Oi Habr.
Depois de experimentar um conhecido banco de dados de 60.000 números manuscritos, o MNIST, surgiu a questão lógica de saber se havia algo semelhante, mas com suporte não apenas para números, mas também para letras. Como se viu, existe e é chamado de base, como você pode imaginar, Extended MNIST (EMNIST).
Se alguém estiver interessado em usar esse banco de dados, você pode fazer um simples reconhecimento de texto, bem-vindo ao gato.
 Nota
Nota : este exemplo é experimental e educacional, eu só estava interessado em ver o que resulta disso. Eu não planejei e não planejo fazer o segundo FineReader; muitas coisas aqui, é claro, não são implementadas. Portanto, reivindicações no estilo de "por que", "já é melhor" etc. etc. não são aceitas. Provavelmente já existem bibliotecas OCR prontas para o Python, mas foi interessante fazê-lo você mesmo. A propósito, para aqueles que querem ver como o FineReader foi criado, há dois artigos em seu blog no Habr em 2014:
1 e
2 (mas é claro, sem códigos-fonte e detalhes, como em qualquer blog corporativo). Bem, vamos começar, tudo está aberto aqui e tudo é de código aberto.
Por exemplo, pegaremos o texto sem formatação. Aqui está um:
OLÁ MUNDO
E vamos ver o que pode ser feito com isso.
Quebrando texto em letras
O primeiro passo é dividir o texto em letras separadas. O OpenCV é útil para isso, mais precisamente sua função findContours.
Abra a imagem (cv2.imread), traduza-a em preto e branco (cv2.cvtColor + cv2.threshold), aumente levemente (cv2.erode) e encontre os contornos.
image_file = "text.png" img = cv2.imread(image_file) gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) ret, thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY) img_erode = cv2.erode(thresh, np.ones((3, 3), np.uint8), iterations=1)
Temos uma árvore hierárquica de contornos (parâmetro cv2.RETR_TREE). Primeiro vem o contorno geral da imagem, depois os contornos das letras, depois os contornos internos. Nós só precisamos do esboço das letras, então eu verifico que o "esboço" é o esboço geral. Essa é uma abordagem simplificada e, para verificações reais, isso pode não funcionar, embora não seja essencial reconhecer as capturas de tela.
Resultado:
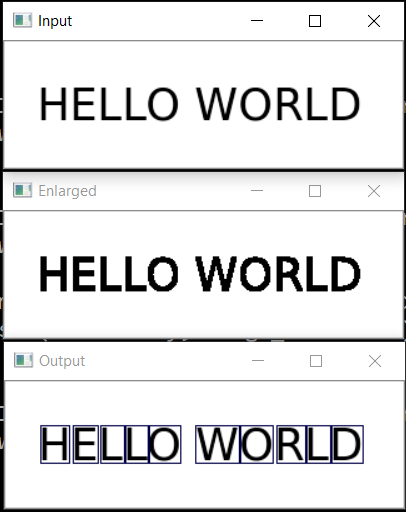
A próxima etapa é salvar cada letra, escalando-a anteriormente para um quadrado de 28x28 (é nesse formato que o banco de dados MNIST é armazenado). O OpenCV é construído com base no numpy, para que possamos usar as funções de trabalhar com matrizes para cortar e dimensionar.
def letters_extract(image_file: str, out_size=28) -> List[Any]: img = cv2.imread(image_file) gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) ret, thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY) img_erode = cv2.erode(thresh, np.ones((3, 3), np.uint8), iterations=1)
No final, classificamos as letras pela coordenada X, assim como você pode ver, salvamos os resultados na forma de tupla (x, w, letra), para que os espaços possam ser selecionados entre os espaços entre as letras.
Verifique se tudo funciona:
cv2.imshow("0", letters[0][2]) cv2.imshow("1", letters[1][2]) cv2.imshow("2", letters[2][2]) cv2.imshow("3", letters[3][2]) cv2.imshow("4", letters[4][2]) cv2.waitKey(0)

As cartas estão prontas para reconhecimento, nós as reconheceremos usando uma rede convolucional - esse tipo de rede é adequado para essas tarefas.
Rede Neural (CNN) para reconhecimento
O conjunto de dados EMNIST de origem possui 62 caracteres diferentes (A..Z, 0..9 etc.):
emnist_labels = [48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122]
Uma rede neural, portanto, possui 62 saídas, na entrada receberá imagens 28x28, após o reconhecimento “1” estará na saída de rede correspondente.
Crie um modelo de rede.
from tensorflow import keras from keras.models import Sequential from keras import optimizers from keras.layers import Convolution2D, MaxPooling2D, Dropout, Flatten, Dense, Reshape, LSTM, BatchNormalization from keras.optimizers import SGD, RMSprop, Adam from keras import backend as K from keras.constraints import maxnorm import tensorflow as tf def emnist_model(): model = Sequential() model.add(Convolution2D(filters=32, kernel_size=(3, 3), padding='valid', input_shape=(28, 28, 1), activation='relu')) model.add(Convolution2D(filters=64, kernel_size=(3, 3), activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(512, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(len(emnist_labels), activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer='adadelta', metrics=['accuracy']) return model
Como você pode ver, essa é uma rede convolucional clássica que destaca certos recursos da imagem (o número de filtros 32 e 64), cuja saída é conectada à rede MLP “linear”, que forma o resultado final.
Treinamento em redes neurais
Passamos ao estágio mais longo - o treinamento em rede. Para fazer isso, utilizamos o banco de dados EMNIST, que pode ser baixado
do link (tamanho do arquivo 536Mb).
Para ler o banco de dados, use a biblioteca idx2numpy. Prepararemos dados para treinamento e validação.
import idx2numpy emnist_path = '/home/Documents/TestApps/keras/emnist/' X_train = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-train-images-idx3-ubyte') y_train = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-train-labels-idx1-ubyte') X_test = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-test-images-idx3-ubyte') y_test = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-test-labels-idx1-ubyte') X_train = np.reshape(X_train, (X_train.shape[0], 28, 28, 1)) X_test = np.reshape(X_test, (X_test.shape[0], 28, 28, 1)) print(X_train.shape, y_train.shape, X_test.shape, y_test.shape, len(emnist_labels)) k = 10 X_train = X_train[:X_train.shape[0] // k] y_train = y_train[:y_train.shape[0] // k] X_test = X_test[:X_test.shape[0] // k] y_test = y_test[:y_test.shape[0] // k]
Preparamos dois conjuntos para treinamento e validação. Os próprios caracteres são matrizes comuns que são fáceis de exibir:

Também usamos apenas 1/10 do conjunto de dados para treinamento (parâmetro k), caso contrário, o processo levará pelo menos 10 horas.
Iniciamos o treinamento em rede; no final do processo, salvamos o modelo treinado em disco.
O processo de aprendizado em si leva cerca de meia hora:
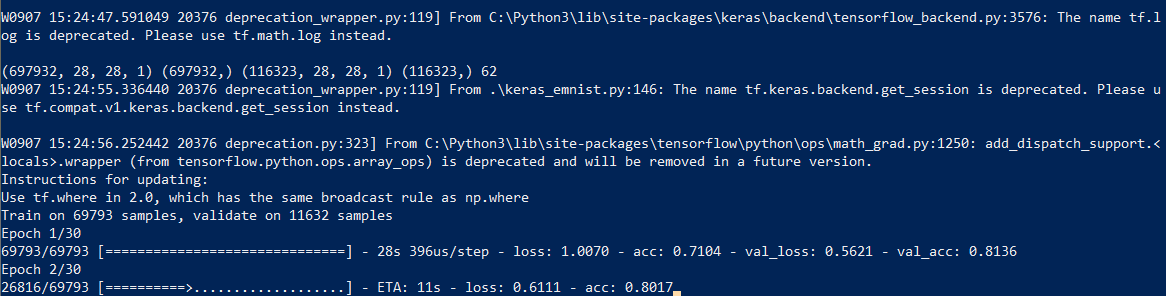
Isso precisa ser feito apenas uma vez; depois, usaremos o arquivo de modelo já salvo. Quando o treinamento terminar, tudo estará pronto, você poderá reconhecer o texto.
Reconhecimento
Para reconhecimento, carregamos o modelo e chamamos a função predict_classes.
model = keras.models.load_model('emnist_letters.h5') def emnist_predict_img(model, img): img_arr = np.expand_dims(img, axis=0) img_arr = 1 - img_arr/255.0 img_arr[0] = np.rot90(img_arr[0], 3) img_arr[0] = np.fliplr(img_arr[0]) img_arr = img_arr.reshape((1, 28, 28, 1)) result = model.predict_classes([img_arr]) return chr(emnist_labels[result[0]])
Como se viu, as imagens no conjunto de dados foram inicialmente giradas, por isso temos que girar a imagem antes do reconhecimento.
A função final, que recebe um arquivo com uma imagem na entrada e fornece uma linha na saída, ocupa apenas 10 linhas de código:
def img_to_str(model: Any, image_file: str): letters = letters_extract(image_file) s_out = "" for i in range(len(letters)): dn = letters[i+1][0] - letters[i][0] - letters[i][1] if i < len(letters) - 1 else 0 s_out += emnist_predict_img(model, letters[i][2]) if (dn > letters[i][1]/4): s_out += ' ' return s_out
Aqui, usamos a largura do caractere salvo anteriormente para adicionar espaços se o espaçamento entre as letras for maior que 1/4 do caractere.
Exemplo de uso:
model = keras.models.load_model('emnist_letters.h5') s_out = img_to_str(model, "hello_world.png") print(s_out)
Resultado:

Uma característica engraçada é que a rede neural “confundiu” a letra “O” e o número “0”, o que, no entanto, não é surpreendente, pois O conjunto original do EMNIST contém letras
manuscritas e números que não são exatamente iguais aos impressos. Idealmente, para reconhecer textos na tela, você precisa preparar um conjunto separado com base nas fontes da tela e treinar uma rede neural nele.
Conclusão
Como você pode ver, não são os deuses que queimam as panelas, e o que antes parecia "mágico" com a ajuda das bibliotecas modernas é bastante simples.
Como o Python é multiplataforma, o código funcionará em qualquer lugar, no Windows, Linux e OSX. Como o Keras é portado para iOS / Android, também, teoricamente, o modelo treinado também pode ser usado em
dispositivos móveis .
Para aqueles que querem experimentar por conta própria, o código-fonte está sob o spoiler.
Como sempre, todas as experiências bem-sucedidas.