Por que queremos escrever código competitivo? Porque os processadores pararam de crescer ao longo dos mergulhos e começaram a crescer ao longo dos núcleos. O número de núcleos de processador está aumentando a cada ano, e queremos utilizá-los efetivamente. Go é o idioma criado para isso. A documentação diz isso.
Tomamos Go, começamos a escrever código competitivo. Obviamente, esperamos que possamos reduzir facilmente o poder de cada núcleo do nosso processador. É isso mesmo?
Meu nome é Artemy. Este post é uma transcrição gratuita da minha conversa com a GopherCon Russia. Pareceu uma tentativa de dar impulso às pessoas que desejam descobrir como escrever um código bom e competitivo.
Vídeo da conferência GopherCon na Rússia
Modelos de interação
Para entender se o Go realmente torna mais fácil para nós, vejamos dois modelos de interação: Memória Compartilhada e Passagem de Mensagens .

Memória compartilhada refere-se à memória compartilhada que vários threads usam para trocar dados. O acesso à memória precisa ser sincronizado. Essa sincronização geralmente é implementada por algum tipo de bloqueio. Essa abordagem é considerada comunicação implícita.
O Message Passing diz que interagiremos explicitamente e, para isso, usaremos os canais nos quais enviaremos mensagens. O CSP ( Communicating Sequential Processes ) e o Modelo do ator são baseados nessa abordagem.

Rob Pike , que é o pai fundador da Go, diz que você precisa abandonar a programação de baixo nível usando a Memória Compartilhada e usar a abordagem Message Passing . Essa abordagem ajudará você a escrever código de maneira mais fácil, mais eficiente e, mais importante, com menos bugs. Go escolhe a abordagem CSP . A mesma abordagem influenciou bastante o desenvolvimento de uma linguagem como Erlang.
Pergunta: É verdade que se pegarmos o Go, tudo ficará bem?

Me deparei com um estudo em que este tablet foi encontrado. O tablet mostra os motivos e o número de erros relacionados aos bloqueios. A primeira coluna mostra os produtos que foram levados para o estudo. Estes são os produtos mais populares escritos em Go. A coluna Memória compartilhada mostra o número de bugs que ocorrem devido ao uso inadequado da Memória compartilhada, e a coluna Passagem de mensagem, respectivamente, mostra o número de bugs devido à Passagem de mensagens.
A coisa mais importante nesta placa é a linha Total . Se você observar, notará que há mais erros ao usar o Message Passing do que ao usar a Memória Compartilhada . Estou certo de que as pessoas que escrevem Kubernetes, Docker ou etcd são desenvolvedores bastante experientes, mas mesmo o Message Passing deles não salva dos erros, e esses erros não são menores do que na Memória Compartilhada.
Então, basta pegar o Go e começar a escrever um código sem erros falhará.
Concorrência e paralelismo
Quando começamos a falar sobre desenvolvimento multithread, precisamos introduzir conceitos como Concorrência e Paralelismo . No mundo de Go, há a expressão "simultaneidade não é paralelismo" . O ponto principal é que a simultaneidade é sobre design, ou seja, como projetamos nosso programa. Paralelismo é apenas uma maneira de executar nosso código.

Se tivermos vários encadeamentos de instruções executados simultaneamente, executamos o código em paralelo. Paralelismo requer competição. Não será possível paralelizar um programa sem um design competitivo, enquanto a competitividade não exige paralelismo, porque um programa que pode ser executado em muitos núcleos, de fato, pode ser executado em um único núcleo.
Go é uma linguagem que nos ajuda a escrever programas competitivos, nos ajuda a criar design. Ele permite que você pense um pouco menos sobre coisas de baixo nível.
Lei de Amdahl
Queremos utilizar os núcleos do processador, escrevemos algum código para isso. Mas surge a pergunta: que tipo de aumento de produtividade obtemos com um aumento no número de núcleos. Portanto, a aceleração que podemos obter é, de fato, limitada pela lei de Amdal .
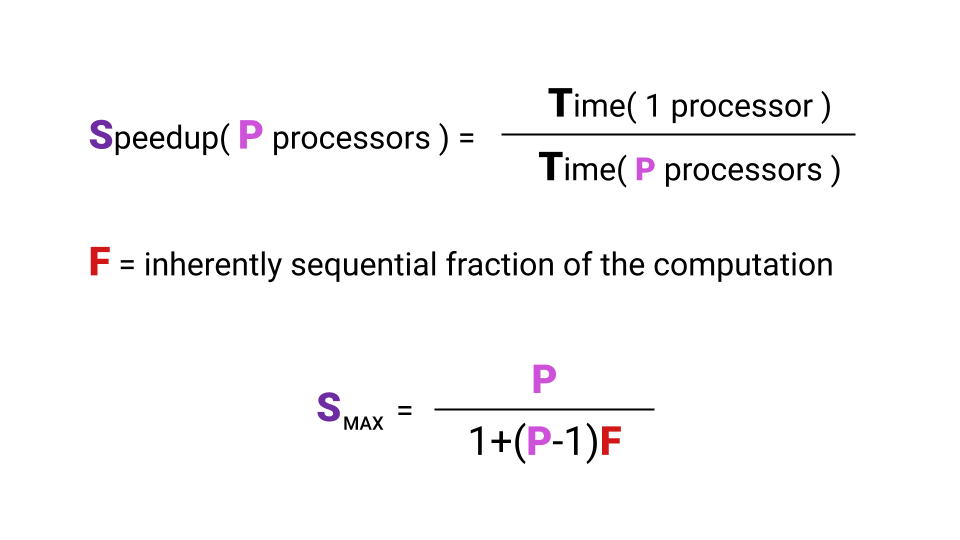
O que é aceleração? Aceleração é o tempo em que um programa é executado em um único processador dividido pelo tempo em que um programa é executado em processadores P. A letra F ( Fração ) indica a parte do programa que deve ser executada sequencialmente. E aqui nem é necessário nos aprofundarmos na fórmula, o principal é notar que a aceleração máxima que obtemos com um aumento no número de núcleos depende fortemente de F. Dê uma olhada no gráfico para visualizar esse relacionamento.
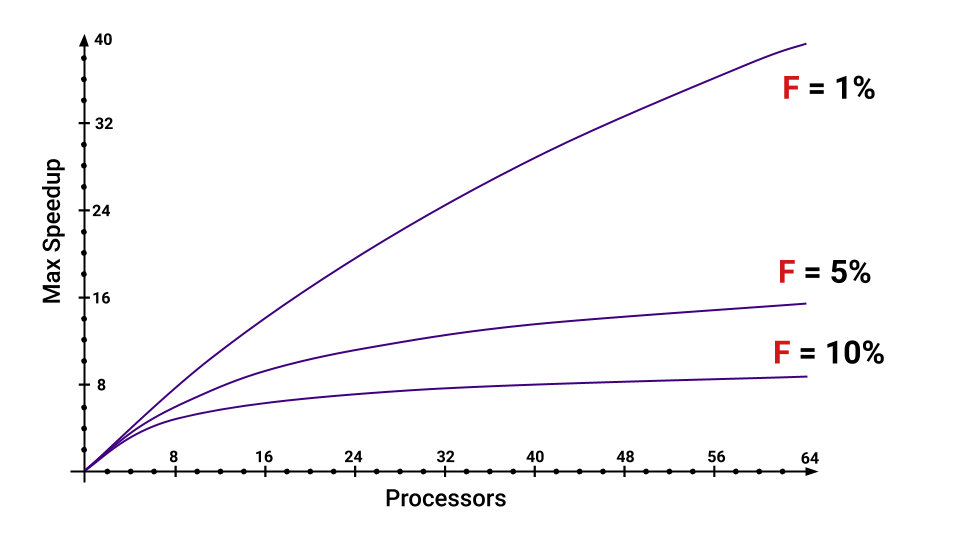
Mesmo que tenhamos apenas 5% do programa a ser executado seqüencialmente, a aceleração máxima que obtivermos diminuirá muito com o aumento do número de núcleos. Você pode estimar quais são as partes que aumentam F.
Limite de CPU vs Limite de E / S
Nem sempre faz sentido usar multithreading. Primeiro, você precisa examinar o tipo de carga. Existem dois tipos de carga: limite da CPU e limite de E / S. A diferença é que, com o limite da CPU, somos limitados pelo desempenho do processador, e com o limite de E / S, a velocidade do nosso subsistema de E / S. Nem velocidade, mas tempo de espera por uma resposta. Ficar online - aguardando uma resposta, indo para o disco - novamente esperando por uma resposta. Qual é a diferença, quantos núcleos existem, se na maioria das vezes estamos esperando por uma resposta?
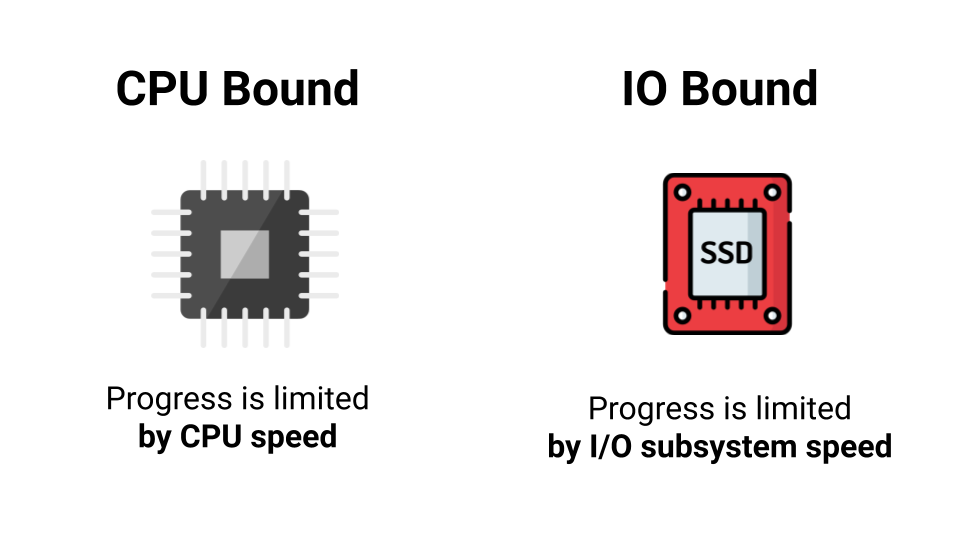
Portanto, um núcleo ou mil, não obteremos um aumento no desempenho com a carga limitada de E / S. Mas se tivermos uma carga limitada pela CPU, haverá uma chance de acelerar ao paralelizar nosso programa.
Embora existam situações em que a carga limite da CPU aparente, ela realmente se degenera em um limite de E / S. Se, por exemplo, queremos pegar e somar todos os elementos de uma grande matriz, o que faremos? Vamos escrever um ciclo, tudo vai funcionar. Então pensamos: “Então, temos vários núcleos. Vamos pegar, dividir a matriz em pedaços e paralelizar a coisa toda. ” Qual será o resultado?
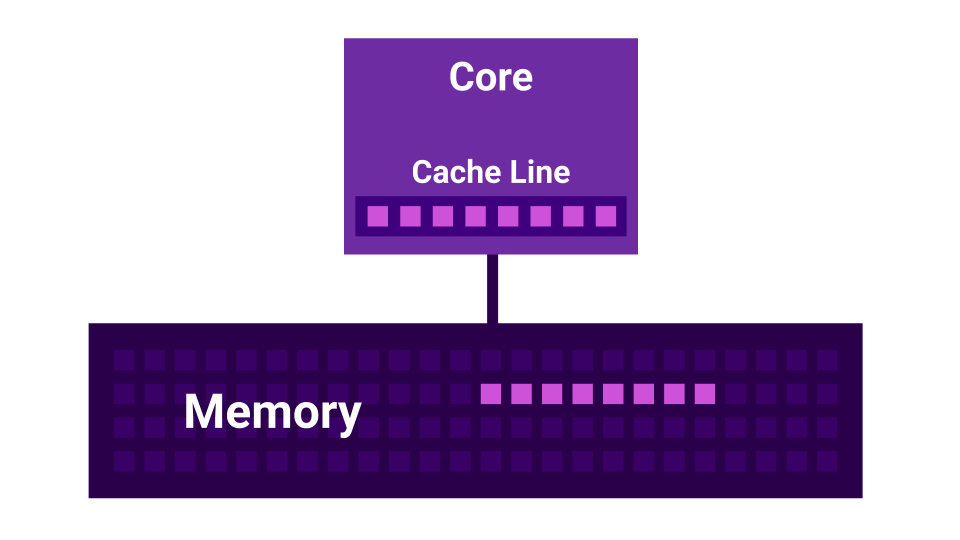
O resultado é uma situação em que nosso processador processa dados mais rapidamente do que eles conseguem obter da memória. Nesse caso, na maioria das vezes, esperaremos os dados da memória e a carga, que parecia estar vinculada à CPU, na verdade acaba sendo E / S vinculada.
Compartilhamento falso
Além disso, há uma história como o compartilhamento falso . Compartilhamento falso é uma situação em que os kernels começam a interferir entre si. Existe um primeiro núcleo, existe um segundo núcleo e cada um deles tem seu próprio cache L1 . O cache L1 é dividido em linhas ( linha de cache ) de 64 bytes. Quando obtemos alguns dados da memória, sempre obtemos nada menos que 64 bytes. Ao alterar esses dados, desabilitamos os caches de todos os núcleos.

Acontece que, se dois núcleos alteram dados muito próximos um do outro ( a uma distância inferior a 64 bytes ), eles começam a interferir entre si, invalidando caches. Nesse caso, se o programa fosse gravado seqüencialmente, ele funcionaria mais rápido do que ao usar vários núcleos que interferem um no outro. Quanto mais núcleos, menor o desempenho.
Agendadores
Subiremos para o próximo nível de abstração - para os planejadores.
Quando o trabalho começa com um código competitivo, os agendadores aparecem. O Go possui o chamado agendador de espaço do usuário que opera em goroutines . O sistema operacional também possui seu próprio agendador , que opera com threads do sistema operacional . E mesmo o processador não é tão simples. Por exemplo, os processadores modernos têm previsão de ramificação e outras maneiras de estragar nossa bela imagem da linearizabilidade do mundo.
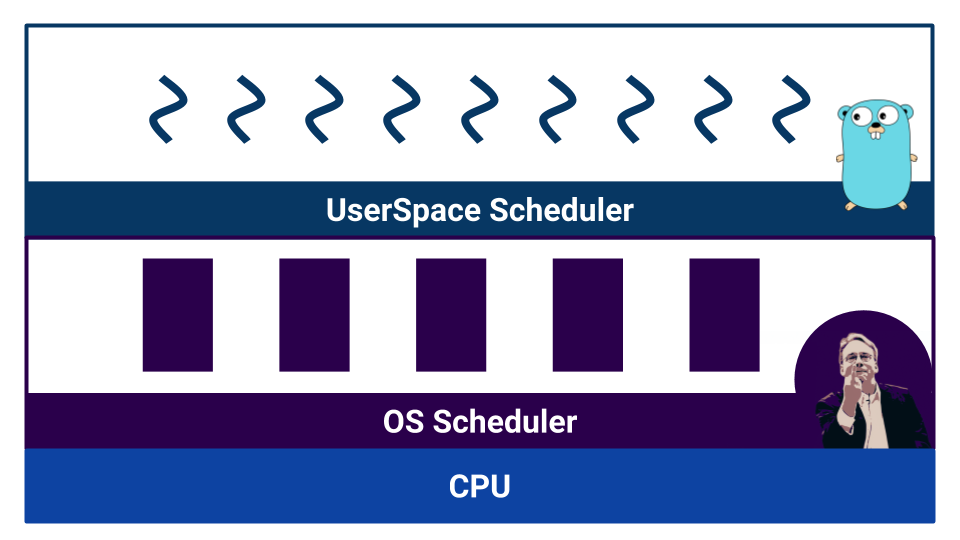
Os agendadores são divididos por tipo de multitarefa. Há multitarefa cooperativa e multitarefa preventiva . No caso de multitarefa cooperativa , o próprio processo de execução decide quando precisa transferir o controle para outro processo e, no caso de multitarefa lotada, existe um componente externo - agendador, que controla a quantidade de recursos alocados ao processo.

A multitarefa cooperativa permite que um processo "monopolize" todo o recurso da CPU. Na multitarefa preemptiva, isso não acontecerá, porque existe um corpo controlador. Porém, com a multitarefa cooperativa, a alternância de contexto é mais eficiente, porque o processo sabe ao certo em que momento é melhor dar controle a outro processo. Na multitarefa preemptiva, o agendador pode interromper o processo a qualquer momento - não é muito eficiente. Ao mesmo tempo, na multitarefa preventiva, podemos fornecer o mesmo recurso para cada processo, graças a um agendador externo.
O sistema operacional usa um agendador baseado na multitarefa preventiva, pois o sistema operacional é necessário para garantir condições iguais para cada usuário. E o Go?
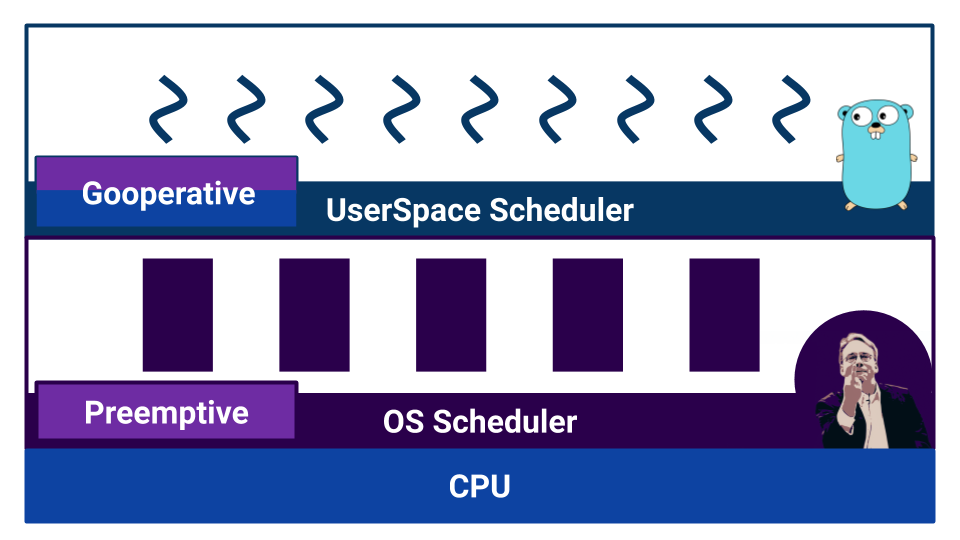
Se lermos a documentação, aprenderemos que o agendador no Go é preventivo. Mas, quando começamos a entender, o Go não possui um agendador como componente externo. No Go, o compilador define pontos de alternância de contexto. E embora nós, como desenvolvedores, não precisemos alternar manualmente o contexto, o controle da alternância não é levado para o componente externo. Graças a isso, o Go é muito eficaz na troca de uma goroutina para outra. Mas um mal-entendido sobre as características do trabalho de um "planejador" pode levar a um comportamento inesperado. Por exemplo, qual será o resultado desse código?

Esse código irá congelar.
Porque Porque, a princípio, usando o GOMAXPROCS , GOMAXPROCS o programa a usar apenas um núcleo. Depois disso, a goroutine foi colocada na fila, dentro da qual um ciclo interminável deveria funcionar. Depois esperamos 500 ms e imprimimos x . Após o time.Sleep goroutine será realmente iniciada, mas não haverá saída do loop infinito, porque o compilador não colocará o ponto de alternância de contexto. O programa congela.
E se adicionarmos runtime.Gosched() dentro do loop, tudo ficará bem, porque indicaremos explicitamente que queremos mudar o contexto.
Esses recursos também precisam saber e lembrar.
Falamos sobre troca de contexto, mas onde o Go geralmente insere pontos de troca?

runtime.morestack() e runtime.newstack() geralmente são inseridos no momento em que a função é chamada. runtime.Goshed() nós podemos fornecer a nós mesmos. E, é claro, a alternância de contexto ocorre durante bloqueios, aumentos de rede e chamadas do sistema. Você pode olhar para este relatório de tópico de Kirill Lashkevich . Muito bom, eu aconselho.
Vamos mais perto do código. Vamos olhar para os erros.
Condição de corrida
Um dos erros mais populares que cometemos é a Race Condition . A conclusão é que, quando realizamos, por exemplo, um incremento, na verdade não realizamos uma operação, mas várias: o processador lê dados da memória para registrar, atualiza o registro e grava dados na memória.

Essas três operações não são executadas atomicamente. Portanto, o planejador a qualquer momento, em qualquer uma dessas operações, pode absorver e dispersar nosso fluxo. Acontece que a ação não está concluída e, por causa disso, detectamos bugs.
Aqui está um exemplo desse código (o incremento é imediatamente decomposto em várias operações ).

O planejador pode antecipar o primeiro encadeamento após a execução da primeira linha e o segundo encadeamento após verificar a condição. Nesse caso, os dois fluxos caem na seção crítica e, portanto, é "crítico" - os dois fluxos não podem ser inseridos lá simultaneamente.
Podemos bloquear usando sync.Mutex do pacote de sync padrão. O bloqueio de acesso nos permite indicar explicitamente que o código deve ser executado por um thread por vez. Com esse código, obtemos o que precisamos.

Os bloqueios são uma operação bastante cara. Portanto, existem operações atômicas no nível do processador. Nesse caso, o incremento pode ser feito atômico, substituindo-o atomic.AddInt64 operação atomic.AddInt64 do pacote atomic .
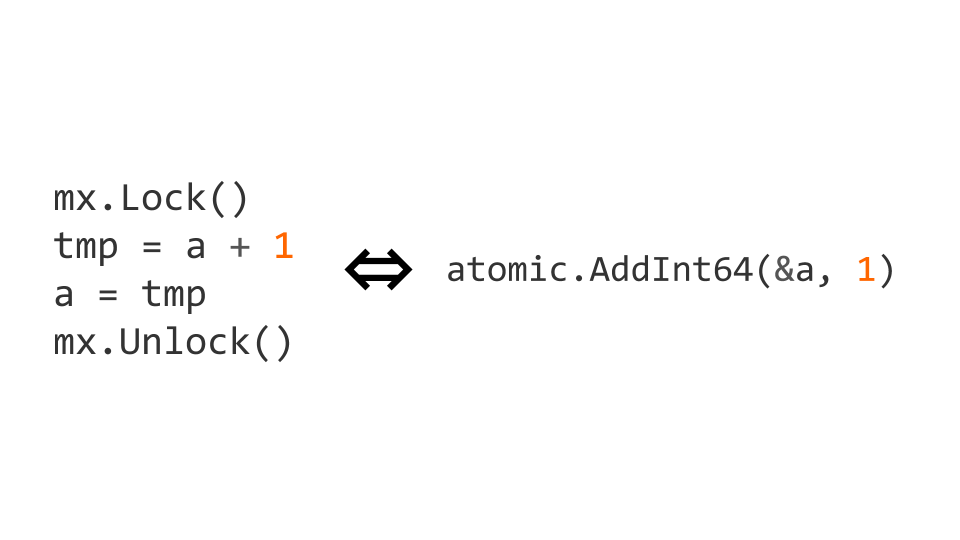
Se começarmos a trabalhar com instruções atômicas, precisamos não apenas escrever atomicamente, mas também ler atomicamente. Se não o fizermos, poderão surgir problemas.
Otimização - O que poderia dar errado?
Fechaduras são boas, mas podem ser caras. Atômicos são baratos o suficiente para não se preocupar com o desempenho.
Assim, aprendemos que as primitivas de sincronização introduzem sobrecarga e decidimos adicionar otimização - verificaremos o sinalizador sem considerar o multithreading e depois verificaremos novamente usando as primitivas de sincronização. Tudo parece bem e deve funcionar.

Está tudo bem, exceto que o compilador está tentando otimizar nosso código. O que ele esta fazendo? Ele troca as instruções de atribuição e obtemos um comportamento inválido, porque o nosso done se torna true antes que o valor da variável "
Não tente fazer essas otimizações - por causa delas, você terá muitos problemas. Aconselho que você leia a especificação de The Go Memory Model e um artigo de Dmitry Vyukova ( @dvyukov ) Raças de dados benignas: o que poderia dar errado? para entender melhor os problemas.
Se você realmente confia no desempenho dos bloqueios - escreva um código sem bloqueios, mas não precisará acessar não sincronizado a memória.
Impasse
O próximo problema que enfrentaremos é o impasse. Pode parecer que tudo é bastante trivial aqui. Existem dois recursos, por exemplo, dois Mutex . No primeiro segmento, capturamos primeiro o primeiro Mutex e, no segundo, capturamos primeiro o segundo Mutex . Além disso, quereremos pegar o segundo Mutex no primeiro thread, mas não conseguiremos fazer isso, porque ele já está bloqueado. No segundo segmento, tentaremos pegar, respectivamente, o primeiro Mutex e também o bloco. Lá está ele, Deadlock.
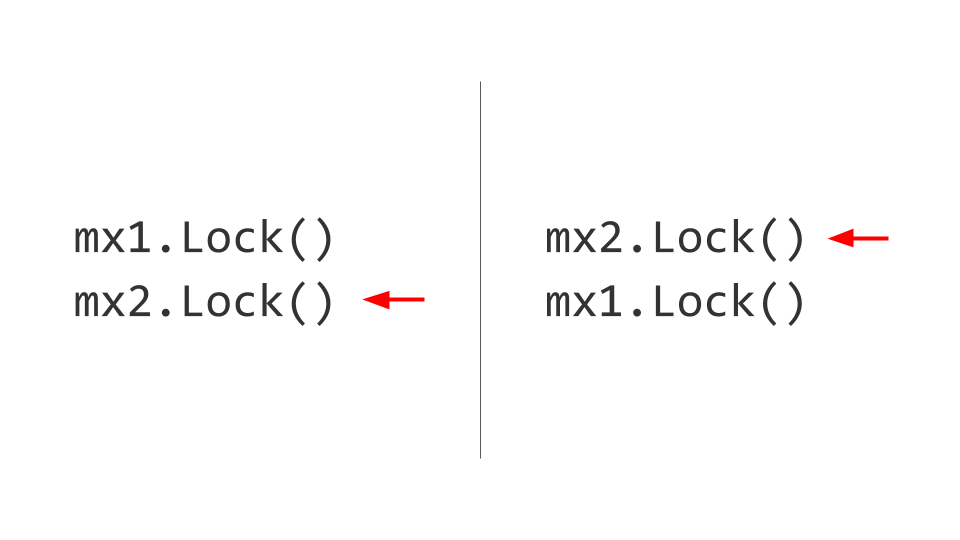
Nenhum desses dois encadeamentos poderá progredir mais, pois os dois aguardarão o recurso. Como isso é resolvido? Trocamos bloqueios e, em seguida, não surgem problemas. Obviamente, é fácil dizer, mas manter essa regra por toda a vida útil do produto não é fácil. Se possível, faça - pegue e solte os bloqueios na mesma ordem .
Pode parecer que desenvolvedores experientes não encontram esses erros, mas aqui está um exemplo de um impasse no código do projeto etcd.

Aqui, o principal problema é que a gravação em um canal sem buffer está bloqueando; para escrever, você precisa de um leitor, por outro lado. Tomando o mutex, o primeiro segmento aguarda o leitor aparecer. O segundo segmento não pode mais capturar o mutex. Impasse
Eu aconselho você a experimentar o emocionante jogo The Deadlock Empire . Neste jogo, você age como um agendador que deve alternar o contexto para impedir que o código seja executado corretamente.
Tipo de problemas
Que problemas ainda existem? Começamos com as condições da corrida . Em seguida, analisamos o Deadlock (ainda existe uma variante do Livelock , é quando não podemos capturar o recurso, mas não há bloqueios explícitos). Há fome , é quando vamos à impressora imprimir um pedaço de papel, e há uma fila e não podemos acessar o recurso. Analisamos o comportamento do programa com o compartilhamento falso . Ainda existe um problema - Bloquear contenção , quando o desempenho diminui devido a muita concorrência por um recurso (por exemplo, um mutex que um grande número de encadeamentos precisa).

Detecção de corrida
O Go é poderoso com a caixa de ferramentas fornecida imediatamente. O Race Detector é uma dessas ferramentas. Usá-lo é simples: escrevemos testes ou executamos em uma carga de combate e detectamos erros.
Você pode ler mais sobre o uso do Race Detector na documentação , mas lembre-se de que ele tem limitações. Vamos nos debruçar sobre eles com mais detalhes.

Em primeiro lugar, o código que não foi executado não é verificado pelo Race Detector. Portanto, a cobertura do teste deve ser alta. Além disso, o Race Detector lembra o histórico de chamadas para cada palavra na memória, mas esse histórico de chamadas tem profundidade. No Go, por exemplo, essa profundidade é de quatro - quatro elementos, quatro acessos. Se o Detector de Regatas não conseguiu uma corrida nessa profundidade, ele acredita que não há corrida. Portanto, embora o Race Detector nunca esteja errado, ele não detectará todos os erros. Você pode esperar pelo Detector de Corrida, mas precisa se lembrar de suas limitações. Separadamente, você pode ler sobre o algoritmo do trabalho .
Bloquear perfil
O perfil de bloco é outra ferramenta que nos permite encontrar e corrigir problemas de bloqueio.

Ele pode ser usado no nível de teste de referência e pode ser observado durante a carga de combate. Portanto, se você estiver procurando por problemas associados à sincronização de acesso a dados, tente começar com o Race Detector e continue usando o Block Profile.
Exemplo de programa
Vejamos o código real no qual podemos tropeçar. Escreveremos uma função que simplesmente pega uma matriz de solicitações e tenta executá-las: cada solicitação em sequência. Se algum dos pedidos retornar um erro, a função encerrará a execução.

Se escrevermos em Go, devemos usar todo o poder da linguagem. Nós tentamos. Temos três vezes mais código.

Pergunta: há algum erro no código?
Claro! Vamos ver quais.
No loop, executamos goroutines. Para orquestração de goroutines, usamos sync.WaitGroup . Mas o que estamos fazendo de errado? Já dentro da goroutine em execução, chamamos wg.Add(1) , ou seja, adicionamos mais uma goroutine para aguardar. E usando wg.Wait() , estamos aguardando a conclusão de todas as goroutines. Mas pode acontecer que, no momento em que wg.Wait() seja chamado, nenhuma goroutine seja iniciada. Nesse caso, wg.Wait() considerará que tudo está feito, fecharemos o canal e sairemos da função sem erros, acreditando que está tudo bem.

O que acontecerá depois? Em seguida, as goroutines serão iniciadas, o código será executado e talvez uma das solicitações retorne um erro. Um erro é gravado em um canal fechado e a gravação em um canal fechado é um pânico. Nosso aplicativo falhará. É improvável que isso fosse o que eu queria obter, então o corrigimos indicando antecipadamente quantas goroutines lançaremos.

Talvez ainda haja alguns problemas?
Há um erro relacionado a como o objeto req aparece dentro da função. A variável req atua como um iterador do ciclo e não sabemos qual valor terá no momento do lançamento da goroutine.

Na prática, nesse código, o valor req provavelmente será igual ao último elemento da matriz. Portanto, você acabou de enviar a mesma solicitação N vezes. Correção: passa explicitamente nossa solicitação como argumento para a função.

Vamos dar uma olhada em como lidamos com erros. Declaramos um canal em buffer em um slot. Quando ocorre um erro, enviamos para este canal. Tudo parece estar bem: ocorreu um erro - retornamos esse erro de uma função.

Mas e se todos os pedidos retornarem com um erro?
Em seguida, escrever no canal receberá apenas o primeiro erro, o restante bloqueará a execução de goroutines. Como não haverá mais leituras do canal na hora de sair da função de leitura, temos um vazamento de goroutine. Ou seja, todas aquelas gorutinas que não conseguiram gravar o erro no canal simplesmente ficam na memória.
Nós corrigimos isso de maneira muito simples: selecionamos no canal do slot o número de solicitações. Isso resolve nosso problema com pouca memória, porque se tivermos um bilhão de solicitações, precisamos alocar um bilhão de slots.

Nós resolvemos os problemas. O código agora é competitivo. Mas o problema está na legibilidade - em comparação com a versão síncrona do código, há muito. E isso não é legal, porque o desenvolvimento de programas competitivos já é difícil, por que o complicamos com muito código?

Errgroup
Eu sugiro aumentar a legibilidade do código.
Eu gosto de usar o pacote errgroup em vez do sync.WaitGroup . Este pacote não requer a especificação de quantas goroutines esperar e permite que você ignore a coleção de erros. É assim que nossa função será errgroup ao usar o errgroup :

Além disso, o errgroup permite orquestrar convenientemente os componentes do nosso programa usando context.Context . O que eu quero dizer?
Suponha que tenhamos vários componentes de nosso programa; se pelo menos um deles falhar, queremos concluir cuidadosamente todos os outros. Portanto, o grupo de errgroup quando errgroup um erro, completa o context e, portanto, todos os componentes recebem uma notificação sobre a necessidade de concluir o trabalho.

Isso pode ser usado para criar programas complexos de múltiplos componentes que se comportam de maneira previsível.
Conclusões
Torne o mais simples possível. Melhor de forma síncrona. O desenvolvimento de programas multithread é geralmente um processo complexo, levando ao aparecimento de erros desagradáveis.

Não use sincronização implícita. Se você realmente descansou, pense em como se livrar dos bloqueios, como criar um algoritmo sem bloqueios.
Go é uma boa linguagem para escrever programas que funcionam efetivamente com um grande número de núcleos, mas não é melhor que todos os outros idiomas, e os erros sempre aparecerão. Portanto, mesmo armado com o Go, tente entender vários níveis de abstrações abaixo do que você trabalha.
