O material, a primeira parte da tradução que publicamos hoje, é dedicado a um problema de grande escala que surgiu no gitlab.com. Aqui falaremos sobre como a encontraram, como brigaram com ela e como finalmente a resolveram. Além disso, diante desse problema, a equipe do gitlab.com descobriu qual é a tirania dos relógios.

→
A segunda parte .
O problema
Começamos a receber mensagens de clientes que, ao trabalharem com o gitlab.com, eles periodicamente encontram erros ao executar solicitações pull. Os erros geralmente ocorriam ao executar tarefas de IC ou durante a operação de outros sistemas automatizados semelhantes. As mensagens de erro eram mais ou menos assim:
ssh_exchange_identification: connection closed by remote host fatal: Could not read from remote repository
A situação ficou ainda mais complicada pelo fato de as mensagens de erro aparecerem de maneira irregular e, ao que parecia, imprevisíveis. Não conseguimos reproduzi-los à vontade, não conseguimos identificar nenhum sinal óbvio do que estava acontecendo nas paradas ou nos registros. As próprias mensagens de erro também não traziam muitos benefícios. O cliente SSH foi informado de que a conexão foi interrompida, mas o motivo pode ser qualquer coisa: um cliente com falha ou uma máquina virtual instável, um firewall que não controlamos, ações estranhas do provedor ou um problema com nosso aplicativo.
Nós, trabalhando no esquema GIT-over-SSH, estamos lidando com um número muito grande de conexões - cerca de 26 milhões por dia. Essa é uma média de 300 conexões por segundo. Portanto, uma tentativa de selecionar um pequeno número de conexões com falha no fluxo de dados existente prometeu ser uma tarefa difícil. O bom dessa situação é que gostamos de resolver problemas complexos.
Primeira pista
Entramos em contato com um de nossos clientes (graças a Hubert Holtz, de Atalanda), que encontrou um problema várias vezes ao dia. Isso nos deu um ponto de apoio. Hubert conseguiu nos fornecer um endereço IP público adequado. Isso significava que poderíamos capturar pacotes em nossos nós de front-end HAProxy, a fim de tentar isolar o problema, contando com um conjunto de dados menor do que o que poderia ser chamado de "todo o tráfego SSH". Melhor ainda, a empresa usou uma
porta ssh alternativa . Isso significava que precisávamos analisar a situação em apenas dois servidores HAProxy, e não em dezesseis.
A análise de pacotes, no entanto, não foi particularmente divertida. Apesar das restrições em cerca de 6,5 horas, foram coletados cerca de 500 MB de pacotes. Encontramos compostos de vida curta. A conexão TCP foi estabelecida, o cliente enviou o identificador, após o qual nosso servidor HAProxy desconectou imediatamente usando a sequência TCP FIN correta. Como resultado, tínhamos à disposição a primeira excelente pista. Ela nos permitiu concluir que a conexão foi definitivamente encerrada por iniciativa do gitlab.com, e não por causa de algo entre nós e o cliente. Isso significava que estávamos diante de um problema que podemos investigar e corrigir.
Lição número 1. O menu Estatísticas da ferramenta Wireshark possui uma tonelada de ferramentas úteis às quais eu, antes desse caso, não prestava muita atenção.
Em particular, estamos falando do item de menu
Conversations , que pode demonstrar informações básicas sobre dados capturados sobre conexões TCP. Há informações sobre tempo, pacotes, bytes. Os dados exibidos na janela correspondente podem ser classificados. Eu devo usar essa ferramenta desde o início, em vez de mexer manualmente com os dados capturados. Então percebi que precisava procurar conexões com um pequeno número de pacotes. A janela
Conversations permitiu que você prestasse atenção imediatamente a elas. Depois disso, consegui encontrar outros compostos semelhantes e garantir que a primeira conexão desse tipo não fosse um fenômeno anormal.
Imersão em log
O que causou a desconexão do HAProxy do cliente? O servidor, é claro, não fez isso de maneira arbitrária: o que estava acontecendo deveria ter tido um motivo mais profundo; se você gosta - "outro nível de
tartarugas ". Havia a sensação de que o próximo objeto de estudo deveria ser os logs HAProxy. Nossos logs foram armazenados no GCP BigQuery. Isso é conveniente, pois temos muitos logs e precisamos analisá-los de maneira abrangente. Mas, primeiro, conseguimos identificar a entrada de log de um dos incidentes, encontrada nos pacotes capturados. Confiamos no tempo e na porta TCP, o que foi uma grande conquista em nosso estudo. O detalhe mais interessante no registro encontrado foi o
t_state (Termination State), que tinha o valor
SD . Aqui está um extrato da documentação do HAProxy:
S: , . D: DATA.
O significado do significado de
D é explicado de maneira muito simples. A conexão TCP foi estabelecida corretamente, os dados foram enviados. Isso coincidiu com as evidências obtidas dos pacotes capturados. Um valor de
S significava que o HAProxy recebeu uma mensagem de falha RST ou ICMP do back-end. Mas não conseguimos encontrar imediatamente uma pista sobre o motivo disso estar acontecendo. A razão para isso pode ser qualquer coisa - de uma rede instável (por exemplo, uma falha ou congestionamento) a um problema no nível do aplicativo. Usando o BigQuery para agregar dados nos back-ends do Git, descobrimos que o problema não está vinculado a nenhuma máquina virtual específica. Precisávamos de mais informações.
Quero observar que as entradas de log com o valor
SD não eram algo especial, característico apenas para o nosso problema. Na porta alternate-ssh, recebemos muitas solicitações relacionadas à verificação de HTTPS. Isso levou ao fato de que o valor
SD caiu nos logs quando o servidor SSH viu a mensagem
TLS ClientHello enquanto esperava receber uma saudação SSH. Isso levou brevemente nossa investigação de forma indireta.
Depois de capturar algum tráfego entre o HAProxy e o servidor Git e novamente usar as ferramentas Wireshark, descobrimos rapidamente que o SSHD no servidor Git desconectou do TCP FIN-ACK imediatamente após um handshake de três vias do TCP. O HAProxy ainda não enviou o primeiro pacote de dados, mas estava prestes a fazê-lo. Quando ele enviou o pacote, o servidor Git respondeu com TCP RST. Como resultado - agora descobrimos o motivo pelo qual o HAProxy escreveu nos logs sobre a falha na conexão com o valor
SD . O SSH fechou a conexão, intencional e corretamente, e o RST foi apenas um artefato do fato de o servidor SSH receber o pacote após o FIN-ACK. Isso não significava mais nada.
Agenda eloquente
Observando e analisando logs com valores
SD no BigQuery, percebemos que os erros têm uma relação pronunciada com o tempo. Ou seja, encontramos picos no número de conexões com falha nos primeiros 10 segundos de cada minuto. Eles foram observados por 5-6 segundos.
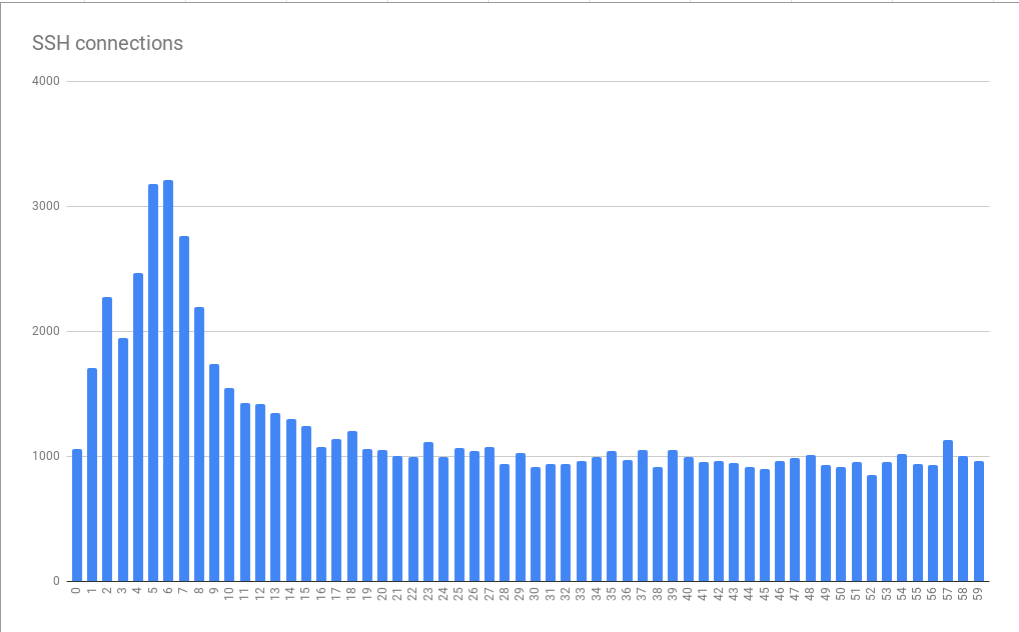 Erros de conexão agrupados em minutos a segundos
Erros de conexão agrupados em minutos a segundosEste gráfico é baseado em dados coletados por muitas horas. O fato de o padrão detectado de distribuição de erros ter se mostrado estável indica que a causa dos erros se manifesta de maneira estável em minutos e horas individuais e, possivelmente ainda pior, aparece de maneira estável em diferentes momentos do dia. É muito interessante que o tamanho médio do pico seja aproximadamente 3 vezes maior que a carga base. Isso significava que estávamos diante de um problema não trivial de dimensionamento. Como resultado, simplesmente conectar "mais recursos" na forma de máquinas virtuais adicionais, projetadas para nos ajudar a lidar com picos de carga, teoricamente poderia ser inaceitavelmente caro. Isso também indicou que estamos alcançando algum tipo de restrição severa. Como resultado, recebemos a primeira pista sobre o problema sistêmico fundamental que causa erros. Eu chamei de tirania de horas.
Sistemas de agendamento Cron ou similares geralmente não diferem na capacidade de personalizar a execução de tarefas para o segundo mais próximo. Se tais sistemas tiverem tais capacidades, eles não serão usados com muita frequência devido ao fato de as pessoas preferirem considerar o tempo, dividido em intervalos, expresso por belos números redondos. Como resultado, as tarefas começam no início de um minuto ou hora, ou em outros momentos semelhantes. Se as tarefas precisarem de alguns segundos para preparar o comando
git fetch para baixar materiais do gitlab.com, isso pode explicar o padrão encontrado quando a carga no sistema aumenta acentuadamente por vários segundos a cada minuto. Nesses momentos, o número de erros aumenta.
Lição número 2. Aparentemente, muitas pessoas usam a sincronização de horário configurada corretamente (via NTP ou usando outros mecanismos).
Se ninguém sincronizasse o tempo, nosso problema não teria se manifestado tão claramente. Boa tarde, NTP!
Mas o que faz com que o SSH se desconecte?
Mais próximo do âmago do problema
Estudando a documentação do SSHD, descobrimos o parâmetro
MaxStartups . Controla o número máximo de conexões não autenticadas. Parece plausível que o limite de conexão se esgote quando, no início do minuto, o sistema está sujeito à carga criada por uma enxurrada de chamadas de tarefas agendadas de toda a Internet. O parâmetro
MaxStartups consiste em três números. O primeiro é o limite inferior (o número de conexões ao atingir quais interrupções nas conexões começam). O segundo é a porcentagem de compostos que excedem o limite inferior dos compostos que precisam ser quebrados aleatoriamente. O terceiro valor é o número máximo absoluto de conexões, após o qual todas as novas conexões são rejeitadas. O valor padrão de MaxStartups é 10: 30: 100 e, em seguida, nossas configurações são 100: 30: 200. Isso indicou que no passado aumentamos os limites de conexão padrão. Talvez - é hora de aumentá-los novamente.
Acabou sendo um pouco desagradável que, desde que o OpenSSH 7.2 foi instalado em nossos servidores, a única maneira de ver os limites definidos no
MaxStartups fossem
MaxStartups para o nível de depuração
Debug . Com essa abordagem, uma avalanche de dados cai nos logs. Portanto, ativamos brevemente esse modo em um dos servidores. Felizmente, após alguns minutos, ficou claro que o número de conexões excedia os limites definidos no
MaxStartups , como resultado de uma desconexão antecipada.
Verificou-se que no OpenSSH 7.6 (esta versão vem com o Ubuntu 18.04)
MaxStartups uma abordagem mais conveniente para registrar o que está relacionado ao
MaxStartups . Aqui você só precisa mudar para o modo de registro
Verbose . Embora não seja ideal, ainda é melhor do que mudar para o nível de
Debug .
Lição número 3. É considerado uma boa forma gravar informações interessantes nos logs nos níveis de registro padrão, e informações sobre uma desconexão intencional por qualquer motivo são certamente interessantes para os administradores de sistema.
Agora que descobrimos a causa do problema, surgiu a pergunta sobre como resolvê-lo. Poderíamos aumentar os valores no parâmetro
MaxStartups , mas quanto isso nos custaria? Certamente, isso exigiria um pouco de memória adicional, mas levaria a conseqüências adversas nas partes do sistema em que as solicitações são processadas? Nós só podíamos pensar nisso, então decidimos pegar e apenas experimentar as novas configurações do
MaxStartups . Nós os trocamos pelo seguinte: 150: 30: 300. Anteriormente, eles pareciam 100: 30: 200, ou seja, aumentamos o número de conexões em 50%. Isso teve um forte efeito positivo no sistema. Ao mesmo tempo, alguns efeitos negativos, como o aumento da carga nos processadores, não foram observados.
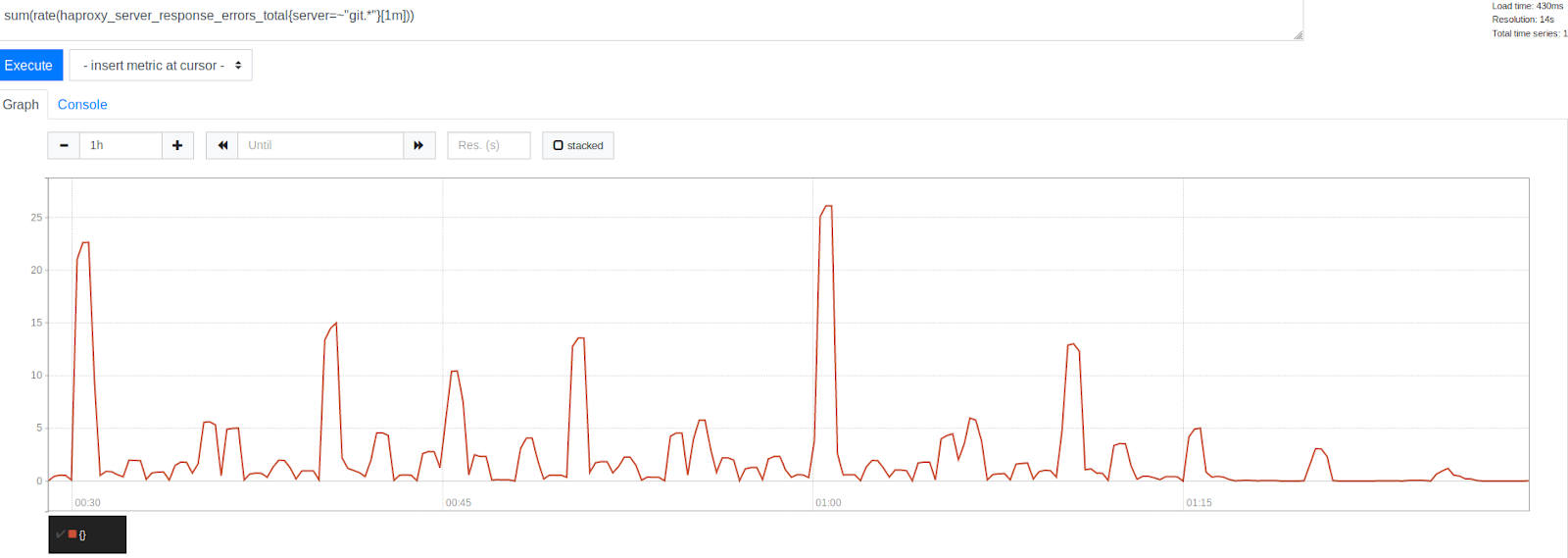 O número de erros antes e depois de aumentar o MaxStartups em 50%
O número de erros antes e depois de aumentar o MaxStartups em 50%Observe a redução significativa nos erros após o carimbo de hora 1:15. Isso indica claramente que fomos capazes de nos livrar de uma parte significativa dos erros, embora alguns deles ainda estivessem presentes. É interessante notar que os erros são agrupados em torno de carimbos de data e hora representados por belos números redondos. Este é o começo da hora, a cada 30, 15 e 10 minutos. Sem dúvida, a tirania do relógio continuou. No início de cada hora, o pico mais alto de erros é observado. Isso, dado o que já descobrimos, parece bastante compreensível. Muitas pessoas simplesmente planejam executar tarefas a cada hora que é executada 0 minutos após o início da hora. Esse fato confirmou nossa teoria de que os picos de erro são causados pelo lançamento de tarefas agendadas. Isso indicava que estávamos no caminho certo para resolver o problema, ajustando os limites do sistema.
Para nosso prazer, alterar o limite de
MaxStartups não levou a efeitos negativos perceptíveis. O uso da CPU nos servidores SSH permaneceu quase no mesmo nível de antes, a carga em nossos sistemas também não aumentou. Foi muito bom, considerando que agora aceitávamos mais conexões, daquelas que simplesmente teriam sido quebradas antes. Além disso, a situação não foi agravada pelo fato de termos feito isso em um momento em que nossos sistemas estavam muito carregados. Tudo parecia promissor.
Para continuar ...
Caros leitores! Quais ferramentas você usa para analisar tráfego e logs?
