Apresentamos a sua atenção a segunda parte da tradução do material sobre a luta da equipe gitlab.com contra a tirania do tempo.

→ Aqui, a propósito, é a
primeira parte .
Limite de velocidade de processamento de solicitações
Neste ponto, não estávamos interessados em simplesmente aumentar os valores do parâmetro
MaxStartups . Embora um aumento de 50% nesse parâmetro tenha sido bom, seu aumento adicional sem motivo suficiente pareceu uma solução bastante grosseira para o problema. Certamente havia algo mais que poderíamos fazer.
As pesquisas me levaram ao nível HAProxy, localizado na frente dos servidores SSH. O HAProxy possui uma boa opção de
rate-limit sessions que afeta a parte do sistema que aceita solicitações de entrada. Se essa opção estiver configurada, ela será usada para limitar o número de novas solicitações TCP por segundo que o front-end envia para os back-end, deixando conexões adicionais de entrada no soquete TCP. Se a velocidade das solicitações recebidas exceder o limite (alterável a cada milissegundo), as novas conexões simplesmente atrasam. O cliente TCP (neste caso, SSH) simplesmente vê o atraso antes de estabelecer uma conexão TCP. Este, na minha opinião, é uma jogada muito bonita. Até que a velocidade na qual as solicitações sejam recebidas, por períodos muito longos, exceda demais o limite, o sistema funcionará bem.
A próxima pergunta foi a seleção do valor da opção de
rate-limit sessions , que deveríamos usar. Encontrar uma resposta para essa pergunta foi complicado pelo fato de termos 27 back-ends SSH e 18 front-end HAProxy (16 main e 2 alt-ssh), além do fato de que os front-end não se coordenam entre si em relação à velocidade do processamento de solicitações . Além disso, tivemos que levar em conta quanto tempo leva a etapa de autenticação da nova sessão SSH. Suponha que o primeiro valor de
MaxStartups seja 150. Isso significa que, se a fase de autenticação demorar dois segundos, podemos transferir cada back-end apenas 75 novas sessões por segundo.
Aqui você pode encontrar detalhes sobre como calcular o valor das
rate-limit sessions de
rate-limit sessions , não entrarei em detalhes aqui. Observo apenas que, para calcular esse valor, quatro parâmetros devem ser levados em consideração. O primeiro e o segundo são o número de servidores dos dois tipos. O terceiro é o valor de
MaxStartups . O quarto é
T - quanto tempo leva para autenticar uma sessão SSH. O valor de
T extremamente importante, mas só pode ser deduzido aproximadamente. Fizemos exatamente isso, deixando o resultado em 2 segundos. Como resultado, obtivemos o valor
rate-limit para os front-ends, que totalizaram 112,5. Nós arredondamos para 110.
E agora, as novas configurações entraram em vigor. Talvez você pense que depois disso tudo terminou feliz? Deve ter sido que o número de erros chegou a zero e todos ao redor ficaram imensamente felizes? Bem, na verdade estava longe de ser tão bom. Essa alteração não resultou em alterações visíveis na taxa de erro. Sinceramente, fiquei muito chateado. Perdemos algo importante ou entendemos mal a essência do problema.
Como resultado, voltamos aos logs (e, finalmente, às informações do HAProxy) e pudemos garantir que o limite de velocidade de processamento de consultas funcionasse nas consultas conforme o esperado. Anteriormente, os indicadores correspondentes eram maiores, o que nos permitiu concluir que limitamos com êxito a velocidade com que as solicitações recebidas são enviadas para processamento. Mas ficou claro que a taxa em que os pedidos chegaram ainda era muito alta. Embora também tenha ficado claro que nem chegou perto desses níveis quando poderia ter um efeito perceptível no sistema. Quando analisamos o processo de seleção de back-end (de acordo com os logs HAProxy), notamos uma estranheza lá. No início da hora, as conexões de back-end eram distribuídas de maneira desigual entre os servidores SSH. No intervalo de tempo escolhido para análise, o número de conexões por segundo em diferentes servidores variava de 30 a 121. E isso significava que nosso balanceamento de carga não funcionava bem. A análise da configuração mostrou que usamos a opção de
balance source , para que um cliente com um endereço IP específico sempre se conectasse ao mesmo back-end. Isso pode ser considerado um fenômeno positivo nos casos em que a ligação da sessão é necessária. Mas estamos lidando com SSH, portanto não precisamos disso. Essa opção já foi configurada por nós, mas não encontramos nenhuma dica sobre por que isso foi feito. Não foi possível encontrar um motivo digno para continuar a usá-lo. Como resultado, decidimos mudar para o
leastconn . Graças a esta opção, novas conexões recebidas fornecem backends com o número mínimo de conexões atuais. Isso afetou o uso de recursos do processador por nossos servidores SSH (Git). Aqui está o cronograma correspondente.
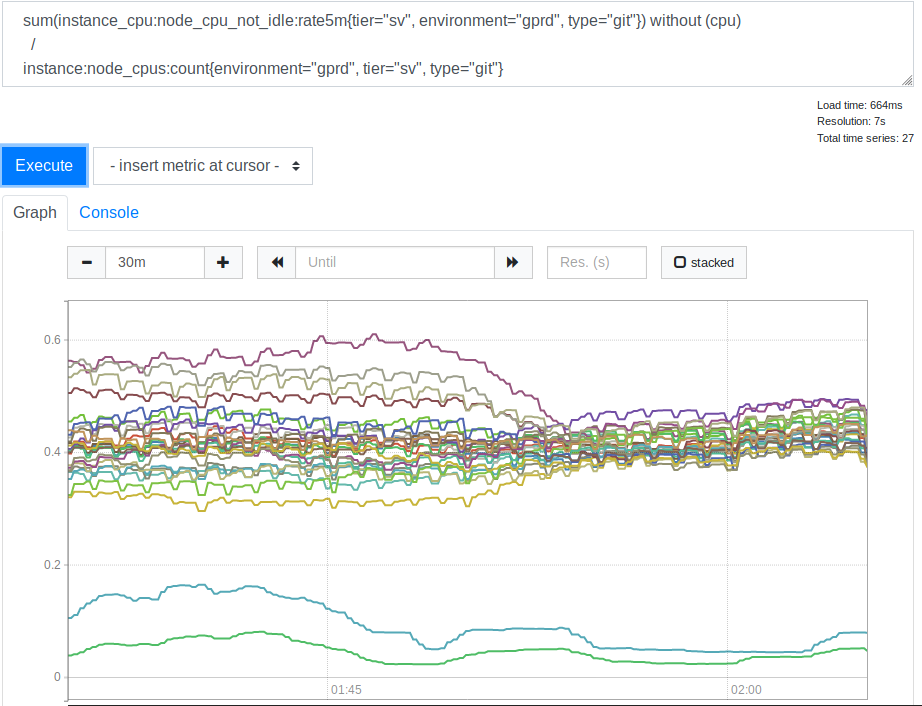 Consumo de CPU pelos servidores antes e depois de aplicar a opção lessconn
Consumo de CPU pelos servidores antes e depois de aplicar a opção lessconnDepois que vimos isso, percebemos que usar o
leastconn é uma boa ideia. As duas linhas que estão na parte inferior do gráfico são nossos servidores Canary, você pode ignorá-las. Porém, antes, a distribuição dos valores de carga da CPU para diferentes servidores era correlacionada como 2: 1 (de 30% a 60%). Isso indicava claramente que anteriormente alguns de nossos back-end eram carregados mais que outros devido à conexão dos clientes com eles. Foi uma surpresa para mim. Parecia razoável esperar que uma ampla variedade de endereços IP de clientes fosse suficiente para carregar nossos servidores de maneira muito mais uniforme. Mas, aparentemente, para distorcer os indicadores de carga do servidor, vários clientes grandes foram suficientes, cujo comportamento difere de alguma opção média.
Lição número 4. Quando você selecionar configurações específicas que diferem das configurações padrão, comente ou deixe um link para os materiais que explicam as alterações. Qualquer pessoa que tenha que lidar com essas configurações no futuro será grata por isso.
Essa transparência é
um dos principais valores do GitLab .
A ativação da opção
leastconn também ajudou a reduzir os níveis de erro. E era exatamente para isso que estávamos nos esforçando. Portanto, decidimos deixar essa opção. Mas, continuando a experimentar, eles reduziram o nível de velocidade de processamento de solicitações para 100, o que ajudou a reduzir ainda mais o nível de erros. Isso indicou que a seleção inicial do valor de
T provavelmente foi realizada incorretamente. Mas, nesse caso, esse indicador era muito pequeno, o que levava a um limite de velocidade muito forte, e até 100 solicitações por segundo eram percebidas como um valor muito baixo, e não estávamos prontos para reduzi-lo ainda mais. Infelizmente, por algum motivo interno, essas duas mudanças foram apenas um experimento. Tivemos que voltar a usar a opção de
balance source do
balance source e limitar a velocidade de processamento de solicitações a 100 solicitações por segundo.
Dado que a velocidade de processamento da consulta foi definida como um nível baixo que nos convém e que não poderíamos usar menos
leastconn , tentamos aumentar o parâmetro
MaxStartups . No começo, aumentamos para 200, isso deu algum efeito. Então - até 250. Erros quase completamente desapareceram e nada de ruim aconteceu.
Lição número 5. Embora altos MaxStartups possam parecer intimidadores, eles têm muito pouco impacto no desempenho, mesmo quando são muito mais altos que os valores padrão.
Talvez isso seja algo como uma alavanca grande e poderosa, que possamos, se necessário, usar no futuro. Talvez encontremos problemas se estivermos falando de números na região de vários milhares ou dezenas de milhares, mas ainda estamos longe disso.
O que isso diz sobre minhas estimativas do parâmetro
T , o tempo necessário para instalar e autenticar uma sessão SSH? Se você trabalha com a fórmula para calcular o indicador de limite de velocidade de processamento de conexão, sabendo que 200 não é suficiente para o indicador
MaxStartups e 250 é suficiente, você pode descobrir que
T provavelmente tem um valor de 2,7 a 3,4 segundos. Como resultado, um valor estimado de 2 segundos não estava longe da verdade, mas o valor real, é claro, foi superior ao esperado. Voltaremos a isso um pouco mais tarde.
Etapas finais
Examinamos novamente os logs, levando em conta o que já sabíamos e, após alguma reflexão, descobrimos que o problema com o qual tudo começou começou pode ser identificado pelos seguintes sinais. Em primeiro lugar, este é um valor
t_state igual a
SD . Em segundo lugar, esse é o valor de
b_read (bytes lidos pelo cliente), igual a 0. Como já mencionado, processamos aproximadamente 26 a 28 milhões de conexões SSH por dia. Foi desagradável saber que, no meio do desastre, aproximadamente 1,5% dessas conexões foram totalmente interrompidas. Obviamente, a escala do problema era muito maior do que pensávamos no começo. Além disso, não havia nada que não pudéssemos detectar anteriormente (mesmo quando percebemos que
t_state="SD" indicava o problema nos logs), mas não pensamos em como fazer isso, embora e você deve pensar sobre isso. Provavelmente, por isso, gastamos muito mais tempo e esforço na solução do problema do que poderíamos ter gasto.
Lição número 6. Meça os níveis de erro reais o mais cedo possível.
Se estivéssemos inicialmente cientes da extensão do problema, poderíamos prestar mais atenção a ele. Embora, como percebê-lo, ainda dependa do conhecimento das características que nos permitem descrever os problemas.
Se falarmos sobre as vantagens que surgiram depois que aumentamos os valores do
MaxStartups e
MaxStartups a velocidade das solicitações de processamento, podemos dizer que o nível de erro caiu para 0,001%. Isso é - até vários milhares por dia. Essa situação parecia muito melhor, mas um nível semelhante de erros ainda era maior do que o que gostaríamos de alcançar. Depois que descobrimos algumas coisas, pudemos novamente usar a opção
leastconn e os erros desapareceram completamente. Depois disso, conseguimos respirar aliviados.
Trabalho futuro
Obviamente, a fase de autenticação SSH ainda leva muito tempo. Talvez até 3,4 segundos. O GitLab pode usar o
AuthorizedKeysCommand para procurar diretamente uma chave SSH em um banco de dados. Isso é muito importante para operações rápidas quando há um grande número de usuários. Caso contrário, o SSHD precisará ler sequencialmente um arquivo
authorized_keys muito grande para encontrar a chave pública do usuário. Esta tarefa não é bem dimensionada. Implementamos uma pesquisa usando uma certa quantidade de código Ruby que realiza chamadas para uma API HTTP externa.
Stan Hugh , chefe do nosso departamento de engenharia e uma fonte inesgotável de conhecimento sobre o GitLab, descobriu que as instâncias Unicorn dos servidores Git / SSH estão sob carga constante de solicitações feitas a eles. Isso pode contribuir significativamente para os três segundos necessários para autenticar solicitações. Como resultado, percebemos que, no futuro, deveríamos investigar esse problema. Talvez aumentemos o número de instâncias Unicorn (ou Puma) nesses nós para que os servidores SSH não precisem esperar para acessá-los. No entanto, há um certo risco aqui, portanto, precisamos ter cuidado e prestar atenção à coleta e análise de indicadores do sistema. O trabalho sobre produtividade continua, mas agora, depois que o principal problema é resolvido, as coisas estão indo mais devagar. Podemos reduzir o valor do
MaxStartups , mas como seu alto nível não cria o impacto negativo no sistema que parece estar criando, isso não é particularmente necessário. Será muito mais fácil para todos viver se o OpenSSH puder, a qualquer momento, nos dizer o quão perto estamos dos limites do
MaxStartups . Será melhor se pudermos sempre saber. Isso é muito melhor do que aprender que os limites são excedidos quando confrontados com conexões interrompidas.
Além disso, precisamos de algum tipo de sistema de notificação quando as entradas de log HAProxy aparecerem, indicando um problema com as conexões desconectadas. O fato é que, na prática, isso não deveria acontecer. Se isso acontecer novamente, precisaremos aumentar ainda mais os valores do
MaxStartups , ou se houver falta de recursos, precisaremos adicionar mais nós Git / SSH ao sistema.
Sumário
Partes de sistemas complexos interagem em padrões complexos. E neles, para resolver vários problemas, muitas vezes podemos encontrar longe de uma "alavanca". Ao lidar com esses sistemas, é útil conhecer as ferramentas presentes neles. O fato é que todos têm seus prós e contras. Além disso, deve-se notar que pode ser arriscado realizar determinadas configurações com base em suposições e valores estimados. Agora, olhando o caminho que percorremos, tentaria medir com a maior precisão possível o tempo necessário para concluir a autenticação da solicitação, o que levaria ao valor aproximado de
T que deduzi que estaria mais próximo da verdade.
Mas a principal lição que aprendemos disso tudo é que, quando muitas pessoas planejam tarefas com base em algumas métricas de tempo agradável, isso, para provedores de serviços centralizados como o GitLab, leva a problemas de escala realmente incomuns.
Se você é um dos que usa as ferramentas agendadas para o lançamento de tarefas, pode pensar em configurar o tempo para iniciar suas tarefas de uma nova maneira. Por exemplo, você pode fazer as tarefas “adormecerem” por um tempo, começando a realmente funcionar apenas 30 segundos após o lançamento. Você pode, por exemplo, indicar horários aleatórios dentro de uma hora no agendamento da inicialização da tarefa (aqui você pode adicionar um tempo de espera aleatório antes da execução real da tarefa). Isso nos ajudará a todos na luta contra a tirania dos relógios.
Caros leitores! Você encontrou problemas semelhantes àquele cuja história este material é dedicado?
