Apresentamos à sua atenção o DbTool - um utilitário de linha de comando para exportar dados do banco de dados para vários formatos e a biblioteca de código-fonte aberto Korzh.DbUtils , cujo uso pode simplificar bastante a "sementeira" inicial do banco de dados no aplicativo .NET (Core).
Com este kit de ferramentas, você pode:
- Salve os dados do banco de dados local em arquivos de um determinado formato de texto (XML, JSON), fáceis de conectar ao projeto.
- Use os arquivos salvos para preencher o banco de dados do próprio aplicativo em sua primeira inicialização.
Abaixo, mostrarei por que tudo isso é necessário, como instalar e configurar essas ferramentas e descrever um cenário detalhado para seu uso.

A tarefa inicial foi criar um mecanismo conveniente de preenchimento de banco de dados em aplicativos .NET (Core). Devido às especificidades do nosso tipo de atividade (desenvolvimento de componentes), geralmente precisamos criar pequenos aplicativos de amostra que demonstrem um ou outro recurso do nosso produto. Esses projetos de demonstração devem funcionar com um determinado banco de dados de teste e, portanto, é aconselhável criar e preencher automaticamente esse banco de dados no primeiro início do aplicativo.
Se o projeto usar o Entity Framework (Core) (e isso acontece com mais freqüência), não haverá problemas com a criação do banco de dados. Você simplesmente chama dbContext.Database.EnsureCreated ou dbContext.Database.Migrate (se for importante manter as migrações).
Mas com o preenchimento do banco de dados, tudo fica um pouco mais complicado. A primeira coisa que vem à mente é simplesmente criar um script SQL com vários INSERTs, colocá-lo no projeto e executá-lo na primeira inicialização. Isso funciona (e fizemos por muito tempo), mas há alguns problemas com essa abordagem. Primeiro de tudo, um problema de sintaxe SQL para um DBMS específico. Muitas vezes, o DBMS original é diferente daquele que é realmente usado pelo usuário e nosso script SQL pode não funcionar.
O segundo problema possível é a migração do próprio banco de dados. Periodicamente, é necessário alterar ligeiramente a estrutura do banco de dados (adicionar um novo campo, excluir ou renomear o antigo, adicionar um novo relacionamento entre tabelas, etc.). Um script SQL criado sob a estrutura antiga geralmente se torna irrelevante nesse caso e sua execução causa um erro. O carregamento de dados de algum formato de terceiros fica sem problemas. Os campos novos / alterados são simplesmente ignorados. Concorde que, para fins de demonstração, é melhor que o programa seja iniciado, embora sem dados em algum campo novo, do que não seja iniciado.
Como resultado, chegamos à seguinte solução:
- Os dados da "cópia principal" do nosso banco de dados demo são gravados em um arquivo em um determinado formato "independente" (atualmente é XML ou JSON). Os arquivos resultantes (ou um arquivo morto) são entregues com o projeto. Esta tarefa, de fato, lida com o DbTool.
- Um pequeno pedaço de código é inserido em nosso programa, que, usando as classes e funções da biblioteca Korzh.DbUtils, preenche o banco de dados com dados do (s) arquivo (s) obtido (s) na primeira etapa.
Além do cenário acima, o DbTool pode ser usado simplesmente para exportar dados para outros formatos e transferir dados entre bancos de dados. Assim, por exemplo, você pode fazer upload de dados do seu banco de dados para o SQL Server e carregá-los em um banco de dados semelhante no MySQL.
Instalação
O DbTool é implementado como uma ferramenta global do .NET Core, ou seja, pode ser facilmente instalado em qualquer sistema em que exista um .NET SDK versão 2.1 ou superior.
Para instalar o utilitário, basta abrir o console (Terminal / Prompt de Comando) e executar o seguinte comando:
dotnet tool install -g Korzh.DbTool
Para verificar após a instalação, digite dbtool no console e você verá ajuda com uma lista de comandos disponíveis.
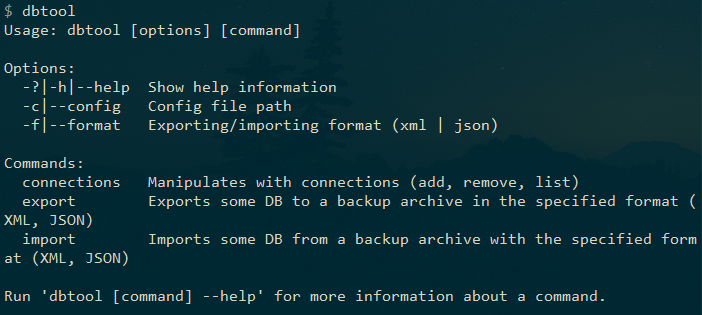
Adicionar conexão ao banco de dados
Para começar a trabalhar com o DbTool, você precisa adicionar uma conexão com o banco de dados:
dbtool add {YourConnectionId} {DbType} {YourConnectionString}
Aqui:
- {YourConnectionId} é um identificador que você deseja atribuir a esta conexão, para que você possa acessá-la mais tarde quando executar outros comandos.
- DbType é o tipo do seu DBMS. No momento da redação deste artigo, o DbTool (versão 1.1.7) suportava os bancos de dados SQL Server (mssql) e MySQL (mysql).
- O último parâmetro neste comando é a cadeia de conexão. O mesmo que você já usa no seu projeto .NET (Core).
Um exemplo:

Depois disso, você pode verificar todas as suas conexões digitando:
dbtool connections list
Exportação de dados
Agora que adicionamos a conexão, podemos exportar nosso banco de dados usando o comando export:
dbtool export {ConnectionId} [--format=xml|json] [--output={path-to-folder}] [--zip={file-name}]
Qualquer opção mencionada acima pode ser omitida. Se você não especificar o format JSON será usado. Se você omitir a opção de output , o resultado será colocado em um diretório no formato ConnectionId_yyyy-MM-dd em um formato descompactado.
Por exemplo, o seguinte comando:
dbtool export MyDb01 --zip=MyDbData.zip
criará um arquivo ZIP com o nome MyDbData.zip no diretório atual e o preencherá com arquivos de dados no formato JSON (um arquivo para cada tabela de banco de dados).

Importação de dados
Você pode importar os dados criados na etapa anterior novamente para o seu banco de dados. Ou para qualquer outra base com a mesma estrutura.
Importante: O DbTool não cria tabelas durante a operação de importação. Assim, o banco de dados no qual os dados são importados já deve existir e ter a mesma (ou pelo menos semelhante) estrutura que a original.
O próprio comando import é o seguinte:
dbtool import {ConnectionId} [--input=path-to-file-or-folder] [--format=xml|json]
A opção --input informa ao utilitário onde procurar dados importados. Se um caminho de pasta for especificado, o DbTool importará arquivos .xml ou .json nessa pasta. Se este for um arquivo ZIP, o utilitário descompactará primeiro esse arquivo e, a partir daí, removerá os arquivos de dados necessários.
Como no caso anterior, --format pode ser omitido, pois o DbTool pode reconhecer o formato por extensões de arquivo.
Um exemplo:
dbtool import MyDb01 --input=MyDbData.zip
Biblioteca Korzh.DbUtils
O próprio utilitário DbTool é construído com base na biblioteca de código aberto Korzh.DbUtils , que inclui vários pacotes com a implementação de algumas operações básicas do banco de dados.
Korzh.DbUtils
Define abstrações básicas e interfaces como IDatasetExporter, IDatasetImporter, IDataPacker, IDbBridge
Korzh.DbUtils.Import
Contém implementações de interfaces IDatasetImporter para os formatos XML e JSON. Além disso, este pacote inclui a classe DbInitializer, que você pode usar para preencher dados em seus projetos (mais sobre isso abaixo).
Korzh.DbUtils.Export
Contém implementações de IDatasetExporter para XML e JSON.
Korzh.DbUtils.SqlServer
Contém a implementação das interfaces das operações básicas do banco de dados (IDbBridge, IDbReader, IDbSeeder) para MS SQL Server.
Korzh.DbUtils.MySQL
Contém implementações de interfaces de banco de dados para MySQL.
Aqui você pode encontrar a referência completa na API da biblioteca Korzh.DbUtils .
Usando o Korzh.DbUtils para preencher o banco de dados com dados na inicialização do aplicativo
Agora, na verdade, consideraremos como usar o DbTool e o Korzh.DbUtils para implementar o script básico para preencher (semear) o banco de dados no primeiro lançamento do aplicativo.
Suponha que você tenha uma “cópia principal” de algum banco de dados que você precisa “copiar” no computador do usuário quando iniciar o aplicativo.
Etapa 1: Exportar a cópia principal para JSON
Basta instalar o DbTool, conforme descrito acima, adicionar uma conexão ao banco de dados e executar o comando export para salvar todos os dados desse banco de dados em uma pasta separada:
dotnet tool install -g Korzh.DbTool dbtool connections add MyMasterDb mssql "{ConnectionString}" dbtool export MyMasterDb
Etapa 2: adicionar arquivos de dados ao nosso projeto
Após a etapa anterior, temos uma nova pasta, no formato MyMasterDb-aaaa-MM-dd, com vários arquivos JSON (um para cada tabela). Basta copiar o conteúdo desta pasta para o App_Data \ DbSeed do nosso projeto .NET (Core). Observe que, para projetos no .NET Framework, você também precisará adicionar manualmente esses arquivos ao projeto.
Etapa 3: código de inicialização do banco de dados
Embora o processo em si (até alguns detalhes) seja aplicável a qualquer tipo de projeto no .NET Core ou .NET Framework (versão 4.6.1 ou superior), para simplificar a descrição, suponha que estamos falando de um projeto ASP.NET Core que funcione com Banco de dados do SQL Server e que esse banco de dados seja criado automaticamente usando o Entity Framework Core.
Assim, para resolver o problema de preencher o banco de dados com dados no primeiro início, precisamos:
1. Instale os pacotes da biblioteca Korzh.DbUtils no projeto NuGet
Nesse caso, precisamos de 2 deles:
- Korzh.DbUtils.Import
- Korzh.DbUtils.SqlServer
2. Adicione código de inicialização
Aqui está um exemplo desse código que devemos adicionar no final do método Startup.Configure:
public void Configure(IApplicationBuilder app, IHostingEnvironment env) { . . . . app.UseMvc(); using (var scope = app.ApplicationServices.GetRequiredService<IServiceScopeFactory>().CreateScope()) using (var context = scope.ServiceProvider.GetService<AppDbContext>()) { if (context.Database.EnsureCreated()) {
Para deixar tudo muito bonito, ou se você precisar executar alguma inicialização adicional na primeira inicialização (por exemplo, adicionar várias contas de usuário e / ou funções de usuário), é melhor projetar todo esse código como um método de extensão separado (vamos chamá-lo de EnsureDbInitialized ) para a interface IApplicationBuilder .
Um exemplo dessa implementação pode ser encontrado no GitHub no projeto de demonstração da biblioteca EasyQuery .
Nesse caso, você só precisa adicionar uma chamada no final do seu método Startup.Configure:
public void Configure ( IApplicationBuilder, IHostingEnvironment) { . . . . app.UseMvc ();
Planos futuros
Embora a biblioteca e o utilitário tenham sido gravados em um cenário muito específico, tentamos fazer tudo o mais flexível e extensível possível, portanto, ativar a funcionalidade adicional não seria um problema.
Das possíveis melhorias, vemos o seguinte:
Suporte para outros bancos de dados (PostgreSQL, Oracle, SQLite, MariaDB)
Novos formatos para os quais você pode exportar dados (CSV, Excel, HTML)
A operação de copiar diretamente dados do banco de dados para o banco de dados (agora você pode implementá-lo através de algumas chamadas consecutivas aos comandos de exportação / importação)
Operações completas de backup / restauração com preservação total da estrutura do banco de dados e sua criação do zero durante a recuperação.
Teremos o maior prazer em ouvir sugestões ou comentários e agradecemos as novas estrelas do repositório de bibliotecas do GitHub :)
Obrigado pela atenção!