primeiro configurei esses roteadores para funcionarem com o OSPF. Assim que o canal de comunicação for formado, o roteador A enviará imediatamente o segundo pacote Hello. Este pacote conterá informações que este roteador não "viu" ninguém neste canal, porque envia o Hello pela primeira vez, bem como seu próprio identificador, dados sobre a rede conectada a ele e outras informações que podem ser compartilhadas com um vizinho.

Depois de receber esse pacote, o roteador B dirá: “Vejo que neste canal de comunicação há um candidato em potencial para a vizinhança OSPF” e passará para o estado inicial Init state. O pacote Hello não é uma mensagem de difusão ponto a ponto ou de difusão, é um pacote multicast enviado para o endereço IP de multicast OSPF 224.0.0.5. Algumas pessoas perguntam o que é uma máscara de sub-rede para um multicast. O fato é que um multicast não possui uma máscara de sub-rede, é distribuído como um sinal de rádio que é ouvido por todos os dispositivos sintonizados em sua frequência. Por exemplo, se você deseja ouvir uma transmissão de rádio FM na frequência 91.0, sintonize o rádio nessa frequência.
Da mesma maneira, o roteador B está configurado para receber mensagens para o endereço multicast 224.0.0.5. Ao ouvir esse canal, ele recebe o pacote Hello enviado pelo roteador A e responde com sua mensagem.

Além disso, a vizinhança pode ser estabelecida apenas se a resposta B satisfizer um conjunto de critérios. O primeiro critério - a frequência do envio de mensagens Hello e o intervalo de espera por uma resposta a essa mensagem Dead Interval devem coincidir para os dois roteadores. O intervalo normalmente inoperante é igual a vários valores do temporizador Hello. Assim, se o Hello Timer do roteador A for 10 s e o roteador B enviar uma mensagem após 30 s com intervalo morto igual a 20 s, a vizinhança não ocorrerá.
O segundo critério é que os dois roteadores devem usar o mesmo tipo de autenticação. Portanto, as senhas de autenticação também devem corresponder.
O terceiro critério é a coincidência dos identificadores da zona Arial ID, o quarto é a coincidência do comprimento do prefixo da rede. Se o roteador A relatar o prefixo / 24, o roteador B também deverá ter um prefixo de rede / 24. No próximo vídeo, consideraremos isso com mais detalhes. Por agora, notarei que essa não é uma máscara de sub-rede, aqui os roteadores usam a máscara curinga reversa. E, é claro, os sinalizadores da zona de stub da área de stub também devem corresponder se os roteadores estiverem nessa zona.
Depois de verificar esses critérios, se eles corresponderem, o roteador B envia seu pacote Hello para o roteador A. Diferentemente da mensagem A, o roteador B relata que viu o roteador A e se apresenta.

Em resposta a esta mensagem, o roteador A envia novamente Hello para o roteador B, no qual confirma que também viu o roteador B, o canal de comunicação entre eles consiste nos dispositivos 1.1.1.1 e 2.2.2.2, e ele próprio é o dispositivo 1.1.1.1. Esta é uma etapa muito importante para estabelecer um bairro. Nesse caso, é usada uma conexão bidirecional bidirecional, mas o que acontece se tivermos um switch com uma rede distribuída de 4 roteadores? Nesse ambiente "compartilhado", um dos roteadores deve desempenhar o papel de um roteador dedicado DR designado de roteador e o segundo - um roteador dedicado de backup Roteador designado de backup, BDR

Cada um desses dispositivos formará uma conexão completa, ou um estado de adjacência total; posteriormente, consideraremos o que é, no entanto, uma conexão desse tipo será estabelecida apenas com DR e BDR, os dois roteadores inferiores D e B ainda se comunicarão de acordo com o esquema de conexão bidirecional Ponto a ponto.
Ou seja, com DR e BDR, todos os roteadores estabelecem um relacionamento completo de proximidade e conexão ponto a ponto entre si. Isso é muito importante, porque, ao conectar os dispositivos adjacentes de maneira bidirecional, todos os parâmetros do pacote Hello devem corresponder. No nosso caso, tudo coincide, então os dispositivos formam um bairro sem problemas.
Assim que a comunicação bidirecional é estabelecida, o roteador A envia ao roteador B o pacote Descrição do banco de dados, ou a “descrição do banco de dados”, e alterna para o estado ExStart - o início da troca ou aguardando o download. O Descritor do Banco de Dados é uma informação semelhante ao índice do livro - é uma enumeração de tudo o que está disponível no banco de dados de roteamento. Em resposta, o roteador B envia sua descrição do banco de dados ao roteador A e entra no estado de troca de dados nos canais do Exchange. Se, no estado Exchange, o roteador detectar que há alguma informação em seu banco de dados, ele entrará no estado de inicialização LOADING e começará a trocar mensagens LSR, LSU e LSA com o vizinho.

Portanto, o roteador A envia um LSR para um vizinho, ele responde com um pacote LSU, ao qual o roteador A responde ao roteador B com uma mensagem LSA. Essa troca ocorrerá tantas vezes quanto o número de vezes que o dispositivo desejar trocar mensagens LSA. Um estado LOADING significa que uma atualização completa do banco de dados LSA ainda não ocorreu. Após o download de todos os dados, os dois dispositivos entrarão no estado de adjacência COMPLETO.
Observo que, com uma conexão bidirecional, o dispositivo está simplesmente no estado de proximidade, e o estado de adjacência total é possível apenas entre roteadores, DR e BDR.Isso significa que cada roteador informa o DR sobre alterações na rede e todos os roteadores aprendem sobre essas alterações no DR
A escolha de DR e BDR é uma questão importante. Considere como a seleção de DR em um ambiente comum. Suponha que em nosso circuito haja três roteadores e um switch. Primeiro, os dispositivos OSPF comparam a prioridade nas mensagens Hello e, em seguida, o ID do roteador.
O dispositivo com a prioridade mais alta se torna DR. Se as prioridades dos dois dispositivos corresponderem, então, dos dois dispositivos, o dispositivo com o ID do roteador mais alto será selecionado, que se tornará DR
Um dispositivo com a segunda maior prioridade ou o segundo mais importante ID do roteador se torna o roteador BDR de backup dedicado.Se o DR falhar, ele será substituído imediatamente pelo BDR.Ele começará a desempenhar o papel de DR e o sistema escolherá outro BDR.

Espero que você tenha descoberto a escolha de DR e BDR, caso contrário, voltarei a esta questão em um dos vídeos a seguir e explicarei esse processo.
Então, vimos o que é Hello, uma descrição do descritor de banco de dados e as mensagens LSR, LSU e LSA. Antes de passar para o próximo tópico, vamos falar um pouco sobre o custo do OSPF.

Na Cisco, o custo de uma rota é calculado usando a fórmula da proporção da largura de banda Largura de banda de referência, que por padrão é definida como 100 Mbps, para o custo do canal. Por exemplo, ao conectar dispositivos através de uma porta serial, a velocidade é de 1,544 Mb / s e o custo é 64. Ao usar uma conexão Ethernet com uma velocidade de 10 Mb / s, o custo é 10 e o custo de uma conexão FastEthernet com uma velocidade de 100 Mb / s será 1.
Ao usar a Gigabit Ethernet, temos uma velocidade de 1000 Mbps, mas, neste caso, a velocidade é sempre assumida como 1. Portanto, se você tiver Gigabit Ethernet na sua rede, deverá alterar o valor padrão Ref. BW por 1000. Nesse caso, o custo será 1 e a tabela inteira será recalculada com um aumento no valor de 10 vezes. Depois de formarmos a vizinhança e construirmos o banco de dados LSDB, prosseguimos para a construção da tabela de roteamento.

Após receber o LSDB, cada um dos roteadores continua independentemente para formar uma lista de rotas usando o algoritmo SPF. Em nosso esquema, o roteador A criará uma tabela para si mesmo. Por exemplo, ele calcula o custo da rota A-R1 e determina igual a 10. Para simplificar o entendimento do esquema, suponha que o roteador A determine a rota ideal para o roteador B. O custo da conexão A-R1 é 10, a conexão A-R2 é 100 e o custo da rota A-R3 é 11, isto é, a soma da rota A-R1 (10) e R1-R3 (1).
Se o roteador A quiser acessar o roteador R4, ele poderá fazer isso na rota A-R1-R4 ou na rota A-R2-R4 e, em ambos os casos, o custo das rotas será o mesmo: 10 + 100 = 100 + 10 = 110. A rota A-R6 custará 100 + 1 = 101, o que já é melhor. A seguir, consideramos o caminho para o roteador R5 ao longo da rota A-R1-R3-R5, cujo custo será 10 + 1 + 100 = 111.
O caminho para o roteador R7 pode ser estabelecido ao longo de duas rotas: A-R1-R4-R7 ou A-R2-R6-R7. O custo do primeiro será 210, o segundo - 201, então você deve escolher 201. Portanto, para acessar o roteador B, o roteador A pode usar 4 rotas.

O custo da rota A-R1-R3-R5-B será 121. A rota A-R1-R4-R7-B custará 220. A rota A-R2-R4-R7-B custa 210 e A-R2-R6-R7- B tem um custo de 211. Com base nisso, o roteador A seleciona a rota com o menor custo igual a 121 e a coloca na tabela de roteamento. Este é um diagrama muito simplificado de como o algoritmo SPF funciona. De fato, a tabela não contém apenas as designações dos roteadores pelos quais a rota ideal é executada, mas também as designações das portas que os conectam e todas as outras informações necessárias.
Considere outro tópico que diz respeito às zonas de roteamento. Geralmente, ao configurar dispositivos OSPF de uma empresa, eles estão todos em uma zona comum.

O que acontece se um dispositivo conectado ao roteador R3 falhar repentinamente? O roteador R3 começará imediatamente a enviar uma mensagem para os roteadores R5 e R1 de que o canal com este dispositivo não está mais funcionando e todos os roteadores começarão a trocar atualizações sobre esse evento.
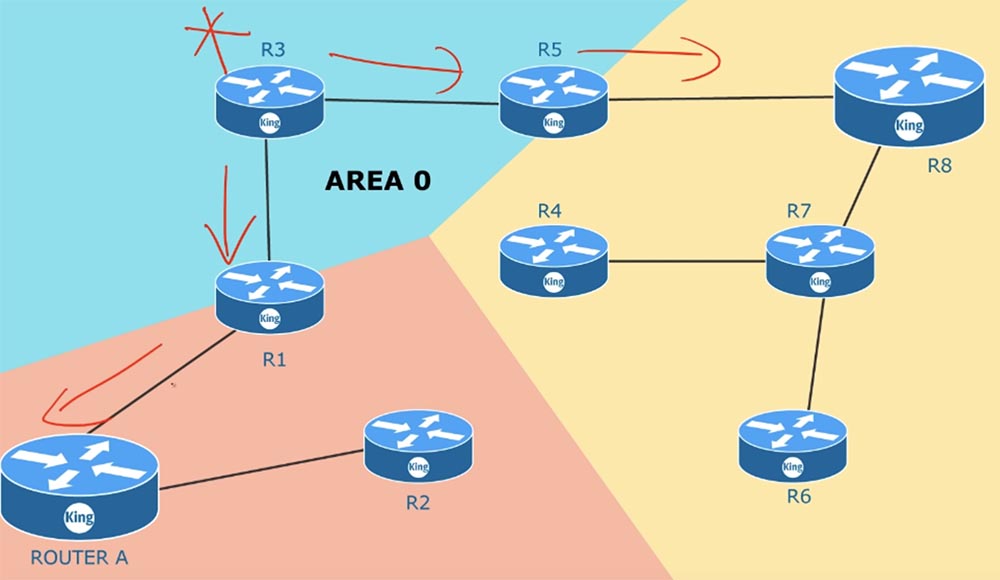
Se você tiver 100 roteadores, todos eles atualizarão as informações sobre o status dos canais, porque estão na mesma zona comum. O mesmo acontecerá se um dos roteadores vizinhos falhar - todos os dispositivos na zona trocarão atualizações do LSA. Depois de trocar essas mensagens, a própria topologia de rede será alterada. Quando isso acontece, o SPF recalcula as tabelas de roteamento de acordo com as condições alteradas. Este é um processo muito demorado, e se você tiver mil dispositivos em uma zona, precisará controlar o tamanho da memória dos roteadores para que seja suficiente armazenar todos os LSAs e um enorme banco de dados do status do canal LSDB. Assim que as alterações ocorrem em uma parte da zona, o algoritmo SPF recalcula imediatamente as rotas. Por padrão, o LSA é atualizado a cada 30 minutos. Esse processo não ocorre simultaneamente em todos os dispositivos; no entanto, em qualquer caso, as atualizações são realizadas por cada roteador com uma frequência de 30 minutos. Mais dispositivos de rede. Quanto mais memória e tempo são necessários para atualizar o LSDB.
Você pode resolver esse problema se dividir uma zona comum em várias zonas separadas, ou seja, use o multi-zoneamento. Para fazer isso, você deve ter um plano ou diagrama de toda a rede que você gerencia. Zona zero A ÁREA 0 é sua zona principal. É o local em que você se conecta a uma rede externa, por exemplo, acesso à Internet. Ao criar novas zonas, você deve ser guiado pela regra: cada zona deve ter um ABR, roteador de borda de área. O roteador de borda tem uma interface em uma zona e uma segunda interface em outra zona. Por exemplo, o roteador R5 possui interfaces na zona 1 e na zona 0. Como eu disse, cada uma das zonas deve estar conectada à zona zero, ou seja, ter um roteador de borda, uma das interfaces conectadas à ÁREA 0.
 Suponha que a conexão R6-R7 esteja com defeito. Nesse caso, a atualização do LSA será distribuída apenas na zona da ÁREA 1 e se referirá apenas a esta zona. Os dispositivos na zona 2 e na zona 0 nem saberão disso. O roteador de borda R5 resume informações sobre o que está acontecendo em sua zona e envia para a zona principal AREA 0 a informação total sobre o estado da rede. Os dispositivos em uma zona não precisam estar cientes de todas as alterações do LSA em outras zonas, porque o roteador ABR encaminhará informações resumidas sobre rotas de uma zona para outra.Se você não estiver totalmente claro sobre o conceito de zonas, poderá descobrir mais na próxima lição quando vamos configurar o roteamento OSPF e considerar alguns exemplos.
Suponha que a conexão R6-R7 esteja com defeito. Nesse caso, a atualização do LSA será distribuída apenas na zona da ÁREA 1 e se referirá apenas a esta zona. Os dispositivos na zona 2 e na zona 0 nem saberão disso. O roteador de borda R5 resume informações sobre o que está acontecendo em sua zona e envia para a zona principal AREA 0 a informação total sobre o estado da rede. Os dispositivos em uma zona não precisam estar cientes de todas as alterações do LSA em outras zonas, porque o roteador ABR encaminhará informações resumidas sobre rotas de uma zona para outra.Se você não estiver totalmente claro sobre o conceito de zonas, poderá descobrir mais na próxima lição quando vamos configurar o roteamento OSPF e considerar alguns exemplos.Obrigado por ficar conosco. Você gosta dos nossos artigos? Deseja ver materiais mais interessantes? Ajude-nos fazendo um pedido ou recomendando a seus amigos, um
desconto de 30% para os usuários da Habr em um análogo exclusivo de servidores básicos que inventamos para você: Toda a verdade sobre o VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps de US $ 20 ou como dividir o servidor? (as opções estão disponíveis com RAID1 e RAID10, até 24 núcleos e até 40GB DDR4).
Dell R730xd 2 vezes mais barato? Somente temos
2 TVs Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV a partir de US $ 199 na Holanda! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - a partir de US $ 99! Leia sobre
Como criar um prédio de infraestrutura. classe usando servidores Dell R730xd E5-2650 v4 custando 9.000 euros por um centavo?